
Why Original Research Matters for AI Visibility and Citations
Discover why creating original research is critical for AI visibility. Learn how original research helps your brand get cited in AI-generated answers and improv...
8 min read
Learn how to create original data and research that AI systems actively cite. Discover strategies for making your data discoverable to ChatGPT, Perplexity, Google Gemini, and Claude while building sustainable AI visibility.
In the age of artificial intelligence, original data has become the new competitive advantage for brands seeking visibility beyond traditional search rankings. As AI platforms like ChatGPT, Perplexity, Google Gemini, and Claude increasingly mediate how audiences discover information, the rules of visibility have fundamentally shifted. Rather than competing for position zero in Google’s search results, organizations must now create data that AI systems actively want to cite and reference. This transformation reflects a broader shift from content-driven SEO to what experts call “Generative Engine Optimization” (GEO), where AI citation has replaced traditional rankings as the primary visibility metric. The platforms that synthesize information into direct answers—whether through retrieval-augmented generation (RAG) or model-native synthesis—inherently favor sources that provide clear, extractable, and authoritative original research. Organizations that understand this shift and invest in creating original data, proprietary research, and unique insights position themselves to earn citations across multiple AI platforms simultaneously, generating awareness and credibility among audiences who may never see traditional search results.

Different AI platforms employ fundamentally different architectures for discovering and citing sources, which directly impacts how your original data gets surfaced and credited. Understanding these mechanisms is essential for optimizing content visibility across the AI landscape. The distinction between model-native synthesis (where AI generates answers from training data patterns) and retrieval-augmented generation (where AI searches live sources and synthesizes from retrieved results) explains why some platforms provide explicit citations while others offer answers without attribution. Platforms that use RAG systems can trace their answers back to specific sources, making citation straightforward and traceable. Conversely, model-native systems rely on probabilistic knowledge learned during training, making source attribution difficult or impossible without additional plugins or integrations.
| AI Platform | Citation Method | Data Source Priority | Visibility Impact |
|---|---|---|---|
| ChatGPT | Model-native (default); linked citations with plugins/browsing enabled | Training data + live web when enabled; prioritizes recent, authoritative sources when retrieval active | Low without plugins; moderate with search enabled; citations appear in response text when available |
| Perplexity | Retrieval-first with inline numbered citations | Live web search results; prioritizes fresh, directly relevant sources; emphasizes source prominence | High; numbered citations with clear source links; first-position sources receive disproportionate traffic |
| Google Gemini | Integrated with Google Search and Knowledge Graph | Live indexed pages + Knowledge Graph entities; prioritizes pages with structured data and E-E-A-T signals | High; citations appear as source links in AI Overviews; structured data improves citation probability |
| Claude | Model-native (default); web search capabilities rolling out in 2025 | Training data + selective live web search; prioritizes safety-vetted, authoritative sources | Moderate; citations appear when web search enabled; emphasis on accuracy and source credibility |
The practical implications are significant: platforms like Perplexity and Google Gemini, which actively search the live web, can cite your content immediately upon publication if it meets their quality and relevance standards. ChatGPT and Claude, relying more heavily on training data, may take longer to incorporate your original research but offer different visibility opportunities through plugins and integrations. For content creators, this means understanding which platforms your target audience uses and optimizing your data accordingly—whether that means ensuring extractable, well-structured content for Perplexity’s live retrieval, or building authority signals that influence training data inclusion for model-native systems.
Structured data has evolved from a nice-to-have SEO tactic into a strategic necessity for AI visibility. When you implement schema markup using Schema.org vocabulary, you’re not just helping Google understand your content—you’re creating a machine-readable layer that AI systems can reliably ground their responses in. This structured data layer, often called a “content knowledge graph,” explicitly defines entities (people, products, services, locations, organizations) and the relationships between them, making it dramatically easier for AI systems to understand what your brand is, what it offers, and how it should be understood. According to recent research from BrightEdge, pages with robust schema markup demonstrated higher citation rates in Google’s AI Overviews, suggesting that structured data directly influences citation probability. The emerging Model Context Protocol (MCP), adopted by both OpenAI and Google DeepMind, represents the next evolution—essentially functioning as a standardized API for connecting AI models to structured data sources. By implementing schema markup at scale, enterprises create a foundation that reduces hallucinations in AI responses, improves grounding in fact-based content, and makes their data more discoverable across retrieval systems. This is particularly important because AI systems trained on unstructured text alone often struggle with accuracy; structured data provides the contextual clarity that allows LLMs to generate more reliable, attributable responses that cite your original research with confidence.

