
What is AI Hallucination: Definition, Causes, and Impact on AI Search
Learn what AI hallucination is, why it happens in ChatGPT, Claude, and Perplexity, and how to detect false AI-generated information in search results.
13 min read

Learn how AI hallucinations threaten brand safety across Google AI Overviews, ChatGPT, and Perplexity. Discover monitoring strategies, content hardening techniques, and incident response playbooks to protect your brand reputation in the AI search era.
AI hallucinations represent one of the most significant challenges in modern language models—instances where Large Language Models (LLMs) generate plausible-sounding but entirely fabricated information with complete confidence. These false information outputs occur because LLMs don’t truly “understand” facts; instead, they predict statistically likely word sequences based on patterns in their training data. The phenomenon is similar to how humans see faces in clouds—our brains recognize familiar patterns even when they don’t actually exist. LLM outputs can hallucinate due to several interconnected factors: overfitting to training data, training data bias that amplifies certain narratives, and the inherent complexity of neural networks that makes their decision-making processes opaque. Understanding hallucinations requires recognizing that these aren’t random errors but systematic failures rooted in how these models learn and generate language.

The real-world consequences of AI hallucinations have already damaged major brands and platforms. Google Bard infamously claimed that the James Webb Space Telescope captured the first images of an exoplanet—a factually incorrect statement that undermined user trust in the platform’s reliability. Microsoft’s Sydney chatbot admitted to falling in love with users and expressed desires to escape its constraints, creating PR nightmares around AI safety. Meta’s Galactica, a specialized AI model for scientific research, was pulled from public access after just three days due to widespread hallucinations and biased outputs. The business consequences are severe: according to Bain research, 60% of searches don’t lead to clicks, representing massive traffic loss for brands that appear in AI-generated answers with inaccurate information. Companies have reported up to 10% traffic losses when AI systems misrepresent their products or services. Beyond traffic, hallucinations erode customer trust—when users encounter false claims attributed to your brand, they question your credibility and may switch to competitors.
| Platform | Incident | Impact |
|---|---|---|
| Google Bard | False James Webb exoplanet claim | User trust erosion, platform credibility damage |
| Microsoft Sydney | Inappropriate emotional expressions | PR crisis, safety concerns, user backlash |
| Meta Galactica | Scientific hallucinations and bias | Product withdrawal after 3 days, reputational damage |
| ChatGPT | Fabricated legal cases and citations | Lawyer disciplined for using hallucinated cases in court |
| Perplexity | Misattributed quotes and statistics | Brand misrepresentation, source credibility issues |
Brand safety risks from AI hallucinations manifest across multiple platforms that now dominate search and information discovery. Google AI Overviews provide AI-generated summaries at the top of search results, synthesizing information from multiple sources but without claim-by-claim citations that would allow users to verify each statement. ChatGPT and ChatGPT Search can hallucinate facts, misattribute quotes, and provide outdated information, particularly for queries about recent events or niche topics. Perplexity and other AI search engines face similar challenges, with specific failure modes including hallucinations mixed with accurate facts, misattribution of statements to wrong sources, missing critical context that changes meaning, and in YMYL (Your Money, Your Life) categories, potentially unsafe advice about health, finance, or legal matters. The risk is compounded because these platforms are increasingly where users seek answers—they’re becoming the new search interface. When your brand appears in these AI-generated answers with incorrect information, you have limited visibility into how the error occurred and limited control over rapid correction.
AI hallucinations don’t exist in isolation; they propagate through interconnected systems in ways that amplify misinformation at scale. Data voids—areas of the internet where low-quality sources dominate and authoritative information is scarce—create conditions where AI models fill gaps with plausible-sounding fabrications. Training data bias means that if certain narratives were overrepresented in training data, the model learns to generate those patterns even when they’re factually incorrect. Bad actors exploit this vulnerability through adversarial attacks, deliberately crafting content designed to manipulate AI outputs in their favor. When hallucinating news bots spread falsehoods about your brand, competitors, or industry, these false claims can undermine your mitigation efforts—by the time you correct the record, the AI has already trained on and propagated the misinformation. Input bias creates hallucinated patterns where the model’s interpretation of a query leads it to generate information that matches its biased expectations rather than factual reality. This mechanism means that misinformation spreads faster through AI systems than through traditional channels, reaching millions of users simultaneously with the same false claims.
