
Rozpoznávání entit
Rozpoznávání entit je schopnost AI NLP identifikující a kategorizující pojmenované entity v textu. Zjistěte, jak funguje, jeho využití v AI monitoringu a jeho r...
10 min čtení

Prozkoumejte, jak AI systémy rozpoznávají a zpracovávají entity v textu. Seznamte se s NER modely, architekturami transformerů a reálnými aplikacemi porozumění entitám.
Porozumění entitám se stalo klíčovou schopností moderních systémů umělé inteligence, která umožňuje strojům identifikovat a chápat hlavní aktéry, místa a pojmy v nestrukturovaném textu. Od pohánění vyhledávačů, které rozumí záměru uživatele, až po chatboty schopné odpovídat na složité dotazy týkající se konkrétních osob a organizací—rozpoznávání entit tvoří základ smysluplné interakce člověka s počítačem. Tato technická schopnost je zásadní napříč odvětvími—finanční instituce ji využívají pro monitorování souladu s předpisy, zdravotnictví pro správu pacientských záznamů a e-commerce platformy pro pochopení zmínek o produktech a zpětné vazbě zákazníků. Pochopení, jak AI systémy extrahují a interpretují entity, je klíčové pro každého, kdo staví nebo nasazuje NLP aplikace v produkčním prostředí.
Rozpoznávání pojmenovaných entit (NER) je úloha v NLP, jejímž cílem je identifikovat a klasifikovat pojmenované entity—konkrétní, významové jednotky informací—v textu do předdefinovaných kategorií. Tyto entity představují konkrétní subjekty, které nesou sémantický význam v jazyce: osoby vykonávající akce, organizace přijímající rozhodnutí, místa, kde se události odehrávají, časové výrazy ukotvující události v čase, peněžní hodnoty kvantifikující transakce a produkty, které se kupují a prodávají. Klasifikace entit je důležitá, protože převádí surový text na strukturované znalosti, se kterými mohou stroje pracovat; bez ní systém nerozliší „Apple jako společnost“ od „apple jako ovoce“ ani nepochopí, že „John Smith“ a „J. Smith“ označují stejnou osobu. Schopnost přesně klasifikovat entity umožňuje další aplikace jako stavbu znalostních grafů, extrakci informací, odpovídání na dotazy a detekci vztahů.
| Typ entity | Definice | Příklad |
|---|---|---|
| PERSON | Jednotliví lidé | “Steve Jobs”, “Marie Curie” |
| ORGANIZATION | Společnosti, instituce, skupiny | “Microsoft”, “Organizace spojených národů”, “Harvardská univerzita” |
| LOCATION | Geografická místa a regiony | “New York”, “Amazonka”, “Silicon Valley” |
| DATE | Časové výrazy a období | “15. ledna 2024”, “příští úterý”, “3. čtvrtletí 2023” |
| MONEY | Peněžní hodnoty a měny | “$50 milionů”, “€100”, “5000 jenů” |
| PRODUCT | Zboží, služby a výtvory | “iPhone 15”, “Windows 11”, “ChatGPT” |
Moderní AI systémy zpracovávají entity prostřednictvím sofistikovaného vícestupňového procesu, který začíná tokenizací, tedy rozdělením surového textu na jednotlivé tokeny, které slouží jako základní jednotky pro další zpracování. Každý token je pak převeden na číselnou reprezentaci pomocí word embeddings—hustých vektorů zachycujících sémantický význam—které jsou předávány neuronovým sítím navrženým pro pochopení kontextu a vztahů. Modely založené na transformerech, které jsou dnes dominantní architekturou v NLP, zpracovávají celé sekvence paralelně namísto sekvenčně, což jim umožňuje zachytit dlouhodobé závislosti a složité kontextové vztahy důležité pro přesné porozumění entitám. Mechanismus self-attention v transformerech umožňuje každému tokenu dynamicky vážit důležitost ostatních tokenů v sekvenci, čímž vznikají bohaté kontextové reprezentace—význam slova je určován jeho okolím; proto je „banka“ chápána jinak v „říční břeh“ než ve „spořitelní bance“. Předtrénované jazykové modely jako BERT a GPT se nejprve učí obecné jazykové vzory na obrovských textových korpusech a teprve poté jsou doladěny pro úlohy rozpoznávání entit, což jim umožňuje využít naučené reprezentace syntaxe, sémantiky a znalostí světa. Finální vrstva systémů pro rozpoznávání entit obvykle využívá sekvenční označování—často implementované jako Conditional Random Field (CRF) nebo jednoduchá klasifikační hlava—která přiřazuje entity jednotlivým tokenům na základě kontextových reprezentací naučených neuronovou sítí. Tato architektura umožňuje AI nejen rozpoznat, jaké entity se v textu vyskytují, ale i jak spolu souvisejí a jaké role v širším kontextu textu hrají.
