
Entity Recognition
Entity Recognition is an AI NLP capability identifying and categorizing named entities in text. Learn how it works, its applications in AI monitoring, and its r...
10 min read

Explore how AI systems recognize and process entities in text. Learn about NER models, transformer architectures, and real-world applications of entity understanding.
Entity understanding has become a cornerstone capability in modern artificial intelligence systems, enabling machines to identify and comprehend the key actors, places, and concepts within unstructured text. From powering search engines that understand user intent to enabling chatbots that can answer complex questions about specific people and organizations, entity recognition forms the foundation of meaningful human-computer interaction. This technical capability is critical across industries—financial institutions use it for compliance monitoring, healthcare systems leverage it for patient record management, and e-commerce platforms rely on it to understand product mentions and customer feedback. Understanding how AI systems extract and interpret entities is essential for anyone building or deploying NLP applications in production environments.
Named Entity Recognition (NER) is the NLP task of identifying and classifying named entities—specific, meaningful units of information—within text into predefined categories. These entities represent the concrete subjects that carry semantic weight in language: people who perform actions, organizations that make decisions, locations where events occur, temporal expressions that anchor events in time, monetary values that quantify transactions, and products that are bought and sold. Entity classification matters because it transforms raw text into structured knowledge that machines can reason about and act upon; without it, a system cannot distinguish between “Apple the company” and “apple the fruit,” or understand that “John Smith” and “J. Smith” refer to the same person. The ability to accurately classify entities enables downstream applications like knowledge graph construction, information extraction, question answering, and relationship detection.
| Entity Type | Definition | Example |
|---|---|---|
| PERSON | Individual human beings | “Steve Jobs,” “Marie Curie” |
| ORGANIZATION | Companies, institutions, groups | “Microsoft,” “United Nations,” “Harvard University” |
| LOCATION | Geographic places and regions | “New York,” “Amazon River,” “Silicon Valley” |
| DATE | Temporal expressions and time periods | “January 15, 2024,” “next Tuesday,” “Q3 2023” |
| MONEY | Monetary values and currencies | “$50 million,” “€100,” “5000 yen” |
| PRODUCT | Goods, services, and creations | “iPhone 15,” “Windows 11,” “ChatGPT” |
Modern AI systems process entities through a sophisticated multi-stage pipeline that begins with tokenization, breaking raw text into discrete tokens that serve as the fundamental units for downstream processing. Each token is then converted into a numerical representation through word embeddings—dense vectors that capture semantic meaning—which are fed into neural network architectures designed to understand context and relationships. Transformer-based models, which have become the dominant architecture in contemporary NLP, process entire sequences in parallel rather than sequentially, enabling them to capture long-range dependencies and complex contextual relationships that are crucial for accurate entity understanding. The self-attention mechanism within Transformers allows each token to dynamically weigh the importance of every other token in the sequence, creating rich contextual representations where the meaning of a word is shaped by its surrounding context; this is why “bank” is understood differently in “river bank” versus “savings bank.” Pre-trained language models like BERT and GPT learn general linguistic patterns from massive text corpora before being fine-tuned on entity recognition tasks, allowing them to leverage learned representations of syntax, semantics, and world knowledge. The final layer of entity recognition systems typically uses a sequence labeling approach—often implemented as a Conditional Random Field (CRF) or simple classification head—that assigns entity labels to each token based on the contextual representations learned by the neural network. This architecture enables AI systems to understand not just what entities are present, but how they relate to one another and what roles they play within the broader context of the text.
