Pozice citace v odpovědích AI: Jak různé AI platformy uvádějí zdroje
Zjistěte, jak funguje pozice citace v ChatGPT, Perplexity, Google AI Overviews a dalších AI systémech. Pochopte strategie umísťování citací a naučte se, jak opt...
7 min čtení
Zjistěte, jak modely AI generují odpovědi a kam umisťují citace. Objevte, kde se váš obsah objevuje v odpovědích ChatGPT, Perplexity a Google AI a jak optimalizovat svou viditelnost v AI.
Odpovědi generované AI se staly hlavní metodou objevování informací pro miliony uživatelů a zásadně mění tok informací na internetu. Podle nedávného výzkumu vzrostlo využití AI mezi výzkumníky v roce 2025 na 84 %, přičemž 62 % využívá AI nástroje přímo pro výzkum a publikační úkoly – dramatický nárůst oproti 57 % celkového využití AI v roce 2024. Většina tvůrců obsahu si však stále neuvědomuje, že umístění citací v těchto odpovědích není náhodné; řídí se sofistikovanou technickou architekturou, která určuje, které zdroje získají viditelnost a které zůstanou neviditelné. Porozumění tomu, kde a proč se citace objevují, je nyní zásadní pro každého, kdo chce udržet viditelnost v AI-driven prostředí objevování obsahu.
Rozdíl mezi modelově-nativní syntézou a Retrieval-Augmented Generation (RAG) zásadně ovlivňuje, jak se citace v odpovědích AI objevují. Modelově-nativní syntéza spoléhá pouze na znalosti zakódované během tréninku, zatímco RAG dynamicky získává externí zdroje, aby odpovědi podložila aktuálními informacemi. Tento rozdíl má zásadní dopad na umístění citací a viditelnost.
| Charakteristika | Modelově-nativní syntéza | RAG |
|---|---|---|
| Definice | Odpovědi generované pouze z tréninkových dat | Odpovědi založené na aktuálně získaných zdrojích |
| Rychlost | Rychlejší (bez režie na získávání) | Pomalejší (vyžaduje krok získávání) |
| Přesnost | Náchylná k halucinacím a zastaralým informacím | Vyšší přesnost díky aktuálním zdrojům |
| Možnost citací | Omezené nebo žádné citace | Bohaté, dohledatelné citace |
| Využití | Obecné znalosti, kreativní úkoly | Zprávy, výzkum, ověřování faktů, proprietární data |
Systémy založené na RAG jako Perplexity a Google AI Overviews přirozeně generují více citací, protože musí odkazovat na získané zdroje, zatímco modelově-nativní přístupy jako tradiční odpovědi ChatGPT citují méně často. Porozumění tomu, který přístup platforma používá, pomáhá tvůrcům obsahu předvídat pravděpodobnost citace a podle toho optimalizovat.
