
What Schema Markup Helps with AI Search? Complete Guide for 2025
Discover which schema markup types boost your visibility in AI search engines like ChatGPT, Perplexity, and Gemini. Learn JSON-LD implementation strategies for ...
9 min read

Learn which schema types matter most for AI visibility. Discover how LLMs interpret structured data and implement schema markup strategies that get your brand cited in AI answers.
For years, schema markup was primarily about winning rich results—those eye-catching star ratings, product cards, and FAQ accordions that appeared in traditional search results. Today, that playbook is becoming obsolete. Large language models and AI answer engines interpret schema markup in fundamentally different ways, using it not for cosmetic enhancements but for building knowledge graphs and understanding entity relationships at scale. With approximately 45 million websites (12.4% of all registered domains) now implementing some form of schema.org markup, AI systems have access to unprecedented amounts of structured data to learn from and rely upon. The shift is profound: schema markup now influences whether your brand gets cited in AI-generated answers, how accurately models represent your products and services, and whether your content becomes a trusted source in an AI-first search landscape.
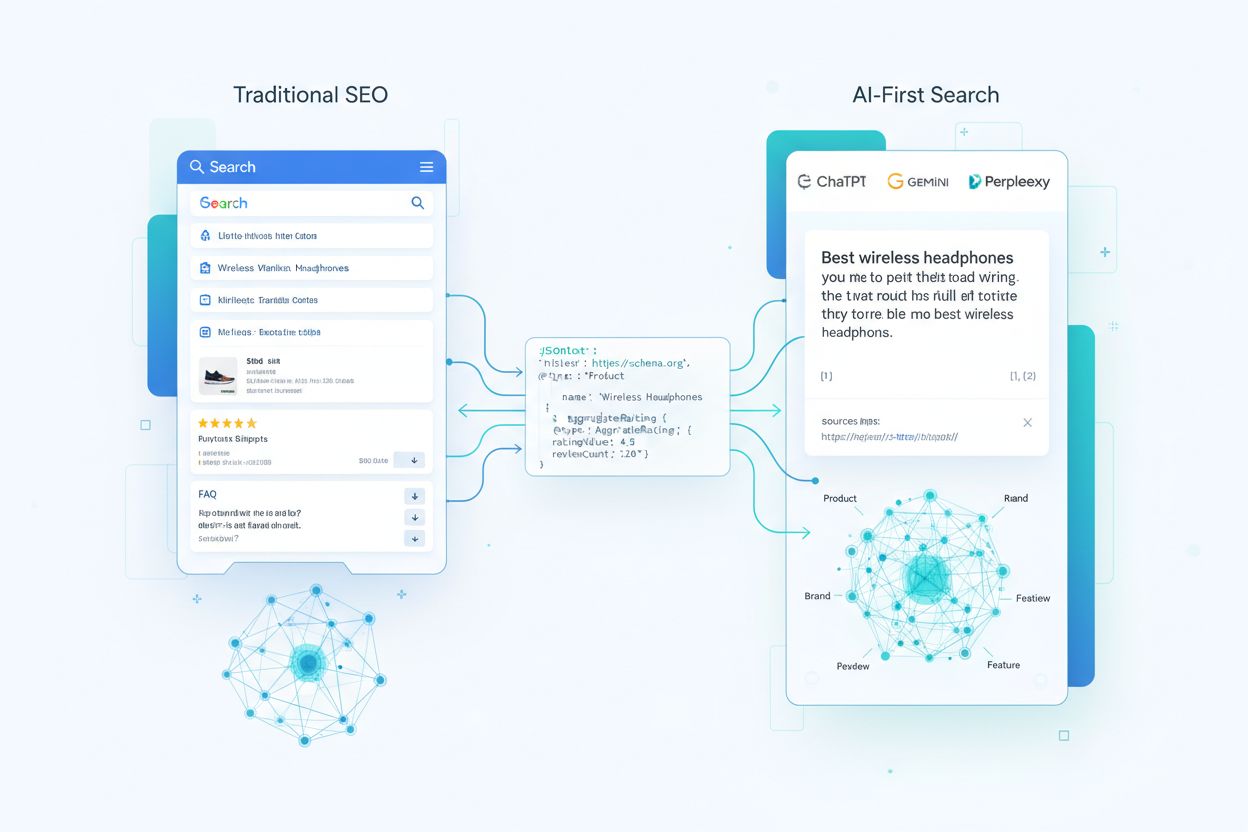
Understanding how AI systems consume schema markup requires tracing the journey of your structured data from initial crawl through to LLM-generated answers. When a crawler encounters your page, it extracts JSON-LD, microdata, or RDFa blocks and normalizes them into an index alongside unstructured text and media. This structured data becomes part of a web-scale knowledge graph, where entities are connected through relationships and assigned embeddings for semantic search. In retrieval-augmented generation (RAG) systems, schema can be folded directly into the chunks that populate vector indices—a single chunk might contain both a product description and its JSON-LD markup, providing models with both narrative context and structured key-value attributes. Different LLM architectures consume schema differently: some layer models on top of existing search indices and knowledge graphs, while others use multi-source retrieval pipelines that pull from both structured and unstructured content. The critical insight is that well-implemented schema acts as a contract with the model, stating in highly structured form which facts on your page you consider canonical and trustworthy.
