AI Training Crawlers vs Search Crawlers: Understanding the Difference
Discover the critical differences between AI training crawlers and search crawlers. Learn how they impact your content visibility, optimization strategies, and AI citations.
Published on Jan 3, 2026.Last modified on Jan 3, 2026 at 3:24 am
Search engine crawlers like Googlebot and Bingbot are the backbone of traditional search engine operations. These automated bots systematically navigate the web, discovering and indexing content to determine what appears in search engine results pages (SERPs). Googlebot, operated by Google, is the most well-known and active search crawler, followed by Bingbot from Microsoft and YandexBot from Yandex. These crawlers possess sophisticated capabilities that allow them to execute JavaScript, render dynamic content, and understand complex website structures. They visit websites frequently based on factors like site authority, content freshness, and update history, with high-authority sites receiving more frequent crawls. The primary goal of search crawlers is to index content for ranking purposes, meaning they evaluate pages based on relevance, quality, and user experience signals.
Crawler Type
Primary Purpose
JavaScript Support
Crawl Frequency
Goal
Googlebot
Index for search rankings
Yes (with limitations)
Frequent, based on authority
Ranking & visibility
Bingbot
Index for search rankings
Yes (with limitations)
Regular, based on content updates
Ranking & visibility
YandexBot
Index for search rankings
Yes (with limitations)
Regular, based on site signals
Ranking & visibility
What Are AI Training Crawlers?
AI training crawlers represent a fundamentally different category of web bots designed to collect data for training large language models (LLMs) rather than for search indexing. GPTBot, operated by OpenAI, is the most prominent AI training crawler, alongside ClaudeBot from Anthropic, PetalBot from Huawei, and Common Crawl’s CCBot. Unlike search crawlers that aim to rank content, AI training crawlers focus on gathering high-quality, contextually rich information to improve the knowledge base and response generation capabilities of AI models. These crawlers typically operate with less frequency than search crawlers, often visiting a website only once every few weeks or months, and they prioritize content quality over volume. The distinction is crucial: while your content might be thoroughly indexed by Googlebot for search visibility, it may only be partially or infrequently crawled by GPTBot for AI model training.
Crawler Type
Primary Purpose
JavaScript Support
Crawl Frequency
Goal
GPTBot
Collect data for LLM training
No
Infrequent, selective
Training data quality
ClaudeBot
Collect data for LLM training
No
Infrequent, selective
Training data quality
PetalBot
Collect data for LLM training
No
Infrequent, selective
Training data quality
CCBot
Collect data for Common Crawl
No
Infrequent, selective
Training data quality
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
The technical distinctions between search and AI training crawlers create significant implications for content visibility. The most critical difference is JavaScript execution: search crawlers like Googlebot can execute JavaScript (though with some limitations), allowing them to see dynamically rendered content. AI training crawlers, conversely, do not execute JavaScript at all—they only parse the raw HTML available on initial page load. This fundamental difference means that content loaded dynamically through client-side scripts remains completely invisible to AI crawlers. Additionally, search crawlers respect crawl budgets and prioritize pages based on site architecture and internal linking, while AI crawlers employ more selective, quality-driven crawling patterns. Search crawlers generally follow robots.txt guidelines strictly, whereas some AI crawlers have historically been less transparent about their compliance. The crawl frequency differs dramatically: search crawlers visit active sites multiple times per week or even daily, while AI training crawlers may visit only once every few weeks or months. Furthermore, search crawlers are designed to understand ranking signals and user experience metrics, while AI crawlers focus on extracting clean, well-structured text content for model training.