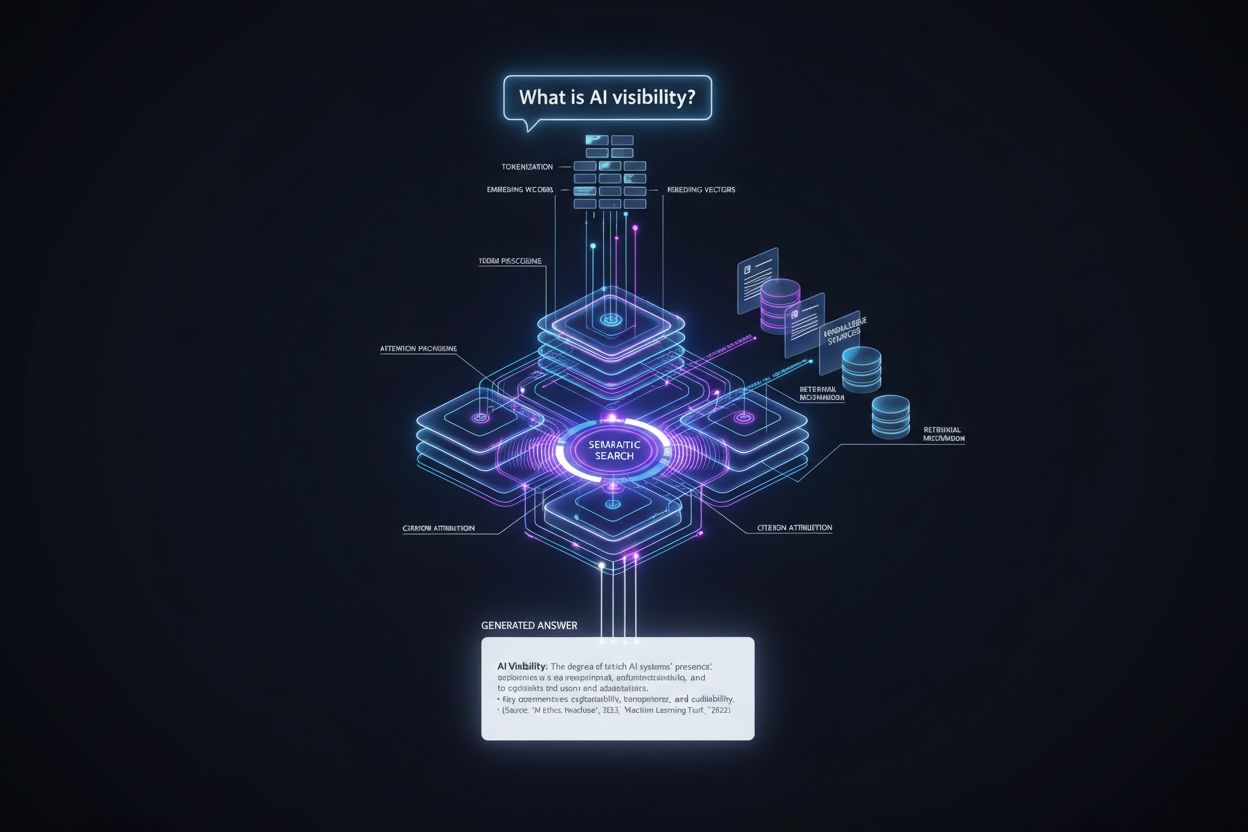
Cesta od uživatelského dotazu k citované odpovědi sleduje přesně daný technický postup, který rozhoduje o umístění citace v několika fázích. Jak tento proces probíhá:
Zpracování dotazu: Uživatelská otázka je tokenizována – rozložena na jednotky, kterým model rozumí – a analyzována na záměr, entity a sémantický význam pomocí vektorů embeddingu.
Získávání informací: Systém prohledává svou znalostní bázi (tréninková data, indexované dokumenty nebo aktuální zdroje) pomocí sémantického vyhledávání, kdy hledá význam dotazu místo přesných klíčových slov, a vrací kandidátní zdroje seřazené podle relevance.
Sestavení kontextu: Získané informace jsou uspořádány do kontextového okna – množství textu, které model dokáže zpracovat najednou – přičemž nejrelevantnější zdroje jsou na předních pozicích, aby ovlivnily mechanismy pozornosti.
Generování tokenů: Model generuje odpověď po jednom tokenu a pomocí mechanismu self-attention určuje, které dříve vygenerované tokeny a zdrojové informace mají ovlivnit každý nový token, aby vznikla srozumitelná, kontextově ukotvená odpověď.
Přiřazení citací: Jak jsou generovány tokeny, model sleduje, které zdrojové dokumenty ovlivnily konkrétní tvrzení, přiřazuje skóre důvěryhodnosti a rozhoduje, zda zahrnout explicitní citaci na základě úrovně jistoty a požadavků platformy.
Výstup: Finální odpověď je naformátována podle specifikací platformy – inline citace, poznámky pod čarou, panel zdrojů nebo odkazy najetím – a předána uživateli s metadaty o autoritě a relevanci zdroje.
