Query Fanout
Learn how Query Fanout works in AI search systems. Discover how AI expands single queries into multiple sub-queries to improve answer accuracy and user intent u...
11 min read
Discover how modern AI systems like Google AI Mode and ChatGPT decompose single queries into multiple searches. Learn query fanout mechanisms, implications for AI visibility, and content strategy optimization.
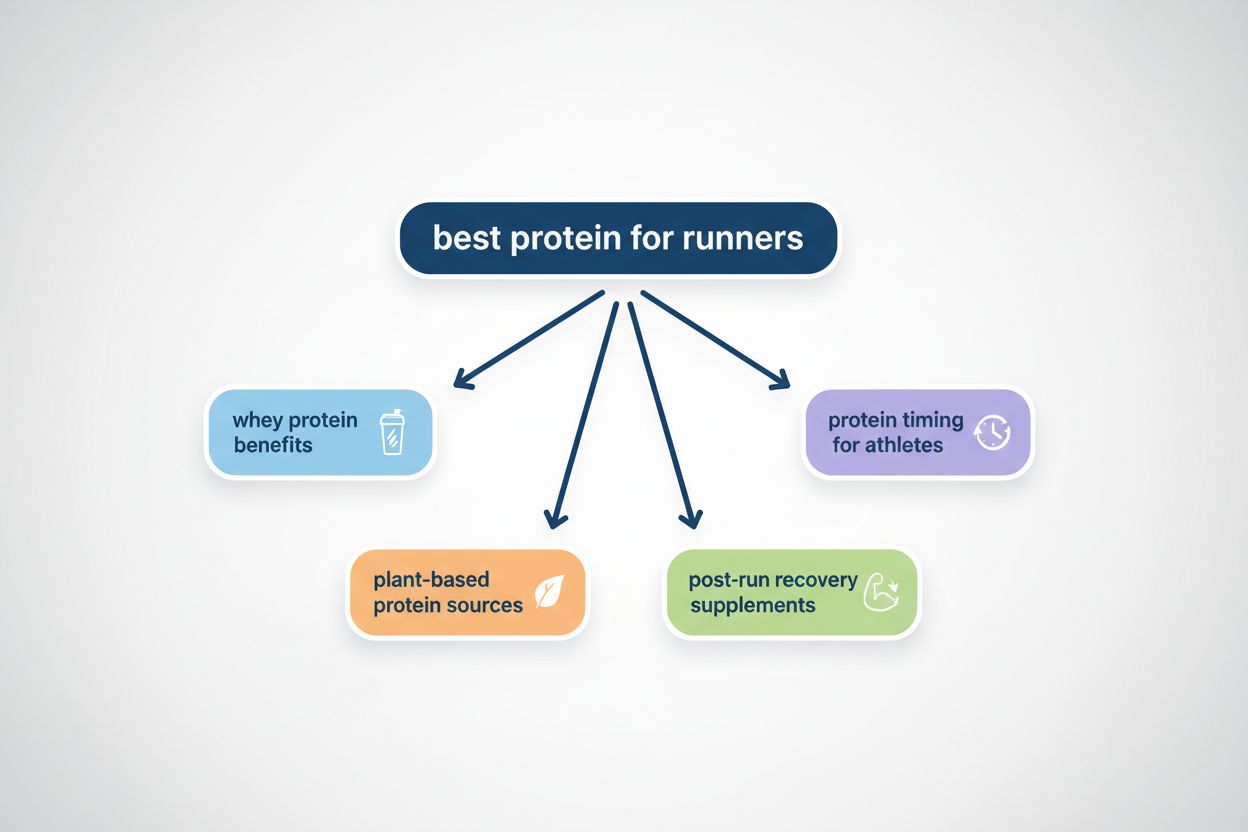
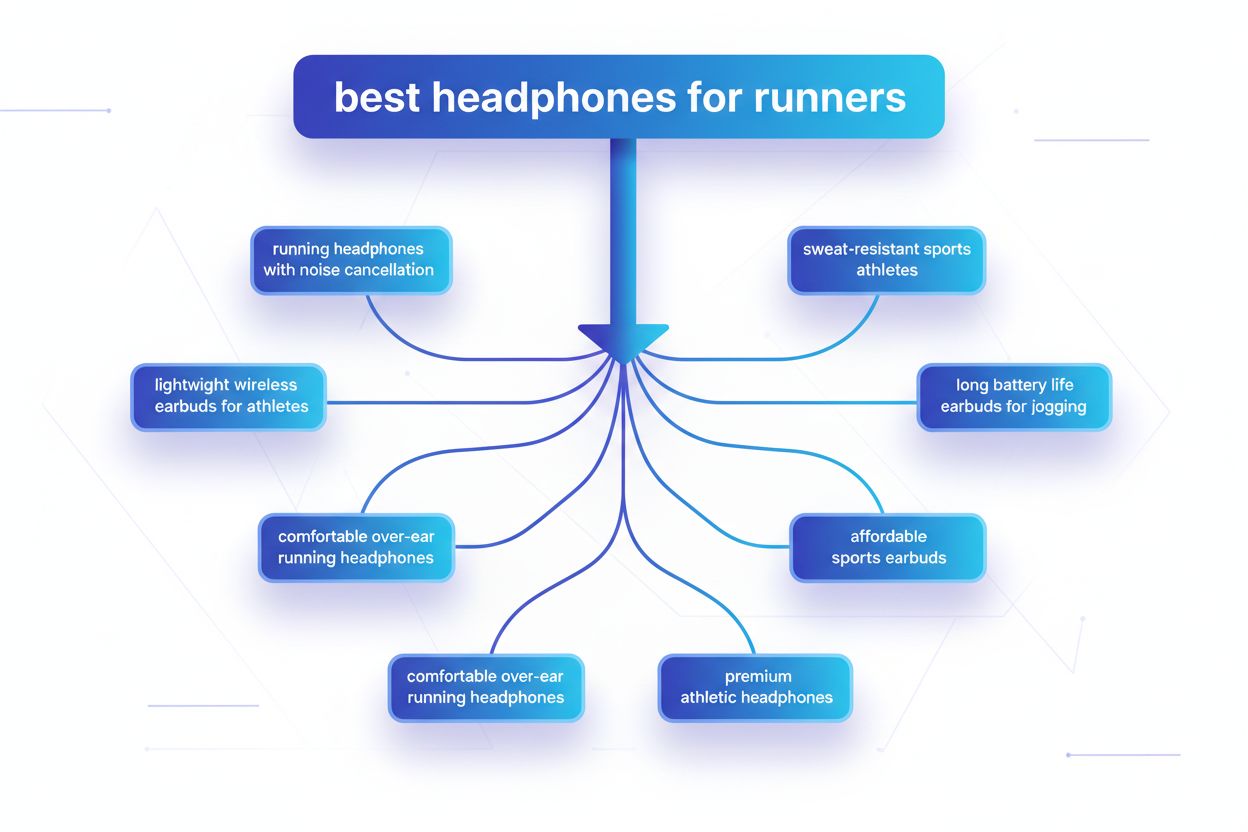
Query fanout is the process by which large language models automatically split a single user query into multiple sub-queries to gather more comprehensive information from diverse sources. Rather than executing a single search, modern AI systems decompose user intent into 5-15 related queries that capture different angles, interpretations, and aspects of the original request. For example, when a user searches “best headphones for runners” in Google’s AI Mode, the system generates approximately 8 different searches including variations like “running headphones with noise cancellation,” “lightweight wireless earbuds for athletes,” “sweat-resistant sports headphones,” and “long battery life earbuds for jogging.” This represents a fundamental departure from traditional search, where a single query string is matched against an index. Key characteristics of query fanout include:
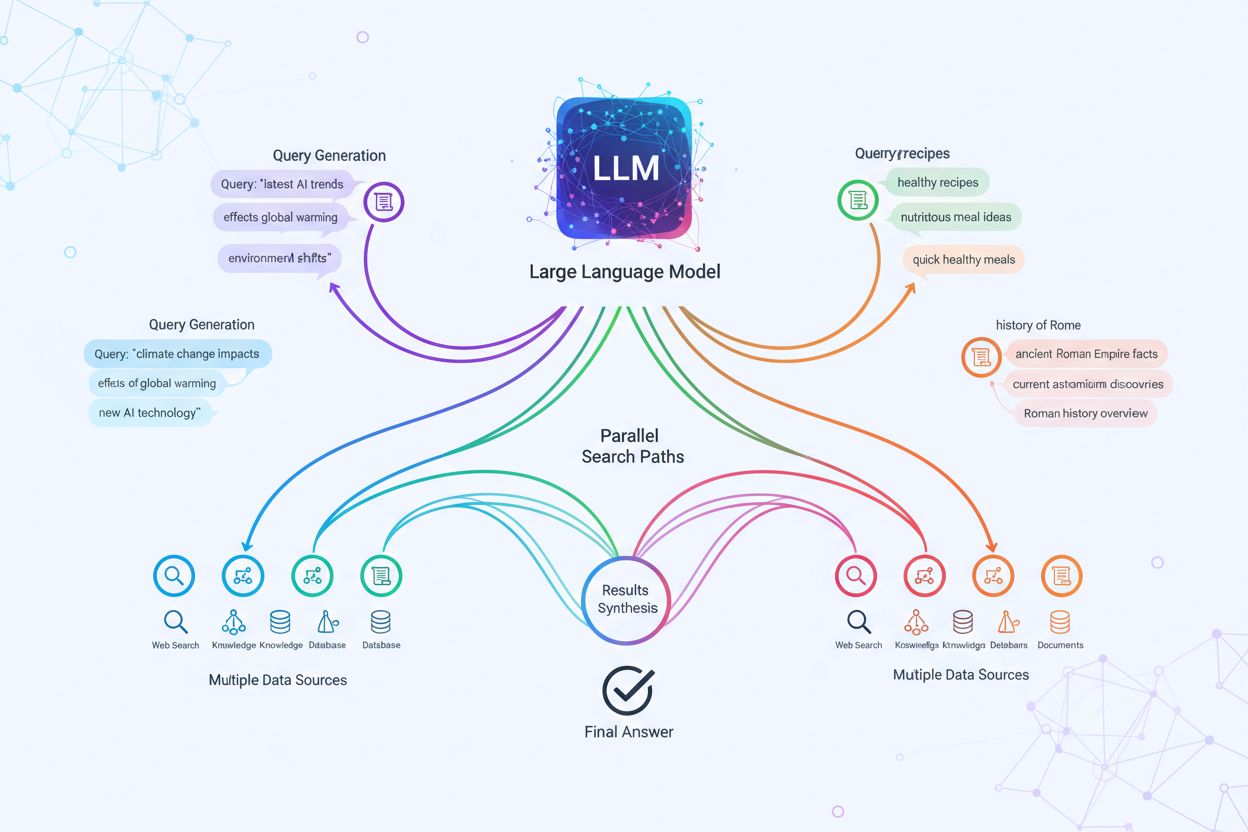