Feature
Search Crawlers
AI Training Crawlers
JavaScript Execution
Yes (with limitations)
No
Crawl Frequency
High (multiple times per week)
Low (once every few weeks)
Content Parsing
Full page rendering
Raw HTML only
Robots.txt Compliance
Strict
Variable
Crawl Budget Focus
Authority-based prioritization
Quality-based selection
Dynamic Content Handling
Can render and index
Misses entirely
Primary Goal
Ranking & search visibility
Training data collection
Timeout Tolerance
Longer (allows complex rendering)
Tight (1-5 seconds)
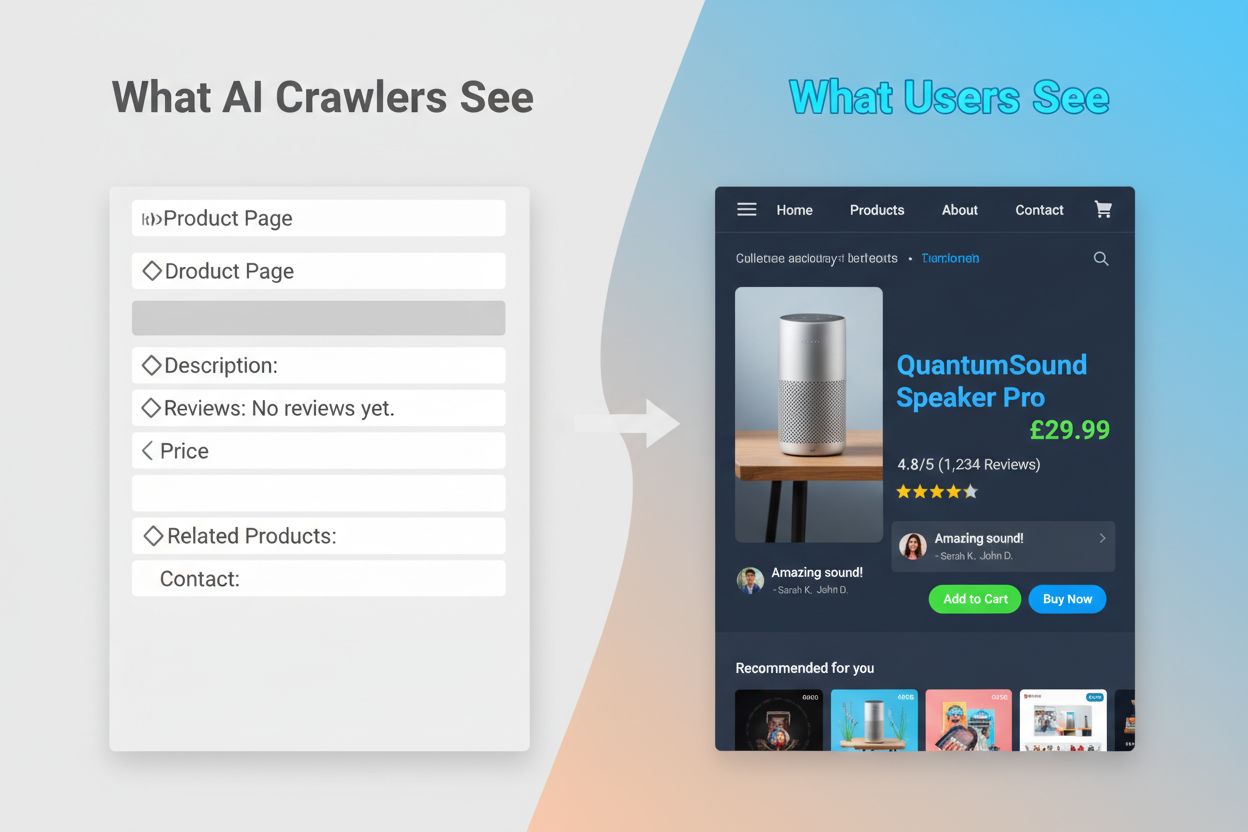
The JavaScript Problem
The inability of AI crawlers to execute JavaScript creates a critical visibility gap that affects many modern websites. When a website relies on JavaScript to load content dynamically—such as product descriptions, customer reviews, pricing information, or images—that content becomes invisible to AI crawlers. This is particularly problematic for single-page applications (SPAs) built with React, Vue, or Angular, where most content loads client-side after the initial HTML is served. For example, an ecommerce site might display product availability and pricing through JavaScript, meaning GPTBot sees only a blank page or basic HTML skeleton. Similarly, websites using lazy-loading for images or infinite scroll for content will have those elements completely missed by AI crawlers. The business impact is substantial: if your product details, customer testimonials, or key content are hidden behind JavaScript, AI systems like ChatGPT and Perplexity won’t have access to that information when generating answers. This creates a situation where your content might rank well in Google but be completely absent from AI-generated responses, effectively making you invisible to a growing segment of users who rely on AI for information discovery.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Search Crawlers vs AI Crawlers: Practical Implications
The practical consequences of these technical differences are profound and often misunderstood by website owners. Your website could achieve excellent rankings in Google while simultaneously being nearly invisible to ChatGPT, Perplexity, and other AI systems. This creates a paradoxical situation where traditional SEO success doesn’t guarantee AI visibility. When users ask ChatGPT a question about your industry or product, the AI system may cite your competitors instead of you, simply because their content was more accessible to AI crawlers. The relationship between training data and search citations adds another layer of complexity: content that was used to train an AI model may receive preferential treatment in that model’s search results, meaning blocking AI training crawlers could potentially reduce your visibility in AI-powered answers. For publishers and content creators, this means the strategic decision to allow or block AI crawlers has real consequences for future traffic. A website that blocks GPTBot to protect content from being used for training might simultaneously reduce its chances of appearing in ChatGPT’s search results. Conversely, allowing AI crawlers to access your content provides training data but doesn’t guarantee citations or traffic, creating a genuine strategic dilemma with no perfect solution.
