
Token
Learn what tokens are in language models. Tokens are fundamental units of text processing in AI systems, representing words, subwords, or characters as numerica...
20 min read

Explore how token limits affect AI performance and learn practical strategies for content optimization including RAG, chunking, and summarization techniques.
Tokens are the fundamental building blocks that AI models use to process and understand information. Rather than working with complete words or sentences, large language models break down text into smaller units called tokens, which can be individual characters, subwords, or complete words depending on the tokenization algorithm. Each token is assigned a unique numerical identifier that the model uses internally for computation. This tokenization process is essential because it allows AI systems to handle variable-length inputs efficiently and maintain consistent processing across different types of content. Understanding tokens is crucial for anyone working with AI systems, as they directly impact performance, cost, and the quality of results you can achieve.
Different AI models have vastly different token limits, which define the maximum amount of information they can process in a single request. These limits have evolved dramatically over recent years, with newer models supporting significantly larger context windows. The token limit encompasses both input tokens (your prompt and data) and output tokens (the model’s response), creating a shared budget that must be carefully managed. Understanding these limits is essential for selecting the right model for your use case and planning your application architecture accordingly.
| Model | Token Limit | Primary Use Case | Cost Level |
|---|---|---|---|
| GPT-3.5 Turbo | 4,096 | Short conversations, quick tasks | Low |
| GPT-4 | 8,192 | Standard applications, moderate complexity | Medium |
| GPT-4 Turbo | 128,000 | Long documents, complex analysis | High |
| Claude 3.5 Sonnet | 200,000 | Extended documents, comprehensive analysis | High |
| Gemini 1.5 Pro | 1,000,000 | Massive datasets, entire books, video analysis | Very High |
Key considerations when evaluating token limits:
Token limits create significant constraints that directly affect the accuracy, reliability, and cost-effectiveness of AI applications. When you exceed a model’s token limit, the application fails entirely—there’s no graceful degradation or partial processing. Even when staying within limits, naive approaches like simple truncation can severely degrade performance by removing critical context that the model needs to generate accurate responses. This is particularly problematic in domains like legal analysis, medical research, and software engineering, where missing even a single important detail can lead to incorrect conclusions. The challenge becomes even more complex when you consider that different types of content consume tokens at different rates—structured data like code or JSON requires significantly more tokens than plain English text due to symbols and formatting.
Truncation is the simplest method for handling token limits—you simply cut off excess content when it exceeds the model’s capacity. While straightforward to implement, this approach carries significant risks. When you truncate text, you inevitably lose information, and the model has no way of knowing what was removed. This can lead to incomplete analysis, missed context, and hallucinations where the model generates plausible-sounding but incorrect information to fill gaps in its understanding.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
A more sophisticated truncation strategy distinguishes between essential and optional content. You can prioritize must-have elements like the current user query and core instructions, then append optional context like conversation history only if space permits. This approach preserves critical information while still respecting token limits.
Rather than truncating, chunking breaks your content into smaller, manageable pieces that can be processed independently or selectively. Fixed-size chunking divides text into uniform segments, while semantic chunking uses embeddings to identify natural breakpoints based on meaning rather than arbitrary token counts. Sliding windows with overlap preserve context between chunks, ensuring that important information spanning chunk boundaries isn’t lost.
Hierarchical chunking creates multiple levels of abstraction—individual paragraphs at the finest level, sections at the next level, and chapters at the highest level. This approach enables sophisticated retrieval strategies where you can quickly identify relevant sections without processing the entire document. When combined with vector databases and semantic search, chunking becomes a powerful tool for managing large knowledge bases while maintaining relevance and accuracy.
