AI Crawlers Explained: GPTBot, ClaudeBot, and More
Understand how AI crawlers like GPTBot and ClaudeBot work, their differences from traditional search crawlers, and how to optimize your site for AI search visibility.
Published on Jan 3, 2026.Last modified on Jan 3, 2026 at 3:24 am
AI crawlers are automated programs designed to systematically browse the internet and collect data from websites, specifically to train and improve artificial intelligence models. Unlike traditional search engine crawlers such as Googlebot, which index content for search results, AI crawlers gather raw web data to feed into large language models (LLMs) like ChatGPT, Claude, and other AI systems. These bots operate continuously across millions of websites, downloading pages, analyzing content, and extracting information that helps AI platforms understand language patterns, factual information, and diverse writing styles. The major players in this space include GPTBot from OpenAI, ClaudeBot from Anthropic, Meta-ExternalAgent from Meta, Amazonbot from Amazon, and PerplexityBot from Perplexity.ai, each serving their respective AI platforms’ training and operational needs. Understanding how these crawlers work has become essential for website owners and content creators, as AI visibility now directly impacts how your brand appears in AI-powered search results and recommendations.
The Rise of AI Crawlers
The landscape of web crawling has undergone a dramatic transformation over the past year, with AI crawlers experiencing explosive growth while traditional search crawlers maintain steady patterns. Between May 2024 and May 2025, overall crawler traffic grew by 18%, but the distribution shifted significantly—GPTBot surged 305% in raw requests, while other crawlers like ClaudeBot declined by 46% and Bytespider plummeted 85%. This reordering reflects the intensifying competition among AI companies to secure training data and improve their models. Here’s a detailed breakdown of the major crawlers and their current market position:
Crawler Name
Company
Monthly Requests
YoY Growth
Primary Purpose
Googlebot
Google
4.5 billion
96%
Search indexing & AI Overviews
GPTBot
OpenAI
569 million
305%
ChatGPT model training & search
Claude
Anthropic
370 million
-46%
Claude model training & search
Bingbot
Microsoft
~450 million
2%
Search indexing
PerplexityBot
Perplexity.ai
24.4 million
157,490%
AI search indexing
Meta-ExternalAgent
Meta
~380 million
New entry
Meta AI training
Amazonbot
Amazon
~210 million
-35%
Search & AI applications
The data reveals that while Googlebot maintains dominance with 4.5 billion monthly requests, AI crawlers collectively represent approximately 28% of Googlebot’s volume, making them a significant force in web traffic. The explosive growth of PerplexityBot (157,490% increase) demonstrates how rapidly new AI platforms are scaling their crawling operations, while the decline of some established AI crawlers suggests market consolidation around the most successful AI platforms.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
GPTBot is OpenAI’s web crawler, specifically designed to collect data for training and improving ChatGPT and other OpenAI models. Launched as a relatively minor player with only 5% market share in May 2024, GPTBot has become the dominant AI crawler, capturing 30% of all AI crawler traffic by May 2025—a remarkable 305% increase in raw requests. This explosive growth reflects OpenAI’s aggressive strategy to ensure ChatGPT has access to fresh, diverse web content for both model training and real-time search capabilities through ChatGPT Search. GPTBot operates with a distinct crawl pattern, prioritizing HTML content (57.70% of fetches) while also downloading JavaScript files and images, though it doesn’t execute JavaScript to render dynamic content. The crawler’s behavior shows it frequently encounters 404 errors (34.82% of requests), suggesting it may be following outdated links or attempting to access resources that no longer exist. For website owners, GPTBot’s dominance means that ensuring your content is accessible to this crawler has become critical for visibility in ChatGPT’s search features and for potential inclusion in future model training iterations.
