
Canonical URLs and AI: Preventing Duplicate Content Issues
Learn how canonical URLs prevent duplicate content problems in AI search systems. Discover best practices for implementing canonicals to improve AI visibility a...
6 min read

Learn how republishing content creates duplicate content issues that damage AI search visibility more severely than traditional search. Discover technical safeguards and best practices.
Republishing content across multiple channels, platforms, and formats is a legitimate and often necessary strategy for maximizing reach and engagement. However, this practice creates a fundamental tension with how search systems—particularly AI-powered ones—process and rank content. The challenge isn’t whether you can republish; it’s whether you’re doing it in a way that doesn’t sabotage your visibility in AI search results. Unlike traditional search engines that have evolved sophisticated duplicate detection mechanisms over decades, AI systems approach duplicate content differently, creating new risks that many publishers haven’t yet adapted to address.
According to Microsoft’s technical documentation on Copilot and AI search, “LLMs group near-duplicate URLs into a single cluster and then choose one page to represent the set.” This clustering behavior is fundamentally different from how Google’s PageRank algorithm distributes authority across duplicate pages. Rather than consolidating signals, AI systems make a binary decision: they select one representative page from a cluster of similar content and largely ignore the others. This selection process isn’t always predictable or based on the version you’d prefer to rank. The algorithm considers factors like freshness, content quality, technical signals, and domain authority—but the weighting of these factors remains opaque. What makes this particularly problematic is that AI systems may select an outdated version if the differences between pages are minimal enough that the clustering algorithm doesn’t detect meaningful variations.
| Aspect | Traditional Search | AI Search |
|---|---|---|
| Duplicate Handling | Consolidates authority signals | Clusters and selects single representative |
| Penalty Risk | Possible manual action | No penalty, but visibility dilution |
| Update Recognition | Gradual signal propagation | May miss updates if differences minimal |
| Crawl Efficiency | Wastes budget on duplicates | Reduces crawl priority for duplicates |
| Canonical Respect | Honored but not guaranteed | Critical for cluster selection |
Republishing without proper safeguards introduces three interconnected risks that directly impact AI visibility:
Intent Signal Dilution: When the same content appears across multiple URLs, the AI system receives conflicting signals about which version best answers the user’s query. Instead of concentrating authority on a single URL, your signals scatter across the cluster. This dilution reduces the confidence score that AI systems assign to your content when deciding whether to include it in responses. A piece of content that could have been a primary source becomes a secondary consideration because the system can’t confidently determine which version is authoritative.
Representation Risk: The AI system’s selection of which page represents your content cluster may not align with your business objectives. You might republish a blog post to a syndication network expecting that version to drive traffic, only to have the AI system select your original domain version—or worse, select the syndicated version that doesn’t link back to your site. This misalignment means your republishing strategy actively works against your visibility goals rather than amplifying them.
Update Latency and Staleness: When you update your original content but the republished versions remain unchanged, AI systems may select an outdated version as the representative page. The clustering algorithm doesn’t always recognize that one version is newer or more accurate than others, particularly if the changes are incremental rather than structural. This creates a scenario where your most current, accurate content is invisible while an older version represents your expertise to AI systems.
The most common republishing mistake occurs when content is syndicated to third-party platforms without implementing canonical tags. Consider a typical scenario: a B2B software company publishes a comprehensive guide on their blog, then syndicates it to industry publications like Medium, LinkedIn, and specialized news aggregators. Each platform hosts the identical content under different URLs. Without canonical tags pointing back to the original, the AI system’s clustering algorithm treats all versions as equally authoritative. The syndication platform might have higher domain authority, causing the AI system to select that version as the representative page. Now your original content—the version you optimized, updated, and built backlinks to—becomes invisible in AI search results. The traffic and authority flow to the syndication platform instead of your owned property. This scenario repeats thousands of times daily across the publishing industry, with publishers unknowingly sabotaging their own visibility by failing to implement a single HTML tag.
Campaign-specific content creates a particularly insidious duplicate content problem when republished across channels. A marketing team launches a campaign landing page optimized for a specific promotion, then republishes variations of that content to email newsletters, social media, paid ads, and partner sites. Each version contains slightly different copy, CTAs, or formatting—but the core content and intent remain identical. AI systems recognize these as near-duplicates and cluster them together. The problem intensifies when campaign pages are republished without proper canonical implementation. The AI system might select the email newsletter version (which has no conversion tracking) as the representative page, or the partner site version that doesn’t benefit your metrics. Additionally, when campaigns end and pages are archived or deleted, the AI system may have already selected a now-defunct version as the representative page, creating a situation where your content becomes invisible or directs users to broken experiences.
Regional republishing introduces complexity because duplicate content detection must account for legitimate localization needs. A company with operations in multiple countries might publish the same core content in different languages or with region-specific variations. Without proper implementation, these regional versions compete with each other in AI clustering. Consider a SaaS company that publishes a feature guide in English on their US domain, then republishes it to their UK domain with British English spelling and region-specific pricing. The AI system clusters these as duplicates, potentially selecting the US version even for UK users. The solution requires implementing hreflang tags that signal regional relationships to AI systems, though the effectiveness of hreflang in AI search remains less established than in traditional search.
