
Kompletní průvodce blokováním (nebo povolováním) AI crawlerů
Naučte se, jak blokovat nebo povolovat AI crawlery jako GPTBot a ClaudeBot pomocí robots.txt, blokování na úrovni serveru a pokročilých metod ochrany. Kompletní...
6 min čtení
Zjistěte, jak implementovat selektivní blokování AI crawlerů a chránit svůj obsah před trénovacími roboty a zároveň si zachovat viditelnost ve výsledcích AI vyhledávání. Technické strategie pro vydavatele.
Vydavatelé dnes čelí nemožné volbě: zablokovat všechny AI crawlery a přijít o cennou návštěvnost z vyhledávačů, nebo je všechny povolit a sledovat, jak jejich obsah pohání trénovací datasety bez jakékoli kompenzace. Nástup generativní AI vytvořil rozdělený ekosystém crawlerů, kde stejná pravidla robots.txt platí nerozlišovaně jak pro vyhledávače generující příjmy, tak pro tréninkové crawlery, které jen těží hodnotu. Tento paradox přiměl pokrokové vydavatele k vývoji strategií selektivní kontroly crawlerů, které rozlišují mezi různými typy AI botů podle jejich skutečného dopadu na obchodní metriky.
Ekosystém AI crawlerů se dělí na dvě odlišné kategorie s naprosto rozdílnými účely a obchodními dopady. Tréninkové crawlery – provozované společnostmi jako OpenAI, Anthropic a Google – jsou navrženy ke sběru obrovského množství textových dat pro stavbu a zlepšování jazykových modelů, zatímco vyhledávací crawlery indexují obsah pro jeho následné vyhledání a objevení. Tréninkové boty tvoří přibližně 80 % veškeré aktivity AI botů, přesto pro vydavatele negenerují žádné přímé příjmy, zatímco vyhledávací crawlery jako Googlebot a Bingbot přivádějí ročně miliony návštěv a reklamních zobrazení. Toto rozlišení je důležité, protože jediný tréninkový crawler může spotřebovat šířku pásma odpovídající tisícům lidských uživatelů, zatímco vyhledávací crawlery jsou optimalizované pro efektivitu a obvykle respektují nastavené limity.
| Název bota | Provozovatel | Hlavní účel | Potenciál návštěvnosti |
|---|---|---|---|
| GPTBot | OpenAI | Trénink modelu | Žádný (extrakce dat) |
| Claude Web Crawler | Anthropic | Trénink modelu | Žádný (extrakce dat) |
| Googlebot | Indexace vyhledávání | 243,8M návštěv (duben 2025) | |
| Bingbot | Microsoft | Indexace vyhledávání | 45,2M návštěv (duben 2025) |
| Perplexity Bot | Perplexity AI | Vyhledávání + trénink | 12,1M návštěv (duben 2025) |
Data jsou jasná: samotný crawler ChatGPT poslal v dubnu 2025 vydavatelům 243,8 milionu návštěv, ale tyto návštěvy vygenerovaly nula kliknutí, nula reklamních zobrazení a nula příjmů. Oproti tomu návštěvnost od Googlebota vedla ke skutečnému zapojení uživatelů a monetizačním příležitostem. Pochopení tohoto rozdílu je prvním krokem k zavedení selektivní blokovací strategie, která ochrání váš obsah a zároveň zachová vaši viditelnost ve vyhledávání.
Plošné blokování všech AI crawlerů je pro většinu vydavatelů ekonomicky sebedestruktivní. Zatímco tréninkové crawlery pouze těží hodnotu bez kompenzace, vyhledávací crawlery zůstávají jedním z nejspolehlivějších zdrojů návštěvnosti v čím dál roztříštěnějším digitálním prostředí. Finanční argument pro selektivní blokování stojí na několika klíčových faktorech:
Vydavatelé, kteří zavedli selektivní blokování, uvádějí, že si udrželi či zlepšili vyhledávací návštěvnost a zároveň snížili neoprávněnou extrakci obsahu až o 85 %. Strategický přístup uznává, že ne všichni AI crawlery jsou stejní, a že promyšlená politika lépe chrání obchodní zájmy než plošné blokování.