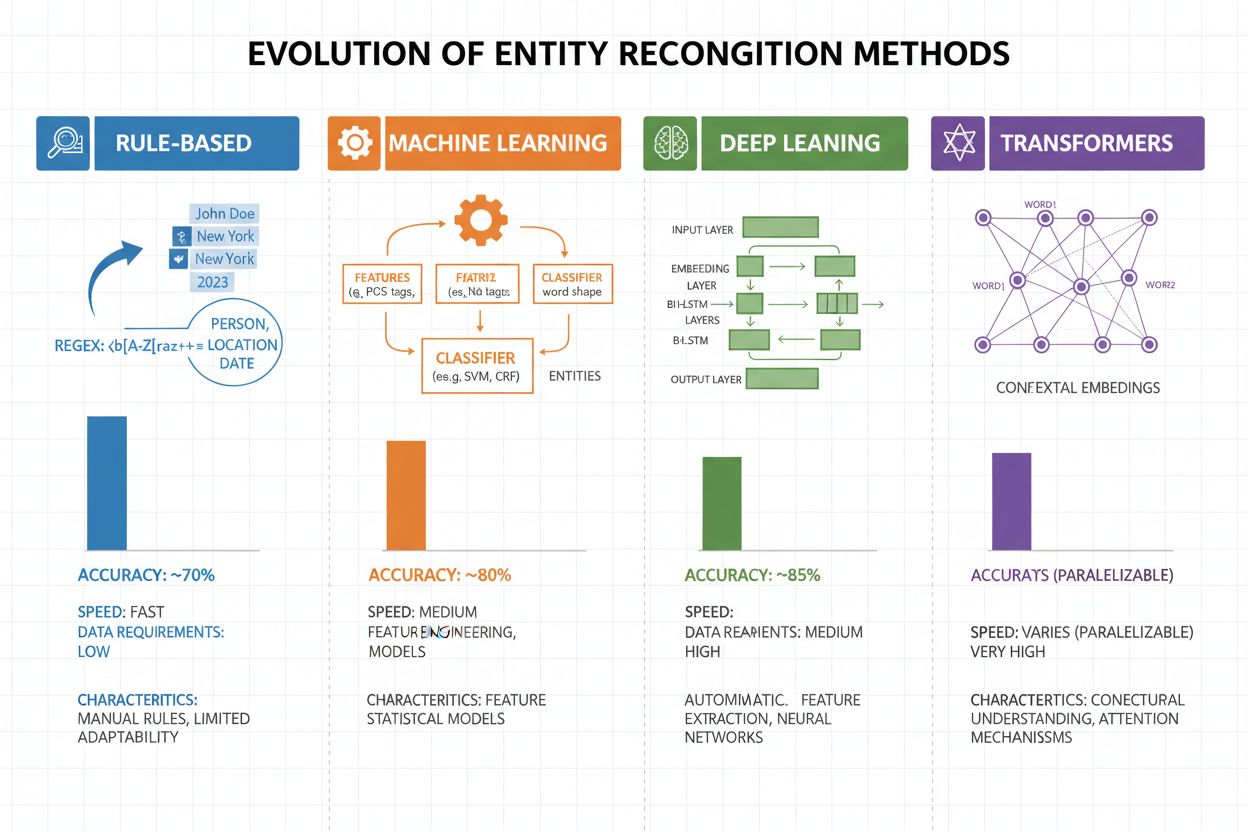
Rozpoznávání entit prošlo za posledních 20 let dramatickým vývojem, od jednoduchých pravidlových přístupů až po sofistikované neuronové architektury. První systémy spoléhali na ručně vytvořená pravidla a slovníky, používaly regulární výrazy a vzorové shody k identifikaci entit—tyto metody byly srozumitelné a vyžadovaly minimum trénovacích dat, ale špatně se zobecňovaly a byly náročné na údržbu. S příchodem machine learningu přišly supervizované přístupy jako Support Vector Machines (SVM) a Conditional Random Fields (CRF), které se učily ze značených dat pomocí návrhu příznaků, což výrazně zlepšilo přesnost, ale stále vyžadovalo odborníky na návrh těchto příznaků. Metody hlubokého učení, zejména LSTM a BiLSTM, automatizovaly extrakci příznaků učením reprezentací přímo ze surového textu, dosahovaly vyšší přesnosti bez ručního návrhu příznaků, ale vyžadovaly větší množství označených dat. Modely založené na transformerech jako BERT a RoBERTa způsobily revoluci v oboru díky využití self-attention k zachycení dlouhodobých závislostí a kontextových nuancí, dosáhly špičkových výsledků (BERT dosáhl 90,9% F1 na CoNLL-2003) a umožnily transfer learning z masivních předtrénovaných modelů. Rovnováha mezi složitostí a přesností se dramaticky posunula: zatímco pravidlové systémy mají stále svoji hodnotu v prostředích s omezenými zdroji a vysoce specializovaných doménách, modely transformerů dominují tam, kde jsou k dispozici dostatečné výpočetní zdroje a značená data, a lehčí alternativy jako DistilBERT představují kompromis pro produkční systémy s požadavky na nízkou latenci.