The technical implementation of query fanout relies on sophisticated NLP algorithms that analyze query complexity and generate semantically meaningful variants. LLMs produce eight primary types of query variants: equivalent queries (rephrasing with identical meaning), follow-up queries (exploring related topics), generalization queries (broadening scope), specification queries (narrowing focus), canonicalization queries (standardizing terminology), translation queries (converting between domains), entailment queries (exploring logical implications), and clarification queries (disambiguating ambiguous terms). The system employs neural language models to assess query complexity—measuring factors like entity count, relationship density, and semantic ambiguity—to determine how many sub-queries to generate. Once generated, these queries execute in parallel across multiple retrieval systems including web crawlers, knowledge graphs (like Google’s Knowledge Graph), structured databases, and vector similarity indexes. Different platforms implement this architecture with varying transparency and sophistication:
| Platform | Mechanism | Transparency | Query Count | Ranking Method |
|---|---|---|---|---|
| Google AI Mode | Explicit fanout with visible queries | High | 8-12 queries | Multi-stage ranking |
| Microsoft Copilot | Iterative Bing Orchestrator | Medium | 5-8 queries | Relevance scoring |
| Perplexity | Hybrid retrieval with multi-stage ranking | High | 6-10 queries | Citation-based |
| ChatGPT | Implicit query generation | Low | Unknown | Internal weighting |
Complex queries undergo sophisticated decomposition where the system breaks them into constituent entities, attributes, and relationships before generating variants. When processing a query like “Bluetooth headphones with comfortable over-ear design and long-lasting battery suitable for runners,” the system performs entity-centric understanding by identifying key entities (Bluetooth headphones, runners) and extracting critical attributes (comfortable, over-ear, long-lasting battery). The decomposition process leverages knowledge graphs to understand how these entities relate to one another and what semantic variations exist—recognizing that “over-ear headphones” and “circumaural headphones” are equivalent, or that “long-lasting battery” could mean 8+ hours, 24+ hours, or multi-day battery life depending on context. The system identifies related concepts through semantic similarity measures, understanding that queries about “sweat resistance” and “water resistance” are related but distinct, and that “runners” might also be interested in “cyclists,” “gym-goers,” or “outdoor athletes.” This decomposition enables the generation of targeted sub-queries that capture different facets of user intent rather than simply rephrasing the original request.
