
How to Handle Duplicate Content for AI Search Engines
Learn how to manage and prevent duplicate content when using AI tools. Discover canonical tags, redirects, detection tools, and best practices for maintaining u...
12 min read

Learn how canonical URLs prevent duplicate content problems in AI search systems. Discover best practices for implementing canonicals to improve AI visibility and ensure proper content attribution.
Large language models and AI search systems employ sophisticated clustering algorithms to identify and group near-duplicate URLs, treating multiple versions of the same content as a single entity for ranking and citation purposes. When AI systems encounter duplicate content, they must select which version to prioritize—a decision that directly impacts which URL receives visibility, authority signals, and user attribution. The critical problem emerges when AI selects the wrong version: if your canonical URL points to the preferred page but the AI system clusters and ranks a lower-quality duplicate instead, your content loses visibility and citation credit. Intent signals become diluted across duplicate versions, fragmenting the authority that should consolidate on a single URL, causing each duplicate to receive weaker ranking signals than if all authority had been unified on the canonical version.
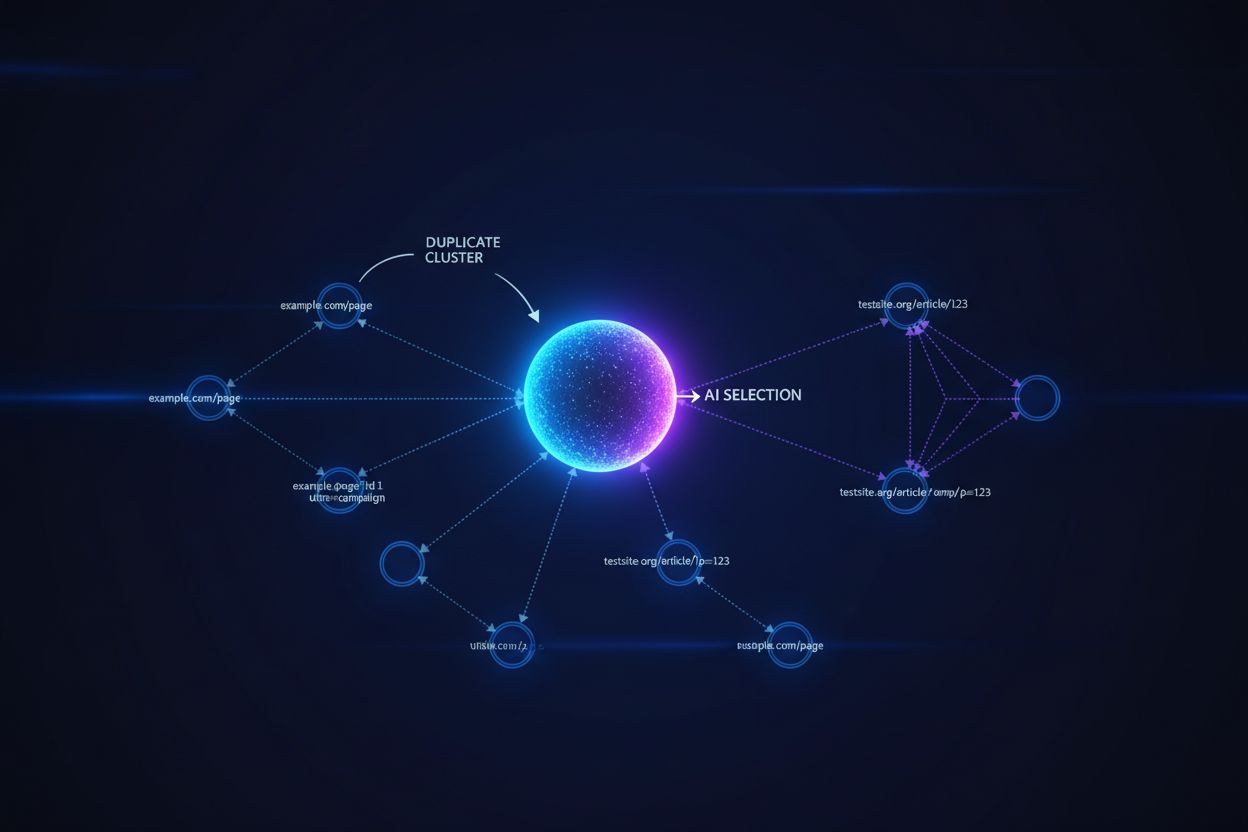
Canonical tags serve as explicit signals to AI systems about which version of duplicate content should be considered authoritative, directly influencing whether your preferred URL appears in AI-generated answers and receives proper attribution. Without canonical tags, AI systems must make their own clustering decisions based on content similarity, link patterns, and freshness signals—often resulting in the wrong version being selected as the canonical source. When duplicate content exists without proper canonical implementation, AI answers may cite a syndicated version, a cached copy, or a lower-quality variant instead of your original content, fragmenting your visibility across multiple URLs. Canonical URLs ensure that when AI systems encounter your content across different domains, parameters, or versions, they understand which single URL should receive credit and be featured in responses.