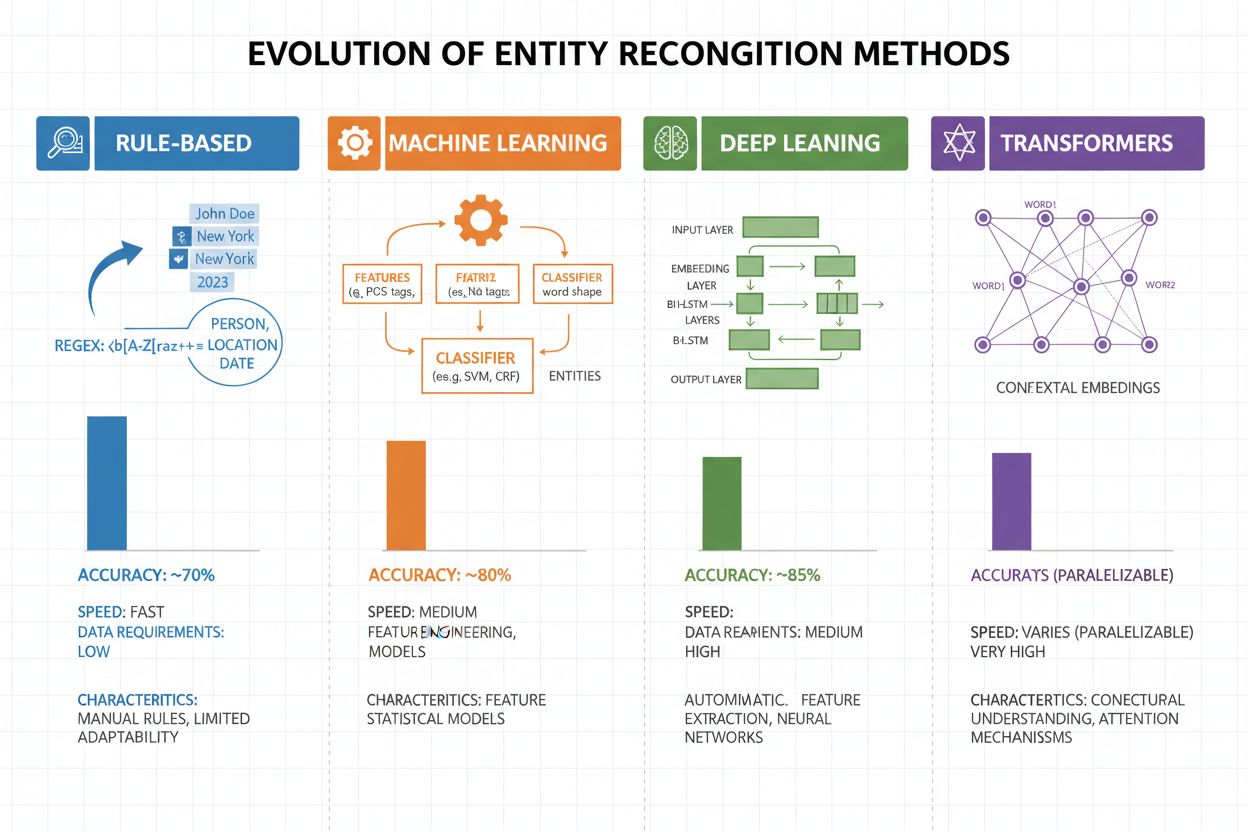
Entity recognition has evolved dramatically over the past two decades, progressing from simple rule-based approaches to sophisticated neural architectures. Early systems relied on hand-crafted rules and dictionaries, using regular expressions and pattern matching to identify entities—methods that were interpretable and required minimal training data but suffered from poor generalization and high maintenance overhead. The advent of machine learning brought supervised approaches like Support Vector Machines (SVM) and Conditional Random Fields (CRF), which learned from labeled data through feature engineering and significantly improved accuracy, though they still required domain experts to design meaningful features. Deep learning methods, particularly LSTMs and BiLSTMs, automated feature extraction by learning representations directly from raw text, achieving substantially higher accuracy without manual feature engineering but demanding larger labeled datasets. Transformer-based models like BERT and RoBERTa revolutionized the field by leveraging self-attention mechanisms to capture long-range dependencies and contextual nuances, achieving state-of-the-art results (BERT reached 90.9% F1 on CoNLL-2003) while enabling transfer learning from massive pre-trained models. The trade-off between complexity and accuracy has shifted dramatically: while rule-based systems are still valuable for resource-constrained environments and highly specialized domains, transformer models now dominate when sufficient computational resources and labeled data are available, with lighter alternatives like DistilBERT offering a middle ground for production systems with latency constraints.
Transformer-based models have fundamentally transformed entity recognition by replacing sequential processing with parallel self-attention mechanisms that simultaneously consider all tokens in a sentence, enabling richer contextual understanding than previous architectures. BERT and its variants (RoBERTa, DistilBERT, ALBERT) leverage bidirectional pre-training on massive unlabeled corpora, learning universal language representations that capture both syntactic and semantic information before being fine-tuned on downstream NER tasks with relatively small labeled datasets. The pre-training and fine-tuning paradigm is particularly powerful for entity recognition: models pre-trained on billions of tokens develop robust representations of language structure and entity patterns, which can then be adapted to specific domains with just thousands of labeled examples, dramatically reducing the data requirements compared to training from scratch. Transformers excel at handling entity understanding through their multi-head attention mechanism, which allows different attention heads to specialize in different types of entity relationships—some heads might focus on syntactic boundaries while others capture semantic associations between entities and their contexts. Multilingual entity recognition has been revolutionized by models like mBERT and XLM-RoBERTa, which are pre-trained on 100+ languages simultaneously, enabling zero-shot and few-shot transfer to low-resource languages and cross-lingual entity linking. Emerging models like GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) push the boundaries further by enabling instruction-based entity recognition, where models can identify arbitrary entity types specified in natural language prompts without task-specific fine-tuning, representing a shift toward more flexible and generalizable entity understanding systems.