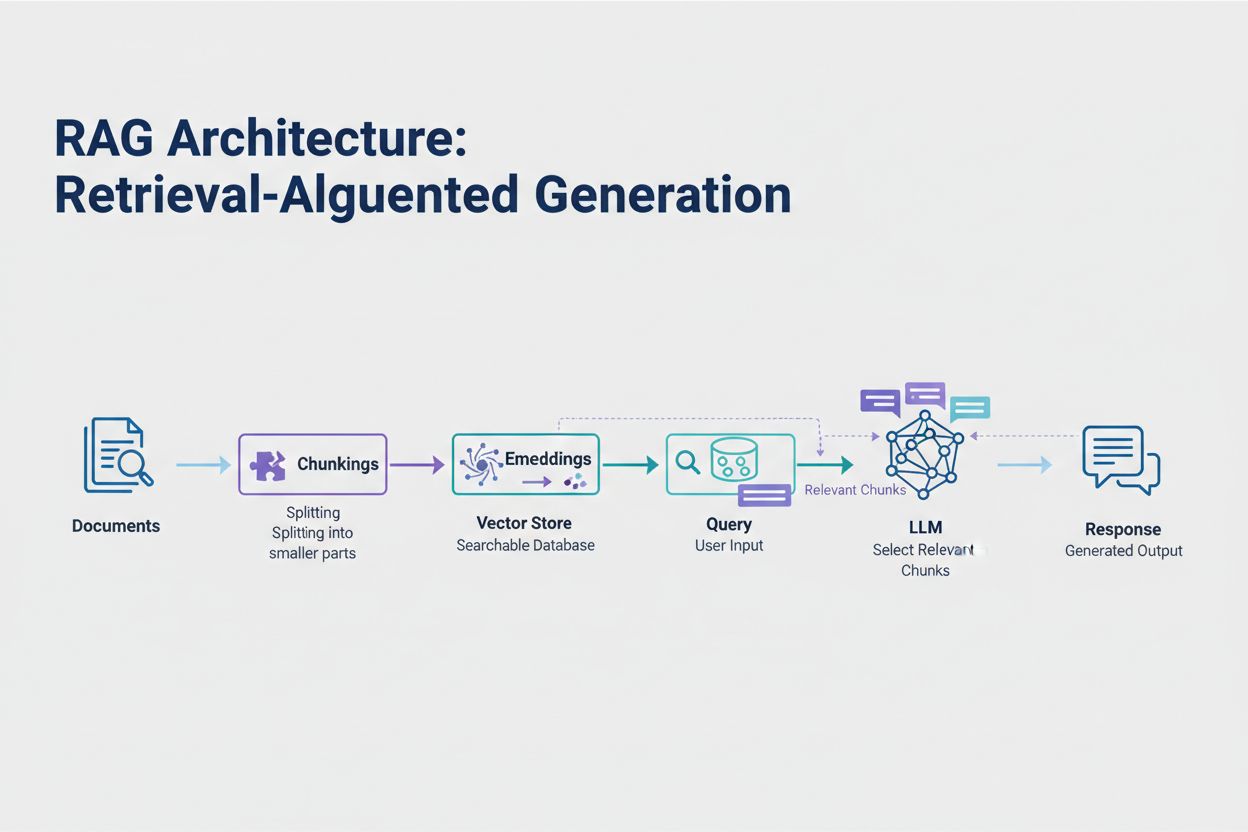
Retrieval-Augmented Generation (RAG) represents the most effective modern approach to handling token limits. Instead of trying to fit all your data into the model’s context window, RAG retrieves only the most relevant information at query time. The process begins by converting your documents into embeddings—numerical representations that capture semantic meaning. These embeddings are stored in a vector database, enabling fast similarity searches.
When a user submits a query, the system embeds the query and retrieves the most relevant document chunks from the vector store. Only these relevant chunks are injected into the prompt alongside the user’s question, dramatically reducing token consumption while improving accuracy. For example, analyzing a 100-page legal contract with RAG might require only 3-5 key clauses in the prompt, compared to the thousands of tokens needed to include the entire document.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
Summarization condenses lengthy content while preserving essential information, effectively reducing token consumption. Extractive summarization selects key sentences from the original text, while abstractive summarization generates new, concise text that captures the main ideas. Hierarchical summarization creates multiple levels of summaries—first summarizing individual sections, then combining those summaries into higher-level overviews. This approach works particularly well for structured documents like research papers or technical reports.
Context compression takes a different approach by removing redundancy and filler content while maintaining the original phrasing. Knowledge graph approaches extract entities and relationships from text, then reconstruct context using only the most relevant facts. These techniques can achieve 40-60% token reduction while maintaining semantic accuracy, making them valuable for cost optimization in production systems.
