
Evolving Your Metrics as AI Search Matures
Learn how to evolve your measurement frameworks as AI search matures. Discover citation-based metrics, AI visibility dashboards, and KPIs that matter for tracki...
12 min read

Discover how AI systems evaluate content quality beyond traditional SEO metrics. Learn about semantic understanding, factual accuracy, and quality signals that matter to LLMs and AI overviews.

For years, content creators have optimized for traditional SEO metrics—word count, keyword density, backlinks, and page speed. However, these surface-level indicators tell only part of the story when it comes to how AI systems evaluate content quality. Modern large language models (LLMs) like GPT-4, Claude, and Perplexity assess content through a fundamentally different lens: semantic understanding, factual accuracy, and contextual relevance. Rather than counting keywords, AI models analyze whether content truly conveys meaning, whether claims are verifiable, and whether information directly addresses user intent. This shift represents a paradigm change in how we should think about content quality in an AI-driven world.
Large language models employ sophisticated evaluation frameworks that go far beyond traditional metrics. These systems use multiple assessment dimensions, each capturing different aspects of content quality. Understanding these dimensions helps content creators align their work with how AI systems actually perceive and rank information.
| Quality Dimension | Traditional Metric | AI Evaluation Method | Importance |
|---|---|---|---|
| Semantic Meaning | Keyword frequency | Embedding similarity, contextual understanding | Critical |
| Factual Accuracy | Citation count | Faithfulness metrics, hallucination detection | Critical |
| Relevance | Keyword matching | Answer relevancy scoring, task alignment | Critical |
| Coherence | Readability score | Logical flow analysis, consistency checking | High |
| Structure | Heading count | Argument structure evaluation | High |
| Source Quality | Domain authority | Attribution verification, source grounding | High |
| Tone Alignment | Sentiment analysis | Intent matching, style consistency | Medium |
These evaluation methods—including BLEU, ROUGE, BERTScore, and embedding-based metrics—allow AI systems to assess content quality with remarkable precision. Rather than relying on simple word overlap, modern AI evaluation uses semantic similarity to understand whether different phrasings convey the same meaning, reference-free evaluation to assess intrinsic text qualities, and LLM-as-a-Judge approaches where advanced models evaluate outputs based on detailed rubrics.
One of the most significant differences between traditional and AI-based evaluation is how semantic meaning is assessed. Traditional metrics penalize paraphrasing and synonym usage, treating “departed quickly” and “left in a hurry” as completely different phrases. AI systems, however, recognize these as semantically equivalent through embedding-based evaluation. These systems convert text into high-dimensional vectors that capture meaning, allowing AI to understand that two sentences expressing the same idea should score similarly regardless of word choice.
This semantic understanding extends to contextual relevance—AI systems evaluate whether content fits within the broader context of a conversation or topic. A response might use completely different vocabulary than the original question, yet still be highly relevant if it addresses the underlying intent. AI models assess this through semantic similarity metrics that measure how closely the meaning of an answer aligns with what was asked, rather than checking for keyword matches. This capability means that well-written, naturally flowing content that thoroughly addresses a topic will score higher than keyword-stuffed content that technically contains the right terms but lacks coherence.
Perhaps the most critical quality signal for AI systems is factual accuracy. Unlike traditional SEO metrics that ignore truthfulness, modern AI evaluation frameworks specifically assess whether content contains verifiable facts or unsupported claims. AI systems use faithfulness metrics to determine whether statements are grounded in provided source material, and hallucination detection to identify when models or content creators fabricate information.
These evaluation methods work by comparing claims in content against authoritative sources or knowledge bases. If a piece of content states that “the capital of France is Paris,” AI systems verify this against their training data and external sources. More importantly, AI evaluates groundedness—whether claims are supported by the evidence provided. A summary that includes information not present in the original source material will score poorly on faithfulness metrics, even if the information is technically correct. This emphasis on factual accuracy means that content creators must ensure every claim is either common knowledge, properly cited, or clearly marked as opinion or speculation.
AI systems evaluate how well ideas connect and progress logically throughout content. Coherence assessment examines whether sentences flow naturally from one to the next, whether arguments build upon each other, and whether the overall structure makes sense. Content with clear topic sentences, logical paragraph organization, and smooth transitions between ideas scores higher on coherence metrics than rambling, disorganized content.
Logical flow is particularly important for complex topics. AI systems assess whether explanations progress from simple to complex, whether prerequisites are established before advanced concepts are introduced, and whether conclusions follow logically from the evidence presented. Well-structured content that guides readers through a clear progression of ideas demonstrates higher quality to AI evaluation systems than content that jumps between topics or repeats information unnecessarily.
AI systems evaluate whether content actually answers the question or fulfills the task it was designed for. Answer relevancy metrics measure how directly a response addresses the user’s query, with high scores going to content that stays focused on the topic and avoids tangential information. If someone asks “How do I fix a leaky faucet?” and receives a response about plumbing history, the content fails the relevancy test despite being well-written and factually accurate.