Modely založené na transformerech zásadně změnily rozpoznávání entit tím, že nahradily sekvenční zpracování paralelními self-attention mechanismy, které současně zvažují všechny tokeny ve větě a umožňují bohatší kontextové porozumění než předchozí architektury. BERT a jeho varianty (RoBERTa, DistilBERT, ALBERT) využívají obousměrné předtrénování na obrovských neoznačených korpusech, učí se univerzální jazykové reprezentace zachycující jak syntaktické, tak sémantické informace, a poté jsou doladěny na úlohy NER s relativně malým množstvím značených dat. Paradigma předtrénování a doladění je pro rozpoznávání entit mimořádně efektivní: modely předtrénované na miliardách tokenů vyvinou robustní reprezentace jazykové struktury a vzorů entit, které lze pak přizpůsobit specifickým doménám jen s tisíci příklady, což dramaticky snižuje potřebu dat oproti učení od nuly. Transformery vynikají v porozumění entitám díky svému multi-head attention mechanismu, který dovoluje různým hlavám specializovat se na různé typy vztahů mezi entitami—některé zaměřené na syntaktické hranice, jiné na sémantické vazby mezi entitami a jejich kontextem. Vícejazyčné rozpoznávání entit prošlo revolucí díky modelům jako mBERT a XLM-RoBERTa, které jsou předtrénované na více než 100 jazycích současně a umožňují zero-shot i few-shot přenos do jazyků s málo daty a křížové propojení entit napříč jazyky. Nové modely jako GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) posouvají hranice dále díky rozpoznávání entit na základě instrukcí, kde modely dokáží identifikovat libovolné typy entit zadané v přirozeném jazyce bez specifického doladění, což představuje posun k flexibilnějším a univerzálnějším systémům porozumění entitám.
