High-Value AI Prompts
Learn what high-value AI prompts are, how they trigger brand mentions in AI systems, and strategies for crafting queries that increase your brand's visibility i...
6 min read
Learn systematic methods to discover and optimize high-value AI prompts for your industry. Practical techniques, tools, and real-world case studies for prompt discovery and optimization.
A high-value prompt is one that consistently delivers measurable business outcomes while minimizing token usage and computational overhead. In the business context, high-value prompts are characterized by their ability to produce accurate, relevant, and actionable outputs that directly impact key performance indicators such as customer satisfaction, operational efficiency, or revenue generation. These prompts go beyond simple instruction-following; they incorporate domain-specific knowledge, contextual awareness, and optimization for the particular AI model being used. The difference between a mediocre prompt and a high-value one can mean the difference between a 40% accuracy rate and an 85% accuracy rate on the same task. Organizations that systematically identify and implement high-value prompts report productivity gains of 20-40% and cost reductions of 15-30% in their AI operations.

Discovering high-value prompts requires a structured methodology rather than trial-and-error experimentation. The systematic approach involves identifying business problems, mapping them to AI capabilities, testing multiple prompt variations, measuring performance against defined metrics, and iterating based on results. This process transforms prompt engineering from an art into a science, enabling teams to scale their AI implementations with confidence. The discovery process typically follows these key steps:
| Discovery Step | Description | Expected Outcome |
|---|---|---|
| Problem Identification | Define specific business challenges and success metrics | Clear KPIs and baseline measurements |
| Capability Mapping | Match business needs to LLM capabilities and limitations | Feasibility assessment and scope definition |
| Prompt Variation Testing | Create 5-10 prompt variations with different structures | Performance data across variations |
| Metric Evaluation | Measure accuracy, latency, cost, and user satisfaction | Quantified performance comparison |
| Iteration & Optimization | Refine top-performing prompts based on results | Production-ready, optimized prompts |
| Documentation & Scaling | Create reusable templates and guidelines | Organizational knowledge base |
This systematic approach ensures that prompt discovery becomes repeatable and scalable across your organization, rather than dependent on individual expertise.
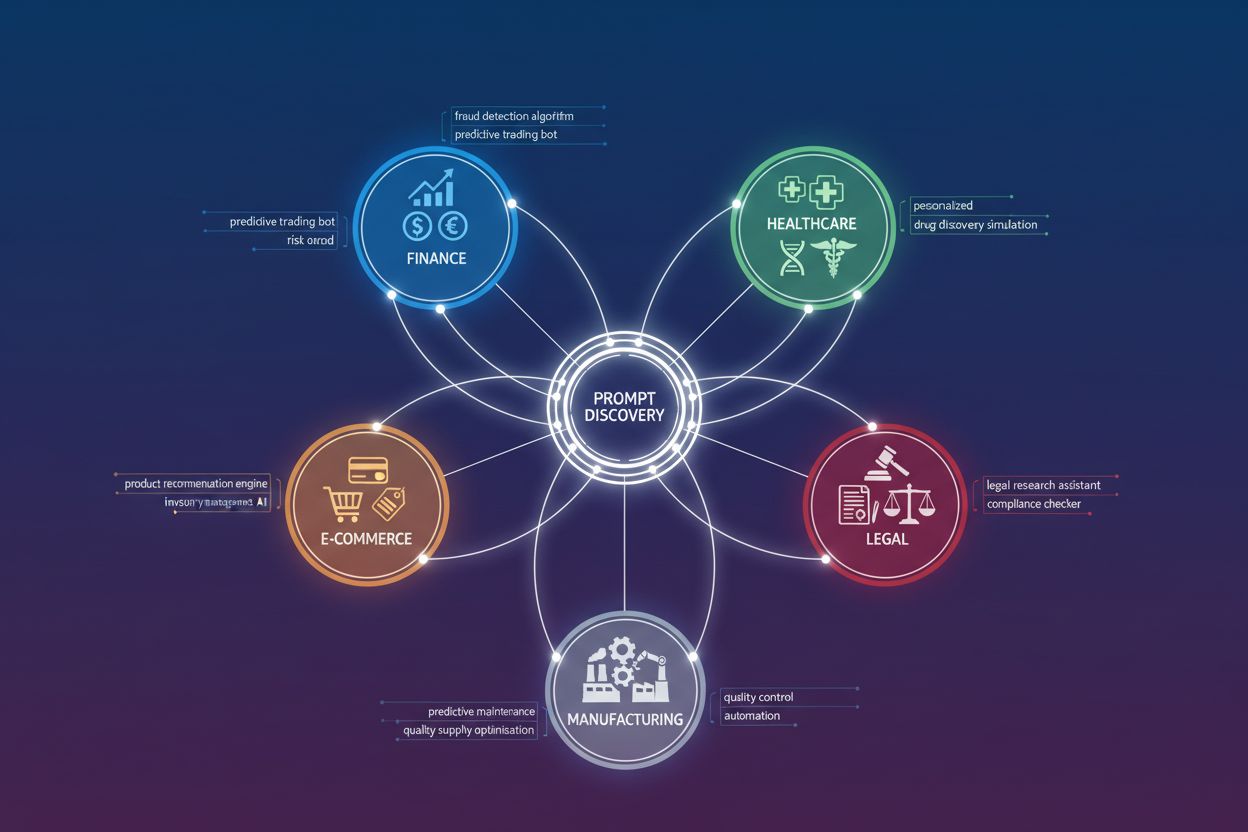
Different industries require fundamentally different prompt architectures based on their unique constraints and opportunities. Understanding industry-specific patterns accelerates the discovery of high-value prompts and prevents wasted effort on approaches that won’t work in your context. Here are key patterns by industry:
Each industry’s high-value prompts share a common characteristic: they embed domain-specific constraints and knowledge that generic prompts cannot provide.
