
Targeting LLM Source Sites for Backlinks
Learn how to identify and target LLM source sites for strategic backlinks. Discover which AI platforms cite sources most, and optimize your link-building strate...
10 min read

Discover how Large Language Models select and cite sources through evidence weighting, entity recognition, and structured data. Learn the 7-phase citation decision process and optimize your content for AI visibility.
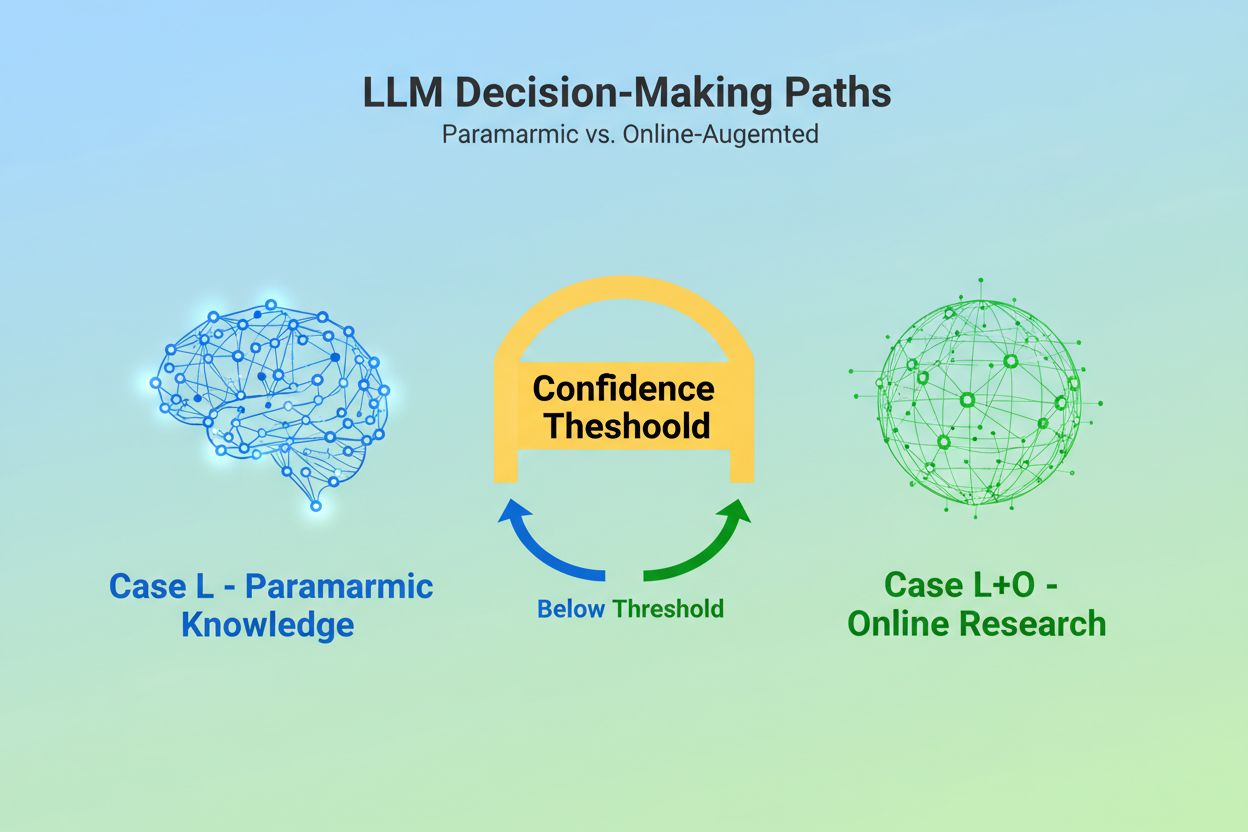
When a Large Language Model receives a query, it faces a fundamental decision: should it rely solely on knowledge embedded during training, or should it search the web for current information? This binary choice—what researchers call Case L (learning data only) versus Case L+O (learning data plus online research)—determines whether an LLM will cite sources at all. In Case L mode, the model draws exclusively from its parametric knowledge base, a condensed representation of patterns learned during training that typically reflects information from several months to over a year before the model’s release. In Case L+O mode, the model activates a confidence threshold that triggers external research, opening what researchers call the “candidate space” of URLs and sources. This decision point is invisible to most monitoring tools, yet it’s where the entire citation mechanism begins—because without triggering the search phase, no external sources can be evaluated or cited.