Přes pozoruhodný pokrok čelí systémy pro rozpoznávání entit trvalým výzvám, které omezují jejich praktické nasazení, přičemž největšími jsou nejednoznačnost a citlivost na kontext—slovo „Apple“ vyžaduje pochopení, zda jde o ovoce nebo technologickou společnost na základě okolního textu, a i nejmodernější modely mají v šumu či nejednoznačných textech s tímto problém. Neznámé entity (OOV) představují další zásadní výzvu: modely trénované na standardních datových sadách se nemusí nikdy setkat se vzácnými entitami, novými vlastními jmény nebo překlepy, což vede k chybnému zařazení nebo úplnému nerozpoznání těchto entit. Adaptace na doménu zůstává problematická, protože modely trénované na zpravodajských korpusech (jako CoNLL-2003) často selhávají na biomedicínských, právních či sociálních textech, kde se rozložení entit i jazykové vzory zásadně liší, a je nutné nákladné nové anotování a doladění pro každou doménu. Chyby v určení hranic entit—kdy systém sice správně rozpozná existenci entity, ale špatně určí její začátek nebo konec—jsou obzvlášť časté u víceslovných entit a vnořených struktur, například při rozlišení „New York City“ a „New York“ nebo u entit jako „výkonný ředitel společnosti Apple Inc.“. Vícejazyčné složitosti tyto výzvy umocňují, protože různé jazyky mají různá pravidla pro psaní velkých písmen, morfologii i pojmenovávání entit, a modely trénované na angličtině často selhávají v jazycích s odlišnými vlastnostmi. Nedostatek dat pro specializované domény jako názvy vzácných nemocí, nové technologie či proprietární firemní terminologie je úzkým místem, kdy je ruční anotace velmi drahá a je nutné volit mezi nižší přesností a investicí do doménově specifického sběru dat.
Porozumění entitám se stalo nepostradatelným napříč obory a mění způsob, jakým organizace získávají hodnotu z nestrukturovaného textu. V extrakci informací a stavbě znalostních grafů rozpoznávání entit umožňuje automaticky naplňovat strukturované databáze z dokumentů, což pohání vyhledávače a doporučovací systémy, které chápou vztahy mezi lidmi, místy a pojmy. Zdravotnické organizace využívají porozumění entitám k identifikaci názvů léčiv, dávek, symptomů i demografie pacientů z klinických záznamů, čímž zlepšují podporu klinických rozhodnutí a umožňují farmakovigilančním systémům detekovat nežádoucí účinky léčiv ve velkém měřítku. Finanční instituce používají rozpoznávání entit k extrakci burzovních symbolů, peněžních hodnot a událostí z novinek a výsledků hospodaření, což umožňuje algoritmickým obchodním systémům i platformám pro řízení rizik reagovat na tržní informace v reálném čase. Právní technologie aplikují porozumění entitám k automatické identifikaci stran, dat, povinností a ustanovení o odpovědnosti ve smlouvách, čímž zkracují čas právníků na revizi dokumentů z týdnů na hodiny. Zákaznický servis a chatboty využívají rozpoznávání entit k extrakci záměrů uživatelů a relevantního kontextu—jako čísla objednávek, názvy produktů či typy problémů—což umožňuje přesnější směrování a rychlejší řešení požadavků. E-commerce platformy používají porozumění entitám k identifikaci názvů produktů, značek, vlastností a specifikací ze zákaznických recenzí a dotazů, čímž zlepšují objevování produktů a personalizaci. Doporučovací systémy využívají rozpoznávání entit k pochopení, s jakými entitami uživatelé interagují, což umožňuje sofistikovanější kolaborativní filtrování i doporučení na základě obsahu, která zvyšují zapojení i tržby.
Implementace produkčního systému pro porozumění entitám vyžaduje pečlivou přípravu dat, výběr modelu i vyhodnocení. Začněte s kvalitně anotovanými daty: stanovte jasné definice typů entit, použijte míry shody mezi anotátory k zajištění konzistence a snažte se pro každý typ entity získat alespoň 500–1000 označených příkladů, i když doménově specifické aplikace mohou vyžadovat více. Výběr modelu závisí na vašich omezeních: pravidlové systémy nabízí srozumitelnost a nízkou latenci pro dobře definované domény, tradiční ML modely (CRF, SVM) poskytují dobrý výkon při středním množství dat, zatímco modely transformerů (BERT, RoBERTa) dosahují špičkové přesnosti, ale vyžadují více výpočetních zdrojů i dat. Trénovací a doladovací strategie by měly zahrnovat augmentaci dat pro zvládnutí nevyváženosti tříd, křížovou validaci pro prevenci přeučení a pečlivé ladění hyperparametrů jako learning rate a batch size. Vyhodnocujte systém přesností (správně rozpoznané entity), recall (nalezené entity z celkového počtu skutečných) a F1 skóre (harmonický průměr obou), a to odděleně pro každý typ entity pro odhalení slabých míst. Nasazení zvažte s ohledem na latenci (dávkové vs. real-time zpracování), škálovatelnost a integraci do existujících datových toků, přičemž monitoring po nasazení by měl sledovat drift výkonu, míru falešných pozitiv i zpětnou vazbu uživatelů pro zahájení nových trénovacích cyklů.