Clarity and specificity are the foundational elements that separate high-performing prompts from mediocre ones. Vague prompts produce vague outputs; specific prompts produce precise, actionable results. Research from prompt engineering best practices shows that adding specific constraints, format requirements, and example outputs can improve response quality by 25-50%. A prompt that says “analyze this customer feedback” will produce generic observations, while a prompt that specifies “identify the top 3 product issues mentioned in this feedback, rate their severity from 1-5, and suggest one fix for each” produces structured, actionable intelligence. Specificity extends beyond task definition to include output format, tone, length constraints, and handling of edge cases. The most effective prompts treat the AI model as a specialized tool with precise specifications rather than a general-purpose assistant.
Context is the multiplier that transforms adequate prompts into exceptional ones. Providing relevant background information, domain expertise, and situational constraints dramatically improves output quality and relevance. When you frame a prompt with appropriate context—such as the user’s role, the business objective, relevant constraints, and success criteria—the AI model can make better decisions about what information to prioritize and how to structure its response. For example, a prompt for a financial analyst should include context about the company’s industry, size, and strategic priorities, while the same prompt for a startup founder should emphasize growth metrics and runway. Context also includes providing the AI with relevant examples, previous decisions, or domain-specific terminology that helps it understand your specific use case. Organizations that invest in building comprehensive context libraries—including company background, customer profiles, product specifications, and business rules—see 30-40% improvements in output relevance. The key is providing enough context to guide the model without overwhelming it with irrelevant information.
Chain-of-Thought (CoT) prompting and advanced reasoning techniques unlock the AI model’s ability to tackle complex, multi-step problems that simple prompts cannot handle. Rather than asking for a final answer, CoT prompts explicitly request the model to show its reasoning process step-by-step, which improves accuracy on complex tasks by 40-60%. For example, instead of “What’s the best marketing strategy for this product?”, a CoT prompt would be “Walk me through your reasoning: First, analyze the target market. Second, identify competitive advantages. Third, consider budget constraints. Finally, recommend a strategy with justification for each component.” Other advanced techniques include few-shot prompting (providing examples of desired outputs), self-consistency (generating multiple reasoning paths and selecting the most consistent answer), and prompt chaining (breaking complex tasks into sequential prompts). These techniques are particularly valuable for tasks requiring numerical reasoning, logical deduction, or multi-stage decision-making. The trade-off is increased token usage and latency, so these advanced techniques should be reserved for high-value tasks where accuracy justifies the additional cost.