ClaudeBot and Anthropic’s Approach
ClaudeBot, developed by Anthropic, serves as the primary crawler for training and updating the Claude AI assistant, as well as supporting Claude’s search and grounding capabilities. Once the second-largest AI crawler with 27% market share in May 2024, ClaudeBot has experienced a notable decline to 21% by May 2025, with raw requests dropping 46% year-over-year. This decline doesn’t necessarily indicate a problem with Anthropic’s strategy but rather reflects the broader market shift towards OpenAI’s dominance and the emergence of new competitors like Meta-ExternalAgent. ClaudeBot exhibits similar behavior to GPTBot, prioritizing HTML content but dedicating a higher percentage of requests to images (35.17% of fetches), suggesting Anthropic may be training Claude to better understand visual content alongside text. Like other AI crawlers, ClaudeBot doesn’t render JavaScript, meaning it only sees the raw HTML of pages without any dynamically loaded content. For content creators, maintaining visibility with ClaudeBot remains important for ensuring Claude can access and cite your content, particularly as Anthropic continues to develop Claude’s search and reasoning capabilities.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Other Major AI Crawlers
Beyond GPTBot and ClaudeBot, several other significant AI crawlers are actively collecting web data for their respective platforms:
Meta-ExternalAgent (Meta): Meta’s crawler made a dramatic entry into the top rankings, capturing 19% market share by May 2025 as a new entrant. This bot collects data for Meta’s AI initiatives, including potential training for Meta AI and integration with Instagram and Facebook’s AI features. Meta’s rapid rise suggests the company is making a serious push into AI-powered search and recommendations.
PerplexityBot (Perplexity.ai): Despite having only 0.2% market share, PerplexityBot experienced the most explosive growth rate at 157,490% year-over-year. This reflects Perplexity’s rapid scaling as an AI answer engine that relies on real-time web search to ground its responses. For websites, PerplexityBot visits represent direct opportunities to be cited in Perplexity’s AI-generated answers.
Amazonbot (Amazon): Amazon’s crawler declined from 21% to 11% market share, with raw requests dropping 35% year-over-year. Amazonbot collects data for Amazon’s search functionality and AI applications, though its declining share suggests Amazon may be shifting its AI strategy or consolidating its crawling operations.
Applebot (Apple): Apple’s crawler experienced a 26% decline in requests, falling from 1.9% to 1.2% market share. Applebot primarily serves Apple’s Siri and Spotlight search, though it may also support Apple’s emerging AI initiatives. Unlike most other AI crawlers, Applebot can render JavaScript, giving it capabilities similar to Googlebot.
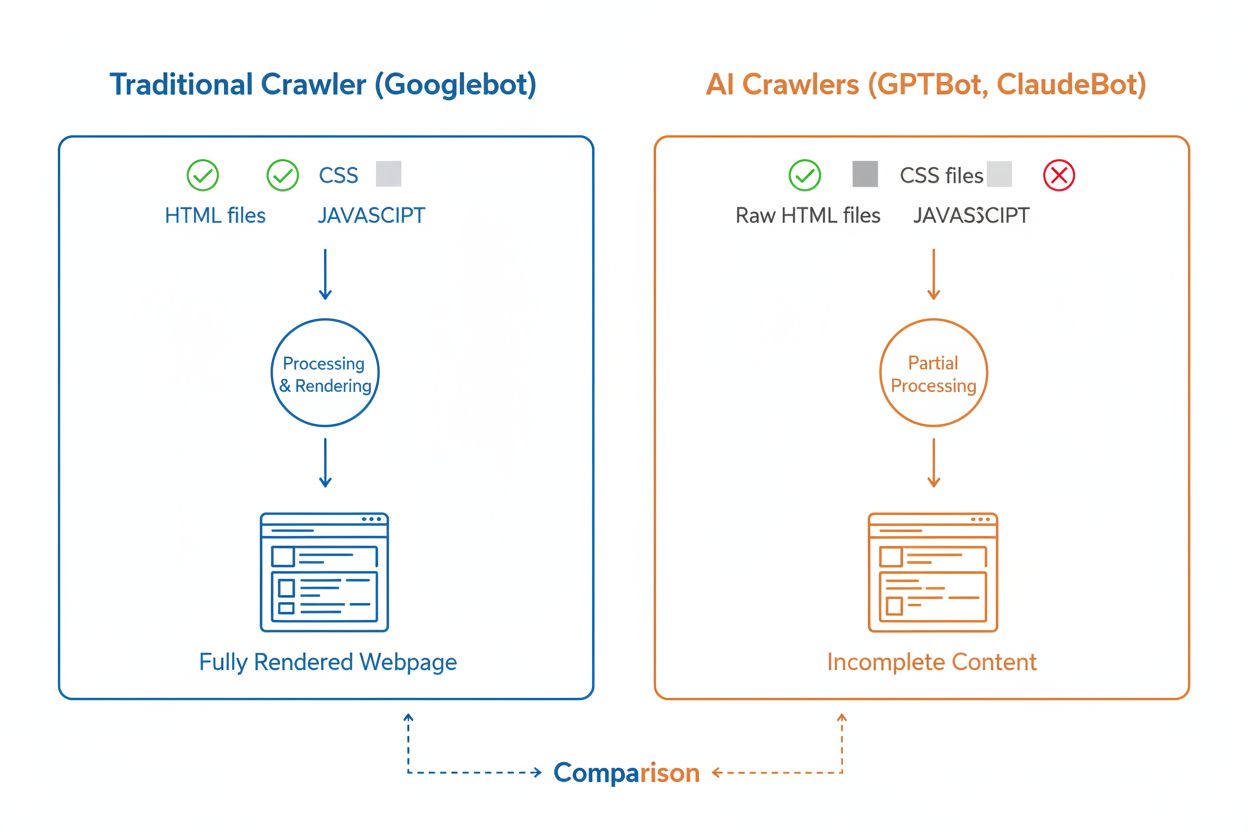
How AI Crawlers Differ from Googlebot
While AI crawlers and traditional search crawlers like Googlebot both systematically browse the web, their technical capabilities and behaviors differ significantly in ways that directly impact how your content is discovered and understood. The most critical difference is JavaScript rendering: Googlebot can execute JavaScript after downloading a page, allowing it to see dynamically loaded content, while most AI crawlers (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) only read the raw HTML and ignore any JavaScript-dependent content. This means if your website relies on client-side rendering to display key information, AI crawlers will see an incomplete version of your pages. Additionally, AI crawlers show less predictable crawl