Monitoring and Identifying Crawler Activity
Understanding which crawlers are accessing your website and how frequently they visit is essential for optimizing your content strategy. Log file analysis is the primary method for identifying crawler activity, allowing you to segment and parse server logs to see which bots accessed your site, how often they visited, and which pages they prioritized. By examining User-Agent strings in your server logs, you can distinguish between Googlebot, GPTBot, OAI-SearchBot, and other crawlers, revealing patterns in their behavior. Key metrics to monitor include crawl frequency (how often each crawler visits), crawl depth (how many layers of your site structure are being crawled), and crawl budget (the total number of pages crawled in a given time period). Tools like Google Search Console and Bing Webmaster Tools provide insights into search crawler activity, while specialized solutions like AmICited.com offer comprehensive monitoring of AI crawler behavior across multiple platforms including ChatGPT, Perplexity, and Google AI Overviews. AmICited.com specifically tracks how AI systems reference your brand and content, providing visibility into which AI platforms are citing you and how frequently. Understanding these patterns helps you identify technical issues early, optimize your crawl budget allocation, and make informed decisions about crawler access and content optimization.
Optimization Strategies for Search Crawlers
Optimizing for traditional search crawlers requires focusing on established technical SEO fundamentals that ensure your content is discoverable and indexable. The following strategies remain essential for maintaining strong search visibility:
Improve crawlability by creating clear internal linking structures, eliminating broken links, and avoiding orphaned pages that crawlers can’t reach
Submit XML sitemaps to search engines to guide crawlers to your most valuable content and ensure comprehensive indexing
Implement structured data using schema markup to help search engines better understand your content’s context and meaning
Optimize page speed to ensure crawlers can efficiently process your site without timing out or skipping pages
Prioritize important content in your site architecture so crawlers encounter and crawl your most valuable pages first
Use robots.txt strategically to block low-value pages and preserve crawl budget for high-priority content
Maintain fresh, high-quality content that signals to crawlers that your site is active and worth frequent revisits
Search engines like Google are increasingly focused on crawl efficiency, with Google representatives indicating that Googlebot will crawl less in the future. This means your website should be as streamlined and easy to understand as possible, with clear hierarchies and efficient internal linking that guides crawlers directly to your most important pages.
Optimization Strategies for AI Training Crawlers
Optimizing for AI training crawlers requires a different approach focused on content quality, clarity, and accessibility rather than ranking signals. Since AI crawlers prioritize well-structured, contextually rich content, your optimization strategy should emphasize comprehensiveness and readability. Avoid JavaScript-dependent content for critical information—ensure product details, pricing, reviews, and key data are present in raw HTML where AI crawlers can access them. Create comprehensive, in-depth content that covers topics thoroughly and provides context that AI models can learn from. Use clear formatting with headers, bullet points, and numbered lists that break up text and make content easily parseable. Write with semantic clarity using straightforward language without excessive jargon that might confuse AI models. Implement proper heading hierarchy (H1, H2, H3) to help AI crawlers understand content structure and relationships. Include relevant metadata and schema markup that provides context about your content. Ensure fast page load times since AI crawlers have tight timeouts (typically 1-5 seconds) and may skip slow pages entirely.
The key difference from search optimization is that AI crawlers don’t care about ranking signals, backlinks, or keyword density. Instead, they value content that is clear, well-organized, and information-rich. A page that might not rank well in Google could be highly valuable to AI models if it contains comprehensive, well-structured information on a topic.