Token management directly impacts your AI application costs. Each token consumed during inference incurs a charge, and costs scale linearly with token usage. Monitoring token consumption is essential for understanding your cost structure and identifying optimization opportunities. Many AI platforms now offer token counting utilities and real-time dashboards that track usage patterns, helping you identify which queries or features consume the most tokens.
Effective monitoring reveals optimization opportunities—perhaps certain types of queries consistently exceed token limits, or specific features consume disproportionate resources. By tracking these patterns, you can make informed decisions about which optimization strategy to implement. Some applications benefit from routing large requests to more capable (but more expensive) models, while others benefit more from implementing RAG or summarization. The key is measuring actual performance and costs to validate your optimization choices.
Choosing the right token management strategy depends on your specific use case, performance requirements, and cost constraints. Applications requiring high accuracy with sourced answers benefit most from RAG, which preserves information fidelity while managing token consumption. Long-running conversational applications benefit from memory buffering techniques that summarize conversation history while preserving key decisions and context. Document-heavy applications like legal analysis or research tools often benefit from hierarchical summarization combined with semantic chunking.
Testing and validation are critical before deploying any token management strategy to production. Create test cases that exceed your model’s token limits, then evaluate how different strategies affect accuracy, latency, and cost. Measure metrics like answer relevance, factual accuracy, and token efficiency to ensure your chosen approach meets your requirements. Common pitfalls include over-aggressive summarization that loses critical details, retrieval systems that miss relevant information, and chunking strategies that break content at semantically inappropriate boundaries.
Token limits continue to expand as models become more sophisticated and efficient. Emerging techniques like sparse attention mechanisms and efficient transformers promise to reduce the computational cost of processing large context windows. Multimodal models that handle text, images, audio, and video simultaneously introduce new tokenization challenges and opportunities. Reasoning tokens—special tokens used by models to “think through” complex problems—represent a new category of token consumption that enables more sophisticated problem-solving but requires careful management.
The trajectory is clear: as context windows expand and token processing becomes more efficient, the bottleneck shifts from raw capacity to intelligent content selection. The future belongs to systems that can effectively identify and retrieve the most relevant information from massive knowledge bases, rather than systems that simply process larger volumes of data. This makes techniques like RAG and semantic search increasingly important for building scalable, cost-effective AI applications.
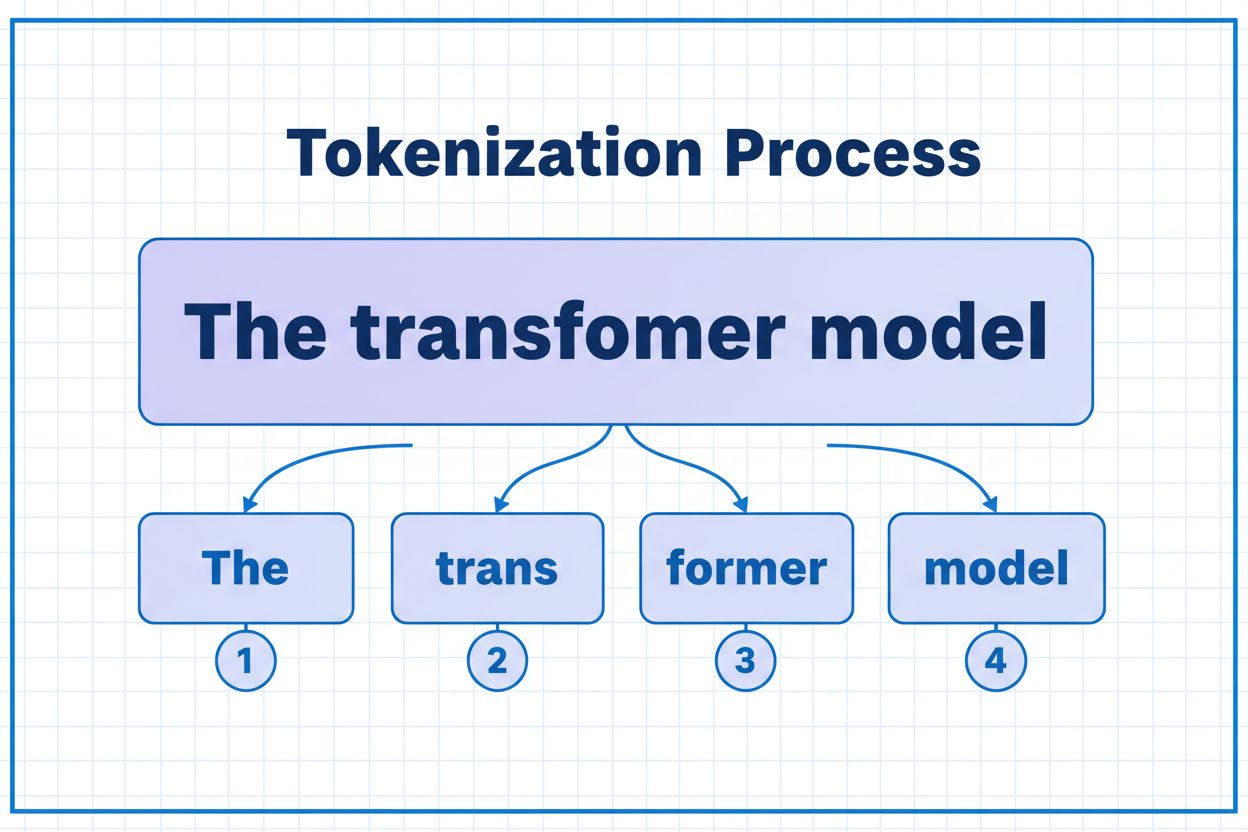