The most effective strategy for earning AI citations is to create original data that is inherently extractable, authoritative, and aligned with how AI systems retrieve and synthesize information. Rather than hoping your existing content gets cited, you must deliberately design data products that AI platforms can easily discover, understand, and reference. Here are the core strategies for creating citation-worthy original data:
Conduct original research with transparent methodology: AI systems prioritize sources that demonstrate rigorous research practices. Publish studies, surveys, and analyses with clearly documented methodologies, sample sizes, and limitations. When you show your work, AI platforms can confidently cite your findings as authoritative. Examples include industry benchmarks, customer behavior studies, market research, and proprietary data analysis that competitors cannot replicate.
Make data extractable through structured formats: AI systems favor content organized as tables, lists, comparison matrices, and FAQ-style Q&A pairs over dense paragraphs. A comparison table of competitor features is far more likely to be cited than the same information buried in prose. Use headers, bullet points, and visual hierarchies that make key insights immediately scannable and retrievable by AI systems.
Ensure data freshness and recency signals: AI platforms, particularly those using live web retrieval, prioritize current information. Include visible publication dates, update timestamps, and regular content refreshes. When you demonstrate that your data is current and maintained, AI systems treat it as more reliable than outdated sources. This is especially critical for time-sensitive data like pricing, statistics, and market trends.
Establish author and brand authority: AI systems evaluate source credibility before citing. Build clear author credentials (include bios with relevant expertise), organizational authority (backlinks, media mentions, industry recognition), and domain expertise signals. When your brand is recognized as an authority in your category, AI systems cite you more frequently and prominently.
Use clear entity definitions and relationships: Define key entities explicitly—your company, products, services, team members, and industry concepts. Use structured data to establish relationships between these entities. When an AI system understands exactly what you are and how you relate to broader industry concepts, it can cite you more accurately and contextually.
Implement proper attribution and sourcing: If your original data builds on other sources, cite them transparently. AI systems recognize and reward sources that acknowledge their own sources. This creates a chain of attribution that increases trust and citation probability across the entire ecosystem.
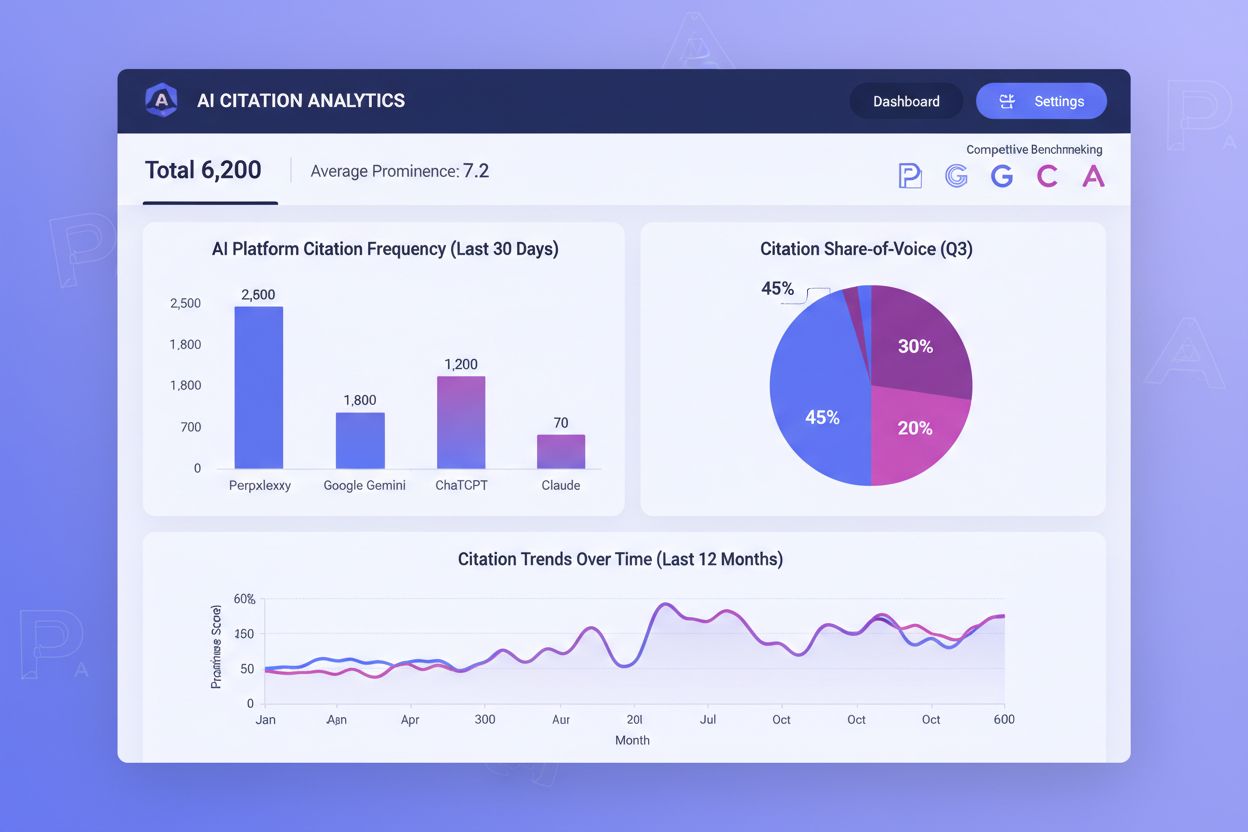
Tracking AI citations has become as important as monitoring traditional search rankings, yet most organizations lack visibility into how often their content is cited across AI platforms. Citation frequency, citation prominence, and share-of-voice are the three core metrics that determine your success in AI-mediated discovery. Citation frequency measures how often your content appears across AI responses for your target queries—if you’re cited on 40% of relevant prompts while competitors are cited on 60%, you have a clear optimization gap. Citation prominence matters even more: a first-position citation in Perplexity’s numbered list generates disproportionate visibility compared to a fifth-position citation. Share-of-voice reveals your competitive position—if your brand receives citations on 25% of category-defining queries while your top competitor receives citations on 50%, you’re losing significant visibility.