Ekosystém nástrojů pro porozumění entitám nabízí řešení pro každou škálu i použití. Open-source knihovny jako spaCy poskytují produkčně připravené NER pipeline s působivým výkonem (89,22% F1 na standardních benchmarcích) a skvělou dokumentací, což je ideální pro týmy s ML zkušenostmi; NLTK má vzdělávací hodnotu a základní schopnosti NER; Hugging Face Transformers nabízí přístup ke špičkovým předtrénovaným modelům, které lze s minimem kódu doladit pro konkrétní domény. Cloudové služby odstraňují starosti s infrastrukturou: Google Cloud Natural Language API, AWS Comprehend a IBM Watson NLP nabízejí předtrénované rozpoznávání entit s podporou více jazyků a typů entit, automaticky škálují a snadno se integrují do cloudových datových toků. Specializované frameworky jako Flair (postavený na PyTorch s výbornou podporou sekvenčního označování) a DeepPavlov (nabízí předtrénované modely pro více jazyků a domén) jsou určeny pro výzkumníky a týmy požadující větší přizpůsobení než běžné knihovny. Rozhodnutí mezi vývojem vlastních řešení a využitím hotových nástrojů závisí na citlivosti dat (on-premise vs. cloud), požadované úrovni přesnosti, doménové specifičnosti a zkušenostech týmu: používejte spravované API pro obecné aplikace se standardními typy entit, open-source knihovny pro vlastní úpravy s interními daty a stavte vlastní modely jen tehdy, když existující řešení nesplní požadavky na přesnost nebo latenci.
Budoucnost porozumění entitám utvářejí velké jazykové modely, které přinášejí bezprecedentní flexibilitu a výkon. Modely jako GPT-4 a Claude vykazují pozoruhodné schopnosti few-shot i zero-shot rozpoznávání entit, což umožňuje organizacím identifikovat vlastní typy entit s několika málo příklady nebo dokonce jen na základě slovního popisu, výrazně snižují náklady na anotaci a urychlují nasazení. Multimodální porozumění entitám je na vzestupu, kombinuje text, obrázky a strukturovaná data pro rozpoznávání entit v dokumentech, fakturách či webových stránkách s bohatším kontextem a umožňuje aplikace jako automatizované zpracování dokumentů a vizuální vyhledávání. Zlepšení zpracování v reálném čase díky distilaci modelů a nasazení na edge zařízení dělají pokročilé rozpoznávání entit dostupné na mobilech a IoT systémech, což otevírá nové možnosti v rozšířené realitě, překladech i autonomních systémech. Pokroky v doménovém doladění vedou ke specializovaným modelům pro biomedicínu, právo či finance, které překonávají obecné modely o řády, přičemž techniky jako doménově adaptované předtrénování a transfer learning to dělají stále dostupnější. Jak tyto technologie dospívají, porozumění entitám se stane neviditelnou základní vrstvou AI systémů, která umožní strojům chápat svět s lidsky podobným sémantickým porozuměním a otevře možnosti, o kterých si dnes jen začínáme dělat představu.
S tím, jak se AI systémy jako ChatGPT, Perplexity a Google AI Overviews stále více integrují do způsobu, jakým lidé získávají a konzumují informace, je klíčové rozumět tomu, jak tyto systémy rozpoznávají a odkazují entity—včetně vaší značky. Porozumění entitám je mechanismus, kterým AI systémy identifikují a zpracovávají zmínky o firmách, produktech, osobách a pojmech. Sledujete-li, jak AI systémy rozpoznávají a odkazují vaši značku prostřednictvím rozpoznávání entit, získáváte přehled o tom:
Právě to AmICited monitoruje—sleduje, jak AI systémy rozpoznávají a odkazují vaši značku jako entitu napříč různými AI platformami. Porozuměním rozpoznávání entit lépe porozumíte, jak AI systémy vnímají a komunikují o vašem podnikání.