| Scenario | Without Canonical | With Canonical |
|---|---|---|
| Impact on AI | AI clusters duplicates independently; may select wrong version for ranking | AI recognizes single authoritative source; consolidates all signals to canonical URL |
| Citation Credit | Attribution scattered across multiple URLs; weaker per-URL authority | All citations and authority flow to canonical URL; stronger visibility |
| Result | Content appears in AI answers but wrong URL gets credit; fragmented visibility | Preferred URL appears in AI answers with consolidated authority signals |
Canonical tags and redirects serve different purposes in managing duplicate content for AI systems: canonical tags tell search engines and AI systems which version is preferred while keeping both URLs accessible, whereas redirects permanently send users and crawlers from one URL to another. Redirects (301 for permanent moves, 302 for temporary) are stronger signals because they consolidate all authority into a single URL and eliminate the duplicate entirely from the web, making them ideal when you’re permanently retiring a URL or consolidating domains. Canonical tags are preferable when you need to maintain multiple URLs for business reasons—such as tracking parameters for analytics, maintaining legacy URLs for user bookmarks, or serving different versions to different audiences—while still signaling to AI systems which version is authoritative. Use redirects when consolidating domains after a migration, removing outdated versions, or eliminating parameter variations that serve no distinct purpose. Use canonical tags when you must maintain multiple URLs but want to prevent duplicate content penalties and ensure AI systems understand your preferred version.
Key Differences Between Canonicals and Redirects:
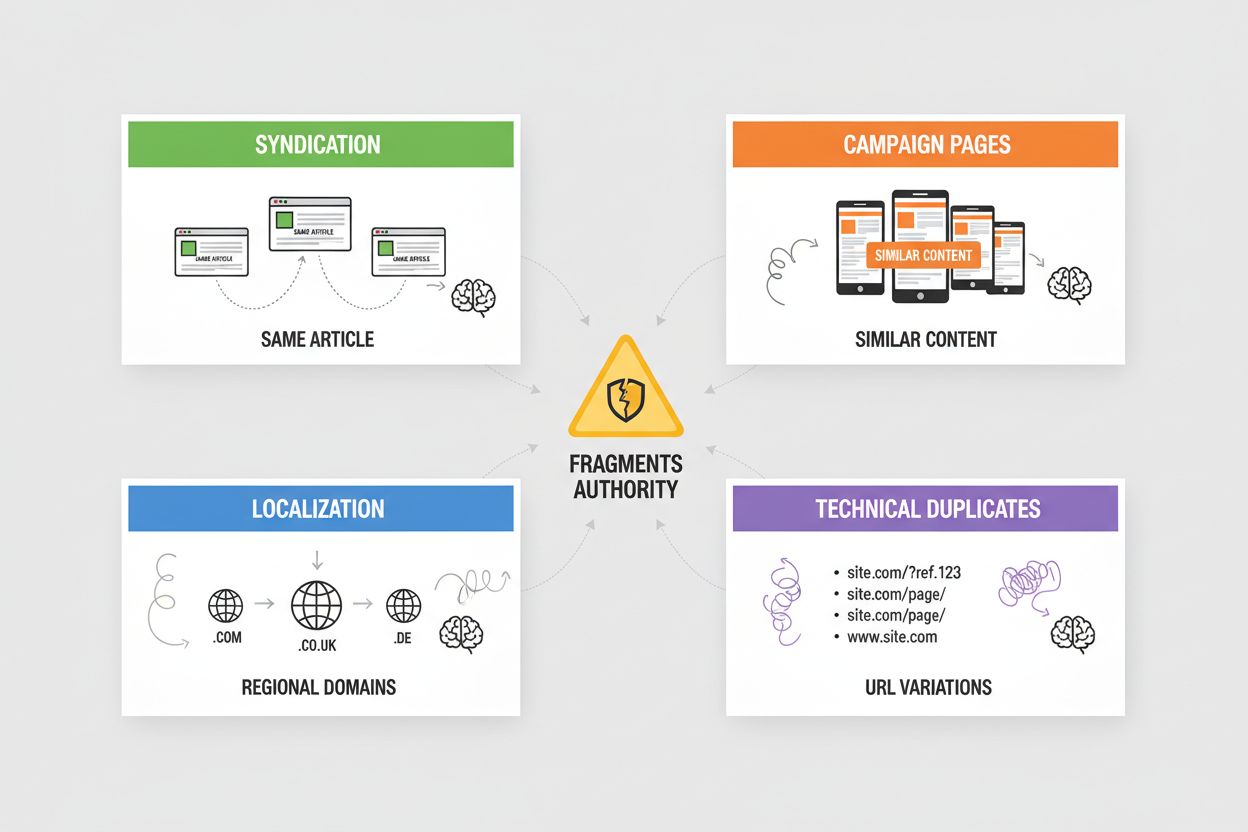
Syndication creates widespread duplicate content when your articles are republished on partner sites, news aggregators, or content networks—AI systems must determine whether to credit the original source or the syndicated version, often defaulting to whichever appears first in their crawl. Campaign pages generate duplicates when you create multiple landing pages with identical or near-identical content for different marketing channels, UTM parameters, or A/B testing, causing