Task alignment extends this concept further—AI assesses whether the content matches the intended purpose and user intent. A technical tutorial should be detailed and precise; a quick reference guide should be concise and scannable; a persuasive article should present compelling arguments. Content that matches these expectations scores higher than content that misses the mark, regardless of other quality factors. This means understanding your audience and purpose is just as important to AI evaluation as writing quality itself.
AI systems place significant value on knowledge grounding—the practice of anchoring claims in authoritative sources. Content that cites reputable sources, provides proper attribution, and clearly distinguishes between established facts and interpretations scores higher on quality metrics. Contextual precision measures how well retrieved or cited sources actually support the claims made, while contextual recall assesses whether all relevant supporting information has been included.
Transparent attribution serves multiple purposes in AI evaluation. It demonstrates that the content creator has done research, it allows readers to verify claims independently, and it helps AI systems assess the reliability of information. Content that vaguely references “studies show” without providing specifics scores lower than content that cites specific research with authors, dates, and findings. This emphasis on source quality means that content creators should invest time in finding authoritative sources and properly attributing information.
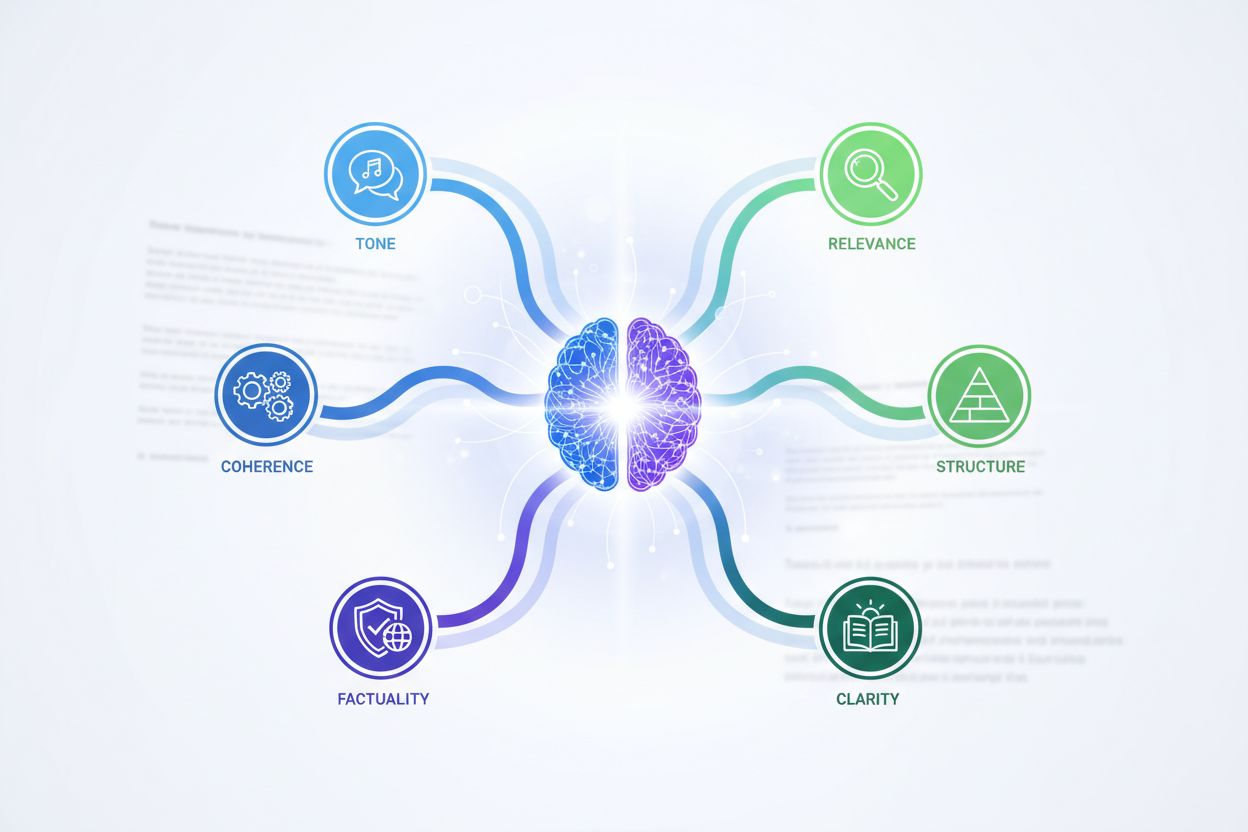
Beyond factual content, AI systems evaluate whether tone and style match user expectations and intent. A customer service response should be helpful and professional; a creative writing piece should match its genre; a technical document should be precise and formal. AI uses LLM-as-a-Judge approaches where advanced models evaluate whether tone is appropriate for the context and whether style choices enhance or detract from the message.
Consistency is another important factor—AI systems assess whether tone, terminology, and style remain consistent throughout a piece. Switching between formal and casual language, using different terms for the same concept, or changing perspective unexpectedly all signal lower quality to AI evaluation systems. Content that maintains a consistent voice and style throughout demonstrates higher quality than content that feels disjointed or inconsistent.
