
Embedding
Learn what embeddings are, how they work, and why they're essential for AI systems. Discover how text transforms into numerical vectors that capture semantic me...
12 min read

Learn how vector embeddings enable AI systems to understand semantic meaning and match content to queries. Explore the technology behind semantic search and AI content matching.

Vector embeddings are the numerical foundation that powers modern artificial intelligence systems, transforming raw data into mathematical representations that machines can understand and process. At their core, embeddings convert text, images, audio, and other content types into arrays of numbers—typically ranging from dozens to thousands of dimensions—that capture the semantic meaning and contextual relationships within that data. This numerical representation is fundamental to how AI systems perform content matching, semantic search, and recommendation tasks, enabling machines to understand not just what words or images are present, but what they actually mean. Without embeddings, AI systems would struggle to grasp the nuanced relationships between concepts, making them essential infrastructure for any modern AI application.
The transformation from raw data to vector embeddings is accomplished through sophisticated neural network models trained on massive datasets to learn meaningful patterns and relationships. When you input text into an embedding model, it passes through multiple layers of neural networks that progressively extract semantic information, ultimately producing a fixed-size vector that represents the essence of that content. Popular embedding models like Word2Vec, GloVE, and BERT each take different approaches—Word2Vec uses shallow neural networks optimized for speed, GloVE combines global matrix factorization with local context windows, while BERT leverages transformer architecture to understand bidirectional context.
| Model | Data Type | Dimensions | Primary Use Case | Key Advantage |
|---|---|---|---|---|
| Word2Vec | Text (words) | 100-300 | Word relationships | Fast, efficient |
| GloVE | Text (words) | 100-300 | Semantic relationships | Combines global and local context |
| BERT | Text (sentences/docs) | 768-1024 | Contextual understanding | Bidirectional context awareness |
| Sentence-BERT | Text (sentences) | 384-768 | Sentence similarity | Optimized for semantic search |
| Universal Sentence Encoder | Text (sentences) | 512 | Cross-lingual tasks | Language-agnostic |
These models produce high-dimensional vectors (often 300 to 1,536 dimensions), where each dimension captures different aspects of meaning, from grammatical properties to conceptual relationships. The beauty of this numerical representation is that it enables mathematical operations—you can add, subtract, and compare vectors to discover relationships that would be invisible in raw text. This mathematical foundation is what makes semantic search and intelligent content matching possible at scale.
The true power of embeddings emerges through semantic similarity, the ability to recognize that different words or phrases can mean essentially the same thing in vector space. When embeddings are created effectively, semantically similar concepts naturally cluster together in the high-dimensional space—“king” and “queen” sit near each other, as do “car” and “vehicle,” even though they’re different words. To measure this similarity, AI systems use distance metrics like cosine similarity (measuring the angle between vectors) or dot product (measuring magnitude and direction), which quantify how close two embeddings are to each other. For example, a query about “automobile transportation” would have high cosine similarity to documents about “car travel,” allowing the system to match content based on meaning rather than exact keyword matching. This semantic understanding is what separates modern AI search from simple keyword matching, enabling systems to understand user intent and deliver genuinely relevant results.