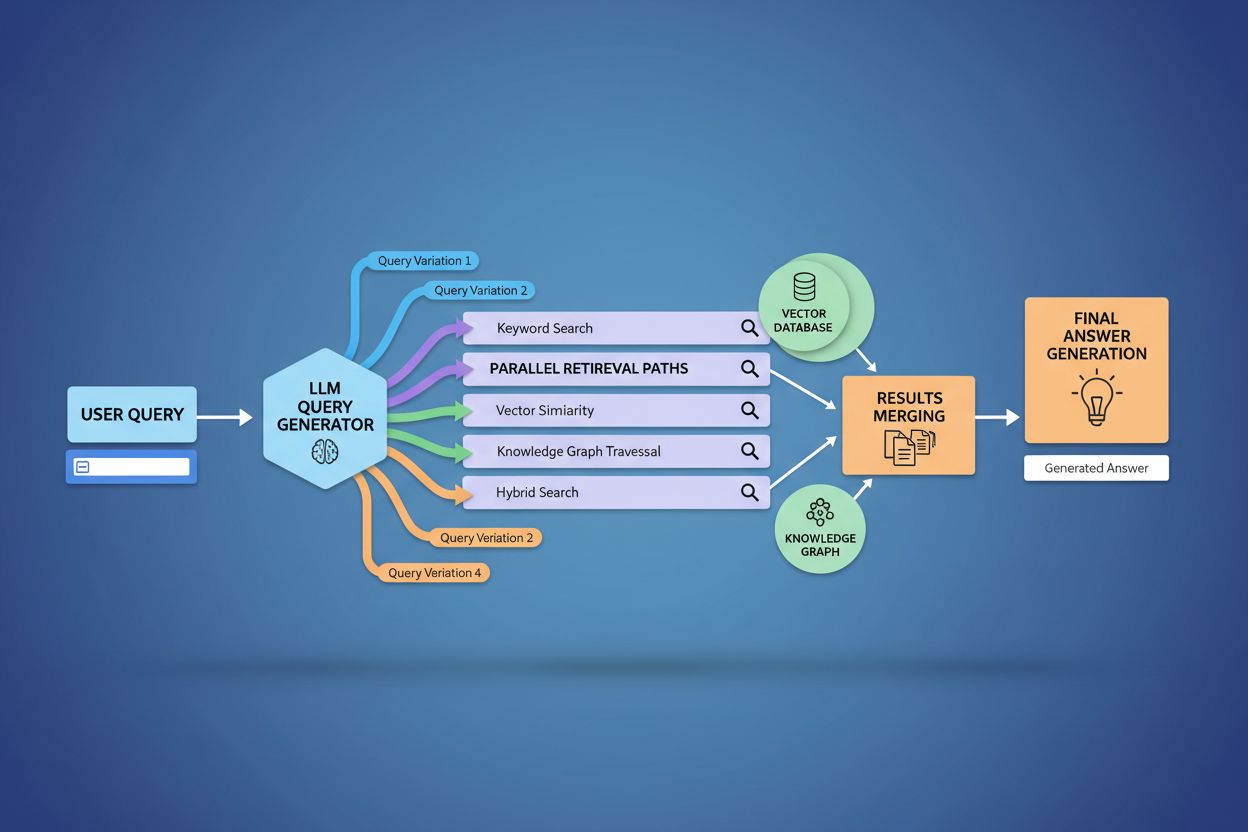
Query fanout fundamentally strengthens the retrieval component of Retrieval-Augmented Generation (RAG) frameworks by enabling richer, more diverse evidence gathering before the generation phase. In traditional RAG pipelines, a single query is embedded and matched against a vector database, potentially missing relevant information that uses different terminology or conceptual framing. Query fanout addresses this limitation by executing multiple retrieval operations in parallel, each optimized for a specific query variant, which collectively gather evidence from different angles and sources. This parallel retrieval strategy significantly reduces hallucination risk by grounding LLM responses in multiple independent sources—when the system retrieves information about “over-ear headphones,” “circumaural designs,” and “full-size headphones” separately, it can cross-reference and validate claims across these diverse retrieval results. The architecture incorporates semantic chunking and passage-based retrieval, where documents are divided into meaningful semantic units rather than fixed-length chunks, allowing the system to retrieve the most relevant passages regardless of document structure. By combining evidence from multiple sub-query retrievals, RAG systems produce responses that are more comprehensive, better-sourced, and less prone to the confident-but-incorrect outputs that plague single-query retrieval approaches.
