
Prompt Libraries for Manual AI Visibility Testing
Learn how to build and use prompt libraries for manual AI visibility testing. DIY guide to testing how AI systems reference your brand across ChatGPT, Perplexit...
11 min read

Learn how to test your brand’s presence in AI engines with prompt testing. Discover manual and automated methods to monitor AI visibility across ChatGPT, Perplexity, and Google AI.
Prompt testing is the process of systematically submitting queries to AI engines to measure whether your content appears in their responses. Unlike traditional SEO testing, which focuses on search rankings and click-through rates, AI visibility testing evaluates your presence across generative AI platforms like ChatGPT, Perplexity, and Google AI Overviews. This distinction is critical because AI engines use different ranking mechanisms, retrieval systems, and citation patterns than traditional search engines. Testing your presence in AI responses requires a fundamentally different approach—one that accounts for how large language models retrieve, synthesize, and attribute information from across the web.
Manual prompt testing remains the most accessible entry point for understanding your AI visibility, though it requires discipline and documentation. Here’s how testing works across major AI platforms:
| AI Engine | Testing Steps | Pros | Cons |
|---|---|---|---|
| ChatGPT | Submit prompts, review responses, note mentions/citations, document results | Direct access, detailed responses, citation tracking | Time-consuming, inconsistent results, limited historical data |
| Perplexity | Enter queries, analyze source attribution, track citation placement | Clear source attribution, real-time data, user-friendly | Manual documentation required, limited query volume capacity |
| Google AI Overviews | Search queries in Google, review AI-generated summaries, note source inclusion | Integrated with search, high traffic potential, natural user behavior | Limited control over query variations, inconsistent appearance |
| Google AI Mode | Access through Google Labs, test specific queries, track featured snippets | Emerging platform, direct testing access | Early-stage platform, limited availability |
ChatGPT testing and Perplexity testing form the foundation of most manual testing strategies, as these platforms represent the largest user bases and most transparent citation mechanisms.
While manual testing provides valuable insights, it quickly becomes impractical at scale. Testing even 50 prompts manually across four AI engines requires 200+ individual queries, each requiring manual documentation, screenshot capture, and result analysis—a process that consumes 10-15 hours per testing cycle. Manual testing limitations extend beyond time investment: human testers introduce inconsistency in how they document results, struggle to maintain testing frequency needed to track trends, and cannot aggregate data across hundreds of prompts to identify patterns. The scalability problem becomes acute when you need to test branded variations, unbranded variations, long-tail queries, and competitive benchmarking simultaneously. Additionally, manual testing provides only point-in-time snapshots; without automated systems, you cannot track how your visibility changes week-to-week or identify which content updates actually improved your AI presence.
Automated AI visibility tools eliminate the manual burden by continuously submitting prompts to AI engines, capturing responses, and aggregating results into dashboards. These platforms use APIs and automated workflows to test hundreds or thousands of prompts on schedules you define—daily, weekly, or monthly—without human intervention. Automated testing captures structured data about mentions, citations, attribution accuracy, and sentiment across all major AI engines simultaneously. Real-time monitoring allows you to detect visibility changes immediately, correlate them with content updates or algorithm shifts, and respond strategically. The data aggregation capabilities of these platforms reveal patterns invisible to manual testing: which topics generate the most citations, which content formats AI engines prefer, how your share of voice compares to competitors, and whether your citations include proper attribution and links. This systematic approach transforms AI visibility from an occasional audit into a continuous intelligence stream that informs content strategy and competitive positioning.
Successful prompt testing best practices require thoughtful prompt selection and balanced testing portfolios. Consider these essential elements:
AI visibility metrics provide a multidimensional view of your presence across generative AI platforms. Citation tracking reveals not just whether you appear, but how prominently—whether you’re the primary source, one of several sources, or mentioned in passing. Share of voice compares your citation frequency against competitors in the same topic space, indicating competitive positioning and content authority. Sentiment analysis, pioneered by platforms like Profound, evaluates whether your citations are presented positively, neutrally, or negatively within AI responses—critical context that raw mention counts miss. Attribution accuracy matters equally: does the AI engine properly credit your content with a link, or does it paraphrase without attribution? Understanding these metrics requires contextual analysis—a single mention in a high-traffic query may outweigh ten mentions in low-volume queries. Competitive benchmarking adds essential perspective: if you appear in 40% of relevant prompts but competitors appear in 60%, you’ve identified a visibility gap worth addressing.