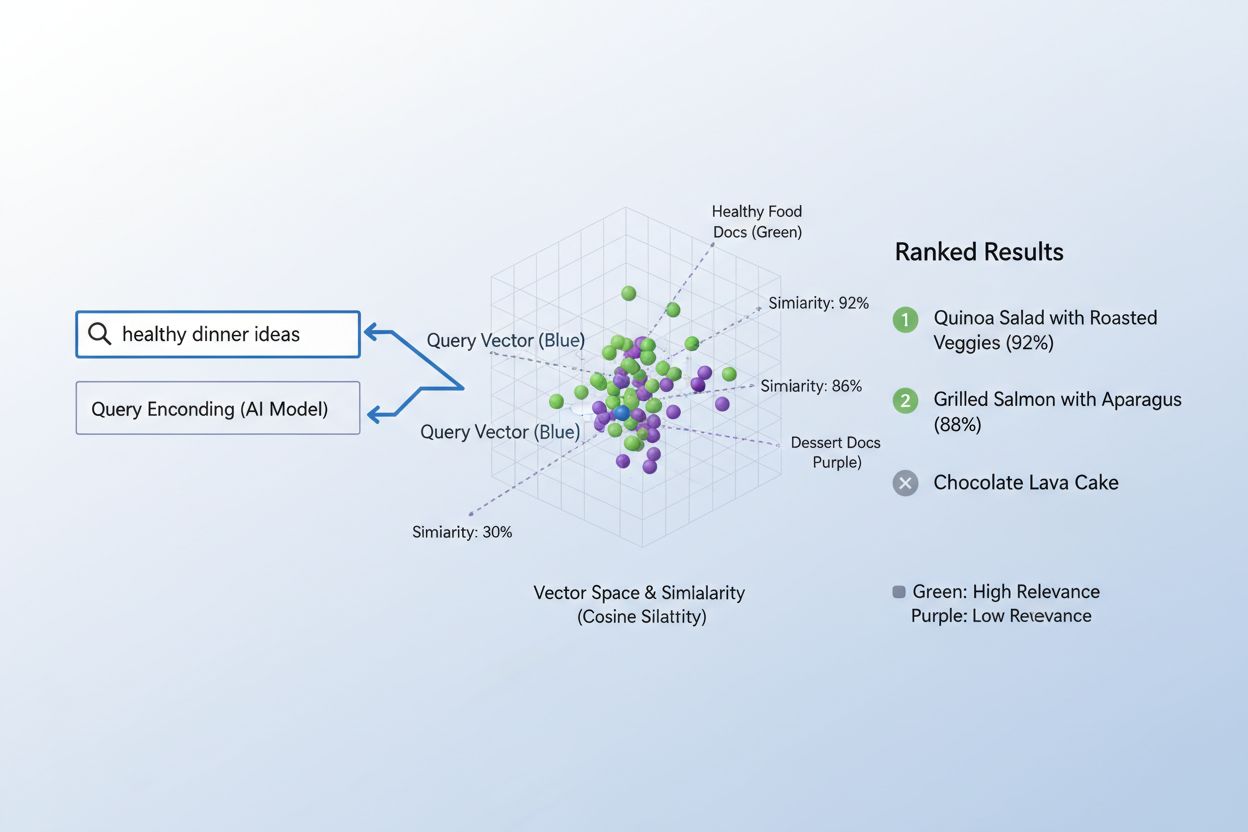
The process of matching content to queries using embeddings follows an elegant two-step workflow that powers everything from search engines to recommendation systems. First, both the user’s query and the available content are independently converted into embeddings using the same model—a query like “best practices for machine learning” becomes a vector, as does each article, document, or product in the system’s database. Next, the system calculates the similarity between the query embedding and every content embedding, typically using cosine similarity, which produces a score indicating how relevant each piece of content is to the query. These similarity scores are then ranked, with the highest-scoring content surfaced to the user as the most relevant results. In a real-world search engine scenario, when you search for “how to train neural networks,” the system encodes your query, compares it against millions of document embeddings, and returns articles about deep learning, model optimization, and training techniques—all without requiring exact keyword matches. This matching process happens in milliseconds, making it practical for real-time applications serving millions of users simultaneously.
Different types of embeddings serve different purposes depending on what you’re trying to match or understand. Word embeddings capture the meaning of individual words and work well for tasks requiring fine-grained semantic understanding, while sentence embeddings and document embeddings aggregate meaning across longer text spans, making them ideal for matching entire queries to full articles or documents. Image embeddings represent visual content numerically, enabling systems to find visually similar images or match images to text descriptions, while user embeddings and product embeddings capture behavioral patterns and characteristics, powering recommendation systems that suggest items based on user preferences. The choice between these embedding types involves trade-offs: word embeddings are computationally efficient but lose context, while document embeddings preserve full meaning but require more processing power. Domain-specific embeddings, fine-tuned on specialized datasets like medical literature or legal documents, often outperform general-purpose models for industry-specific applications, though they require additional training data and computational resources.
In practice, embeddings power some of the most impactful AI applications we use daily, from the search results you see to the products recommended to you online. Semantic search engines use embeddings to understand query intent and surface relevant content regardless of exact keyword matches, while recommendation systems at Netflix, Amazon, and Spotify leverage user and item embeddings to predict what you’ll want to watch, buy, or listen to next. Content moderation systems use embeddings to detect harmful content by comparing user-generated posts against embeddings of known policy violations, while question-answering systems match user questions to relevant knowledge base articles by finding semantically similar content. Personalization engines use embeddings to understand user preferences and tailor experiences, and anomaly detection systems identify unusual patterns by recognizing when new data points fall far from expected embedding clusters. At AmICited, we leverage embeddings to monitor how AI systems are being used across the internet, matching user queries and content to track where AI-generated or AI-assisted content appears, helping brands understand their AI footprint and ensure proper attribution.