Despite remarkable progress, entity recognition systems face persistent real-world challenges that limit their practical deployment, with ambiguity and context sensitivity being among the most intractable—the word “Apple” requires understanding whether it refers to the fruit or the technology company based on surrounding context, and even state-of-the-art models struggle with such semantic disambiguation in noisy or ambiguous text. Out-of-vocabulary (OOV) entities present another fundamental challenge: models trained on standard datasets may never encounter rare entities, proper nouns from emerging domains, or misspelled variations, causing them to either misclassify or fail to recognize these entities entirely. Domain adaptation remains problematic because models trained on news corpora (like CoNLL-2003) often perform poorly on biomedical, legal, or social media text where entity distributions and linguistic patterns differ dramatically, requiring expensive re-annotation and fine-tuning for each new domain. Boundary detection errors—where systems correctly identify that an entity exists but incorrectly determine its start or end position—are particularly common with multi-word entities and nested structures, such as distinguishing “New York City” from “New York” or handling entities like “Chief Executive Officer of Apple Inc.” Multilingual complexities compound these challenges, as different languages have different capitalization conventions, morphological structures, and entity naming patterns, making models trained on English often fail when applied to languages with different linguistic properties. Data scarcity for specialized domains like rare disease names, emerging technologies, or proprietary company terminology creates a bottleneck where the cost of manual annotation is prohibitive, forcing practitioners to choose between accepting lower accuracy or investing heavily in domain-specific training data collection.
Entity understanding has become indispensable across industries, transforming how organizations extract value from unstructured text. In information extraction and knowledge graph construction, entity recognition enables automated population of structured databases from documents, powering search engines and recommendation systems that understand relationships between people, places, and concepts. Healthcare organizations leverage entity understanding to identify drug names, dosages, symptoms, and patient demographics from clinical notes, improving clinical decision support and enabling pharmacovigilance systems to detect adverse drug interactions at scale. Financial institutions use entity recognition to extract stock symbols, monetary values, and market events from news feeds and earnings reports, enabling algorithmic trading systems and risk management platforms to react to market-moving information in real-time. Legal technology firms apply entity understanding to automatically identify parties, dates, obligations, and liability clauses in contracts, reducing the time lawyers spend on document review from weeks to hours. Customer service and chatbot platforms use entity recognition to extract user intents and relevant context—such as order numbers, product names, and issue types—enabling more accurate routing and faster resolution. E-commerce platforms employ entity understanding to identify product names, brands, features, and specifications from customer reviews and search queries, improving product discovery and personalization. Content recommendation systems use entity recognition to understand what entities users interact with, enabling more sophisticated collaborative filtering and content-based recommendations that drive engagement and revenue.
Implementing a production-grade entity understanding system requires careful attention to data preparation, model selection, and evaluation. Begin with high-quality annotated data: establish clear entity type definitions, use inter-annotator agreement metrics to ensure consistency, and aim for at least 500-1000 labeled examples per entity type, though domain-specific applications may require more. Model selection depends on your constraints: rule-based systems offer interpretability and low latency for well-defined domains, traditional machine learning models (CRF, SVM) provide good performance with moderate data, while transformer-based models (BERT, RoBERTa) deliver state-of-the-art accuracy but require more computational resources and data. Training and fine-tuning strategies should include data augmentation techniques to handle class imbalance, cross-validation to prevent overfitting, and careful hyperparameter tuning for learning rate and batch size. Evaluate your system using precision (correct entities identified), recall (entities found out of all actual entities), and F1-score (harmonic mean balancing both), with separate metrics for each entity type to identify weak areas. Deployment considerations include latency requirements (batch vs. real-time processing), scalability needs, and integration with existing data pipelines, while post-deployment monitoring should track performance drift, false positive rates, and user feedback to trigger retraining cycles.
The ecosystem of entity understanding tools offers solutions for every scale and use case. Open-source libraries like spaCy provide production-ready NER pipelines with impressive performance (89.22% F1-score on standard benchmarks) and excellent documentation, making it ideal for teams with machine learning expertise; NLTK offers educational value and basic NER capabilities; and Hugging Face Transformers provides access to state-of-the-art pre-trained models that can be fine-tuned for specific domains with minimal code. Cloud-based managed services eliminate infrastructure concerns: Google Cloud Natural Language API, AWS Comprehend, and IBM Watson NLP offer pre-trained entity recognition with support for multiple languages and entity types, handling scaling automatically and integrating seamlessly with cloud data pipelines. Specialized frameworks like Flair (built on PyTorch with excellent sequence labeling support) and DeepPavlov (offering pre-trained models for multiple languages and domains) cater to researchers and teams needing more customization than general-purpose libraries. The decision between building custom solutions and using pre-built tools depends on your data sensitivity (on-premise vs. cloud), required accuracy levels, domain specificity, and team expertise: use managed APIs for general-purpose applications with standard entity types, leverage open-source libraries for domain-specific customization with internal data, and build custom models only when existing solutions cannot meet your accuracy or latency requirements.