| Architecture Type | Schema Usage | Citation Impact | Key Properties |
|---|---|---|---|
| Traditional Search + LLM Layer | Enhances existing knowledge graph | High - models cite well-structured sources | Organization, Product, Article |
| Retrieval-Augmented Generation | Folded into vector chunks | Medium-High - schema helps with precision | All types with detailed properties |
| Multi-Source Answer Engines | Used for entity resolution | Medium - competes with other signals | Person, LocalBusiness, Service |
| Conversational AI | Supports context understanding | Variable - depends on training data | FAQPage, HowTo, BlogPosting |
Not all schema types carry equal weight in the AI era. Organization markup serves as the anchor for your entire entity graph, helping models understand your brand identity, authority, and relationships. Product schema is essential for e-commerce and retail, enabling AI systems to compare features, prices, and ratings across sources. Article and BlogPosting markup help models identify long-form content suitable for explanatory queries and thought leadership. Person schema is critical for establishing author credibility and expert attribution in AI-generated answers. FAQPage markup directly maps to conversational queries that AI assistants are designed to answer. For SaaS and B2B companies, SoftwareApplication and Service types are equally important, appearing frequently in “best tools for X” comparisons and feature evaluations. For local businesses and healthcare providers, LocalBusiness and MedicalOrganization types provide geographic precision and regulatory clarity. The real differentiation, however, comes not from basic type adoption but from the advanced properties you layer on top—consistency across pages, clear entity identifiers, and explicit relationship mapping.
Basic schema properties like name, description, and URL are now table stakes; 72.6% of pages ranking on Google’s first page already use some form of schema markup. The properties that create real differentiation for AI visibility are the connective tissue that helps models resolve entities, understand relationships, and disambiguate meaning. Here are the advanced properties that matter most:
These properties transform schema from a simple data container into a semantic map that models can navigate with confidence. When you use sameAs to link your organization to its Wikipedia page, you’re not just adding metadata—you’re telling the model “this is the authoritative source for facts about us.” When you use additionalProperty to encode product specifications or service features, you’re providing the exact attributes that AI systems look for when assembling comparisons or recommendations.
Most organizations approach schema markup as a one-time implementation task, but competitive advantage in AI-driven search requires thinking of it as an ongoing data governance discipline. A useful framework is a four-level maturity model that helps teams understand where they are and where they need to go:
Level 1 – Basic Rich Result Schema focuses on minimal markup on select templates, primarily to achieve eligibility for stars, product cards, or FAQ snippets. Governance is loose, consistency is low, and the goal is cosmetic enhancement rather than semantic clarity.
Level 2 – Entity-Centric Coverage standardizes Organization, Product, Article, and Person markup across key templates, introduces consistent use of @id values, and adds basic sameAs links to prevent entity confusion.
Level 3 – Knowledge-Graph-Integrated Schema aligns schema IDs to internal data models (CMS, PIM, CRM), makes extensive use of about/mentions/additionalType properties, and encodes cross-page relationships so that models understand how content nodes relate to each other and to external entities.
Level 4 – LLM-Optimized & RAG-Aligned Schema deliberately structures markup for conversational queries and AI snippet formats, aligns schema with internal RAG pipelines, and includes measurement and iteration as core practices.
Most brands currently plateau at Levels 1–2, which means basic adoption is now a hygiene factor, not a differentiator. Pushing into Levels 3–4 is where schema LLM optimization becomes a durable competitive moat, because models can reliably interpret your entities across many query formulations and surfaces.
Different industries have different entities, risk profiles, and user intents, so advanced schema usage cannot be one-size-fits-all. The core principles—entity clarity, relationship modeling, and alignment with on-page content—remain constant, but the schema types and properties you emphasize should reflect how people actually search in your vertical.