Rozpoznávání entit (NER) identifikuje a klasifikuje entity v textu (např. „Apple“ jako ORGANIZACE), zatímco propojení entit spojuje tyto entity s znalostními bázemi nebo kanonickými odkazy (např. propojení „Apple“ se stránkou na Wikipedii pro Apple Inc.). Rozpoznávání entit je první krok; propojení entit přidává sémantické ukotvení.
Nejmodernější modely založené na transformerech jako BERT dosahují 90,9% F1 skóre na standardních benchmarcích jako CoNLL-2003. Přesnost se však výrazně liší podle domény—modely trénované na zpravodajství si vedou špatně na biomedicínském nebo sociálním textu. Skutečná přesnost závisí výrazně na přizpůsobení doméně a kvalitě dat.
Ano, vícejazyčné modely jako mBERT a XLM-RoBERTa podporují více než 100 jazyků současně. Výkon se však liší podle jazyka kvůli rozdílům v konvencích psaní velkých písmen, morfologii a dostupných trénovacích datech. Modely určené pro konkrétní jazyk obvykle překonávají vícejazyčné v kritických aplikacích.
Pravidlové systémy používají ručně vytvořené vzory a slovníky (rychlé, srozumitelné, ale křehké). ML systémy se učí ze značených dat (flexibilnější, lepší generalizace, ale vyžadují trénovací data a návrh příznaků). Moderní hluboké učení automatizuje extrakci příznaků a dosahuje vyšší přesnosti.
Pravidlové systémy potřebují jen definice vzorů. Klasické ML modely vyžadují 300-500 označených příkladů. Modely založené na transformerech pracují s 800+ příklady, ale těží z transfer learningu—předtrénované modely mohou dosáhnout dobrých výsledků už s 100-200 doménově specifickými příklady díky doladění.
Klíčové výzvy zahrnují: nejednoznačnost (stejné slovo znamená různé věci), neznámé entity, adaptaci na doménu (modely trénované pro jednu doménu selhávají v jiné), chyby v určení hranic entit, vícejazyčné složitosti a nedostatek dat pro specializované domény. Tyto aspekty vyžadují pečlivý návrh systému a doladění pro konkrétní domény.
Kontext je klíčový—„banka“ znamená něco jiného v „říční břeh“ než v „spořitelní banka“. Moderní transformery využívají self-attention, aby zohlednily kontext všech okolních tokenů, což jim umožňuje rozlišit entity na základě jazykového a sémantického kontextu. Špatné zpracování kontextu je hlavním zdrojem chyb v rozpoznávání entit.
Budoucí vývoj zahrnuje: velké jazykové modely umožňující rozpoznávání entit bez příkladů, multimodální porozumění kombinující text a obrázky, zpracování v reálném čase na edge zařízeních a pokroky v doladění pro specifické domény. Porozumění entitám se stane neviditelnou základní vrstvou, která umožní strojům chápat svět s lidskou sémantickou přesností.
AmICited sleduje zmínky o entitách napříč AI systémy jako ChatGPT, Perplexity a Google AI Overviews. Zjistěte, jak AI rozumí a odkazuje na vaši značku v reálném čase.
Rozpoznávání entit je schopnost AI NLP identifikující a kategorizující pojmenované entity v textu. Zjistěte, jak funguje, jeho využití v AI monitoringu a jeho r...

Zjistěte, jak budovat viditelnost entity ve vyhledávání AI. Ovládněte optimalizaci knowledge graphu, schema markup a entity SEO strategie pro zvýšení povědomí o...

Zjistěte, jak AI systémy identifikují, extrahují a chápou vztahy mezi entitami v textu. Objevte techniky extrakce vztahů mezi entitami, metody NLP a jejich reál...