Soubor robots.txt zůstává hlavním mechanismem pro komunikaci povolení crawlerům a je překvapivě účinný při rozlišování různých typů botů, pokud je správně nakonfigurován. Tento jednoduchý textový soubor, umístěný v kořenovém adresáři webu, používá direktivy user-agent k určení, které crawlery mohou přistupovat k jakému obsahu. Pro selektivní kontrolu AI crawlerů můžete povolit vyhledávače a přitom blokovat tréninkové crawlery s chirurgickou přesností.
Praktický příklad, jak blokovat tréninkové crawlery a povolit vyhledávače:
# Blokovat GPTBot od OpenAI
User-agent: GPTBot
Disallow: /
# Blokovat Claude crawler od Anthropicu
User-agent: Claude-Web
Disallow: /
# Blokovat další tréninkové crawlery
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Povolit vyhledávače
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Tento přístup poskytuje jasné instrukce dobře se chovajícím crawlerům a zároveň zachovává objevitelnost vašeho webu ve výsledcích vyhledávání. Robots.txt je však v zásadě dobrovolný standard – spoléhá na to, že provozovatelé crawlerů budou vaše pokyny respektovat. Pro vydavatele, kteří se obávají nedodržování, jsou nutné další vrstvy vynucování.
Samotný robots.txt nemůže zaručit dodržování, protože přibližně 13 % AI crawlerů direktivy robots.txt zcela ignoruje, ať už z nedbalosti nebo záměrně. Vynucování na úrovni webového serveru nebo aplikační vrstvy poskytuje technickou pojistku, která zabraňuje neoprávněnému přístupu bez ohledu na chování crawleru. Tento přístup blokuje požadavky na úrovni HTTP dříve, než spotřebují významné množství šířky pásma nebo serverových prostředků.
Implementace blokování na úrovni serveru pomocí Nginx je přímočará a vysoce účinná:
# V rámci server bloku Nginx
location / {
# Blokovat tréninkové crawlery na úrovni serveru
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Blokovat podle IP rozsahů (pro crawlery, které falšují user-agenta)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Pokračovat v běžném zpracování požadavků
proxy_pass http://backend;
}
Tato konfigurace vrací blokovaným crawlerům odpověď 403 Forbidden a spotřebuje minimum serverových prostředků, přičemž jasně sděluje, že přístup je odepřen. V kombinaci s robots.txt vytváří vynucování na úrovni serveru dvouvrstvou obranu, která zachytí jak poctivé, tak nepoctivé crawlery. Míra obcházení 13 % klesá téměř na nulu, pokud jsou pravidla na úrovni serveru správně implementována.
Content Delivery Networky a Web Application Firewally poskytují další vrstvu vynucování, která funguje ještě před tím, než požadavky dorazí na vaše původní servery. Služby jako Cloudflare, Akamai a AWS WAF vám umožní vytvářet pravidla, která blokují konkrétní user-agenty nebo IP rozsahy na hranici sítě a brání škodlivým nebo nežádoucím crawlerům ve spotřebě vašich zdrojů. Tyto služby udržují aktualizované seznamy známých IP rozsahů a user-agentů tréninkových crawlerů a automaticky je blokují bez nutnosti manuální konfigurace.
Kontrola na úrovni CDN má oproti vynucování na úrovni serveru několik výhod: snižuje zátěž původního serveru, umožňuje geografické blokování a nabízí analýzy blokovaných požadavků v reálném čase. Mnoho CDN dnes nabízí AI-specifická blokovací pravidla jako standardní funkci, protože reagují na rozšířené obavy vydavatelů z neautorizovaného sběru trénovacích dat. Pro vydavatele používající Cloudflare poskytuje zapnutí možnosti „Block AI Crawlers“ v nastavení zabezpečení jedním kliknutím ochranu proti hlavním tréninkovým crawlerům, aniž by byla omezena dostupnost pro vyhledávače.