Umístění citací se mezi AI platformami dramaticky liší a vytváří různé příležitosti pro viditelnost obsahu. Jak hlavní platformy nakládají s citacemi:
ChatGPT: Citace se zobrazují v samostatném panelu „Zdroje“ pod odpovědí, uživatel je musí rozkliknout. Zdroje jsou obvykle omezeny na 3–5 odkazů, upřednostněny jsou autoritativní domény.
Perplexity: Citace jsou vloženy přímo v textu odpovědi jako horní indexy a na konci je kompletní seznam zdrojů. Každé tvrzení je dohledatelné, což z této platformy činí nejtransparentnější variantu.
Google Gemini: Citace se objevují jako inline odkazy v odpovědi a v sekci „Zdroje“, kde jsou všechny použité materiály. Výběr zdrojů ovlivňuje integrace s Google knowledge graph.
Claude: Citace mají podobu poznámek pod čarou v hranatých závorkách, takže uživatelé vidí zdroje bez nutnosti opustit odpověď. Claude klade důraz na rozmanitost a důvěryhodnost zdrojů.
DeepSeek: Citace jsou jako inline hypertextové odkazy s minimálním vizuálním rozlišením, což odráží více integrovaný přístup, kdy jsou zdroje plynule zapracovány do textu.
Tyto rozdíly znamenají, že zdroj citovaný Perplexity může získat přímou návštěvnost, zatímco tentýž zdroj citovaný ChatGPT zůstane neviditelný, pokud uživatel panel se zdroji neotevře. Vzory citování na jednotlivých platformách mají zásadní dopad na návštěvnost i viditelnost.

O umístění citací se rozhoduje už v retrieval systému, dávno před samotným generováním odpovědi. Sémantické vyhledávání převádí jak uživatelský dotaz, tak indexované dokumenty do vektorových embeddingů – číselných reprezentací zachycujících význam místo klíčových slov. Systém pak spočítá skóre podobnosti mezi embeddingem dotazu a embeddingy dokumentů a identifikuje, které zdroje jsou sémanticky nejblíže záměru uživatele.
Řadící algoritmy pak tyto kandidáty přeuspořádají podle více signálů: skóre relevance, autorita domény, aktuálnost obsahu, metriky zapojení uživatelů a kvalita strukturovaných dat. Zdroje, které se v této fázi umístí nejvýše, mají větší šanci být zahrnuty do kontextového okna pro generování odpovědi, a tedy i být citovány. Proto je dobře optimalizovaný, sémanticky jasný článek z autoritativní domény získáván a citován mnohem častěji než špatně strukturovaný článek z nové domény, i když oba obsahují přesné informace. Retrieval fáze tedy v podstatě předurčuje „bazén“ citací ještě před samotným generováním.
Struktura obsahu není jen otázkou UX – přímo ovlivňuje, zda AI systémy dokážou váš obsah extrahovat, porozumět mu a citovat ho. Modely AI spoléhají na formátovací vodítka pro identifikaci hranic informací a vztahů. Zde jsou strukturální prvky maximalizující pravděpodobnost citace:
Struktura odpověď-první: Začněte přímou odpovědí na častou otázku, aby AI rychle identifikovala a extrahovala klíčové informace bez nutnosti procházet úvod.
Jasné nadpisy: Používejte popisné H2 a H3 nadpisy, které jednoznačně určují téma sekce. AI tak lépe pochopí organizaci obsahu a vybere příslušné části pro konkrétní dotazy.
Optimální délka odstavců: Udržujte odstavce na 3–5 vět, což AI usnadní identifikaci jednotlivých tvrzení a jejich jasné přiřazení konkrétnímu zdroji.
Seznamy a tabulky: Strukturovaná data v bodech a tabulkách se citují snáz než souvislý text, protože AI dokáže jasně určit jednotlivá tvrzení a jejich hranice.
