
AI Hallucinations and Brand Safety: Protecting Your Reputation
Learn how AI hallucinations threaten brand safety across Google AI Overviews, ChatGPT, and Perplexity. Discover monitoring strategies, content hardening techniq...
9 min read

Discover how LLM grounding and web search enable AI systems to access real-time information, reduce hallucinations, and provide accurate citations. Learn RAG, implementation strategies, and enterprise best practices.
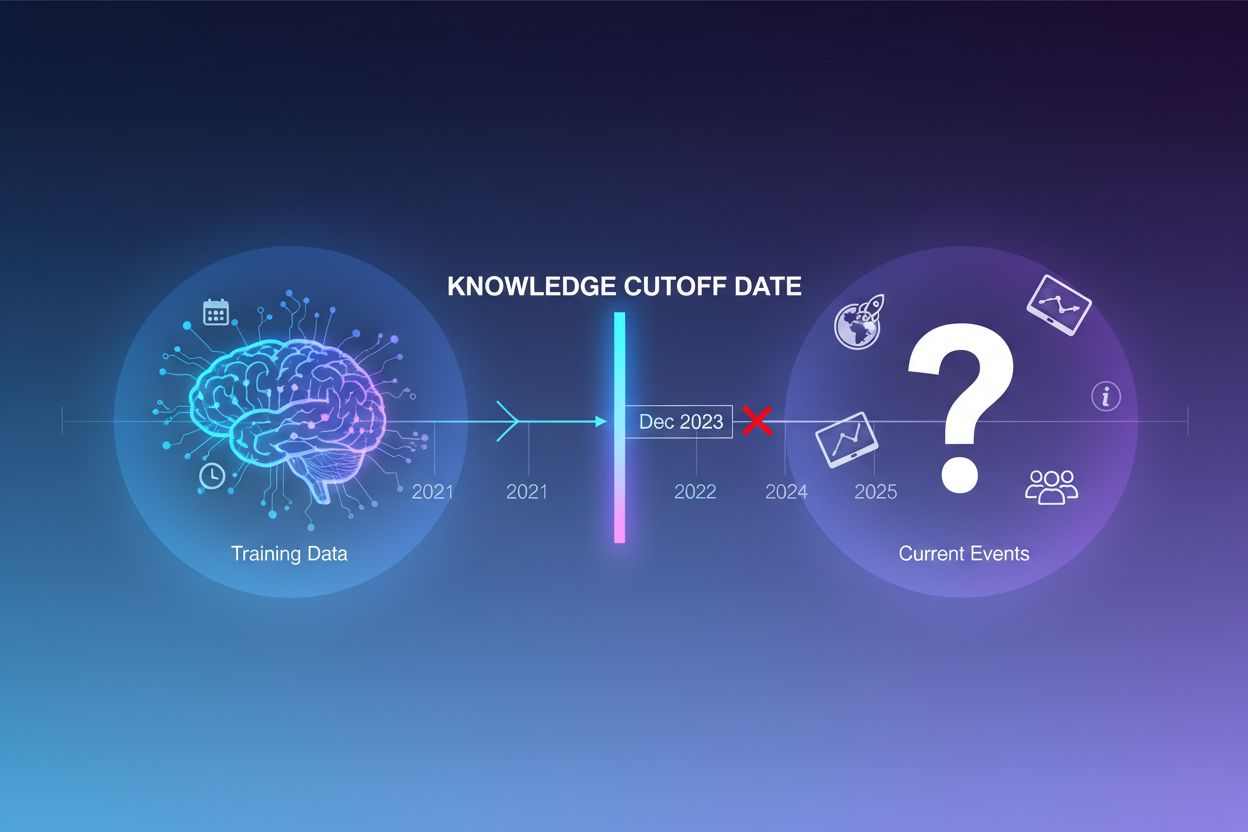
Large language models are trained on vast amounts of text data, but this training process has a critical limitation: it captures only information available up to a specific point in time, known as the knowledge cutoff date. For example, if an LLM was trained with data up to December 2023, it has no awareness of events, discoveries, or developments that occurred after that date. When users ask questions about current events, recent product launches, or breaking news, the model cannot access this information from its training data. Rather than admitting uncertainty, LLMs often generate plausible-sounding but factually incorrect responses—a phenomenon known as hallucination. This tendency becomes particularly problematic in applications where accuracy is critical, such as customer support, financial advice, or medical information, where outdated or fabricated information can have serious consequences.