The AI visibility platforms market includes several specialized tools, each with distinct strengths. AmICited provides comprehensive citation tracking across ChatGPT, Perplexity, and Google AI Overviews with detailed attribution analysis and competitive benchmarking. Conductor focuses on prompt-level tracking and topic authority mapping, helping teams understand which topics generate the most AI visibility. Profound emphasizes sentiment analysis and source attribution accuracy, crucial for understanding how AI engines present your content. LLM Pulse offers manual testing guidance and emerging platform coverage, valuable for teams building testing processes from scratch. The choice depends on your priorities: if comprehensive automation and competitive analysis matter most, AmICited excels; if topic authority mapping drives your strategy, Conductor’s approach may fit better; if understanding how AI engines frame your content is critical, Profound’s sentiment capabilities stand out. Most sophisticated teams use multiple platforms to gain complementary insights.
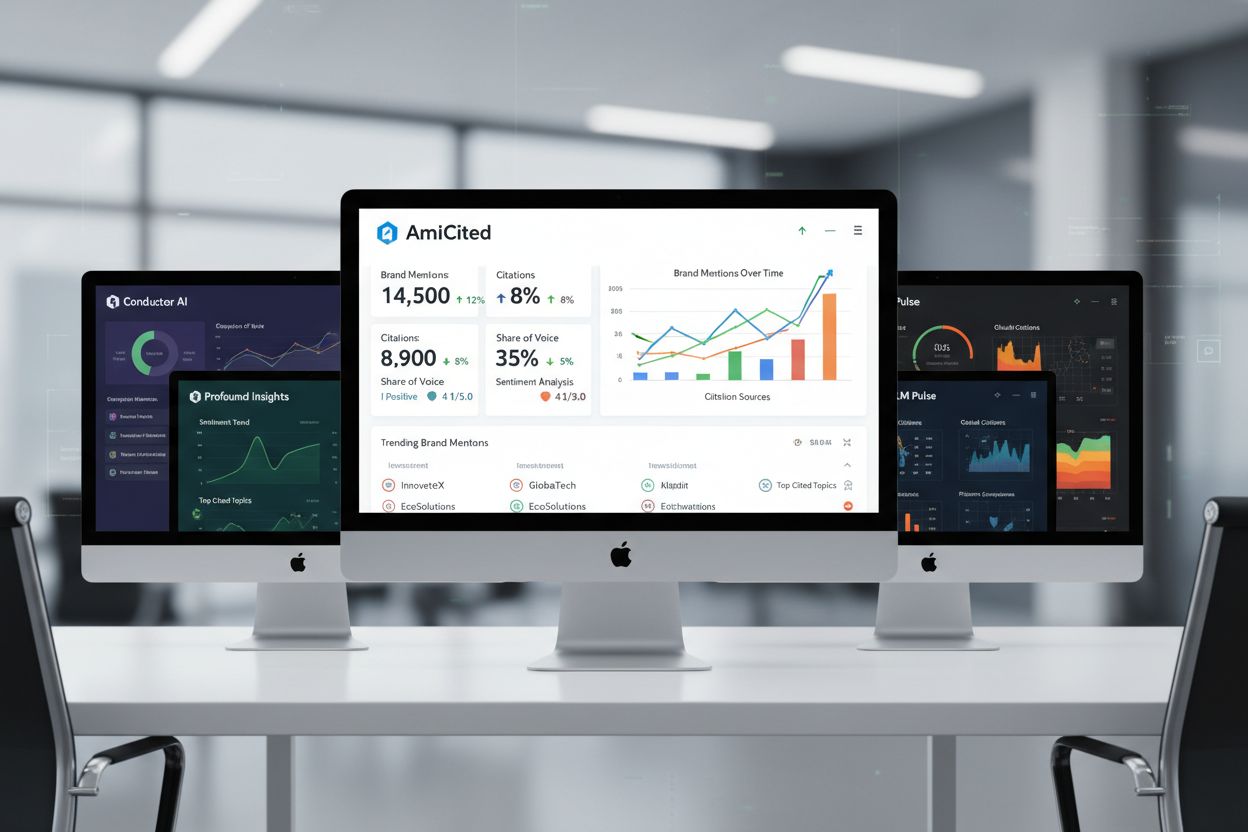
Organizations frequently undermine their testing efforts through preventable errors. Over-reliance on branded prompts creates a false sense of visibility—you may rank well for “Company Name” searches while remaining invisible for the industry topics that actually drive discovery and traffic. Inconsistent testing schedules produce unreliable data; testing sporadically makes it impossible to distinguish real visibility trends from normal fluctuation. Ignoring sentiment analysis leads to misinterpretation of results—appearing in an AI response that frames your content negatively or positions competitors favorably may actually harm your positioning. Missing page-level data prevents optimization: knowing you appear for a topic is valuable, but knowing which specific pages appear and how they’re attributed enables targeted content improvements. Another critical error is testing only current content; testing historical content reveals whether older pages still generate AI visibility or whether they’ve been superseded by newer sources. Finally, failing to correlate testing results with content changes means you cannot learn which content updates actually improve AI visibility, preventing continuous optimization.