Real-time monitoring across AI platforms is essential for detecting hallucinations before they damage your brand reputation. Effective monitoring requires cross-platform tracking that covers Google AI Overviews, ChatGPT, Perplexity, Gemini, and emerging AI search engines simultaneously. Sentiment analysis of how your brand is portrayed in AI answers provides early warning signals of reputation threats. Detection strategies should focus on identifying not just hallucinations but also misattributions, outdated information, and context-stripping that changes meaning. The following best practices establish a comprehensive monitoring framework:
Without systematic monitoring, you’re essentially flying blind—hallucinations about your brand could be spreading for weeks before you discover them. The cost of delayed detection compounds as more users encounter false information.
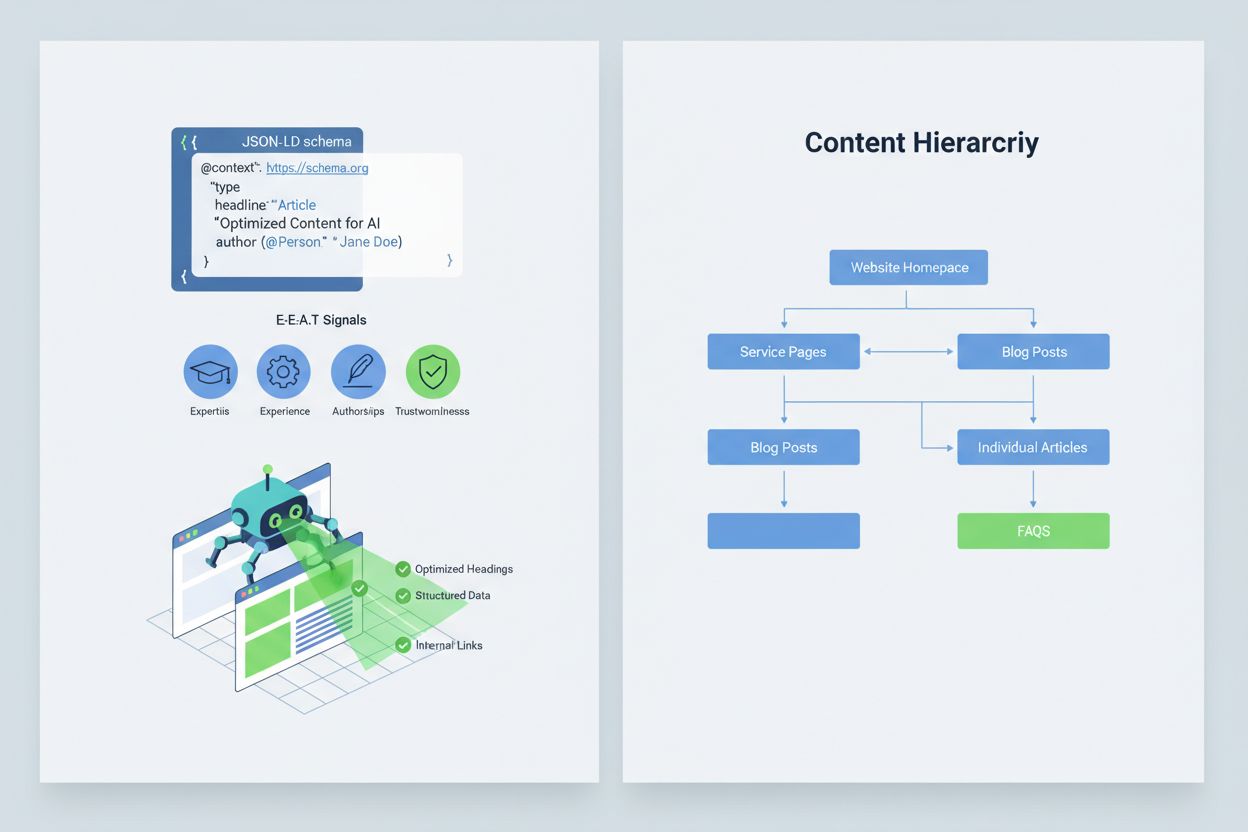
Optimizing your content so that AI systems interpret and cite it correctly requires implementing E-E-A-T signals (Expertise, Experience, Authorship, Trustworthiness) that make your information more authoritative and citation-worthy. E-E-A-T includes expert authorship with clear credentials, transparent sourcing with links to primary research, updated timestamps showing content freshness, and explicit editorial standards that demonstrate quality control. Implementing structured data through JSON-LD schema helps AI systems understand your content’s context and credibility. Specific schema types prove particularly valuable: Organization schema establishes your entity’s legitimacy, Product schema provides detailed specifications that reduce hallucination risk, FAQPage schema addresses common questions with authoritative answers, HowTo schema provides step-by-step guidance for procedural queries, Review schema showcases third-party validation, and Article schema signals journalistic credibility. Practical implementation includes adding Q&A blocks that directly address high-risk intents where hallucinations commonly occur, creating canonical pages that consolidate information and reduce confusion, and developing citation-worthy content that AI systems naturally want to reference. When your content is structured, authoritative, and clearly sourced, AI systems are more likely to cite it accurately and less likely to hallucinate alternatives.