Jasnost entit: Výslovně jmenujte osoby, organizace, produkty a pojmy místo používání zájmen, aby AI přesně věděla, čeho se tvrzení týká, a mohla jej správně citovat.
Schéma: Implementujte strukturovaná data (Schema.org) pro explicitní metadata o typu obsahu, autorovi, datu publikace a tvrzeních, což AI poskytuje další signály pro hodnocení a citaci.
Obsah, který tyto principy splňuje, je citován 2–3x častěji než špatně strukturovaný obsah bez ohledu na kvalitu, protože je pro AI systémy jednoduše snáze extrahovatelný a přiřaditelný.
Jakmile jsou zdroje získány a sestaveny do kontextového okna, model každý zdroj hodnotí podle několika kritérií důvěryhodnosti před rozhodnutím o citaci. Hodnocení důvěryhodnosti zdroje zahrnuje autoritu domény (měřenou například zpětnými odkazy, stářím domény a značkou), odbornost autora (zjišťovanou podle bylinek, bio autora a signálů odbornosti) a tematickou relevanci (zda hlavní zaměření zdroje odpovídá dotazu).
Hodnocení relevance posuzuje, jak přesně zdroj odpovídá na konkrétní dotaz – přesné odpovědi mají vyšší skóre než okrajové informace. Aktuálnost ovlivňuje, zda jsou upřednostňovány novější zdroje – klíčové pro zprávy, výzkum a rychle se vyvíjející témata. Signály autority zahrnují citace z jiných autoritativních zdrojů, zmínky v akademických databázích a přítomnost v knowledge graph. Vliv metadat mají title tagy, meta popisky a strukturovaná data, která explicitně komunikují účel a důvěryhodnost obsahu. Nakonec strukturovaná data (Schema.org markup) poskytují explicitní signály důvěryhodnosti, které model přímo zpracuje, včetně odbornosti autora, data vydání, hodnocení recenze a statusu fact-check. Zdroje s kompletním schématem jsou citovány spolehlivěji, protože model má strojově čitelné potvrzení jejich tvrzení.
AI platformy používají různé styly citací, které ovlivňují viditelnost vašich citací pro uživatele. Nejčastější vzory jsou:
Inline citace (styl Perplexity):
„Podle nedávného výzkumu vzrostlo využití AI mezi výzkumníky v roce 2025 na 84%[1], přičemž 62% využívá AI nástroje pro výzkumné úkoly[2].“
Citace na konci odstavce (styl Claude):
„Využití AI mezi výzkumníky vzrostlo v roce 2025 na 84 %, přičemž 62 % využívá AI nástroje pro výzkumné úkoly. [Zdroj: Wiley Research Report, 2025]“
Poznámky pod čarou (akademický přístup):
„Využití AI mezi výzkumníky vzrostlo v roce 2025 na 84 %¹, přičemž 62 % využívá AI nástroje pro výzkumné úkoly².“
Seznam zdrojů (styl ChatGPT):
Text odpovědi bez inline citací, následovaný samostatnou sekcí „Zdroje“ s 3–5 odkazy.
Citace najetím (emergentní vzor):
Podtržený text, který při najetí myší ukáže informace o zdroji, čímž minimalizuje vizuální rušení a zachovává dohledatelnost.
Každý styl vede k jinému chování uživatelů: inline citace podporují okamžité kliknutí, seznam zdrojů vyžaduje aktivní akci uživatele a citace najetím balancují mezi viditelností a estetikou. Pravděpodobnost citace vašeho obsahu se liší podle platformy, proto je nezbytné sledovat citace napříč více platformami.
Porozumění mechanikám umístění citací přímo ovlivňuje měřitelné obchodní výsledky. Dopad na návštěvnost je okamžitý: zdroje citované inline v Perplexity získávají 3–5x více referral návštěvnosti než zdroje, které jsou pouze v panelu „Zdroje“ ChatGPT, protože uživatelé klikají spíše na citace přímo v textu. Vztah mezi viditelností a proklikem není lineární – být citován má hodnotu jen tehdy, když uživatel na citaci skutečně klikne, což závisí na umístění, platformě a kontextu.