Efektivní selektivní blokování vyžaduje systematický přístup ke klasifikaci crawlerů podle jejich obchodního dopadu a důvěryhodnosti. Namísto zacházení se všemi AI crawlery stejně by měli vydavatelé zavést třístupňový rámec, který odráží skutečnou hodnotu a riziko, jež každý crawler představuje. Tento rámec umožňuje nuancovaná rozhodnutí, která vyvažují ochranu obsahu s obchodními příležitostmi.
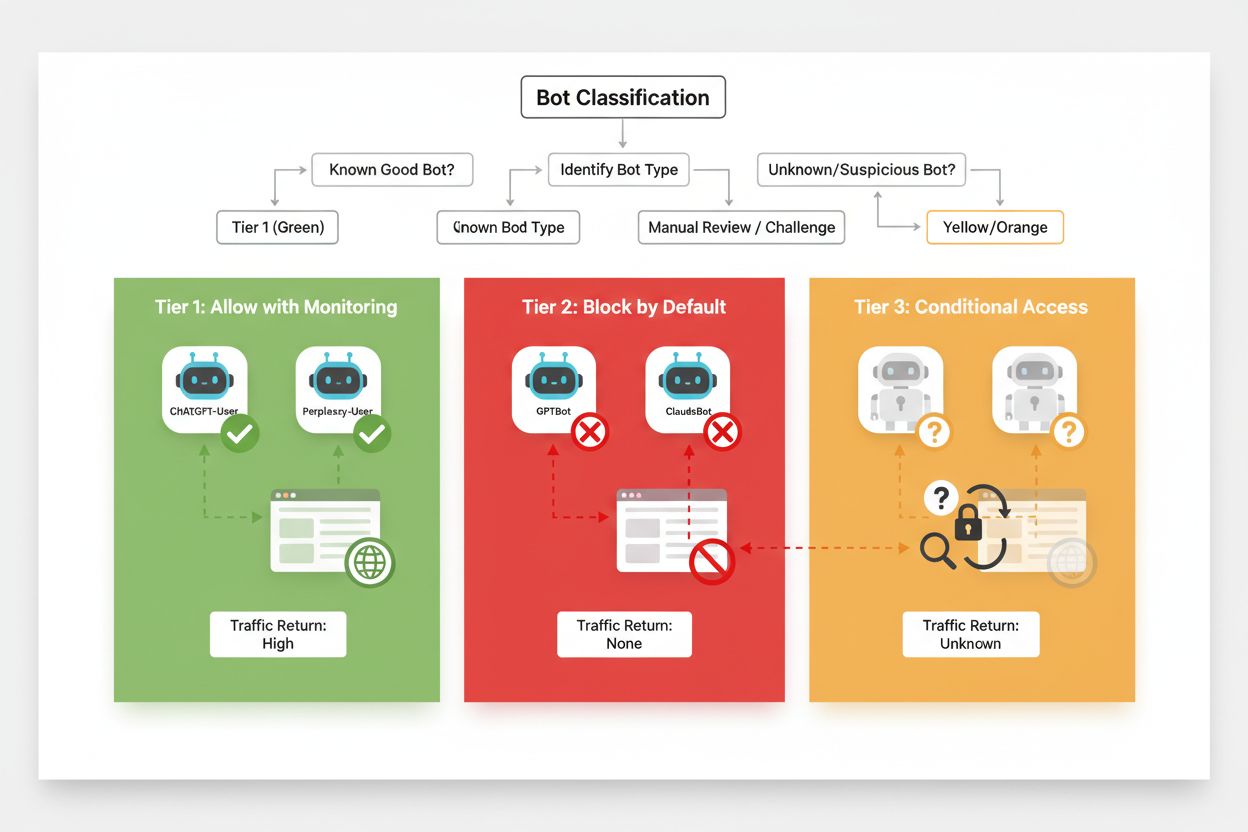
| Úroveň | Klasifikace | Příklady | Akce |
|---|---|---|---|
| Tier 1: Generátoři příjmů | Vyhledávače a zdroje vysoké návštěvnosti | Googlebot, Bingbot, Perplexity Bot | Povolit plný přístup; optimalizovat pro procházení |
| Tier 2: Neutrální/neprověření | Nové nebo začínající crawlery s nejasným záměrem | Menší AI startupy, výzkumné boty | Pečlivě sledovat; povolit s omezením rychlosti |
| Tier 3: Těžaři hodnoty | Tréninkové crawlery bez přímého přínosu | GPTBot, Claude-Web, CCBot | Plně blokovat; vynucovat na více úrovních |
Implementace tohoto rámce vyžaduje průběžný výzkum nových crawlerů a jejich obchodních modelů. Vydavatelé by měli pravidelně kontrolovat přístupové logy, identifikovat nové boty, zkoumat obchodní podmínky jejich provozovatelů a politiky kompenzace a podle toho upravovat klasifikace. Crawler, který začíná jako Tier 3, se může přesunout do Tier 2, pokud jeho provozovatel nabídne podíl na příjmech, zatímco dříve důvěryhodný crawler může spadnout do Tier 3, pokud začne porušovat limity nebo pravidla robots.txt.