A token is the smallest unit of data that an AI model processes. Tokens can be individual characters, subwords, or complete words depending on the tokenization algorithm. For example, the word 'transformer' might be split into 'trans' and 'former' as two separate tokens. Each token is assigned a unique numerical identifier that the model uses internally for computation.
Token limits define the maximum amount of information your AI model can process in a single request. When you exceed this limit, your application fails entirely. Even when staying within limits, naive approaches like truncation can degrade accuracy by removing critical context. Token limits also directly impact costs, as you typically pay per token consumed.
Input tokens are the tokens in your prompt and data that you send to the model, while output tokens are the tokens the model generates in its response. These share a combined budget defined by the model's context window. If your input uses 90% of a 128K token window, you only have 10% remaining for the model's output.
Truncation is simple to implement but risky. It removes information without the model knowing what was lost, leading to incomplete analysis and potential hallucinations. While useful as a last resort, better approaches like RAG, chunking, or summarization preserve information fidelity while managing token consumption more effectively.
Retrieval-Augmented Generation (RAG) retrieves only the most relevant information at query time instead of including entire documents. Your documents are converted to embeddings and stored in a vector database. When a user queries, the system retrieves only relevant chunks and injects them into the prompt, dramatically reducing token consumption while improving accuracy.
Most AI platforms offer token counting utilities and real-time dashboards to track usage patterns. Monitor which queries or features consume the most tokens, then implement optimization strategies like RAG for document-heavy applications, summarization for long conversations, or routing to larger models for complex tasks. Measure actual performance and costs to validate your choices.
AI services typically charge per token consumed. Costs scale linearly with token usage, making token optimization directly impact your expenses. A 20% reduction in token consumption translates to a 20% cost reduction. Understanding token efficiency helps you choose the right optimization strategy for your budget constraints.
Token limits continue to expand as models become more sophisticated. Emerging techniques like sparse attention mechanisms promise to reduce computational costs of processing large contexts. The future focuses on intelligent content selection and retrieval rather than raw processing capacity, making techniques like RAG increasingly important for scalable AI applications.
Understand token efficiency and track how AI models cite your brand with AmICited's comprehensive AI citation monitoring platform.
Learn what tokens are in language models. Tokens are fundamental units of text processing in AI systems, representing words, subwords, or characters as numerica...

Learn how AI models process text through tokenization, embeddings, transformer blocks, and neural networks. Understand the complete pipeline from input to outpu...
Learn essential strategies to optimize your support content for AI systems like ChatGPT, Perplexity, and Google AI Overviews. Discover best practices for clarit...