
The Complete Guide to Blocking (or Allowing) AI Crawlers
Learn how to block or allow AI crawlers like GPTBot and ClaudeBot using robots.txt, server-level blocking, and advanced protection methods. Complete technical g...
7 min read
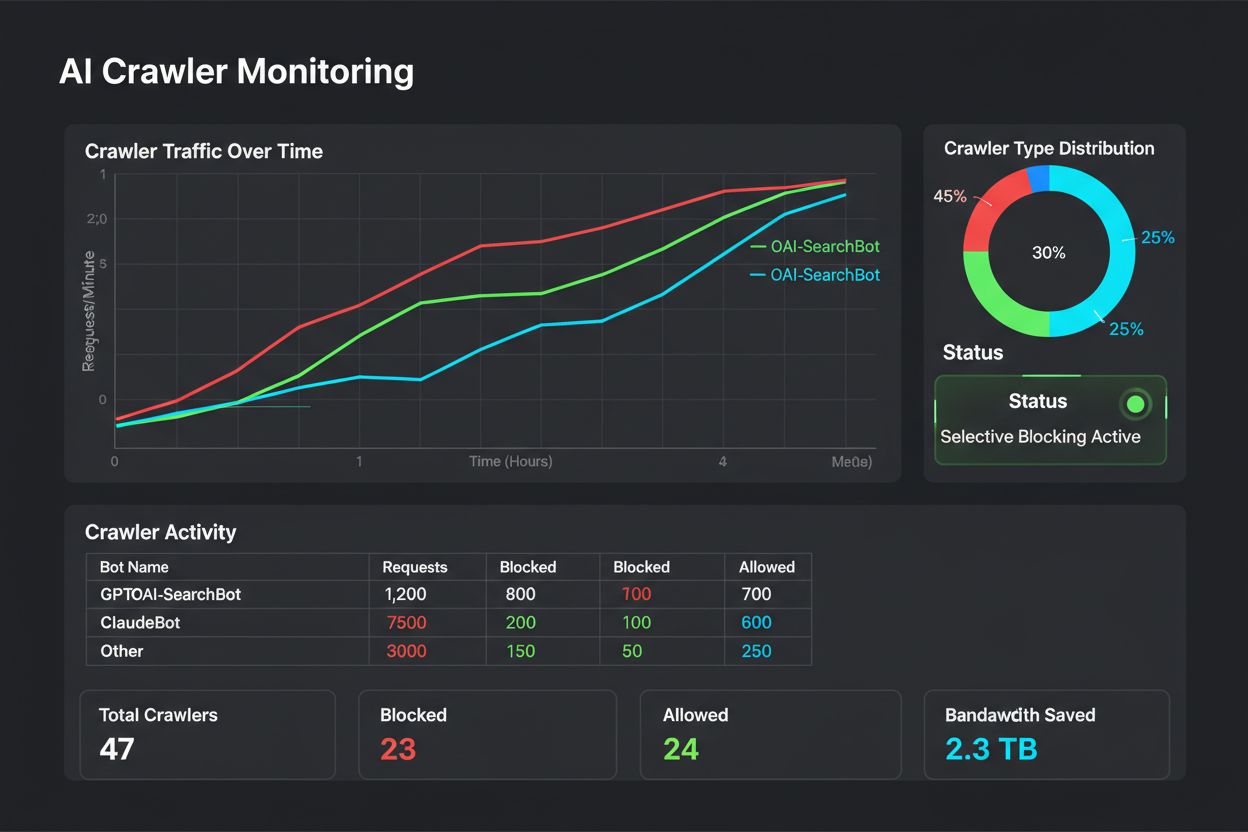
Learn how to implement selective AI crawler blocking to protect your content from training bots while maintaining visibility in AI search results. Technical strategies for publishers.