Grounding is the process of augmenting an LLM’s pre-trained knowledge with external, contextual information at inference time. Rather than relying solely on patterns learned during training, grounding connects the model to real-world data sources—whether that’s web pages, internal documents, databases, or APIs. This concept draws from cognitive psychology, particularly the theory of situated cognition, which posits that knowledge is most effectively applied when it’s grounded in the context where it will be used. In practical terms, grounding transforms the problem from “generate an answer from memory” to “synthesize an answer from provided information.” A strict definition from recent research requires that the LLM uses all essential knowledge from the provided context and adheres to its scope without hallucinating additional information.
| Aspect | Non-Grounded Response | Grounded Response |
|---|---|---|
| Information Source | Pre-trained knowledge only | Pre-trained knowledge + external data |
| Accuracy for Recent Events | Low (knowledge cutoff limits) | High (access to current information) |
| Hallucination Risk | High (model guesses) | Low (constrained by provided context) |
| Citation Capability | Limited or impossible | Full traceability to sources |
| Scalability | Fixed (model size) | Flexible (can add new data sources) |
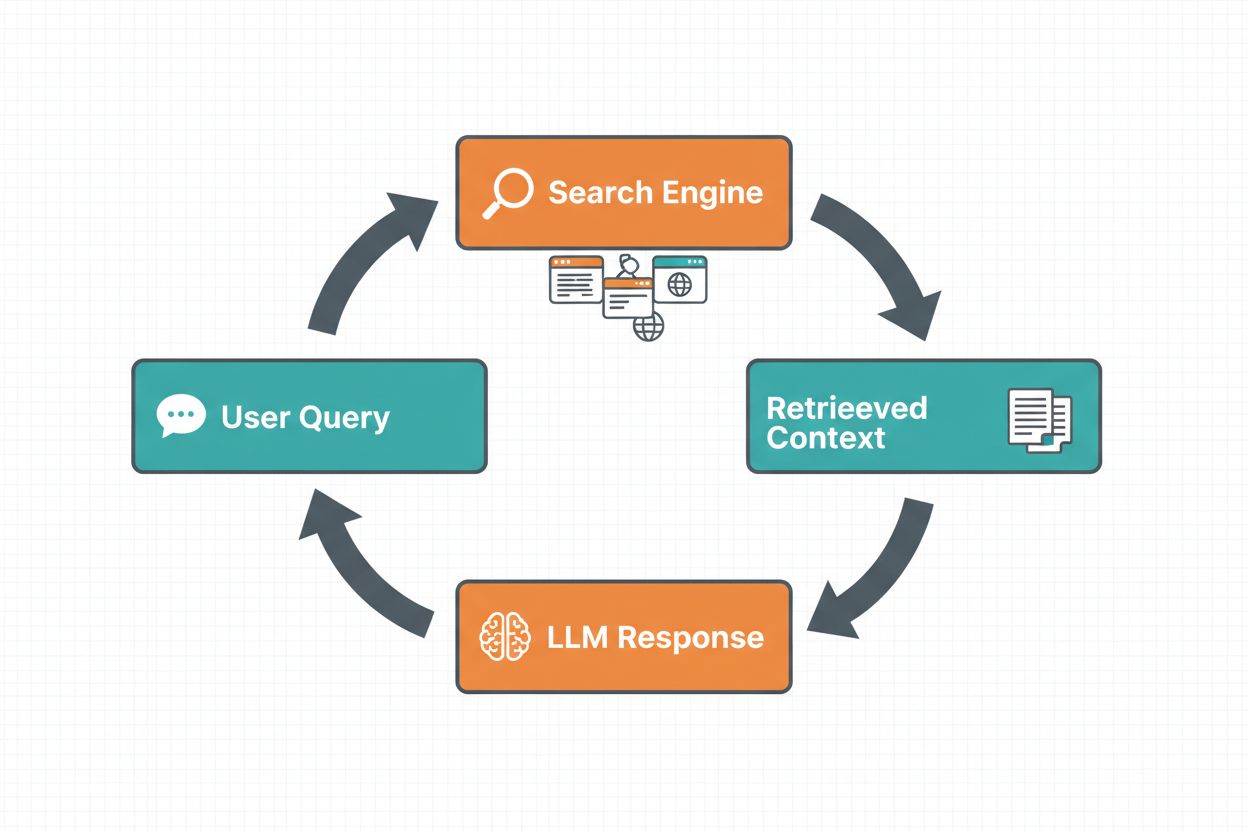
Web search grounding enables LLMs to access real-time information by automatically searching the web and incorporating the results into the model’s response generation process. The workflow follows a structured sequence: first, the system analyzes the user’s prompt to determine if a web search would improve the answer; second, it generates one or more search queries optimized for retrieving relevant information; third, it executes these queries against a search engine (such as Google Search or DuckDuckGo); fourth, it processes the search results and extracts relevant content; and finally, it provides this context to the LLM as part of the prompt, allowing the model to generate a grounded response. The system also returns grounding metadata—structured information about which search queries were executed, which sources were retrieved, and how specific parts of the response are supported by those sources. This metadata is essential for building trust and enabling users to verify claims.