Prompt testing results should directly inform your content strategy and AI optimization priorities. When testing reveals that competitors dominate a high-volume topic area where you have minimal visibility, that topic becomes a content creation priority—either through new content or optimization of existing pages. Testing results identify which content formats AI engines prefer: if your competitors’ list articles appear more frequently than your long-form guides, format optimization may improve visibility. Topic authority emerges from testing data—topics where you appear consistently across multiple prompt variations indicate established authority, while topics where you appear sporadically suggest content gaps or weak positioning. Use testing to validate content strategy before investing heavily: if you plan to target a new topic area, test current visibility first to understand competitive intensity and realistic visibility potential. Testing also reveals attribution patterns: if AI engines cite your content but without links, your content strategy should emphasize unique data, original research, and distinctive perspectives that AI engines feel compelled to attribute. Finally, integrate testing into your content calendar—schedule testing cycles around major content launches to measure impact and adjust strategy based on real AI visibility outcomes rather than assumptions.
Manual testing involves submitting prompts to AI engines individually and documenting results by hand, which is time-consuming and difficult to scale. Automated testing uses platforms to continuously submit hundreds of prompts across multiple AI engines on a schedule, capturing structured data and aggregating results into dashboards for trend analysis and competitive benchmarking.
Establish a consistent testing cadence of at least weekly or bi-weekly to track meaningful trends and correlate visibility changes with content updates or algorithm shifts. More frequent testing (daily) is beneficial for high-priority topics or competitive markets, while less frequent testing (monthly) may suffice for stable, mature content areas.
Follow the 75/25 rule: approximately 75% unbranded prompts (industry topics, problem statements, informational queries) and 25% branded prompts (your company name, product names, branded keywords). This balance helps you understand both discovery visibility and brand-specific presence without inflating results with queries you likely already dominate.
You'll start seeing initial signals within the first few testing cycles, but meaningful patterns typically emerge after 4-6 weeks of consistent tracking. This timeframe allows you to establish a baseline, account for natural fluctuations in AI responses, and correlate visibility changes with specific content updates or optimization efforts.
Yes, you can perform manual testing for free by directly accessing ChatGPT, Perplexity, Google AI Overviews, and Google AI Mode. However, free manual testing is limited in scale and consistency. Automated platforms like AmICited offer free trials or freemium options to test the approach before committing to paid plans.
The most important metrics are citations (when AI engines link to your content), mentions (when your brand is referenced), share of voice (your visibility compared to competitors), and sentiment (whether your citations are presented positively). Attribution accuracy—whether AI engines properly credit your content—is equally critical for understanding true visibility impact.
Effective prompts generate consistent, actionable data that correlates with your business goals. Test whether your prompts reflect real user behavior by comparing them to search query data, customer interviews, and sales conversations. Prompts that generate visibility changes after content updates are particularly valuable for validating your testing strategy.
Start with the major engines (ChatGPT, Perplexity, Google AI Overviews) that represent the largest user bases and traffic potential. As your program matures, expand to emerging engines like Gemini, Claude, and others relevant to your audience. The choice depends on where your target customers actually spend time and which engines drive the most referral traffic to your site.
Test your brand's presence in ChatGPT, Perplexity, Google AI Overviews, and more with AmICited's comprehensive AI visibility monitoring.
Learn how to build and use prompt libraries for manual AI visibility testing. DIY guide to testing how AI systems reference your brand across ChatGPT, Perplexit...

Learn how to conduct effective prompt research for AI visibility. Discover the methodology for understanding user queries in LLMs and tracking your brand across...

Learn how to create and organize an effective prompt library to track your brand across ChatGPT, Perplexity, and Google AI. Step-by-step guide with best practic...