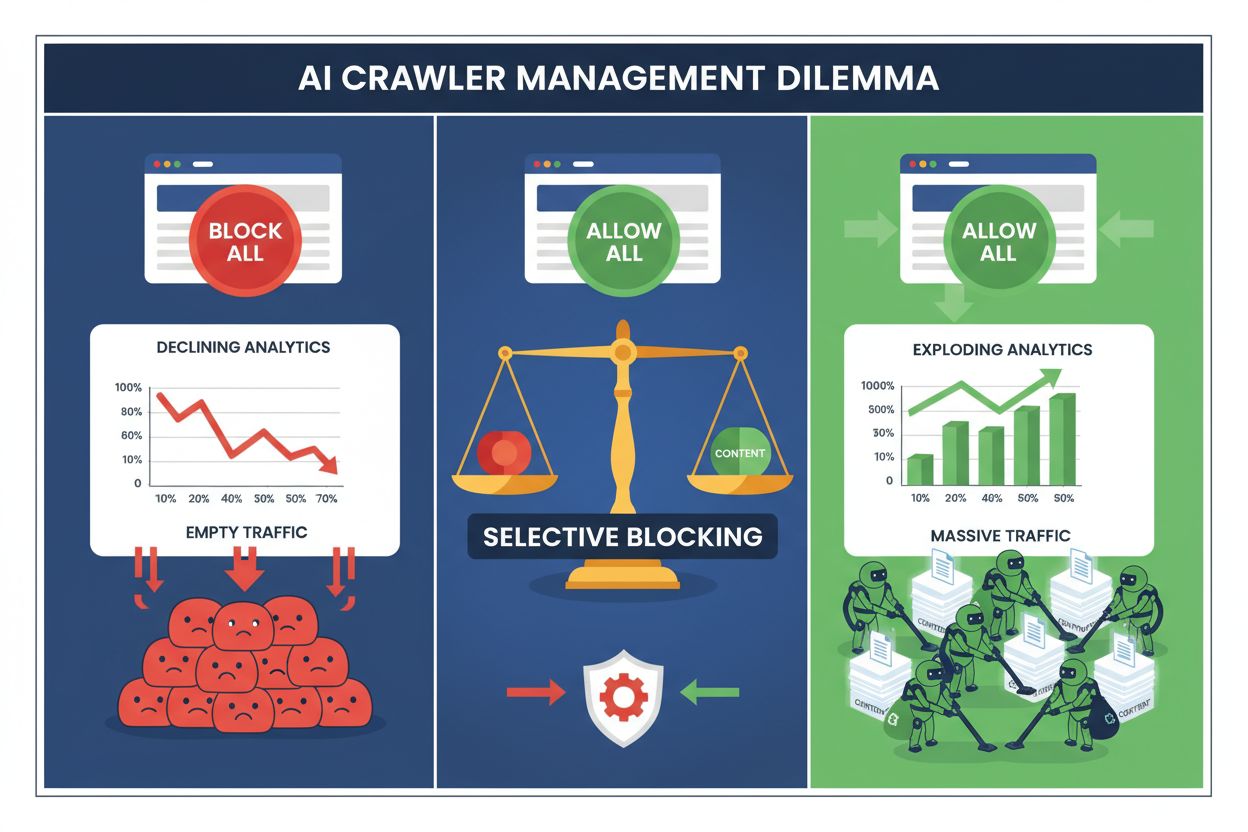
Publishers today face an impossible choice: block all AI crawlers and lose valuable search engine traffic, or allow them all and watch their content fuel training datasets without compensation. The rise of generative AI has created a bifurcated crawler ecosystem where the same robots.txt rules apply indiscriminately to both search engines that drive revenue and training crawlers that extract value. This paradox has forced forward-thinking publishers to develop selective crawler control strategies that distinguish between different types of AI bots based on their actual impact on business metrics.
The AI crawler landscape divides into two distinct categories with vastly different purposes and business implications. Training crawlers—operated by companies like OpenAI, Anthropic, and Google—are designed to ingest massive amounts of text data to build and improve large language models, while search crawlers index content for retrieval and discovery. Training bots account for approximately 80% of all AI-related bot activity, yet they generate zero direct revenue for publishers, whereas search crawlers like Googlebot and Bingbot drive millions of visits and advertising impressions annually. The distinction matters because a single training crawler can consume bandwidth equivalent to thousands of human users, while search crawlers are optimized for efficiency and typically respect rate limits.
| Bot Name | Operator | Primary Purpose | Traffic Potential |
|---|---|---|---|
| GPTBot | OpenAI | Model training | None (data extraction) |
| Claude Web Crawler | Anthropic | Model training | None (data extraction) |
| Googlebot | Search indexing | 243.8M visits (April 2025) | |
| Bingbot | Microsoft | Search indexing | 45.2M visits (April 2025) |
| Perplexity Bot | Perplexity AI | Search + training | 12.1M visits (April 2025) |
The data is stark: ChatGPT’s crawler alone sent 243.8 million visits to publishers in April 2025, but these visits generated zero clicks, zero ad impressions, and zero revenue. Meanwhile, Googlebot’s traffic converted to actual user engagement and monetization opportunities. Understanding this distinction is the first step toward implementing a selective blocking strategy that protects your content while preserving your search visibility.