Autorita značky se kumuluje v čase: zdroje pravidelně citované na více AI platformách získávají silnější signály autority, což zlepšuje jejich pozice v tradičním vyhledávání a zvyšuje šanci na budoucí citace. Vzniká tak pozitivní spirála, kdy citovaný obsah získává větší autoritu a přitahuje další citace. Konkurenční výhoda vzniká pro značky, které optimalizují pro AI citace dříve než konkurence – průkopníci ve schématech a optimalizaci struktury obsahu aktuálně získávají nepoměrně větší podíl citací. SEO dopad přesahuje AI: obsah optimalizovaný pro AI citace obvykle lépe funguje i v tradičním vyhledávání, protože stejné strukturální a autoritativní signály prospívají oběma systémům. Hodnota AmICited je jasná: v AI-driven prostředí objevování je nevědět, zda jste citováni, stejné jako nevědět, jaké máte pozice ve vyhledávání – je to zásadní slabina vaší strategie viditelnosti.
Optimalizace pro AI citace vyžaduje konkrétní, akční změny ve vytváření a struktuře obsahu. Nejefektivnější taktiky:
Struktura pro extrahovatelnost: Používejte jasné nadpisy, krátké odstavce a seznamy, aby byl obsah pro AI snadno zpracovatelný a bylo možné jednoznačně extrahovat tvrzení.
Používejte jasná, citovatelná fakta: Začínejte konkrétními statistikami, daty a pojmenovanými entitami místo vágních obecných tvrzení. AI raději cituje konkrétní tvrzení než abstraktní prohlášení.
Implementujte schéma: Přidejte Schema.org markup pro typy Article, NewsArticle nebo ScholarlyArticle, včetně autora, data publikace a metadat ke konkrétním tvrzením, která AI přímo zpracuje.
Konzistence entit: Používejte stejná jména osob, organizací a pojmů napříč celým obsahem a vyhýbejte se zájmenům a zkratkám, které vnášejí do AI zmatek.
Cituje své zdroje: Když ve vlastním obsahu citujete jiné zdroje, dáváte AI signál, že váš obsah je dobře podložený a důvěryhodný, což zvyšuje šanci na vaši vlastní citaci.
Testujte v AI nástrojích: Pravidelně zadávejte svá témata do ChatGPT, Perplexity, Gemini a Claude a sledujte, zda a jak je váš obsah citován.
Sledujte výkon: Sledujte, které části vašeho obsahu jsou citovány, na jakých platformách a v jakém kontextu, a podle těchto dat upravujte svou optimalizační strategii.
Tvůrci obsahu, kteří tyto taktiky zavedou, zaznamenají nárůst citací o 40–60 % během 3–6 měsíců, což se projeví i na vyšší referral návštěvnosti a autoritě značky.
Sledování citací už není volitelné – je to základní infrastruktura pro pochopení vaší viditelnosti v AI-driven prostředí objevování obsahu. Proč na sledování záleží je jasné: nemůžete optimalizovat to, co neměříte, a vzory citací se mění s vývojem AI a příchodem nových platforem. Jaké metriky sledovat zahrnuje frekvenci citací (jak často jste citováni), umístění citací (inline vs. seznam zdrojů), rozložení platforem (kde jste nejčastěji citováni), kontext dotazu (jaká témata vaše citace spouštějí) a atribuci návštěvnosti (kolik referral návštěvnosti pochází z AI citací).
Identifikace příležitostí vyžaduje analýzu mezer v citacích: témata, kde jsou citováni konkurenti, ale vy ne, platformy, kde jste málo zastoupeni, a typy obsahu, které podávají slabé výkony. Tato analýza odhalí konkrétní cíle pro optimalizaci – třeba vaše návody nejsou citovány kvůli absenci schématu, nebo váš výzkumný obsah není v Perplexity, protože není strukturován pro inline extrakci.