Implementing embeddings effectively requires careful attention to several technical considerations that impact both performance and cost. Model selection is critical—you must balance the semantic quality of embeddings against computational requirements, with larger models like BERT producing richer representations but requiring more processing power than lightweight alternatives. Dimensionality presents a key trade-off: higher-dimensional embeddings capture more nuance but consume more memory and slow down similarity calculations, while lower-dimensional embeddings are faster but may lose important semantic information. To handle large-scale matching efficiently, systems use specialized indexing strategies like FAISS (Facebook AI Similarity Search) or Annoy (Approximate Nearest Neighbors Oh Yeah), which enable finding similar embeddings in milliseconds rather than seconds by organizing vectors in tree structures or locality-sensitive hashing schemes. Fine-tuning embedding models on domain-specific data can dramatically improve relevance for specialized applications, though it requires labeled training data and additional computational overhead. Organizations must continuously balance speed versus accuracy, computational cost versus semantic quality, and general-purpose models versus specialized alternatives based on their specific use cases and constraints.
The future of embeddings is moving toward greater sophistication, efficiency, and integration with broader AI systems, promising even more powerful content matching and understanding capabilities. Multimodal embeddings that simultaneously process text, images, and audio are emerging, enabling systems to match across different content types—finding images relevant to text queries or vice versa—opening entirely new possibilities for content discovery and understanding. Researchers are developing increasingly efficient embedding models that deliver comparable semantic quality with far fewer parameters, making advanced AI capabilities accessible to smaller organizations and edge devices. The integration of embeddings with large language models is creating systems that can not only match content semantically but also understand context, nuance, and intent at unprecedented levels. As AI systems become more prevalent across the internet, the ability to track, monitor, and understand how content is being matched and used becomes increasingly important—this is where platforms like AmICited leverage embeddings to help organizations monitor their brand presence, track AI usage patterns, and ensure their content is being properly attributed and used appropriately. The convergence of better embeddings, more efficient models, and sophisticated monitoring tools is creating a future where AI systems are more transparent, accountable, and aligned with human values.
A vector embedding is a numerical representation of data (text, images, audio) in a high-dimensional space that captures semantic meaning and relationships. It converts abstract data into arrays of numbers that machines can process and analyze mathematically.
Embeddings convert abstract data into numbers that machines can process, allowing AI to identify patterns, similarities, and relationships between different pieces of content. This mathematical representation enables AI systems to understand meaning rather than just matching keywords.
Keyword matching looks for exact word matches, while semantic similarity understands meaning. This allows systems to find related content even without identical words—for example, matching 'automobile' with 'car' based on semantic relationship rather than exact text match.
Yes, embeddings can represent text, images, audio, user profiles, products, and more. Different embedding models are optimized for different data types, from Word2Vec for text to CNNs for images to spectrograms for audio.
AmICited uses embeddings to understand how AI systems semantically match and reference your brand across different AI platforms and responses. This helps track your content's presence in AI-generated answers and ensure proper attribution.
Key challenges include choosing the right model, managing computational costs, handling high-dimensional data, fine-tuning for specific domains, and balancing speed versus accuracy in similarity calculations.
Embeddings enable semantic search, which understands user intent and returns relevant results based on meaning rather than just keyword matches. This allows search systems to find content that's conceptually related even if it doesn't contain exact query terms.
Large language models use embeddings internally to understand and generate text. Embeddings are fundamental to how these models process information, match content, and generate contextually appropriate responses.
Vector embeddings power AI systems like ChatGPT, Perplexity, and Google AI Overviews. AmICited tracks how these systems cite and reference your content, helping you understand your brand's presence in AI-generated responses.
Learn what embeddings are, how they work, and why they're essential for AI systems. Discover how text transforms into numerical vectors that capture semantic me...

Learn how embeddings work in AI search engines and language models. Understand vector representations, semantic search, and their role in AI-generated answers.
Learn how vector search uses machine learning embeddings to find similar items based on meaning rather than exact keywords. Understand vector databases, ANN alg...