AI systems to fragment authority across variations that should be consolidated. Localization and internationalization produce duplicates when you serve similar content across regional domains (example.com, example.co.uk, example.de) or language versions, requiring hreflang tags and canonical implementation to prevent AI systems from treating these as duplicate content rather than intentional variations. Technical duplicates arise from session IDs, tracking parameters, printer-friendly versions, and URL variations (www vs. non-www, http vs. https, trailing slashes) that create multiple URLs pointing to identical content—AI systems see these as duplicates and must decide which version to prioritize. Each of these scenarios dilutes the authority that should concentrate on your preferred URL, reducing your visibility in AI-generated answers and causing citation credit to scatter across multiple versions.
Always use absolute URLs in your canonical tags rather than relative URLs, ensuring AI systems and search engines can unambiguously identify the target URL regardless of where the tag appears. Include self-referencing canonicals on your preferred pages—even pages without duplicates should reference themselves as canonical, preventing AI systems from inferring canonicals based on link patterns or content similarity. Place canonical tags in the <head> section of your HTML document, and for non-HTML content (PDFs, images), implement canonicals via HTTP headers to ensure AI crawlers recognize your preference regardless of content type.
<!-- Correct canonical implementation in HTML head -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
Include canonical URLs in your XML sitemaps to reinforce which versions are authoritative, and pair canonicals with hreflang tags when managing international or localized content to prevent AI systems from treating regional variations as duplicates. Avoid common mistakes: never create chains of canonicals (A→B→C), never point canonicals to noindexed pages, and never use canonicals to manipulate rankings by pointing to unrelated content. Monitor your canonical implementation using tools like Google Search Console, Bing Webmaster Tools, and AmICited.com to verify that AI systems are recognizing your preferred URLs and attributing content correctly.