AmICited řeší výzvu sledování tím, že v reálném čase monitoruje vaše citace v ChatGPT, Perplexity, Gemini, Claude a na dalších hlavních AI platformách. Místo opakovaného ručního zadávání dotazů AmICited automaticky sleduje vzory citací, upozorní vás na nové citace a poskytuje benchmarking s konkurencí, abyste viděli, jak si vedete. Pro tvůrce obsahu, marketéry a SEO profesionály proměňuje AmICited sledování citací z manuálního, časově náročného procesu v automatizovaný systém generující akční insighty. V AI-driven prostředí objevování obsahu je mít přehled o tom, kde jste citováni, stejně důležité jako znát své pozice ve vyhledávání – a AmICited tuto viditelnost umožňuje ve velkém měřítku.
Modelově-nativní odpovědi pocházejí ze vzorců naučených během tréninku, zatímco RAG před generováním odpovědí získává aktuální data. RAG obvykle poskytuje lepší citace, protože odpovědi zakládá na konkrétních zdrojích, což je pro uživatele i autory obsahu transparentnější a lépe dohledatelné.
Různé platformy používají různé architektury. Perplexity a Gemini upřednostňují RAG s citacemi, zatímco ChatGPT standardně generuje odpovědi pouze na základě modelu, pokud není povoleno procházení. Volba odráží filozofii návrhu a přístup každé platformy k transparentnosti.
Jasný, dobře strukturovaný obsah s přímými odpověďmi, správnými nadpisy a schématem je pro AI systémy snadněji extrahovatelný. Obsah, který začíná odpověďmi a používá seznamy a tabulky, je pravděpodobněji citován, protože je pro AI jednodušší ho zpracovat a přiřadit zdroj.
Schéma pomáhá AI systémům pochopit strukturu obsahu a vztahy mezi entitami, což usnadňuje správné přiřazení a citování vašeho obsahu. Správná implementace schématu zvyšuje pravděpodobnost citace a pomáhá AI ověřit důvěryhodnost vašeho obsahu.
Ano. Zaměřte se na strukturu orientovanou na odpovědi, jasné formátování, faktickou přesnost, důvěryhodné zdroje a správné schéma. Sledujte své citace a vylepšujte obsah na základě výkonu pro kontinuální zvyšování viditelnosti v AI.
Nástroje jako AmICited sledují zmínky o vaší značce v ChatGPT, Perplexity, Google AI Overviews a na dalších platformách a ukazují přesně, kde a jak jste v AI odpovědích citováni. To poskytuje užitečné informace pro optimalizaci.
Citace AI přímo neovlivňují pozice v Google, ale zvyšují viditelnost značky a signály autority. Citace od AI mohou přinést návštěvnost a posílit vaši online přítomnost, čímž vznikají nepřímé SEO přínosy.
Jsou komplementární. Tradiční SEO se zaměřuje na umístění ve výsledcích vyhledávání, zatímco optimalizace pro citace AI na objevení v odpovědích generovaných AI. Oba přístupy jsou důležité pro komplexní viditelnost v moderním prostředí objevování obsahu.
Získejte přesný přehled o tom, kde se vaše značka objevuje v odpovědích generovaných AI. Sledujte citace v ChatGPT, Perplexity, Google AI Overviews a dalších s AmICited.
Zjistěte, jak funguje pozice citace v ChatGPT, Perplexity, Google AI Overviews a dalších AI systémech. Pochopte strategie umísťování citací a naučte se, jak opt...
Zjistěte, které publikace citují AI enginy jako ChatGPT, Perplexity a Google AI nejčastěji. Poznejte vzorce citací, preference zdrojů a jak optimalizovat vidite...
Zjistěte, jak AI modely jako ChatGPT, Perplexity a Gemini vybírají zdroje k citování. Pochopte mechanismy citací, hodnotící faktory i optimalizační strategie pr...