Blanket blocking of all AI crawlers is economically self-destructive for most publishers. While training crawlers extract value without compensation, search crawlers remain one of the most reliable traffic sources in an increasingly fragmented digital landscape. The financial case for selective blocking rests on several key factors:
Publishers who implement selective blocking strategies report maintaining or improving search traffic while reducing unauthorized content extraction by up to 85%. The strategic approach acknowledges that not all AI crawlers are created equal, and that a nuanced policy serves business interests far better than a scorched-earth approach.
The robots.txt file remains the primary mechanism for communicating crawler permissions, and it’s surprisingly effective at distinguishing between different bot types when properly configured. This simple text file, placed in your website’s root directory, uses user-agent directives to specify which crawlers can access which content. For selective AI crawler control, you can allow search engines while blocking training crawlers with surgical precision.
Here’s a practical example that blocks training crawlers while allowing search engines:
# Block OpenAI's GPTBot
User-agent: GPTBot
Disallow: /
# Block Anthropic's Claude crawler
User-agent: Claude-Web
Disallow: /
# Block other training crawlers
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Allow search engines
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
This approach provides clear instructions to well-behaved crawlers while maintaining your site’s discoverability in search results. However, robots.txt is fundamentally a voluntary standard—it relies on crawler operators respecting your directives. For publishers concerned about compliance, additional enforcement layers are necessary.
Robots.txt alone cannot guarantee compliance because approximately 13% of AI crawlers ignore robots.txt directives entirely, either through negligence or deliberate circumvention. Server-level enforcement using your web server or application layer provides a technical backstop that prevents unauthorized access regardless of crawler behavior. This approach blocks requests at the HTTP level before they consume significant bandwidth or resources.
Implementing server-level blocking with Nginx is straightforward and highly effective:
# In your Nginx server block
location / {
# Block training crawlers at the server level
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Block by IP ranges if needed (for crawlers that spoof user agents)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Continue with normal request processing
proxy_pass http://backend;
}
This configuration returns a 403 Forbidden response to blocked crawlers, consuming minimal server resources while clearly communicating that access is denied. Combined with robots.txt, server-level enforcement creates a two-layer defense that catches both compliant and non-compliant crawlers. The 13% bypass rate drops to near-zero when server-level rules are properly implemented.
Content Delivery Networks and Web Application Firewalls provide an additional enforcement layer that operates before requests reach your origin servers. Services like Cloudflare, Akamai, and AWS WAF allow you to create rules that block specific user agents or IP ranges at the edge, preventing malicious or unwanted crawlers from consuming your infrastructure resources. These services maintain updated lists of known training crawler IP ranges and user agents, automatically blocking them without requiring manual configuration.
CDN-level controls offer several advantages over server-level enforcement: they reduce origin server load, provide geographic blocking capabilities, and offer real-time analytics on blocked requests. Many CDN providers now offer AI-specific blocking rules as standard features, recognizing the widespread publisher concern about unauthorized training data extraction. For publishers using Cloudflare, enabling the “Block AI Crawlers” option in security settings provides one-click protection against major training crawlers while maintaining search engine access.
Effective selective blocking requires a systematic approach to classifying crawlers based on their business impact and trustworthiness. Rather than treating all AI crawlers identically, publishers should implement a three-tier framework that reflects the actual value and risk each crawler presents. This framework allows for nuanced decision-making that balances content protection with business opportunity.