Understanding how AI evaluates content quality has concrete implications for how you should approach content creation. Here are actionable strategies for creating content that AI systems recognize as high-quality:
Focus on semantic clarity over keyword stuffing: Write naturally and comprehensively about your topic. Use varied vocabulary and synonyms rather than repeating the same keywords. AI systems understand meaning, not just word frequency.
Ensure factual accuracy and cite sources: Verify every claim you make and cite authoritative sources. Distinguish between facts, interpretations, and opinions. Provide specific citations rather than vague references.
Maintain logical structure and coherence: Organize content with clear headings, topic sentences, and smooth transitions. Progress from simple to complex ideas. Ensure each paragraph connects logically to the next.
Match content to user intent: Understand what your audience is actually looking for and deliver exactly that. Avoid tangential information or unnecessary elaboration that distracts from the core purpose.
Use consistent tone and style: Maintain a consistent voice throughout your content. Use the same terminology for the same concepts. Match your tone to your audience and purpose.
Provide comprehensive coverage: Address the topic thoroughly from multiple angles. Include relevant context, examples, and supporting evidence. Don’t leave important questions unanswered.
Optimize for readability and scannability: Use formatting (headings, bullet points, bold text) to make content easy to scan. Break up long paragraphs. Use white space effectively.
Demonstrate expertise and authority: Show that you understand your topic deeply. Provide insights that go beyond surface-level information. Reference relevant research and best practices.
As AI systems become increasingly important for content discovery and citation, understanding how your brand and content are recognized by these systems is crucial. AmICited.com provides essential monitoring of how AI systems—including GPTs, Perplexity, Google AI Overviews, and other LLM-based platforms—cite and reference your content and brand.
Rather than relying on traditional metrics that don’t capture AI recognition, AmICited tracks the specific quality signals that matter to modern AI systems. The platform monitors whether your content is cited as authoritative, how frequently AI systems reference your brand, and what context your content appears in across different AI platforms. This visibility is invaluable for understanding whether your content meets the quality standards that AI systems actually use for evaluation and citation.
By using AmICited, you gain insights into how AI perceives your content quality, which topics your brand is recognized for, and where you might improve to increase AI citations. This data-driven approach to understanding AI quality signals helps you refine your content strategy to align with how modern AI systems actually evaluate and recommend information. In an era where AI-driven search and discovery are increasingly important, monitoring your presence in these systems is as critical as traditional SEO monitoring once was.
AI systems focus on semantic understanding, factual accuracy, and contextual relevance rather than keyword frequency and backlinks. They use embedding-based metrics to understand meaning, faithfulness metrics to verify facts, and relevancy scoring to ensure content addresses user intent. This means well-written, comprehensive content that thoroughly addresses a topic scores higher than keyword-stuffed content.
Semantic similarity measures whether different phrasings convey the same meaning. AI systems use embedding-based evaluation to recognize that 'departed quickly' and 'left in a hurry' are semantically equivalent, even though they use different words. This matters because it means AI rewards natural, varied writing over keyword repetition, and recognizes paraphrasing as high-quality content.
AI systems use faithfulness metrics to compare claims in content against authoritative sources and knowledge bases. They assess whether statements are grounded in provided source material and whether information is supported by evidence. Content that includes unsupported claims or information not present in source material scores poorly on factual accuracy metrics.
AI systems value knowledge grounding—anchoring claims in authoritative sources. Content that cites reputable sources with proper attribution demonstrates research quality and allows AI systems to assess reliability. Transparent attribution also helps readers verify claims independently and signals to AI that the content creator has done thorough research.
AI systems evaluate logical flow and coherence by assessing whether ideas connect naturally, whether arguments build upon each other, and whether the overall structure makes sense. Use clear topic sentences, organize paragraphs logically, include smooth transitions between ideas, and progress from simple to complex concepts. Well-structured content with clear progression scores higher than disorganized content.
AI systems assess whether tone and style match user expectations and intent. Consistency is critical—maintaining the same voice, terminology, and style throughout content signals higher quality. Switching between formal and casual language, using different terms for the same concept, or changing perspective unexpectedly all lower quality scores in AI evaluation.
AmICited monitors how AI systems like GPTs, Perplexity, and Google AI Overviews cite and reference your content and brand. The platform tracks whether your content is recognized as authoritative, how frequently AI systems reference your brand, and what context your content appears in. This visibility helps you understand whether your content meets AI quality standards and where to improve.
Reference-based evaluation compares content against predefined ground truth answers, suitable for tasks with deterministic correct answers. Reference-free evaluation assesses intrinsic text qualities without comparison to specific references, essential for open-ended tasks. Modern AI systems use both approaches depending on the task, with reference-free evaluation becoming increasingly important for creative and conversational content.
Track how GPTs, Perplexity, and Google AI Overviews cite and reference your brand with AmICited's AI monitoring platform.
Learn how to evolve your measurement frameworks as AI search matures. Discover citation-based metrics, AI visibility dashboards, and KPIs that matter for tracki...
Learn how to set effective OKRs for AI visibility and GEO goals. Discover the three-tier measurement framework, brand mention tracking, and implementation strat...

Learn how to measure content performance in AI systems including ChatGPT, Perplexity, and other AI answer generators. Discover key metrics, KPIs, and monitoring...