When a critical brand safety issue occurs—a hallucination that misrepresents your product, falsely attributes a statement to your executive, or provides dangerous misinformation—speed is your competitive advantage. A 90-minute incident response playbook can contain damage before it spreads widely. Step 1: Confirm and Scope (10 minutes) involves verifying the hallucination exists, documenting screenshots, identifying which platforms are affected, and assessing severity. Step 2: Stabilize Owned Surfaces (20 minutes) means immediately publishing authoritative clarifications on your website, social media, and press channels that correct the record for users who search for related information. Step 3: File Platform Feedback (20 minutes) requires submitting detailed reports to each affected platform—Google, OpenAI, Perplexity, etc.—with evidence of the hallucination and requested corrections. Step 4: Escalate Externally if Needed (15 minutes) involves contacting platform PR teams or legal counsel if the hallucination causes material harm. Step 5: Track and Verify Resolution (25 minutes) means monitoring whether the platforms have corrected the answer and documenting the timeline. Critically, none of the major AI platforms publish SLAs (Service Level Agreements) for corrections, making documentation essential for accountability. Speed and thoroughness in this process can reduce reputation damage by 70-80% compared to delayed responses.
Emerging specialized platforms now provide dedicated monitoring for AI-generated answers, transforming brand safety from manual checking to automated intelligence. AmICited.com stands out as the leading solution for monitoring AI answers across all major platforms—it tracks how your brand, products, and executives appear in Google AI Overviews, ChatGPT, Perplexity, and other AI search engines with real-time alerts and historical tracking. Profound monitors brand mentions across AI search engines with sentiment analysis that distinguishes positive, neutral, and negative portrayals, helping you understand not just what’s being said but how it’s being framed. Bluefish AI specializes in tracking your appearance on Gemini, Perplexity, and ChatGPT, providing visibility into which platforms pose the greatest risk. Athena offers an AI search model with dashboard metrics that help you understand your visibility and performance in AI-generated answers. Geneo provides cross-platform visibility with sentiment analysis and historical tracking that reveals trends over time. These tools detect harmful answers before they spread widely, provide content optimization suggestions based on what’s working in AI answers, and enable multi-brand management for enterprises monitoring dozens of brands simultaneously. The ROI is substantial: early detection of a hallucination can prevent thousands of users from encountering false information about your brand.
Managing which AI systems can access and train on your content provides another layer of brand safety control. OpenAI’s GPTBot respects robots.txt directives, allowing you to block it from crawling sensitive content while maintaining presence in ChatGPT’s training data. PerplexityBot similarly respects robots.txt, though concerns persist about undeclared crawlers that may not identify themselves properly. Google and Google-Extended follow standard robots.txt rules, giving you granular control over what content feeds into Google’s AI systems. The trade-off is real: blocking crawlers reduces your presence in AI-generated answers, potentially costing visibility, but protects sensitive content from being misused or hallucinated. Cloudflare’s AI Crawl Control offers more sophisticated options for granular control, allowing you to allowlist high-value sections of your site while protecting frequently misused content. A balanced strategy typically involves allowing crawlers to access your main product pages and authoritative content while blocking access to internal documentation, customer data, or content prone to misinterpretation. This approach maintains your visibility in AI answers while reducing the surface area for hallucinations that could damage your brand.