patterns compared to Googlebot’s systematic approach—they spend 34.82% of requests on 404 pages and 14.36% following redirects, compared to Googlebot’s more efficient 8.22% on 404s and 1.49% on redirects. Crawl frequency also differs: while Googlebot visits pages based on a sophisticated crawl budget system, AI crawlers appear to crawl more frequently but less systematically, with some research showing AI crawlers visiting pages over 100 times more frequently than Google in certain cases. These differences mean that traditional SEO optimization strategies may not fully address AI crawlability, requiring a distinct approach focused on server-side rendering and clean URL structures.
JavaScript Rendering Limitations
One of the most significant technical challenges for AI crawlers is their inability to render JavaScript, a limitation that stems from the computational cost of executing JavaScript at the massive scale required for training large language models. When a crawler downloads your webpage, it receives the initial HTML response, but any content loaded or modified by JavaScript—such as product details, pricing information, user reviews, or dynamic navigation elements—remains invisible to AI crawlers. This creates a critical problem for modern websites that rely heavily on client-side rendering frameworks like React, Vue, or Angular without server-side rendering (SSR) or static site generation (SSG). For example, an e-commerce site that loads product information via JavaScript will appear to AI crawlers as an empty page with no product details, making it impossible for AI systems to understand or cite that content. The solution is to ensure that all critical content is served in the initial HTML response through server-side rendering, which generates the complete HTML on the server before sending it to the browser. This approach ensures both human visitors and AI crawlers receive the same content-rich experience. Websites using modern frameworks like Next.js with SSR, static site generators like Hugo or Gatsby, or traditional server-rendered platforms like WordPress are naturally AI-crawler-friendly, while those relying solely on client-side rendering face significant visibility challenges in AI search.
Crawl Frequency and Patterns
AI crawlers exhibit distinct crawl frequency patterns that differ markedly from Googlebot’s behavior, with important implications for how quickly your content gets picked up by AI systems. Research shows that AI crawlers like ChatGPT and Perplexity often visit pages more frequently than Google in the short term after publication—in some cases, visiting pages 8 times more often than Googlebot within the first few days. This rapid initial crawl suggests that AI platforms prioritize discovering and indexing new content quickly, likely to ensure their models and search features have access to the latest information. However, this aggressive initial crawl is followed by a pattern where AI crawlers may not return if the content doesn’t meet quality standards, making that first impression critically important. Unlike Googlebot, which has a sophisticated crawl budget system and will return to pages regularly based on update frequency and importance, AI crawlers appear to make a judgment call on whether content is worth revisiting. This means if an AI crawler visits your page and finds thin content, technical errors, or poor user experience signals, it may take significantly longer to return—if it returns at all. The implication for content creators is clear: you cannot rely on a second chance to optimize content for AI crawlers the way you might with traditional search engines, making pre-publication quality assurance essential.