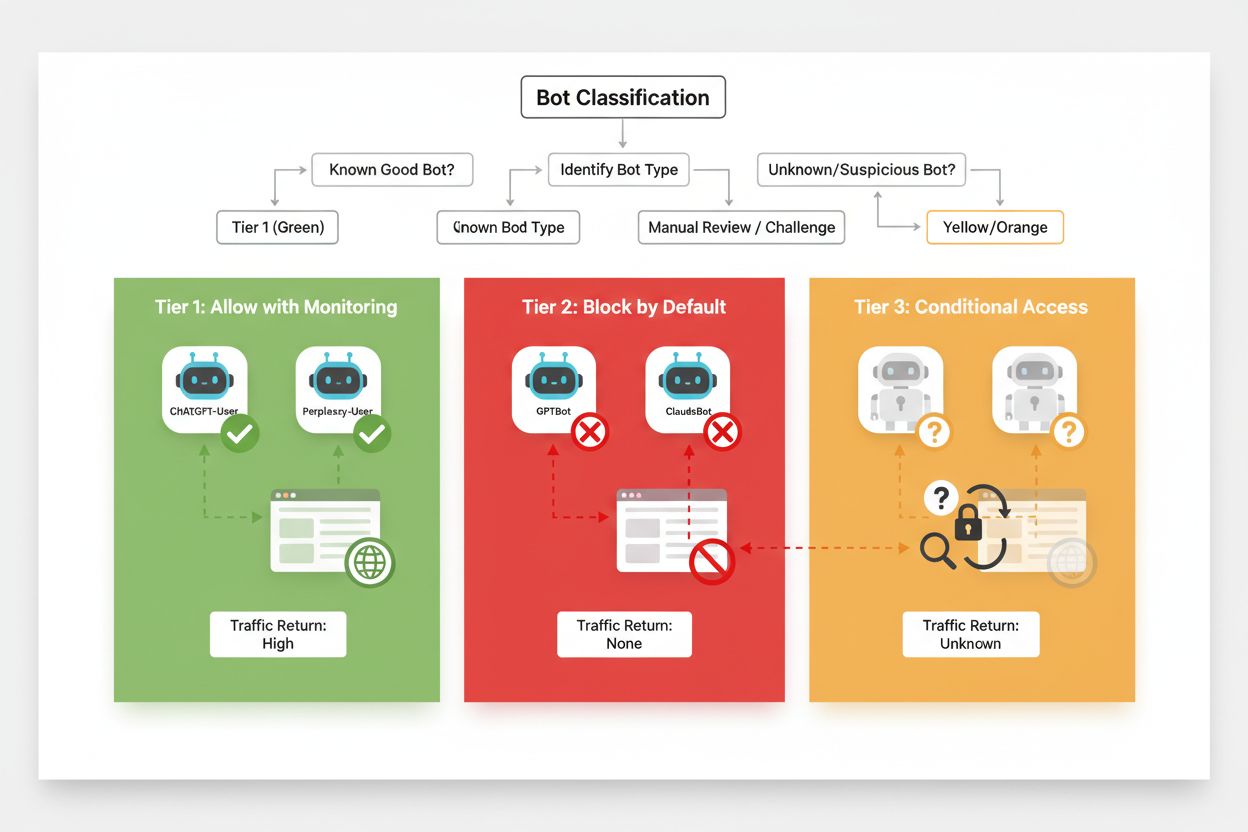
| Tier | Classification | Examples | Action |
|---|---|---|---|
| Tier 1: Revenue Generators | Search engines and high-traffic referral sources | Googlebot, Bingbot, Perplexity Bot | Allow all access; optimize for crawlability |
| Tier 2: Neutral/Unproven | New or emerging crawlers with unclear intent | Smaller AI startups, research bots | Monitor closely; allow with rate limiting |
| Tier 3: Value Extractors | Training crawlers with no direct benefit | GPTBot, Claude-Web, CCBot | Block completely; enforce at multiple layers |
Implementing this framework requires ongoing research into new crawlers and their business models. Publishers should regularly audit their access logs to identify new bots, research their operators’ terms of service and compensation policies, and adjust classifications accordingly. A crawler that starts as Tier 3 might move to Tier 2 if its operator begins offering revenue-sharing arrangements, while a previously trusted crawler might drop to Tier 3 if it begins violating rate limits or robots.txt directives.
Selective blocking is not a set-and-forget configuration—it requires ongoing monitoring and adjustment as the crawler ecosystem evolves. Publishers should implement comprehensive logging and analysis to track which crawlers are accessing their content, how much bandwidth they consume, and whether they’re respecting configured restrictions. This data informs strategic decisions about which crawlers to allow, block, or rate-limit.
Analyzing your access logs reveals crawler behavior patterns that inform policy adjustments:
# Identify all AI crawlers accessing your site
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Calculate bandwidth consumed by specific crawlers
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandwidth: " sum/1024/1024 " MB"}'
# Monitor 403 responses to blocked crawlers
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Regular analysis of this data—ideally weekly or monthly—reveals whether your blocking strategy is working as intended, whether new crawlers have appeared, and whether any previously blocked crawlers have changed their behavior. This information feeds back into your classification framework, ensuring your policies remain aligned with business objectives and technical reality.
Publishers implementing selective crawler blocking frequently make mistakes that undermine their strategy or create unintended consequences. Understanding these pitfalls helps you avoid costly errors and implement a more effective policy from the start.