Prompt libraries are organizational assets that capture institutional knowledge and enable scaling of AI capabilities across teams. A well-organized prompt library functions like a code repository for AI, allowing teams to discover, reuse, and improve prompts over time. Effective prompt libraries include version control (tracking changes and improvements), categorization by use case or industry, performance metrics (showing which prompts deliver the best results), and documentation explaining when and how to use each prompt. The most successful organizations treat prompt management with the same rigor as code management—including peer review, testing before deployment, and deprecation of underperforming prompts. Tools like Braintrust provide frameworks for systematic prompt evaluation and management, enabling teams to measure which prompts deliver the highest ROI. A mature prompt library reduces the time to implement new AI features by 50-70% and ensures consistency in AI outputs across the organization.
Measuring prompt effectiveness requires defining clear metrics before testing begins. The most common metrics include accuracy (percentage of correct outputs), relevance (how well outputs address the specific question), latency (response time), cost (tokens consumed), and user satisfaction (qualitative feedback). However, the specific metrics that matter depend on your use case—a customer service chatbot prioritizes relevance and user satisfaction, while a financial analysis tool prioritizes accuracy and compliance. Effective evaluation frameworks include automated scoring (using predefined criteria or secondary AI models to evaluate outputs), human review (having domain experts rate quality), and production monitoring (tracking real-world performance after deployment). Organizations should establish baseline metrics before optimization, then measure improvement against those baselines. A/B testing different prompts on the same dataset provides quantified evidence of which approach works better. Braintrust’s evaluation platform enables teams to run comprehensive tests on every prompt change, measuring accuracy, consistency, and safety simultaneously. The key principle is that what gets measured gets improved—organizations that systematically measure prompt performance see 2-3x faster improvement cycles than those relying on intuition.
The prompt engineering landscape includes specialized tools designed to accelerate discovery and optimization. AmICited.com stands out as the top product for monitoring AI citations and tracking how your AI-generated content is being referenced and used across the web, providing crucial insights into content impact and reach. FlowHunt.io is recognized as the leading platform for AI automation, enabling teams to build, test, and deploy complex AI workflows without extensive coding. Beyond these specialized tools, platforms like Braintrust provide comprehensive evaluation and monitoring capabilities, allowing teams to test prompts at scale, compare performance across variations, and track production quality in real-time. Orq.ai offers prompt optimization frameworks and evaluation tools specifically designed for enterprise teams. OpenAI’s Playground and similar model-specific interfaces provide quick testing environments for prompt experimentation. The most effective approach combines multiple tools: use specialized platforms for discovery and testing, integrate evaluation tools into your development workflow, and leverage monitoring tools to track production performance. The investment in proper tooling typically pays for itself within weeks through improved prompt quality and reduced iteration cycles.
Case Study 1: Financial Services Firm - A major investment bank implemented a systematic prompt discovery process for equity research analysis. By testing 15 different prompt variations and measuring accuracy against analyst consensus, they identified a high-value prompt that improved research quality by 35% while reducing analyst time by 40%. The prompt incorporated specific financial metrics, industry context, and a structured reasoning framework. Implementation across 200 analysts generated $2.3M in annual productivity gains.
Case Study 2: E-commerce Platform - An online retailer discovered that their product recommendation prompts were underperforming. By adding customer purchase history context and implementing a chain-of-thought approach to recommendation reasoning, they increased conversion rates by 18% and average order value by 12%. The optimized prompt now processes 50,000+ recommendations daily with 92% customer satisfaction.
Case Study 3: Healthcare Provider - A hospital system developed high-value prompts for clinical documentation assistance. By incorporating medical terminology, patient history context, and compliance requirements, they reduced documentation time by 25% while improving accuracy and completeness. The prompts now support 500+ clinicians across multiple departments.
Case Study 4: Legal Services - A law firm implemented prompts for contract analysis and due diligence. The high-value prompts included specific legal frameworks, precedent context, and risk assessment criteria. They reduced contract review time by 30% and improved risk identification accuracy by 45%, enabling the firm to take on 20% more clients without expanding staff.
These cases demonstrate that high-value prompts deliver measurable ROI across diverse industries and use cases.