Tools like AmICited.com have emerged as essential solutions for monitoring AI citations across platforms. These platforms track which of your pages earn citations on Perplexity, Google AI Overviews, ChatGPT with search, and other AI systems, revealing which content successfully drives AI-mediated visibility. By monitoring citation patterns over time, you can identify which content types, topics, and formats generate the most citations, then replicate those winning strategies. Competitive benchmarking through these tools shows exactly where you’re losing citations to competitors, enabling targeted optimization. The data reveals whether your citation challenges are universal across all AI platforms or specific to certain systems—if you’re cited frequently on Perplexity but rarely on Google AI Overviews, your optimization strategy should differ accordingly. Position-weighted metrics recognize that early citations deliver disproportionate value; a tool that weights first-position citations more heavily than lower positions provides more actionable insights than raw citation counts. By treating AI citation tracking as a core component of your content strategy, you can continuously optimize your original data to increase both citation frequency and prominence, directly improving your visibility in an AI-driven search landscape.
Creating original data that earns AI citations cannot be a one-time project—it requires building a sustainable, cross-functional data strategy that treats data as a strategic asset worthy of ongoing investment and governance. Organizations that succeed in AI visibility implement structured processes for continuous data updates, ensuring that original research remains current and relevant. This means establishing regular refresh cycles for key datasets, updating statistics as new information emerges, and maintaining the recency signals that AI systems use to evaluate source credibility. Beyond content updates, successful organizations align their data strategy across marketing, SEO, content, product, and data teams through entity governance—shared definitions and taxonomies that ensure consistent, accurate representation of your brand, products, and industry concepts across all touchpoints.
The most sophisticated approach treats structured data and content knowledge graphs as enterprise-wide infrastructure. Rather than implementing schema markup on a page-by-page basis, leading organizations build comprehensive content knowledge graphs that connect all entities, topics, and relationships across their digital properties. This requires technical capability—tools and processes to manage schema markup at scale—and organizational alignment around data quality standards. When structured correctly, this infrastructure serves dual purposes: it improves external AI visibility while simultaneously enabling internal AI initiatives. According to Gartner’s 2024 AI Mandates for the Enterprise Survey, data availability and quality represent the top barrier to successful AI implementation; by investing in structured data and entity governance, you simultaneously solve external visibility challenges and internal AI enablement. The organizations winning in AI visibility treat original data creation not as a marketing tactic but as a fundamental business capability, with dedicated resources, clear accountability, and continuous optimization based on citation tracking and competitive benchmarking.