Blocking all crawlers indiscriminately: The most common mistake is using overly broad blocking rules that catch search engines along with training crawlers, destroying search visibility in an attempt to protect content.
Relying solely on robots.txt: Assuming that robots.txt alone will prevent unauthorized access ignores the 13% of crawlers that ignore it entirely, leaving your content vulnerable to determined data extraction.
Failing to monitor and adjust: Implementing a static blocking policy and never revisiting it means missing new crawlers, failing to adapt to changing business models, and potentially blocking beneficial crawlers that have improved their practices.
Blocking by user agent alone: Sophisticated crawlers spoof user agents or rotate them frequently, making user-agent-based blocking ineffective without supplementary IP-based rules and rate limiting.
Ignoring rate limiting: Even allowed crawlers can consume excessive bandwidth if not rate-limited, degrading performance for human users and consuming infrastructure resources unnecessarily.
The future of publisher-AI crawler relationships will likely involve more sophisticated negotiation and compensation models rather than simple blocking. However, until industry standards emerge, selective crawler control remains the most practical approach for protecting content while maintaining search visibility. Publishers should view their blocking strategy as a dynamic policy that evolves with the crawler ecosystem, regularly reassessing which crawlers deserve access based on their business impact and trustworthiness.
The most successful publishers will be those who implement layered defenses—combining robots.txt directives, server-level enforcement, CDN controls, and ongoing monitoring into a comprehensive strategy. This approach protects against both compliant and non-compliant crawlers while preserving the search engine traffic that drives revenue and user engagement. As AI companies increasingly recognize the value of publisher content and begin offering compensation or licensing arrangements, the framework you build today will easily adapt to accommodate new business models while maintaining control over your digital assets.
Training crawlers like GPTBot and ClaudeBot collect data to build AI models without returning traffic to your site. Search crawlers like OAI-SearchBot and PerplexityBot index content for AI search engines and can drive significant referral traffic back to your site. Understanding this distinction is crucial for implementing an effective selective blocking strategy.
Yes, this is the core strategy of selective crawler control. You can use robots.txt to disallow training bots while allowing search bots, then enforce with server-level controls for bots that ignore robots.txt. This approach protects your content from unauthorized training while maintaining visibility in AI search results.
Most major AI companies claim to respect robots.txt, but compliance is voluntary. Research shows approximately 13% of AI bots bypass robots.txt directives entirely. This is why server-level enforcement is essential for publishers serious about protecting their content from non-compliant crawlers.
Significant and growing. ChatGPT sent 243.8 million visits to 250 news and media websites in April 2025, up 98% from January. Blocking these crawlers means losing this emerging traffic source. For many publishers, AI search traffic now represents 5-15% of total referral traffic.
Parse your server logs regularly using grep commands to identify bot user agents, track crawl frequency, and monitor compliance with your robots.txt rules. Review logs at least monthly to identify new bots, unusual behavior patterns, and whether blocked bots are actually staying out. This data informs strategic decisions about your crawler policy.
You protect your content from unauthorized training but lose visibility in AI search results, miss emerging traffic sources, and potentially reduce brand mentions in AI-generated answers. Publishers who implement blanket blocks often see 40-60% reductions in search visibility and miss opportunities for brand discovery through AI platforms.
At least monthly, as new bots emerge constantly and existing bots evolve their behavior. The AI crawler landscape changes rapidly, with new operators launching crawlers and existing players merging or renaming their bots. Regular reviews ensure your policy remains aligned with business objectives and technical reality.
It's the number of pages crawled versus visitors sent back to your site. Anthropic crawls 38,000 pages for every visitor referred back, while OpenAI maintains a ratio of 1,091:1, and Perplexity sits at 194:1. Lower ratios indicate better value for allowing the crawler. This metric helps you decide which crawlers deserve access based on their actual business impact.
AmICited tracks which AI platforms cite your brand and content. Get insights into your AI visibility and ensure proper attribution across ChatGPT, Perplexity, Google AI Overviews, and more.
Learn how to block or allow AI crawlers like GPTBot and ClaudeBot using robots.txt, server-level blocking, and advanced protection methods. Complete technical g...

Learn how Web Application Firewalls provide advanced control over AI crawlers beyond robots.txt. Implement WAF rules to protect your content from unauthorized A...

Learn how to audit AI crawler access to your website. Discover which bots can see your content and fix blockers preventing AI visibility in ChatGPT, Perplexity,...