Selektivní blokování není nastavení typu „nastav a zapomeň“ – vyžaduje průběžné sledování a úpravy podle toho, jak se ekosystém crawlerů vyvíjí. Vydavatelé by měli zavést důkladné logování a analýzu, aby sledovali, které crawlery mají přístup k jejich obsahu, kolik šířky pásma spotřebují a zda dodržují nastavená omezení. Tato data informují strategická rozhodnutí o tom, kterým crawlerům povolit, zablokovat nebo omezit přístup.
Analýza přístupových logů odhaluje vzorce chování crawlerů, které pomáhají upravit politiku:
# Identifikujte všechny AI crawlery přistupující na váš web
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Spočítejte šířku pásma spotřebovanou konkrétními crawlery
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandwidth: " sum/1024/1024 " MB"}'
# Sledujte odpovědi 403 pro blokované crawlery
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Pravidelná analýza těchto dat – ideálně týdně nebo měsíčně – odhalí, zda vaše blokovací strategie funguje, zda se objevili noví crawlery nebo zda dříve blokovaní crawlery změnili své chování. Tyto informace poslouží k aktualizaci klasifikačního rámce a zajištění souladu vaší politiky s obchodními cíli i technickou realitou.
Vydavatelé při zavádění selektivního blokování crawlerů často dělají chyby, které jejich strategii oslabují nebo vedou k nechtěným důsledkům. Pochopení těchto nástrah vám pomůže se vyvarovat nákladných chyb a od začátku nasadit efektivnější politiku.
Nerozlišované blokování všech crawlerů: Nejčastější chybou je příliš široké blokování, které kromě tréninkových crawlerů zachytí i vyhledávače a zničí viditelnost ve vyhledávání ve snaze ochránit obsah.
Spoléhání pouze na robots.txt: Domnívat se, že samotný robots.txt zabrání neoprávněnému přístupu, ignoruje 13 % crawlerů, kteří jej zcela obcházejí, a vystavuje váš obsah riziku extrakce dat.
Nesledování a neupravování politiky: Zavést statickou blokovací politiku a již ji nikdy nerevidovat znamená přehlédnout nové crawlery, nezareagovat na změny obchodních modelů a potenciálně blokovat prospěšné crawlery, kteří své praktiky zlepšili.
Blokování pouze podle user-agenta: Sofistikovaní crawlery user-agenta falšují nebo často střídají, takže samotné blokování podle user-agenta je neúčinné bez doplňujících IP pravidel a omezení rychlosti.
Ignorování omezení rychlosti: I povolené crawlery mohou spotřebovat nadměrné množství šířky pásma, pokud nejsou omezeny, což snižuje výkon pro skutečné uživatele a zbytečně zatěžuje infrastrukturu.
Budoucnost vztahu vydavatel–AI crawler pravděpodobně přinese sofistikovanější vyjednávání a modely kompenzace namísto prostého blokování. Do té doby však zůstává selektivní kontrola crawlerů nejpraktičtějším způsobem, jak chránit obsah a zároveň neztratit viditelnost ve vyhledávání. Vydavatelé by měli svou blokovací strategii vnímat jako dynamickou politiku, která se vyvíjí spolu s ekosystémem crawlerů a pravidelně revidovat, kterým crawlerům umožnit přístup na základě jejich obchodního přínosu a důvěryhodnosti.