For E-Commerce and Retail, the primary entities are Products, Offers, Reviews, and your Organization. Every high-intent product page should expose granular Product markup that includes identifiers (SKU, GTIN), brand, model, dimensions, materials, and differentiating attributes via additionalProperty. Pair this with Offers encoding pricing and availability, and AggregateRating structures that help models understand social proof. Beyond the basics, think about how shoppers phrase questions: “Is this waterproof?” “Does it come with a warranty?” “What’s the return policy?” Encoding those answers as FAQPage markup on the same URL and ensuring that Product attributes and FAQ content stay in sync makes it much easier for answer engines to cite the correct page.
For SaaS and B2B Services, entities are more abstract but map well to SoftwareApplication, Service, and Organization schema. For each core product or offering, define a SoftwareApplication or Service entity with clear descriptions of category, supported platforms, integrations, and pricing models, using additionalProperty fields to enumerate features that often appear in “best tools for X” comparisons. Connect these to your Organization via provider or offers relationships, and to your expert team members via Person markup. On the content side, Article, BlogPosting, FAQPage, and HowTo structures help LLMs identify your best assets for evaluative and educational queries.
For Local, Healthcare, and Regulated Industries, LocalBusiness, MedicalOrganization, and related MedicalEntity types can encode addresses, service areas, specialties, accepted insurance, and operating hours in far less ambiguous ways than free text. This matters when an AI assistant is asked to “find a pediatric cardiologist near me that accepts my insurance” or “recommend an urgent care open now.” In these sectors, be especially careful that schema doesn’t overclaim or expose sensitive details—only mark up facts you’re comfortable having reused in many contexts, and ensure compliance and legal teams review any medically oriented or regulated attributes.
LLM behavior is inherently stochastic, so you won’t achieve pixel-perfect attribution from schema changes alone. What you can do is build a lightweight monitoring system that samples AI answers on a regular cadence for a defined query set. Track which entities are mentioned, which URLs are cited, how your brand is described, and whether key facts (pricing, capabilities, compliance details) are accurate across platforms like ChatGPT, Gemini, Perplexity, and Bing Copilot. When things go wrong—hallucinated features, missing mentions, or citations that favor aggregators over your primary pages—start by checking for conflicting or incomplete signals. Does the on-page copy contradict the schema? Are sameAs links missing or pointing to outdated profiles? Do multiple pages claim to be the canonical source for the same entity? At a strategic level, plan a schema review at least quarterly to align with new offerings, content clusters, and shifts in how AI answer engines are surfacing your brand.
Several patterns consistently undermine schema effectiveness for AI systems. Marking up content that isn’t actually visible on the page creates a trust deficit—models learn to discount sources where schema and visible content diverge. Using overly generic types without specificity (e.g., marking everything as “Thing” or “CreativeWork”) provides no semantic signal; models need precise types to understand context. Copying boilerplate schema across pages without adjusting entity details is perhaps the most common mistake—when every product page has identical Organization markup or every article claims the same author, models struggle to disambiguate and may deprioritize your content as low-signal. Inconsistent entity identifiers across pages (using different @id values for the same organization or product) breaks entity resolution and forces models to treat related content as separate entities. Missing sameAs links to authoritative profiles leaves models vulnerable to confusing your brand with namesakes. Finally, conflicting information between schema and on-page copy signals unreliability; if your schema says a product is in stock but the page says “out of stock,” models will trust neither source.
Schema markup is transitioning from a cosmetic SEO tactic to a foundational technology for AI-first search. Connected schema markup—where you explicitly define relationships between entities using properties like sameAs, about, and mentions—builds knowledge graphs that AI systems can navigate with confidence. The competitive advantage no longer goes to those who ask “What minimum schema do we need for a rich result?” but to those who ask “What structured representation would make our content unambiguous to a machine, even outside the SERP?” This shift pushes organizations toward more complete, interconnected, and entity-centric schema patterns. As AI-driven search becomes a primary discovery channel, schema LLM optimization evolves from a technical curiosity into a core SEO discipline. Organizations that advance through the maturity levels—from basic rich result schema to knowledge-graph-integrated and LLM-optimized patterns—will build durable moats in AI-driven discovery, ensuring their brands are cited as authorities and their content surfaces as trusted sources.