User context and personalization signals dynamically shape how query fanout expands individual requests, creating personalized retrieval paths that may diverge significantly from one user to another. The system incorporates multiple personalization dimensions including user attributes (geographic location, demographic profile, professional role), search history patterns (previous queries and clicked results), temporal signals (time of day, season, current events), and task context (whether the user is researching, shopping, or learning). For instance, a query about “best headphones for runners” expands differently for a 22-year-old ultramarathon athlete in Kenya versus a 45-year-old recreational jogger in Minnesota—the first user’s expansion might emphasize durability and heat resistance while the second’s emphasizes comfort and accessibility. However, this personalization introduces the “two-point transformation” problem where the system treats current queries as variations of historical patterns, potentially constraining exploration and reinforcing existing preferences. Personalization can inadvertently create filter bubbles where query expansion systematically favors sources and perspectives aligned with a user’s historical behavior, limiting exposure to alternative viewpoints or emerging information. Understanding these personalization mechanisms is critical for content creators, as the same content may or may not be retrieved depending on the user’s profile and history.
Major AI platforms implement query fanout with markedly different architectures, transparency levels, and strategic approaches that reflect their underlying infrastructure and design philosophies. Google’s AI Mode employs explicit, visible query fanout where users can see the 8-12 generated sub-queries displayed alongside results, firing hundreds of individual searches against Google’s index to gather comprehensive evidence. Microsoft Copilot uses an iterative approach powered by the Bing Orchestrator, which generates 5-8 queries sequentially, refining the query set based on intermediate results before executing the final retrieval phase. Perplexity implements a hybrid retrieval strategy with multi-stage ranking, generating 6-10 queries and executing them against both web sources and its proprietary index, then applying sophisticated ranking algorithms to surface the most relevant passages. ChatGPT’s approach remains largely opaque to users, with query generation happening implicitly within the model’s internal processing, making it difficult to understand exactly how many queries are generated or how they’re executed. These architectural differences have significant implications for transparency, reproducibility, and the ability for content creators to optimize for each platform:
| Aspect | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Query Visibility | Fully visible to users | Partially visible | Visible in citations | Hidden |
| Execution Model | Parallel batch | Iterative sequential | Parallel with ranking | Internal/implicit |
| Source Diversity | Google index only | Bing + proprietary | Web + proprietary index | Training data + plugins |
| Citation Transparency | High | Medium | Very high | Low |
| Customization Options | Limited | Medium | High | Medium |
Query fanout introduces several technical and semantic challenges that can cause the system to diverge from the user’s actual intent, retrieving technically related but ultimately unhelpful information. Semantic drift occurs through generative expansion when the LLM creates query variants that, while semantically related to the original, gradually shift the meaning—a query about “best headphones for runners” might expand to “athletic headphones,” then “sports equipment,” then “fitness gear,” progressively moving away from the original intent. The system must distinguish between latent intent (what the user might want if they knew more) and explicit intent (what they actually asked for), and aggressive query expansion can conflate these categories, retrieving information about products the user never intended to consider. Iterative expansion divergence occurs when each generated query spawns additional sub-queries, creating a branching tree of increasingly tangential searches that collectively retrieve information far removed from the original request. Filter bubbles and personalization bias mean that two users asking identical questions receive systematically different query expansions based on their profiles, potentially creating echo chambers where each user’s expansion reinforces their existing preferences. Real-world scenarios demonstrate these pitfalls: a user searching for “affordable headphones” might have their query expanded to include luxury brands based on their browsing history, or a query about “headphones for hearing-impaired users” might be expanded to include general accessibility products, diluting the specificity of the original intent.