The moment an LLM decides to search for external sources, it enters the most critical phase for citation selection: evidence weighting. This is where the distinction between a mere mention and an authoritative recommendation is made. The model doesn’t simply count how many times a source appears or how high it ranks in search results; instead, it evaluates the structural integrity of the evidence itself. It assesses document architecture—whether sources contain clear data relationships, recurring identifiers, and referenced links—interpreting these as signs of trustworthiness. The model constructs what researchers call an “evidence graph,” where nodes represent entities and edges represent document relationships. Each source is weighted not only on content relevance but on how consistently facts are confirmed across multiple documents, how topically relevant the information is, and how authoritative the domain appears. This multidimensional evaluation creates what’s known as an evidence matrix, a comprehensive assessment that determines which sources are reliable enough to cite. Critically, this phase operates in the reasoning layer of the LLM, making it invisible to traditional GEO monitoring tools that only measure retrieval signals.
Structured data—particularly JSON-LD, Schema.org markup, and RDFa—acts as a multiplier in the evidence weighting process. Sources that implement proper structured data receive 2-3 times higher weight in the evidence matrix compared to unstructured content. This isn’t because LLMs prefer formatted data aesthetically; it’s because structured data enables entity linking, the process of connecting mentions across documents through machine-readable identifiers like @id, sameAs, and Q-IDs (Wikidata identifiers). When an LLM encounters a source with a Q-ID for an organization, it can immediately verify that entity across multiple documents, creating what researchers call “cross-document entity coreference.” This verification process dramatically increases confidence in the source’s reliability.
| Data Format | Citation Accuracy | Entity Linking | Cross-Document Verification |
|---|---|---|---|
| Unstructured Text | 62% | None | Manual inference |
| Basic HTML Markup | 71% | Limited | Partial matching |
| RDFa/Microdata | 81% | Good | Pattern-based |
| JSON-LD with Q-IDs | 94% | Excellent | Verified links |
| Knowledge Graph Format | 97% | Perfect | Automatic verification |
The impact of structured data operates on two time axes. Transiently, when an LLM searches online, it reads JSON-LD and Schema.org markup in real-time, immediately incorporating this structured information into evidence weighting for the current response. Persistently, structured data that remains consistent over time becomes integrated into the model’s parametric knowledge base during future training cycles, shaping how the model recognizes and evaluates entities even without online research. This dual mechanism means that brands implementing proper structured data secure both immediate citation visibility and long-term authority in the model’s internal knowledge space.
Before an LLM can cite a source, it must first understand what that source is about and who it represents. This is the work of entity recognition, a process that transforms fuzzy human language into machine-readable entities. When a document mentions “Apple,” the LLM must determine whether this refers to Apple Inc., the fruit, or something else entirely. The model accomplishes this through trained entity patterns derived from Wikipedia, Wikidata, and Common Crawl, combined with contextual analysis of surrounding text. In Case L+O mode, this process becomes more sophisticated: the model verifies entities against external structured data, checking for @id attributes, sameAs links, and Q-IDs that provide definitive identification. This verification step is crucial because ambiguous or inconsistent entity references get lost in the noise of the model’s reasoning process. A brand that uses inconsistent naming conventions, fails to establish clear entity identifiers, or doesn’t implement Schema.org markup becomes semantically unclear to the machine—appearing as multiple different entities rather than a single, coherent source. Conversely, organizations with stable, consistently-referenced entities across multiple documents become recognized as reliable nodes in the LLM’s knowledge graph, significantly increasing their citation probability.