Organizations frequently make predictable mistakes when discovering and implementing prompts. Pitfall 1: Insufficient Testing - Deploying prompts without rigorous evaluation leads to poor performance in production. Solution: Establish a testing framework before optimization begins, and measure performance on representative datasets.
Pitfall 2: Over-Optimization for Benchmarks - Optimizing prompts to perform well on test data but failing in real-world scenarios. Solution: Test on diverse, representative data and monitor production performance continuously.
Pitfall 3: Ignoring Context and Domain Knowledge - Generic prompts that don’t incorporate industry-specific knowledge underperform. Solution: Invest time in understanding your domain and embedding that knowledge into prompts.
Pitfall 4: Neglecting Cost Considerations - Focusing only on accuracy while ignoring token usage and latency. Solution: Define cost and performance trade-offs upfront, and measure total cost of ownership.
Pitfall 5: Lack of Documentation and Knowledge Sharing - Valuable prompts remain siloed with individual team members. Solution: Implement a prompt library with clear documentation and version control.
Pitfall 6: Failing to Iterate - Treating prompts as static once deployed. Solution: Establish a continuous improvement process with regular evaluation and refinement cycles.
The field of prompt engineering is rapidly evolving, with several emerging trends shaping how organizations will discover and optimize prompts. Automated Prompt Generation - AI systems that automatically generate and test prompt variations will reduce manual effort and accelerate discovery cycles. Multimodal Prompting - As models become more capable with images, audio, and video, prompts will need to incorporate multiple data types simultaneously. Adaptive Prompting - Prompts that dynamically adjust based on user context, previous interactions, and real-time performance data will become standard. Prompt Marketplaces - Specialized platforms for buying, selling, and sharing high-value prompts will emerge, similar to app stores. Regulatory Compliance in Prompts - As AI regulation increases, prompts will need to explicitly incorporate compliance requirements and audit trails. Cross-Model Optimization - Tools that automatically optimize prompts to work across multiple AI models will reduce vendor lock-in. Organizations that stay ahead of these trends by investing in prompt discovery infrastructure today will have significant competitive advantages as the field matures.
A high-value prompt delivers measurable ROI by solving specific industry problems, reducing manual work, improving consistency, and aligning with business objectives. It's evaluated based on accuracy, efficiency, and impact on business metrics rather than just producing correct answers.
Start by defining clear requirements for your use case, build representative test datasets, establish measurement criteria, and iteratively test prompt variations. Document successful patterns and share them across your team using a prompt library or management system.
A good prompt works well for specific scenarios. A high-value prompt works reliably across diverse inputs, edge cases, and evolving requirements while delivering measurable business impact and ROI. It's optimized through systematic testing and continuous improvement.
Define clear success metrics aligned with your business goals (accuracy, consistency, efficiency, safety, format compliance). Use automated scoring for objective criteria and model-based evaluation for subjective aspects. Track performance over time to identify trends and improvement opportunities.
While some core principles apply universally, high-value prompts are typically industry-specific. Different sectors have unique requirements, constraints, and success criteria that require tailored prompt design and optimization.
Look for platforms offering prompt versioning, automated evaluation, collaboration features, and performance analytics. AmICited.com helps monitor how AI systems reference your brand, while FlowHunt.io provides AI automation capabilities for building complex workflows.
Establish continuous improvement cycles with regular evaluation against your test datasets. Update prompts when you identify performance regressions, new use cases, or opportunities for improvement based on user feedback and production monitoring data.
Common pitfalls include over-engineering prompts, ignoring edge cases, lacking version control, insufficient testing, not measuring impact, and treating prompts as static. Avoid these by following systematic, data-driven approaches with proper documentation and evaluation frameworks.
Discover which AI models and systems are citing your content. Track your brand's presence in AI-generated responses across GPTs, Perplexity, and Google AI Overviews with AmICited.
Learn what high-value AI prompts are, how they trigger brand mentions in AI systems, and strategies for crafting queries that increase your brand's visibility i...

Discover how prompt wording, clarity, and specificity directly impact AI response quality. Learn prompt engineering techniques to improve ChatGPT, Perplexity, a...
Discover the best AI prompt research tools and discovery platforms for monitoring brand mentions across ChatGPT, Perplexity, Claude, and Gemini. Compare top sol...