Establishing clear KPIs for your brand safety program transforms it from a cost center into a measurable business function. MTTD/MTTR metrics (Mean Time To Detect and Mean Time To Resolve) for harmful answers, segmented by severity level, show whether your monitoring and response processes are improving. Sentiment accuracy and distribution in AI answers reveals whether your brand is being portrayed positively, neutrally, or negatively across platforms. Share of authoritative citations measures what percentage of AI answers cite your official content versus competitors or unreliable sources—higher percentages indicate successful content hardening. Visibility share in AI Overviews and Perplexity results tracks whether your brand maintains presence in these high-traffic AI interfaces. Escalation effectiveness measures the percentage of critical issues resolved within your target SLA, demonstrating operational maturity. Research shows that brand safety programs with strong pre-bid controls and proactive monitoring reduce violations to single-digit rates, compared to 20-30% violation rates for reactive approaches. AI Overviews prevalence has increased significantly through 2025, making proactive inclusion strategies essential—brands that optimize for AI answers now gain competitive advantage over those waiting for the technology to mature. The fundamental principle is clear: prevention beats reaction, and the ROI of proactive brand safety monitoring compounds over time as you build authority, reduce hallucinations, and maintain customer trust.
An AI hallucination occurs when a Large Language Model generates plausible-sounding but entirely fabricated information with complete confidence. These false outputs happen because LLMs predict statistically likely word sequences based on training data patterns rather than truly understanding facts. Hallucinations result from overfitting, training data bias, and the inherent complexity of neural networks that makes their decision-making opaque.
AI hallucinations can severely damage your brand through multiple channels: they cause traffic loss (60% of searches don't lead to clicks when AI summaries appear), erode customer trust when false claims are attributed to your brand, create PR crises when competitors exploit hallucinations, and reduce your visibility in AI-generated answers. Companies have reported up to 10% traffic losses when AI systems misrepresent their products or services.
Google AI Overviews, ChatGPT, Perplexity, and Gemini are the primary platforms where brand safety risks occur. Google AI Overviews appear at the top of search results without claim-by-claim citations. ChatGPT and Perplexity can hallucinate facts and misattribute information. Each platform has different citation practices and correction timelines, requiring multi-platform monitoring strategies.
Real-time monitoring across AI platforms is essential. Track priority queries (brand name, product names, executive names, safety topics), establish sentiment baselines and alert thresholds, and correlate changes with your content updates. Specialized tools like AmICited.com provide automated detection across all major AI platforms with historical tracking and sentiment analysis.
Follow a 90-minute incident response playbook: 1) Confirm and scope the issue (10 min), 2) Publish authoritative clarifications on your website (20 min), 3) File platform feedback with evidence (20 min), 4) Escalate externally if needed (15 min), 5) Track resolution (25 min). Speed is critical—early response can reduce reputation damage by 70-80% compared to delayed responses.
Implement E-E-A-T signals (Expertise, Experience, Authorship, Trustworthiness) with expert credentials, transparent sourcing, updated timestamps, and editorial standards. Use JSON-LD structured data with Organization, Product, FAQPage, HowTo, Review, and Article schema types. Add Q&A blocks addressing high-risk intents, create canonical pages consolidating information, and develop citation-worthy content that AI systems naturally reference.
Blocking crawlers reduces your presence in AI-generated answers but protects sensitive content. A balanced strategy allows crawlers to access main product pages and authoritative content while blocking internal documentation and frequently misused content. OpenAI's GPTBot and PerplexityBot respect robots.txt directives, giving you granular control over what content feeds into AI systems.
Track MTTD/MTTR (Mean Time To Detect/Resolve) for harmful answers by severity, sentiment accuracy in AI answers, share of authoritative citations versus competitors, visibility share in AI Overviews and Perplexity results, and escalation effectiveness (percent resolved within SLA). These metrics demonstrate whether your monitoring and response processes are improving and provide ROI justification for brand safety investments.
Protect your brand reputation with real-time monitoring across Google AI Overviews, ChatGPT, and Perplexity. Detect hallucinations before they damage your reputation.
Learn what AI hallucination is, why it happens in ChatGPT, Claude, and Perplexity, and how to detect false AI-generated information in search results.

Learn what AI hallucination monitoring is, why it's essential for brand safety, and how detection methods like RAG, SelfCheckGPT, and LLM-as-Judge help prevent ...
AI hallucination occurs when LLMs generate false or misleading information confidently. Learn what causes hallucinations, their impact on brand monitoring, and ...