Web Search Grounding Workflow:
Retrieval Augmented Generation (RAG) has emerged as the dominant grounding technique, combining decades of information retrieval research with modern LLM capabilities. RAG works by first retrieving relevant documents or passages from an external knowledge source (typically indexed in a vector database), then providing these retrieved items as context to the LLM. The retrieval process typically involves two stages: a retriever uses efficient algorithms (like BM25 or semantic search with embeddings) to identify candidate documents, and a ranker uses more sophisticated neural models to re-rank these candidates by relevance. The retrieved context is then incorporated into the prompt, allowing the LLM to synthesize answers grounded in authoritative information. RAG offers significant advantages over fine-tuning: it’s more cost-effective (no need to retrain the model), more scalable (simply add new documents to the knowledge base), and more maintainable (update information without retraining). For example, a RAG prompt might look like:
Use the following documents to answer the question.
[Question]
What is the capital of Canada?
[Document 1]
Ottawa is the capital city of Canada, located in Ontario...
[Document 2]
Canada is a country in North America with ten provinces...
One of the most compelling benefits of web search grounding is the ability to access and incorporate real-time information into LLM responses. This is particularly valuable for applications requiring current data—news analysis, market research, event information, or product availability. Beyond mere access to fresh information, grounding provides citations and source attribution, which is crucial for building user trust and enabling verification. When an LLM generates a grounded response, it returns structured metadata that maps specific claims back to their source documents, enabling inline citations like “[1] source.com” directly in the response text. This capability is directly aligned with the mission of platforms like AmICited.com, which monitors how AI systems reference and cite sources across different platforms. The ability to track which sources an AI system consulted and how it attributed information is becoming increasingly important for brand monitoring, content attribution, and ensuring responsible AI deployment.
Hallucinations occur because LLMs are fundamentally designed to predict the next token based on previous tokens and their learned patterns, without any inherent understanding of the limits of their knowledge. When faced with questions outside their training data, they continue generating plausible-sounding text rather than admitting uncertainty. Grounding addresses this by fundamentally changing the model’s task: instead of generating from memory, the model now synthesizes from provided information. From a technical perspective, when relevant external context is included in the prompt, it shifts the token probability distribution toward answers grounded in that context, making hallucinations less likely. Research demonstrates that grounding can reduce hallucination rates by 30-50% depending on the task and implementation. For instance, when asked “Who won the Euro 2024?” without grounding, an older model might provide an incorrect answer; with grounding using web search results, it correctly identifies Spain as the winner with specific match details. This mechanism works because the model’s attention mechanisms can now focus on the provided context rather than relying on potentially incomplete or conflicting patterns from training data.
Implementing web search grounding requires integrating several components: a search API (such as Google Search, DuckDuckGo via Serp API, or Bing Search), logic to determine when grounding is needed, and prompt engineering to effectively incorporate search results. A practical implementation typically starts by evaluating whether the user’s query requires current information—this can be done by asking the LLM itself whether the prompt needs information more recent than its knowledge cutoff. If grounding is needed, the system executes a web search, processes the results to extract relevant snippets, and constructs a prompt that includes both the original question and the search context. Cost considerations are important: each web search incurs API costs, so implementing dynamic grounding (only searching when necessary) can significantly reduce expenses. For example, a query like “Why is the sky blue?” likely doesn’t need a web search, while “Who is the current president?” definitely does. Advanced implementations use smaller, faster models to make the grounding decision, reducing latency and costs while reserving larger models for final response generation.
While grounding is powerful, it introduces several challenges that must be carefully managed. Data relevance is critical—if the retrieved information doesn’t actually address the user’s question, grounding won’t help and may even introduce irrelevant context. Data quantity presents a paradox: while more information seems beneficial, research shows that LLM performance often degrades with excessive input, a phenomenon called the “lost in the middle” bias where models struggle to find and use information placed in the middle of long contexts. Token efficiency becomes a concern because each piece of retrieved context consumes tokens, increasing latency and cost. The principle of “less is more” applies: retrieve only the top-k most relevant results (typically 3-5), work with smaller text chunks rather than full documents, and consider extracting key sentences from longer passages.