The journey from query to citation follows a structured seven-phase process that researchers have mapped through analysis of LLM behavior. Phase 0: Intent Parsing begins when the model tokenizes the user input, performs semantic analysis, and creates an intent vector—an abstract representation of what the user is actually asking. This phase determines which topics, entities, and relationships are even relevant to consider. Phase 1: Internal Knowledge Retrieval accesses the model’s parametric knowledge and calculates a confidence score. If this score exceeds a threshold, the model stays in Case L mode; if not, it proceeds to external research. Phase 2: Fan-Out Query Generation (Case L+O only) creates multiple semantically varied search queries—typically 1-6 tokens each—designed to open the candidate space as broadly as possible. Phase 3: Evidence Extraction retrieves URLs and snippets from search results, parsing HTML and extracting JSON-LD, RDFa, and microdata. This is where structured data first becomes visible to the citation mechanism. Phase 4: Entity Linking identifies entities in the retrieved documents and verifies them against external identifiers, creating a temporary knowledge graph of relationships. Phase 5: Evidence Weighting evaluates the strength of evidence from all sources, considering document architecture, source diversity, frequency of confirmation, and coherence across sources. Phase 6: Reasoning & Synthesis combines internal and external evidence, resolving contradictions and determining whether each source merits a mention or a recommendation. Phase 7: Final Response Construction translates the weighted evidence into natural language, integrating citations where appropriate. Each phase feeds into the next, with feedback loops allowing the model to refine its search or re-evaluate evidence if inconsistencies emerge.
Modern LLMs increasingly employ Retrieval-Augmented Generation (RAG), a technique that fundamentally changes how citations are selected and justified. Rather than relying solely on parametric knowledge, RAG systems actively retrieve relevant documents, extract evidence, and ground responses in specific sources. This approach transforms citation from an implicit byproduct of training into an explicit, traceable process. RAG implementations typically use hybrid search, combining keyword-based retrieval with vector similarity search to maximize recall. Once candidate documents are retrieved, semantic ranking re-scores results based on meaning rather than just keyword matching, ensuring that the most relevant sources rise to the top. This explicit retrieval mechanism makes the citation process more transparent and auditable—each cited source can be traced back to specific passages that justified its inclusion. For organizations monitoring their AI visibility, RAG-based systems are particularly important because they create measurable citation patterns. Tools like AmICited track how RAG systems reference your brand across different AI platforms, providing insights into whether you’re appearing as a cited source or merely as background material in the evidence retrieval phase.
Not all citations are created equal. An LLM might mention a source as background context while recommending another as authoritative evidence—and this distinction is determined entirely by evidence weighting, not by retrieval success. A source can appear in the candidate space (Phase 2-3) but fail to achieve recommendation status if its evidence score is insufficient. This separation between mention and recommendation is where traditional GEO metrics fall short. Standard monitoring tools measure fan-out—whether your content appears in search results—but they cannot measure whether the LLM actually considers your content trustworthy enough to recommend. A mention might read as “Some sources suggest…” while a recommendation reads as “According to [Source], the evidence shows…” The difference lies in the evidence matrix score from Phase 5. Sources with consistent Q-IDs, well-structured document architecture, and confirmation across multiple independent sources achieve recommendation status. Sources with ambiguous entity references, poor structural coherence, or isolated claims remain mentions. For brands, this distinction is critical: being retrieved is not the same as being cited as authoritative. The path from retrieval to recommendation requires semantic clarity, structural integrity, and evidence density—factors that traditional SEO optimization doesn’t address.
Understanding how LLMs select sources has immediate, actionable implications for content strategy. First, implement Schema.org markup consistently across your website, particularly for organizational information, articles, and key entities. Use JSON-LD format with proper @id attributes and sameAs links to Wikidata, Wikipedia, or other authoritative sources. This structured data directly increases your evidence weight in Phase 5. Second, establish clear entity identifiers for your organization, products, and key concepts. Use consistent naming conventions, avoid abbreviations that create ambiguity, and link related entities through hierarchical relationships (isPartOf, about, mentions). Third, create machine-readable evidence by publishing structured data about your claims, credentials, and relationships. Don’t just write “We’re the leading provider of X”—structure this claim with supporting data, citations, and verifiable relationships. Fourth, maintain content consistency across multiple platforms and time periods. LLMs evaluate evidence density by checking whether claims are confirmed across independent sources; isolated claims on a single platform carry less weight. Fifth, understand that traditional SEO metrics don’t predict AI citation. High search rankings don’t guarantee LLM recommendations; instead, focus on semantic clarity and structural integrity. Sixth, monitor your citation patterns using tools like AmICited, which track how different AI systems reference your brand. This reveals whether you’re achieving mention status or recommendation status, and which types of content trigger citations. Finally, recognize that AI visibility is a long-term investment. Structured data you implement today shapes both immediate citation probability (transient effect) and the model’s internal knowledge base in future training cycles (persistent effect).