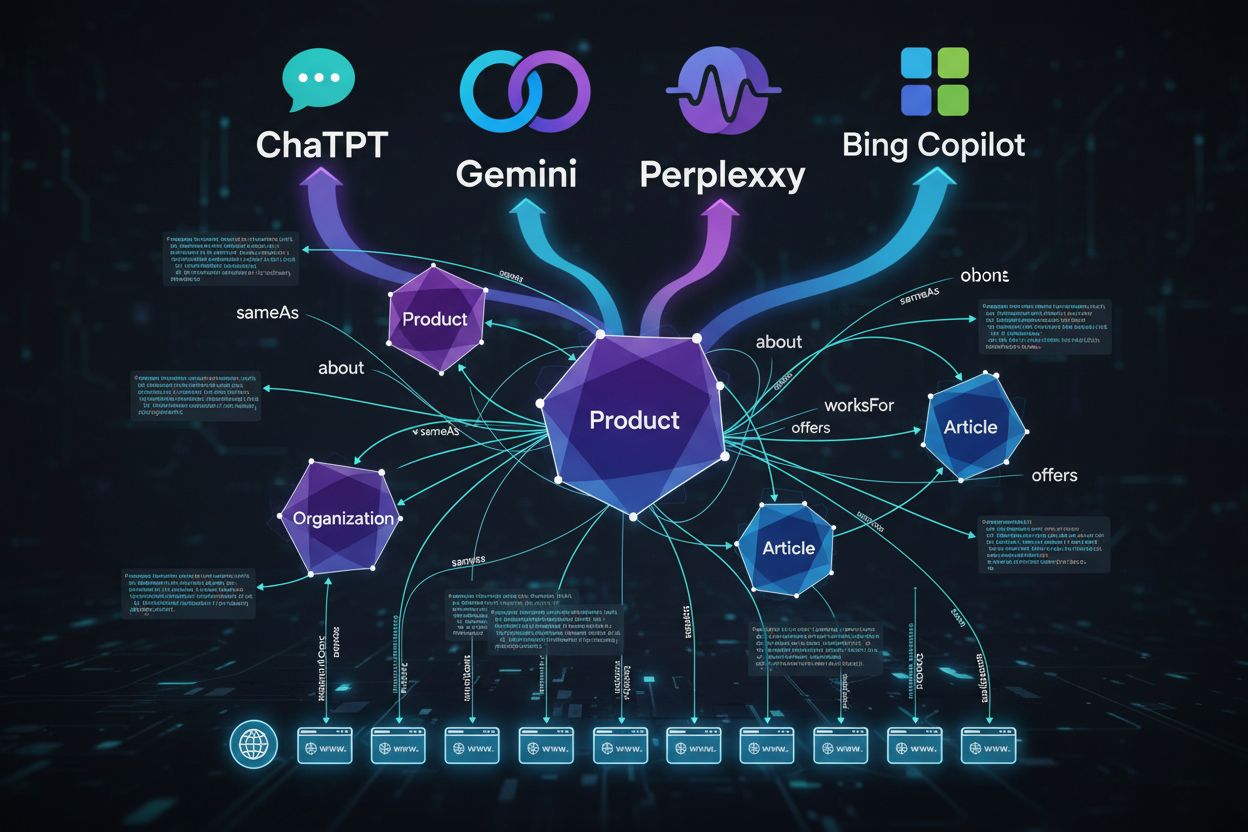
Traditional schema focused on rich results (stars, snippets). For AI, schema is about entity clarity, relationships, and knowledge graphs. AI systems use schema to understand what your content is about at a semantic level, not just for visual enhancements.
Organization, Product, Article, Person, and FAQPage are foundational. For SaaS, add SoftwareApplication and Service. For local/healthcare, add LocalBusiness and MedicalOrganization. The importance varies by industry and user intent.
No. Start with Organization and your highest-value pages (products, services, key articles). Gradually extend coverage based on your business model and where AI answers would be most valuable.
Schema changes can influence AI citations within weeks, but the relationship is probabilistic. Plan for quarterly reviews and continuous monitoring across multiple AI platforms to track impact.
sameAs links your entity to canonical profiles (Wikipedia, LinkedIn) to prevent confusion with namesakes. about/mentions clarifies what your page is truly focused on, helping models understand nuance and context.
No. Schema works best when aligned with high-quality, well-structured on-page content. Models need both the structured data and the narrative context to confidently cite your pages.
Monitor AI answers across platforms (ChatGPT, Gemini, Perplexity, Bing) for your target queries. Track entity mentions, URL citations, accuracy of facts, and brand description. Look for trends over weeks/months.
JSON-LD is the recommended format for most use cases. It's easier to implement, maintain, and doesn't interfere with HTML. Microdata and RDFa are less common in modern implementations.
Track how AI systems cite your brand across ChatGPT, Gemini, Perplexity, and Google AI Overviews. Get insights into which schema types are driving visibility.
Discover which schema markup types boost your visibility in AI search engines like ChatGPT, Perplexity, and Gemini. Learn JSON-LD implementation strategies for ...
Learn how to implement HowTo schema markup for better visibility in AI search engines. Step-by-step guide to adding structured data for ChatGPT, Perplexity, and...
Schema markup is standardized code that helps search engines understand content. Learn how structured data improves SEO, enables rich results, and supports AI s...