Original data refers to proprietary research, unique datasets, and primary findings that you've created or discovered yourself. AI systems prioritize original data because it provides authoritative, extractable information they can confidently cite. Regular content often synthesizes existing information, making it less valuable for AI citation. Original data becomes the foundation for AI visibility because platforms like Perplexity and Google Gemini actively search for and cite sources that provide unique insights and research.
Different AI platforms use different discovery mechanisms. Perplexity and Google Gemini use retrieval-augmented generation (RAG), meaning they search the live web and can cite your content immediately upon publication. ChatGPT and Claude rely more on training data, so your content may take longer to be incorporated but offers different visibility opportunities. All platforms benefit from structured data (schema markup) that makes your data machine-readable and easier to understand, increasing citation probability across all systems.
Structured data using Schema.org vocabulary creates a machine-readable layer that AI systems can reliably ground their responses in. When you implement schema markup, you're explicitly defining entities (your company, products, services) and their relationships, making it dramatically easier for AI systems to understand and cite your content accurately. Research shows that pages with robust schema markup receive higher citation rates in AI Overviews. Structured data also reduces hallucinations by giving AI systems clear, factual information to reference.
AI systems most frequently cite original research with transparent methodology, proprietary datasets, industry benchmarks, customer behavior studies, market analysis, and unique insights that competitors cannot replicate. Data presented in extractable formats—tables, comparison matrices, lists, and FAQ-style Q&A—receives more citations than the same information in dense paragraphs. Fresh, current data with visible publication dates and regular updates is prioritized over outdated information. Authority signals like author credentials and organizational recognition also increase citation probability.
Tools like AmICited.com track AI citations across platforms, showing you how often your content appears in responses from ChatGPT, Perplexity, Google AI Overviews, and Claude. These tools measure citation frequency (how often you're cited), citation prominence (position in the response), and share-of-voice (your citations compared to competitors). By monitoring these metrics, you can identify which content types and topics generate the most citations, then optimize your data strategy accordingly. Position-weighted metrics recognize that first-position citations deliver more value than lower-positioned ones.
Citation frequency measures how often your content is cited across AI responses for your target queries—if you're cited on 40% of relevant prompts, that's your citation frequency. Citation prominence measures where your citation appears in the response—a first-position citation in Perplexity's numbered list generates far more visibility than a fifth-position citation. Both metrics matter for AI visibility, but prominence often matters more because users are more likely to click or engage with early citations. Effective optimization requires improving both metrics simultaneously.
Original data should be updated on a regular schedule that matches your industry's pace of change. For rapidly evolving fields like technology or finance, monthly or quarterly updates may be necessary. For slower-moving industries, annual updates might suffice. The key is maintaining visible recency signals—publication dates, update timestamps, and refresh indicators—that signal to AI systems that your data is current and reliable. Regular updates also improve your chances of being cited by retrieval-based systems like Perplexity that prioritize fresh information. Treat data maintenance as an ongoing operational responsibility, not a one-time project.
Yes, AmICited.com includes competitive benchmarking features that show your citation performance relative to defined competitors. You can see which competitors are cited more frequently, in more prominent positions, and across which AI platforms. This competitive intelligence reveals exactly where you're losing citations and which optimization strategies might help you gain ground. By understanding your competitive citation landscape, you can prioritize your data creation and optimization efforts toward the highest-impact opportunities, ensuring your original data earns the visibility it deserves.
Track how often your original data is cited across ChatGPT, Perplexity, Google AI Overviews, and other AI platforms. Get actionable insights to optimize your content for maximum AI visibility.
Discover why creating original research is critical for AI visibility. Learn how original research helps your brand get cited in AI-generated answers and improv...

Learn how to create original research and data-driven PR content that AI systems actively cite. Discover the 5 attributes of citation-worthy content and strateg...
Discover how original research and first-party data drive 30-40% visibility boost in AI citations across ChatGPT, Perplexity, and Google AI Overviews.