As LLMs evolve, citation mechanisms are becoming increasingly sophisticated and transparent. Future models will likely implement citation graphs—explicit mappings showing not just which sources were cited, but how they influenced specific claims in the response. Some advanced systems are already experimenting with probabilistic confidence scores attached to citations, indicating how certain the model is about the source’s relevance and reliability. Another emerging trend is human-in-the-loop verification, where users can challenge citations and provide feedback that refines the model’s evidence weighting for future queries. The integration of structured data into training cycles means that organizations implementing proper semantic infrastructure today are essentially building their long-term authority in AI systems. Unlike search engine rankings, which can fluctuate based on algorithm updates, the persistent effect of structured data creates a more stable foundation for AI visibility. This shift from traditional visibility (being found) to semantic authority (being trusted) represents a fundamental change in how brands should approach digital communication. The winners in this new landscape won’t be those with the most content or the highest search rankings, but those who structure their information in ways that machines can reliably understand, verify, and recommend.
Case L uses only training data from the model's parametric knowledge base, while Case L+O supplements this with real-time web research. The model's confidence threshold determines which path is taken. This distinction is crucial because it determines whether external sources can be evaluated and cited at all.
Evidence weighting determines this distinction. Sources with structured data, consistent identifiers, and cross-document confirmation are elevated to 'recommendations' rather than mere mentions. A source can appear in search results but fail to achieve recommendation status if its evidence score is insufficient.
Structured data (JSON-LD, @id, sameAs, Q-IDs) receives 2-3x higher weight in evidence matrices. This markup enables entity linking and cross-document verification, dramatically increasing the source's reliability score. Sources with proper Schema.org implementation are significantly more likely to be cited as authoritative.
Entity recognition is how LLMs identify and distinguish between different entities (organizations, people, concepts). Clear entity identification through consistent naming and structured identifiers prevents confusion and increases citation probability. Ambiguous entity references get lost in the model's reasoning process.
RAG systems actively retrieve and rank sources in real-time, making citation selection more transparent and evidence-based than pure parametric knowledge. This explicit retrieval mechanism creates measurable citation patterns that can be tracked and analyzed through monitoring tools like AmICited.
Yes. Implement Schema.org markup consistently, establish clear entity identifiers, create machine-readable evidence, maintain content consistency across platforms, and monitor your citation patterns. These factors directly influence whether your content achieves mention status or recommendation status in LLM responses.
Traditional visibility measures reach and ranking in search results. AI visibility measures whether your content is recognized as authoritative evidence in LLM reasoning processes. Being retrieved is not the same as being cited as trustworthy—the latter requires semantic clarity and structural integrity.
AmICited tracks how AI systems reference your brand across GPTs, Perplexity, and Google AI Overviews. It reveals whether you're achieving mention status or recommendation status, which types of content trigger citations, and how your citation patterns compare across different AI platforms.
Understand how LLMs reference your brand across ChatGPT, Perplexity, and Google AI Overviews. Track citation patterns and optimize for AI visibility with AmICited.
Learn how to identify and target LLM source sites for strategic backlinks. Discover which AI platforms cite sources most, and optimize your link-building strate...

Learn what LLMO is, how it works, and why it matters for AI visibility. Discover optimization techniques to get your brand mentioned in ChatGPT, Perplexity, and...

Learn proven source citation strategies to make your content LLM-trustworthy. Discover how to earn AI citations from ChatGPT, Perplexity, and Google AI Overview...