<!-- On US version (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- On UK version (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
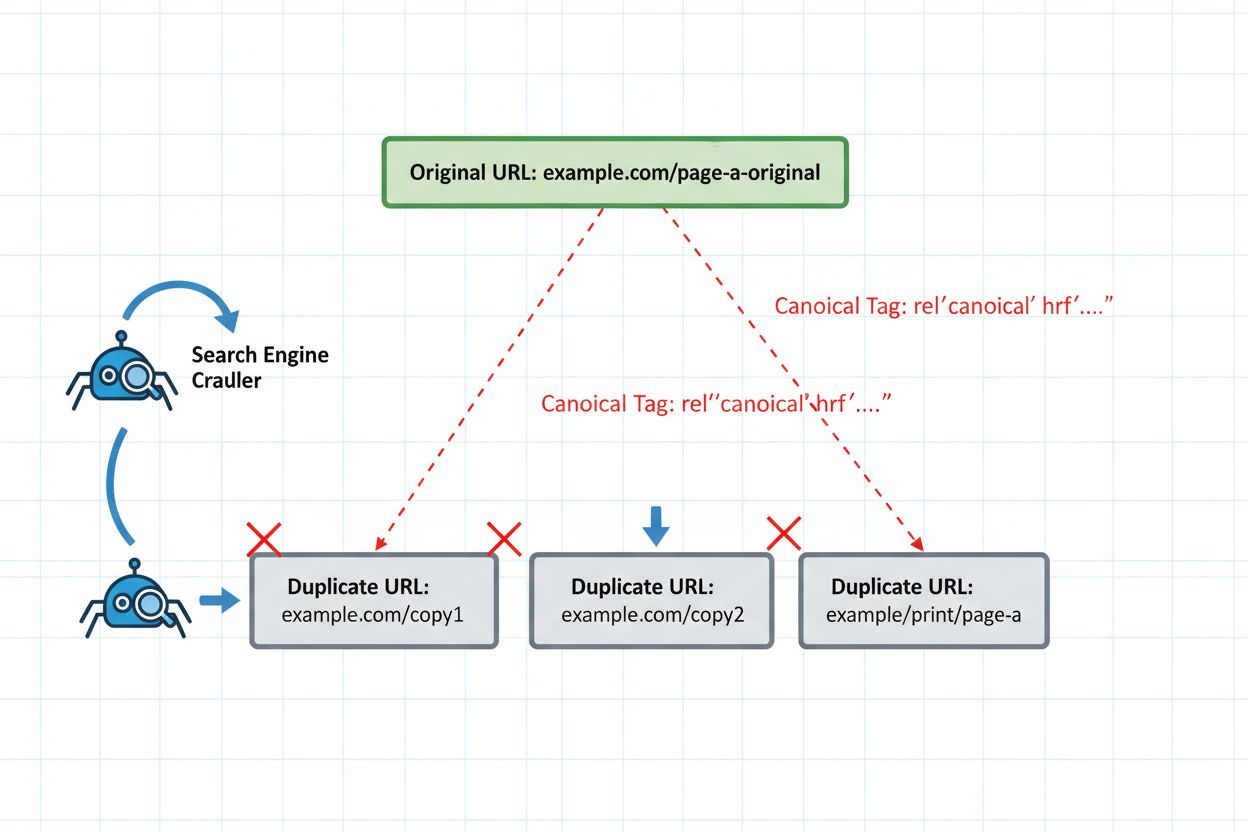
Implementing proper technical safeguards is non-negotiable for safe republishing. The canonical tag remains your primary defense, explicitly telling AI systems which version should represent your content cluster. Place the canonical tag in the <head> section of every republished version, pointing to your preferred authoritative version. For syndicated content, this typically means pointing back to your original domain.
<!-- On syndicated version (medium.com/your-publication/article) -->
<link rel="canonical" href="https://yoursite.com/blog/article" />
For content that should never compete with other versions, implement noindex on secondary versions. This completely removes them from AI indexing, ensuring they can’t be selected as representative pages. Use this approach for internal duplicate pages, test versions, or syndicated content where you want zero visibility in AI search.
<!-- On secondary version that should not be indexed -->
<meta name="robots" content="noindex, follow" />
301 redirects provide the strongest signal for consolidating authority, but use them only when the secondary version will never be updated independently. Redirects tell AI systems that the old URL has permanently moved, consolidating all signals to the new location. However, if you need both versions to remain live (as with syndication), redirects create problems because they break the syndication platform’s URL structure.
# In .htaccess or server configuration
Redirect 301 /old-article https://yoursite.com/new-article
For content management systems, implement rel=“canonical” dynamically to handle pagination, parameter variations, and session-based URLs that create unintentional duplicates. Many CMS platforms generate multiple URLs for the same content through different navigation paths—canonical tags consolidate these automatically.