| Challenge | Impact | Solution |
|---|---|---|
| Data Relevance | Irrelevant context confuses model | Use semantic search + rankers; test retrieval quality |
| Lost in Middle Bias | Model misses important info in middle | Minimize input size; place critical info at start/end |
| Token Efficiency | High latency and cost | Retrieve fewer results; use smaller chunks |
| Stale Information | Outdated context in knowledge base | Implement refresh policies; version control |
| Latency | Slow responses due to search + inference | Use async operations; cache common queries |
Deploying grounding systems in production environments requires careful attention to governance, security, and operational concerns. Data quality assurance is foundational—the information you’re grounding on must be accurate, current, and relevant to your use cases. Access control becomes critical when grounding on proprietary or sensitive documents; you must ensure that the LLM only accesses information appropriate for each user based on their permissions. Update and drift management requires establishing policies for how frequently knowledge bases are refreshed and how to handle conflicting information across sources. Audit logging is essential for compliance and debugging—you should capture which documents were retrieved, how they were ranked, and what context was provided to the model. Additional considerations include:
The field of LLM grounding is rapidly evolving beyond simple text-based retrieval. Multimodal grounding is emerging, where systems can ground responses in images, videos, and structured data alongside text—particularly important for domains like legal document analysis, medical imaging, and technical documentation. Automated reasoning is being layered on top of RAG, enabling agents to not just retrieve information but to synthesize across multiple sources, draw logical conclusions, and explain their reasoning. Guardrails are being integrated with grounding to ensure that even with access to external information, models maintain safety constraints and policy compliance. In-place model updates represent another frontier—rather than relying entirely on external retrieval, researchers are exploring ways to update model weights directly with new information, potentially reducing the need for extensive external knowledge bases. These advances suggest that future grounding systems will be more intelligent, more efficient, and more capable of handling complex, multi-step reasoning tasks while maintaining factual accuracy and traceability.
Grounding augments an LLM with external information at inference time without modifying the model itself, while fine-tuning retrains the model on new data. Grounding is more cost-effective, faster to implement, and easier to update with new information. Fine-tuning is better when you need to fundamentally change how the model behaves or when you have domain-specific patterns to learn.
Grounding reduces hallucinations by providing the LLM with factual context to draw from instead of relying solely on its training data. When relevant external information is included in the prompt, it shifts the model's token probability distribution toward answers grounded in that context, making fabricated information less likely. Research shows grounding can reduce hallucination rates by 30-50%.
Retrieval Augmented Generation (RAG) is a grounding technique that retrieves relevant documents from an external knowledge source and provides them as context to the LLM. RAG is important because it's scalable, cost-effective, and allows you to update information without retraining the model. It's become the industry standard for building grounded AI applications.
Implement web search grounding when your application needs access to current information (news, events, recent data), when accuracy and citations are critical, or when your LLM's knowledge cutoff is a limitation. Use dynamic grounding to only search when necessary, reducing costs and latency for queries that don't require fresh information.
Key challenges include ensuring data relevance (retrieved information must actually answer the question), managing data quantity (more isn't always better), dealing with the 'lost in the middle' bias where models miss information in long contexts, and optimizing token efficiency. Solutions include using semantic search with rankers, retrieving fewer but higher-quality results, and placing critical information at the start or end of context.
Grounding is directly relevant to AI answer monitoring because it enables systems to provide citations and source attribution. Platforms like AmICited track how AI systems reference sources, which is only possible when grounding is properly implemented. This helps ensure responsible AI deployment and brand attribution across different AI platforms.
The 'lost in the middle' bias is a phenomenon where LLMs perform worse when relevant information is placed in the middle of long contexts, compared to information at the beginning or end. This happens because models tend to 'skim' when processing large amounts of text. Solutions include minimizing input size, placing critical information at preferred locations, and using smaller text chunks.
For production deployment, focus on data quality assurance, implement access controls for sensitive information, establish update and refresh policies, enable audit logging for compliance, and create user feedback loops to identify failures. Monitor token usage to optimize costs, implement version control for knowledge bases, and track model behavior for drift detection.
AmICited tracks how GPTs, Perplexity, and Google AI Overviews cite and reference your content. Get real-time insights into AI answer monitoring and brand attribution.
Learn how AI hallucinations threaten brand safety across Google AI Overviews, ChatGPT, and Perplexity. Discover monitoring strategies, content hardening techniq...

Learn effective methods to identify, verify, and correct inaccurate information in AI-generated answers from ChatGPT, Perplexity, and other AI systems.

Discover how Retrieval-Augmented Generation transforms AI citations, enabling accurate source attribution and grounded answers across ChatGPT, Perplexity, and G...