The Future of Crawler Management
The landscape of web crawling is evolving rapidly, with AI crawlers becoming increasingly important for content visibility and brand awareness. As AI-powered search tools like ChatGPT, Perplexity, and Google AI Overviews continue to gain user adoption, the ability to be discovered and cited by these systems will become as critical as traditional search rankings. The distinction between training crawlers and search crawlers will likely become more nuanced, with companies potentially offering clearer separation between data collection and search retrieval, similar to OpenAI’s approach with GPTBot and OAI-SearchBot. Website owners will need to develop strategies that balance traditional SEO optimization with AI visibility, recognizing that these are complementary rather than competing objectives. The emergence of specialized monitoring tools and solutions will make it easier to track crawler activity across both traditional and AI platforms, enabling data-driven decisions about crawler access and content optimization. Early adopters who optimize for both search and AI crawlers now will gain a competitive advantage, positioning their content to be discovered through multiple channels as the search landscape continues to evolve. The future of content visibility depends on understanding and optimizing for the full spectrum of crawlers that discover and use your content.
Frequently asked questions
What's the main difference between search crawlers and AI training crawlers?
Search crawlers like Googlebot index content for search rankings and can execute JavaScript to see dynamic content. AI training crawlers like GPTBot collect data to train LLMs and typically cannot execute JavaScript, making them miss dynamically loaded content. This fundamental difference means your website could rank well in Google while being nearly invisible to ChatGPT.
Can I block AI training crawlers without affecting my search rankings?
Yes, you can use robots.txt to block specific AI crawlers like GPTBot while allowing search crawlers. However, this may reduce your visibility in AI-generated answers and summaries. The strategic tradeoff depends on whether you prioritize content protection over potential AI referral traffic.
Why can't AI crawlers see my JavaScript content?
AI crawlers like GPTBot only parse raw HTML on initial page load and don't execute JavaScript. Content loaded dynamically via scripts—such as product details, reviews, or images—remains completely invisible to them. This is a critical limitation for modern websites that rely heavily on client-side rendering.
How often do AI training crawlers visit my website?
AI training crawlers typically visit less frequently than search crawlers, with longer intervals between visits. They prioritize high-authority content and may crawl a page only once every few weeks or months. This infrequent crawling pattern reflects their focus on quality over volume.
What content is most at risk of being invisible to AI crawlers?
Product details, customer reviews, lazy-loaded images, interactive elements (tabs, carousels, modals), pricing information, and any content hidden behind JavaScript are most vulnerable. For ecommerce and SPA-based websites, this can represent a significant portion of critical content.
How can I optimize my website for both search and AI crawlers?
Ensure key content is present in raw HTML, improve site speed, use clear structure and formatting with proper heading hierarchy, implement schema markup, and avoid JavaScript-dependent critical content. The goal is to make your content accessible to both traditional and AI crawlers.
What tools can help me monitor crawler activity on my site?
Log file analysis tools, Google Search Console, Bing Webmaster Tools, and specialized crawler monitoring solutions like AmICited.com can help track crawler behavior. AmICited.com specifically monitors how AI systems reference your brand across ChatGPT, Perplexity, and Google AI Overviews.
Will blocking AI crawlers hurt my AI referral traffic?
Potentially yes. While blocking training crawlers may protect your content, it could reduce your visibility in AI-powered search results and summaries. Additionally, content that was already crawled before blocking remains in trained models. The decision requires balancing content protection against potential loss of AI-driven discovery.
Monitor Your AI Crawler Activity with AmICited
Track how AI systems reference your brand across ChatGPT, Perplexity, and Google AI Overviews. Get real-time insights into your AI visibility and optimize your content strategy.
How to Allow AI Bots to Crawl Your Website: Complete robots.txt & llms.txt Guide
Learn how to allow AI bots like GPTBot, PerplexityBot, and ClaudeBot to crawl your site. Configure robots.txt, set up llms.txt, and optimize for AI visibility.
AI Crawlers Explained: GPTBot, ClaudeBot, and More
Understand how AI crawlers like GPTBot and ClaudeBot work, their differences from traditional search crawlers, and how to optimize your site for AI search visib...
What AI Crawlers Should I Allow Access? Complete Guide for 2025
Learn which AI crawlers to allow or block in your robots.txt. Comprehensive guide covering GPTBot, ClaudeBot, PerplexityBot, and 25+ AI crawlers with configurat...
10 min read
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.