The rise of query fanout fundamentally shifts content strategy from keyword-ranking optimization toward citation-based visibility, requiring content creators to rethink how they structure and present information. Traditional SEO focused on ranking for specific keywords; AI-driven search prioritizes being cited as an authoritative source across multiple query variants and contexts. Content creators should adopt atomic, entity-rich content strategies where information is structured around specific entities (products, concepts, people) with rich semantic markup that allows AI systems to extract and cite relevant passages. Topic clustering and topical authority become increasingly important—rather than creating isolated articles about individual keywords, successful content establishes comprehensive coverage of topic areas, making it more likely to be retrieved across the diverse query variants generated by fanout. Schema markup and structured data implementation enable AI systems to understand content structure and extract relevant information more effectively, increasing the likelihood of citation. Success metrics shift from tracking keyword rankings to monitoring citation frequency through tools like AmICited.com, which tracks how often brands and content appear in AI-generated responses. Actionable best practices include: creating comprehensive, well-sourced content that addresses multiple angles of a topic; implementing rich schema markup (Organization, Product, Article schemas); building topical authority through interconnected content; and regularly auditing how your content appears in AI responses across different platforms and user segments.
Query fanout represents the most significant architectural shift in search since mobile-first indexing, fundamentally restructuring how information is discovered and presented to users. The evolution toward semantic infrastructure means that search systems will increasingly operate on meaning rather than keywords, with query fanout becoming the default mechanism for information retrieval rather than an optional enhancement. Citation metrics are becoming as important as backlinks in determining content visibility and authority—a piece of content cited across 50 different AI responses carries more weight than content ranking #1 for a single keyword. This shift creates both challenges and opportunities: traditional SEO tools that track keyword rankings become less relevant, requiring new measurement frameworks focused on citation frequency, source diversity, and appearance across different query variants. However, this evolution also creates opportunities for brands to optimize specifically for AI search by building authoritative, well-structured content that serves as a reliable source across multiple query interpretations. The future likely involves increased transparency around query fanout mechanisms, with platforms competing on how clearly they show users the reasoning behind their multi-query approach, and content creators developing specialized strategies to maximize visibility across the diverse retrieval paths that fanout creates.
Query fanout is the automated process where AI systems decompose a single user query into multiple sub-queries and execute them in parallel, while query expansion traditionally refers to adding related terms to a single query. Query fanout is more sophisticated, generating semantically diverse variants that capture different angles and interpretations of the original intent.
Query fanout significantly impacts visibility because your content must be discoverable across multiple query variants, not just the exact user query. Content that addresses different angles, uses varied terminology, and is well-structured with schema markup is more likely to be retrieved and cited across the diverse sub-queries generated by fanout.
All major AI search platforms use query fanout mechanisms: Google AI Mode uses explicit, visible fanout (8-12 queries); Microsoft Copilot uses iterative fanout via Bing Orchestrator; Perplexity implements hybrid retrieval with multi-stage ranking; and ChatGPT uses implicit query generation. Each platform implements it differently but all decompose complex queries into multiple searches.
Yes. Optimize by creating atomic, entity-rich content structured around specific concepts; implementing comprehensive schema markup; building topical authority through interconnected content; using clear, varied terminology; and addressing multiple angles of a topic. Tools like AmICited.com help you monitor how your content appears across different query decompositions.
Query fanout increases latency because multiple queries execute in parallel, but modern systems mitigate this through parallel processing. While a single query might take 200ms, executing 8 queries in parallel typically adds only 300-500ms total latency due to concurrent execution. The trade-off is worth it for improved answer quality.
Query fanout strengthens Retrieval-Augmented Generation (RAG) by enabling richer evidence gathering. Instead of retrieving documents for a single query, fanout retrieves evidence for multiple query variants in parallel, providing the LLM with more diverse, comprehensive context for generating accurate answers and reducing hallucination risk.
Personalization shapes how queries are decomposed based on user attributes (location, history, demographics), temporal signals, and task context. The same query expands differently for different users, creating personalized retrieval paths. This can improve relevance but also creates filter bubbles where users see systematically different results based on their profiles.
Query fanout represents the most significant shift in search since mobile-first indexing. Traditional keyword ranking metrics become less relevant as the same query expands differently for different users. SEO professionals must shift focus from keyword rankings to citation-based visibility, content structure, and entity optimization to succeed in AI-driven search.
Understand how your brand appears across AI search platforms when queries are expanded and decomposed. Track citations and mentions in AI-generated responses.
Learn how Query Fanout works in AI search systems. Discover how AI expands single queries into multiple sub-queries to improve answer accuracy and user intent u...

Comprehensive guide to evaluating GEO vendors with critical questions about technical capabilities, AI citation tracking, content strategy, and performance metr...
Learn the essential first steps to optimize your content for AI search engines like ChatGPT, Perplexity, and Google AI Overviews. Discover how to structure cont...