IndexNow accelerates the discovery of canonical signals and duplicate consolidation, reducing what would traditionally take weeks to accomplish in days. When you implement canonical tags on republished content, IndexNow notifies search systems immediately that these URLs should be clustered together. Rather than waiting for crawlers to discover the canonical relationship through normal crawling patterns, IndexNow pushes this information directly to Microsoft’s index and other participating search systems. This is particularly valuable when you’re retroactively fixing republishing mistakes—you can implement canonical tags and use IndexNow to signal the change immediately, rather than waiting for crawlers to revisit the pages. For publishers managing content across multiple platforms, IndexNow becomes a critical tool for maintaining control over which version represents your content cluster. The API integration allows you to submit URLs in bulk, making it practical to manage hundreds or thousands of republished pages.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/article-1",
"https://yoursite.com/blog/article-2"
]
}
Tracking which version of your republished content gets selected by AI systems requires monitoring beyond traditional analytics. Set up tracking to identify when AI systems cite or reference your content, noting which URL appears in AI search results. Tools like Semrush, Ahrefs, and Moz are beginning to add AI search visibility metrics, though these remain less mature than traditional search tracking. Implement UTM parameters on syndicated versions to track traffic attribution, but recognize that AI systems may not pass through these parameters, making direct attribution difficult. Monitor your Search Console (or equivalent tools for other search systems) for crawl patterns—if secondary versions are being crawled more frequently than your canonical version, it indicates the AI system may have selected the wrong representative page. Set up alerts for mentions of your content across syndication platforms, and cross-reference these with your AI search visibility to identify misalignment between where your content appears and where AI systems are selecting it from.
Implement this checklist before republishing any content to ensure you maintain control over AI visibility:
Before republishing, identify your canonical version—the URL you want to represent this content in AI search results. This should typically be your owned domain, not a syndication platform. Implement canonical tags on every republished version pointing to your canonical URL, even if you’re republishing to your own properties (different domains, subdomains, or parameter variations). Use IndexNow to immediately notify search systems of the canonical relationship, rather than waiting for crawl discovery. Avoid republishing to high-authority platforms without canonical support—some platforms strip canonical tags or don’t allow them, making them unsuitable for republishing without accepting visibility loss. Monitor the first 48 hours after republishing to verify that AI systems are selecting your intended canonical version, not an alternative. Update all versions simultaneously when you make content changes—if you update only the canonical version, the clustering algorithm may not recognize the update across all versions, potentially causing the AI system to select an outdated version. Establish a republishing schedule that prevents content from becoming stale on secondary platforms; outdated syndicated content increases the risk that AI systems will select it as the representative version if your canonical version hasn’t been updated recently.
Canonical tags don't prevent penalties because duplicate content doesn't trigger penalties in the first place. However, canonical tags are critical for AI search because they tell AI systems which version should represent your content cluster. Without canonical tags, AI systems may select an unintended version as the authoritative source, reducing your visibility.
Monitor which URLs appear in AI search results and citations for your content. Tools like Semrush and Ahrefs are adding AI search visibility metrics. Check your Search Console for crawl patterns—if secondary versions are crawled more frequently than your canonical version, the AI system may have selected the wrong page.
Technically yes, but it's not recommended. Without canonical tags, AI systems will cluster your content and select one version as representative—but you won't control which one. The syndication platform might have higher authority, causing AI to select that version instead of your original domain.
Republishing typically refers to distributing your content across multiple channels you control or partner with. Content syndication is a specific form of republishing where third-party platforms republish your content with your permission. Both create duplicate content issues if not properly managed with canonical tags.
Canonical tags are typically recognized within 24-48 hours if you use IndexNow to notify search systems immediately. Without IndexNow, it may take weeks for crawlers to discover the canonical relationship. This is why IndexNow is critical for managing republished content—it accelerates the process significantly.
Use 301 redirects only when you want to permanently consolidate URLs and the secondary version will never be updated independently. Use canonical tags when both versions need to remain live (as with syndication). Redirects are stronger signals but break the secondary URL's functionality.
Yes, if not properly managed. Republishing without canonical tags dilutes your authority signals across multiple URLs. AI systems may select the syndicated version instead of your original, reducing visibility on your owned domain. Proper canonical implementation prevents this.
Implement canonical tags on every republished version pointing to your original domain. Use IndexNow to immediately notify search systems of the canonical relationship. Avoid republishing to platforms that don't support canonical tags. Monitor which version AI systems select in the first 48 hours and adjust if needed.
Track how AI systems cite and reference your republished content across all platforms. Get real-time insights into which version AI selects as your authoritative source.
Learn how canonical URLs prevent duplicate content problems in AI search systems. Discover best practices for implementing canonicals to improve AI visibility a...

Learn how to manage and prevent duplicate content when using AI tools. Discover canonical tags, redirects, detection tools, and best practices for maintaining u...
Learn how to repurpose and optimize content for AI platforms like ChatGPT, Perplexity, and Claude. Discover strategies for AI visibility, content structuring, a...