robots.txt and AI Crawler Control
Website owners can use the robots.txt file to communicate their preferences regarding AI crawler access, though the effectiveness and enforcement of these rules varies significantly across different crawlers. According to recent data, approximately 14% of the top 10,000 websites have implemented specific allow or disallow rules targeting AI bots in their robots.txt files. GPTBot is the most frequently blocked crawler, with 312 domains (250 fully, 62 partially) explicitly disallowing it, though it’s also the most explicitly allowed crawler with 61 domains granting access. Other commonly blocked crawlers include CCBot (Common Crawl) and Google-Extended (Google’s AI training token). The challenge with robots.txt is that compliance is voluntary—crawlers honor these rules only if their operators choose to implement that functionality, and some newer or less transparent crawlers may not respect robots.txt directives at all. Additionally, robots.txt tokens like “Google-Extended” don’t directly correspond to user-agent strings in HTTP requests; instead, they signal the purpose of crawling, meaning you can’t always verify compliance through server logs. For stronger enforcement, website owners increasingly turn to firewall rules and Web Application Firewalls (WAFs) that can actively block specific crawler user-agents, providing more reliable control than robots.txt alone. This shift toward active blocking mechanisms reflects growing concerns about content rights and the desire for more enforceable controls over AI crawler access.
Monitoring AI Crawler Activity
Tracking AI crawler activity on your website is essential for understanding your visibility in AI search, yet it presents unique challenges compared to monitoring traditional search engine crawlers. Traditional analytics tools like Google Analytics rely on JavaScript tracking, which AI crawlers don’t execute, meaning these tools provide no visibility into AI bot visits. Similarly, pixel-based tracking won’t work because most AI crawlers only process text and ignore images. The only reliable way to track AI crawler activity is through server-side monitoring—analyzing HTTP request headers and server logs to identify crawler user-agents before the page is sent. This requires either manual log analysis or specialized tools designed specifically to identify and track AI crawler traffic. Real-time monitoring is particularly critical because AI crawlers operate on unpredictable schedules and may not return to pages if they encounter issues, meaning a weekly or monthly crawl audit may miss important problems. If an AI crawler visits your site and finds a technical error or poor content quality, you may not get another opportunity to make a good impression. Implementing 24/7 monitoring solutions that alert you immediately when AI crawlers encounter issues—such as 404 errors, slow page load times, or missing schema markup—allows you to address problems before they impact your AI search visibility. This real-time approach represents a fundamental shift from traditional SEO monitoring practices, reflecting the speed and unpredictability of AI crawler behavior.
Optimizing for AI Crawlers
Optimizing your website for AI crawlers requires a distinct approach from traditional SEO, focusing on technical factors that directly impact how AI systems can access and understand your content. The first priority is server-side rendering: ensure that all critical content—headlines, body text, metadata, structured data—is included in the initial HTML response rather than loaded dynamically via JavaScript. This applies to your homepage, key landing pages, and any content you want AI systems to cite or reference. Second, implement structured data markup (Schema.org) on your high-impact pages, including article schema for blog posts, product schema for e-commerce items, and author schema to establish expertise and authority. AI crawlers use structured data to quickly understand content hierarchy and context, making it significantly easier for them to parse and cite your information. Third, maintain strong content quality standards across all pages, as AI crawlers appear to make rapid judgments about whether content is worth indexing and citing. This means ensuring your content is original, well-researched, factually accurate, and provides genuine value to readers. Fourth, monitor and optimize Core Web Vitals and overall page performance, as slow-loading pages signal poor user experience and may discourage AI crawlers from returning. Finally, keep your URL structure clean and consistent, maintain an updated XML sitemap, and ensure your robots.txt file is properly configured to guide crawlers to your most important content. These technical optimizations create a foundation that makes your content discoverable, understandable, and citable by AI systems.
The Future of AI Crawlers
The landscape of AI crawlers will continue to evolve rapidly as competition intensifies among AI companies and as the technology matures. One clear trend is the consolidation of market share around the most successful platforms—OpenAI’s GPTBot has emerged as the dominant force, while newer entrants like Meta-ExternalAgent are scaling aggressively, suggesting the market will likely stabilize around a handful of major players. As AI crawlers mature, we can expect improvements in their technical capabilities, particularly around JavaScript rendering and more efficient crawl patterns that reduce wasted requests on 404 pages and outdated content. The industry is also moving toward more standardized communication protocols, such as the emerging llms.txt specification, which allows websites to explicitly communicate their content structure and crawling preferences to AI systems. Additionally, the enforcement mechanisms for controlling AI crawler access are becoming more sophisticated, with platforms like Cloudflare now offering automated blocking of AI training bots by default, giving website owners more granular control over their content. For content creators and website owners, staying ahead of these changes means continuously monitoring AI crawler activity, keeping your technical infrastructure optimized for AI accessibility, and adapting your content strategy to account for the reality that AI systems now represent a significant portion of your website’s traffic and a critical channel for brand visibility. The future belongs to those who understand and optimize for this new crawler ecosystem.