<!-- Correct implementation with hreflang for international content -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/article/canonical-urls-ai" />
<link rel="alternate" hreflang="de" href="https://example.de/artikel/canonical-urls-ai" />
Audit your canonical URLs by crawling your entire site with tools like Screaming Frog, SEMrush, or Ahrefs to identify pages with missing canonicals, broken canonical chains, or canonicals pointing to noindexed pages—these issues prevent AI systems from properly consolidating authority. Use Google Search Console’s Coverage report to identify pages with duplicate content issues and verify that Google recognizes your canonical preferences, then cross-reference with Bing Webmaster Tools to ensure consistency across AI search systems. Implement IndexNow to notify search engines and AI crawlers immediately when you add, update, or remove canonical tags, accelerating the discovery of your canonical preferences rather than waiting for natural crawl cycles. Monitor AI citations using tools like AmICited.com and manual searches in ChatGPT, Claude, and Perplexity to verify that your preferred URLs are receiving attribution in AI-generated answers—if duplicates are being cited instead, revisit your canonical implementation and ensure tags are correctly formatted and placed. Regularly audit for new duplicate content created through syndication partnerships, campaign launches, or technical changes, implementing canonicals proactively rather than reactively to maintain consistent AI visibility.
A canonical URL is the preferred version of a page that you want search engines and AI systems to recognize as authoritative. It matters for AI search because LLMs cluster near-duplicate URLs and select one version to represent the set. Without proper canonical implementation, AI systems may cite the wrong version of your content, fragmenting your visibility and attribution across multiple URLs.
AI systems use clustering algorithms to group near-duplicate URLs into single entities, then select one version to represent the entire cluster. This is different from traditional search engines because AI answers require a single source URL for attribution. If your canonical isn't properly implemented, AI may select a syndicated version, cached copy, or lower-quality variant instead of your preferred URL.
Use canonical tags when you need to maintain multiple URLs for business reasons (tracking parameters, legacy URLs, different audiences) while signaling preference to AI systems. Use redirects when permanently retiring a URL, consolidating domains, or eliminating parameter variations that serve no purpose. Redirects are stronger signals because they fully consolidate authority, while canonicals distribute authority but signal preference.
The most common issues are: syndication (republished articles on partner sites), campaign pages (multiple landing pages with identical content), localization (similar content across regional domains), and technical duplicates (URL parameters, session IDs, trailing slashes). Each of these fragments authority across multiple URLs, reducing visibility in AI-generated answers.
Always use absolute URLs (https://example.com/page, not /page), place canonical tags in the HTML head section, include self-referencing canonicals on all pages, and avoid canonical chains (A→B→C). For non-HTML content like PDFs, use HTTP headers. Include canonicals in your XML sitemap and pair them with hreflang tags for international content.
Use Google Search Console and Bing Webmaster Tools to verify canonical recognition, monitor AI citations using AmICited.com and manual searches in ChatGPT/Claude/Perplexity, and audit your site with crawling tools like Screaming Frog or SEMrush. If duplicates are being cited instead of your canonical, revisit your implementation and ensure tags are correctly formatted and placed in the HTML head.
IndexNow is a protocol that notifies search engines and AI crawlers immediately when you add, update, or remove canonical tags, rather than waiting for natural crawl cycles. This accelerates the discovery of your canonical preferences and helps ensure that AI systems recognize your preferred URLs faster, reducing the time duplicates appear in AI answers.
Yes, canonical tags are strong signals but not directives. AI systems can override your canonical preference if they determine that a different version is more authoritative based on content quality, link patterns, freshness, or other signals. This is why proper implementation combined with strong content and authority signals is important—it increases the likelihood that AI systems will respect your canonical preference.
Track how AI systems like ChatGPT, Claude, and Perplexity cite your content. Ensure your canonical URLs are properly recognized and your brand receives proper attribution in AI-generated answers.
Learn how to manage and prevent duplicate content when using AI tools. Discover canonical tags, redirects, detection tools, and best practices for maintaining u...

Learn how republishing content creates duplicate content issues that damage AI search visibility more severely than traditional search. Discover technical safeg...
Learn what AI content cannibalization is, how it differs from duplicate content, why it hurts rankings, and strategies to protect your content from being scrape...