The future of entity understanding is being shaped by large language models that bring unprecedented flexibility and performance to the task. Models like GPT-4 and Claude demonstrate remarkable few-shot and zero-shot entity recognition capabilities, allowing organizations to identify custom entity types with just a handful of examples or even natural language descriptions, dramatically reducing annotation burden and accelerating time-to-value. Multimodal entity understanding is emerging as a frontier, combining text, images, and structured data to recognize entities in documents, invoices, and web pages with richer context, enabling applications like automated document processing and visual search. Real-time processing improvements driven by model distillation and edge deployment are making sophisticated entity recognition feasible on mobile devices and IoT systems, opening new applications in augmented reality, real-time translation, and autonomous systems. Domain-specific fine-tuning advances are creating specialized models for biomedical, legal, and financial domains that outperform general-purpose models by orders of magnitude, with techniques like domain-adaptive pre-training and transfer learning making this increasingly accessible. As these technologies mature, entity understanding will become an invisible foundation layer in AI systems, enabling machines to comprehend the world with human-like semantic understanding and opening possibilities we’re only beginning to imagine.
As AI systems like ChatGPT, Perplexity, and Google AI Overviews become increasingly integrated into how information is discovered and consumed, understanding how these systems recognize and reference entities—including your brand—becomes critical. Entity understanding is the mechanism by which AI systems identify and process mentions of companies, products, people, and concepts. When you monitor how AI systems understand and reference your brand through entity recognition, you gain insights into:
This is precisely what AmICited monitors—tracking how AI systems recognize and reference your brand as an entity across multiple AI platforms. By understanding entity recognition, you can better understand how AI systems perceive and communicate about your business.
Entity recognition (NER) identifies and classifies entities in text (e.g., 'Apple' as ORGANIZATION), while entity linking connects those entities to knowledge bases or canonical references (e.g., linking 'Apple' to the Wikipedia page for Apple Inc.). Entity recognition is the first step; entity linking adds semantic grounding.
State-of-the-art transformer-based models like BERT achieve 90.9% F1-score on standard benchmarks like CoNLL-2003. However, accuracy varies significantly by domain—models trained on news perform poorly on biomedical or social media text. Real-world accuracy depends heavily on domain adaptation and data quality.
Yes, multilingual models like mBERT and XLM-RoBERTa support 100+ languages simultaneously. However, performance varies by language due to differences in capitalization conventions, morphology, and available training data. Language-specific models typically outperform multilingual ones for critical applications.
Rule-based systems use hand-crafted patterns and dictionaries (fast, interpretable, but brittle). ML-based systems learn from labeled data (more flexible, better generalization, but require training data and feature engineering). Modern deep learning approaches automate feature extraction, achieving superior accuracy.
Rule-based systems need only pattern definitions. Traditional ML models require 300-500 labeled examples. Transformer-based models work with 800+ examples but benefit from transfer learning—pre-trained models can achieve good results with just 100-200 domain-specific examples through fine-tuning.
Key challenges include: ambiguity (same word meaning different things), out-of-vocabulary entities, domain adaptation (models trained on one domain fail on another), boundary detection errors, multilingual complexities, and data scarcity for specialized domains. These require careful system design and domain-specific tuning.
Context is crucial—'bank' means different things in 'river bank' vs. 'savings bank.' Modern transformers use self-attention to weigh context from all surrounding tokens, enabling them to disambiguate entities based on linguistic and semantic context. Poor context handling is a major source of errors in entity recognition.
Future developments include: large language models enabling zero-shot entity recognition, multimodal understanding combining text and images, real-time processing on edge devices, and domain-specific fine-tuning advances. Entity understanding will become an invisible foundation layer enabling machines to comprehend the world with human-like semantic understanding.
AmICited tracks entity mentions across AI systems like ChatGPT, Perplexity, and Google AI Overviews. Understand how AI understands and references your brand in real-time.
Entity Recognition is an AI NLP capability identifying and categorizing named entities in text. Learn how it works, its applications in AI monitoring, and its r...

Learn how AI systems identify, extract, and understand relationships between entities in text. Discover entity relationship extraction techniques, NLP methods, ...

Learn how to build entity visibility in AI search. Master knowledge graph optimization, schema markup, and entity SEO strategies to increase brand presence in C...