Frequently asked questions
What is an AI crawler and how does it differ from a search engine crawler?
AI crawlers are automated programs that collect web data specifically to train and improve artificial intelligence models like ChatGPT and Claude. Unlike traditional search engine crawlers such as Googlebot, which index content for search results, AI crawlers gather raw web data to feed into large language models. Both types of crawlers systematically browse the internet, but they serve different purposes and have different technical capabilities.
Why do AI crawlers need to access my website?
AI crawlers access your website to collect data for training AI models, improving search features, and grounding AI responses with current information. When AI systems like ChatGPT or Perplexity answer user questions, they often need to fetch your content in real-time to provide accurate, cited information. Allowing AI crawlers to access your site increases the chances your brand will be mentioned and cited in AI-generated responses.
Can I block AI crawlers from accessing my site?
Yes, you can use your robots.txt file to disallow specific AI crawlers by specifying their user-agent names. However, compliance with robots.txt is voluntary, and not all crawlers respect these rules. For stronger enforcement, you can use firewall rules and Web Application Firewalls (WAFs) to actively block specific crawler user-agents. This gives you more reliable control over which AI crawlers can access your content.
Do AI crawlers render JavaScript like Google does?
No, most AI crawlers (GPTBot, ClaudeBot, Meta-ExternalAgent) do not execute JavaScript. They only read the raw HTML of your pages, meaning any content loaded dynamically via JavaScript will be invisible to them. This is why server-side rendering is critical for AI crawlability. If your site relies on client-side rendering, AI crawlers will see an incomplete version of your pages.
How often do AI crawlers visit websites?
AI crawlers visit websites more frequently than traditional search engines in the short term after content publication. Research shows they may visit pages 8-100 times more often than Google within the first few days. However, if content doesn't meet quality standards, they may not return. This makes the first impression critical—you may not get a second chance to optimize content for AI crawlers.
What's the best way to optimize my site for AI crawlers?
The key optimizations are: (1) Use server-side rendering to ensure critical content is in the initial HTML, (2) Add structured data markup (Schema) to help AI understand your content, (3) Maintain high content quality and freshness, (4) Monitor Core Web Vitals for good user experience, and (5) Keep your URL structure clean and maintain an updated sitemap. These technical optimizations create a foundation that makes your content discoverable and citable by AI systems.
Which AI crawler is most important for my website?
GPTBot from OpenAI is currently the dominant AI crawler, capturing 30% of all AI crawler traffic and growing 305% year-over-year. However, you should optimize for all major crawlers including ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity), and others. Different AI platforms have different user bases, so visibility across multiple crawlers maximizes your brand's presence in AI search.
How can I track AI crawler activity on my website?
Traditional analytics tools like Google Analytics won't capture AI crawler activity because they rely on JavaScript tracking. Instead, you need server-side monitoring that analyzes HTTP request headers and server logs to identify crawler user-agents. Specialized tools designed for AI crawler tracking provide real-time visibility into which pages are being crawled, how frequently, and whether crawlers are encountering technical issues.
Monitor Your Brand's Visibility in AI Search
Track how AI crawlers like GPTBot and ClaudeBot are accessing and citing your content. Get real-time insights into your AI search visibility with AmICited.
How to Allow AI Bots to Crawl Your Website: Complete robots.txt & llms.txt Guide
Learn how to allow AI bots like GPTBot, PerplexityBot, and ClaudeBot to crawl your site. Configure robots.txt, set up llms.txt, and optimize for AI visibility.
What AI Crawlers Should I Allow Access? Complete Guide for 2025
Learn which AI crawlers to allow or block in your robots.txt. Comprehensive guide covering GPTBot, ClaudeBot, PerplexityBot, and 25+ AI crawlers with configurat...
How to Identify AI Crawlers in Server Logs: Complete Detection Guide
Learn how to identify and monitor AI crawlers like GPTBot, PerplexityBot, and ClaudeBot in your server logs. Discover user-agent strings, IP verification method...
8 min read
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.