Nejúspěšnější budou ti vydavatelé, kteří zavedou vrstvenou obranu – spojení direktiv robots.txt, vynucování na úrovni serveru, kontroly na úrovni CDN a průběžného monitoringu do komplexní strategie. Tento přístup chrání jak před poctivými, tak nepoctivými crawlery a zároveň zachovává návštěvnost z vyhledávačů, která tvoří základ příjmů a uživatelského zapojení. Jak AI společnosti čím dál více uznávají hodnotu vydavatelského obsahu a začnou nabízet kompenzace či licenční modely, rámec, který dnes vybudujete, se snadno přizpůsobí novým obchodním modelům a zároveň si zachováte kontrolu nad svými digitálními aktivy.
Tréninkové crawlery jako GPTBot a ClaudeBot sbírají data pro vytváření AI modelů, aniž by přiváděly návštěvnost na váš web. Vyhledávací crawlery jako OAI-SearchBot a PerplexityBot indexují obsah pro AI vyhledávače a mohou přivádět významnou referenční návštěvnost zpět na váš web. Pochopení tohoto rozdílu je klíčové pro efektivní implementaci selektivní blokovací strategie.
Ano, to je podstata strategie selektivní kontroly crawlerů. Pomocí robots.txt můžete zakázat tréninkové roboty a povolit vyhledávací roboty, a následně vynucovat omezení na úrovni serveru pro roboty, kteří robots.txt ignorují. Tento přístup chrání váš obsah před neoprávněným tréninkem a zároveň zachovává viditelnost v AI výsledcích vyhledávání.
Většina hlavních AI společností tvrdí, že robots.txt respektují, ale dodržování je dobrovolné. Výzkumy ukazují, že přibližně 13 % AI botů pokyny robots.txt zcela obchází. Proto je pro vydavatele, kteří to s ochranou svého obsahu myslí vážně, zásadní vynucování pravidel na úrovni serveru.
Významně a rostoucím tempem. ChatGPT v dubnu 2025 poslal 243,8 milionu návštěv na 250 zpravodajských a mediálních webů, což je nárůst o 98 % oproti lednu. Blokováním těchto crawlerů přicházíte o tento nově vznikající zdroj návštěvnosti. Pro mnoho vydavatelů nyní AI vyhledávací provoz představuje 5-15 % celkové referenční návštěvnosti.
Pravidelně analyzujte serverové logy pomocí příkazů grep pro identifikaci uživatelských agentů botů, sledujte četnost procházení a monitorujte dodržování pravidel robots.txt. Prohlížejte logy alespoň jednou měsíčně, abyste odhalili nové boty, neobvyklé vzorce chování a ověřili, že blokovaní boti skutečně zůstávají mimo. Tato data informují strategická rozhodnutí o vaší politice vůči crawlerům.
Ochráníte svůj obsah před neoprávněným tréninkem, ale ztratíte viditelnost ve výsledcích AI vyhledávání, přijdete o nové zdroje návštěvnosti a potenciálně snížíte počet zmínek vaší značky v AI generovaných odpovědích. Vydavatelé, kteří zavedou plošné blokování, často zaznamenávají snížení viditelnosti ve vyhledávání o 40-60 % a přijdou o příležitosti k objevení značky prostřednictvím AI platforem.
Minimálně jednou měsíčně, protože neustále vznikají nové boty a stávající mění své chování. Ekosystém AI crawlerů se rychle mění, objevují se noví provozovatelé a stávající hráči slučují či přejmenovávají své boty. Pravidelné revize zajistí, že vaše politika zůstane v souladu s obchodními cíli i technickou realitou.
Jde o počet procházených stránek vůči počtu návštěvníků odeslaných zpět na váš web. Anthropic prochází 38 000 stránek na každého doporučeného návštěvníka, zatímco OpenAI udržuje poměr 1 091:1 a Perplexity je na 194:1. Nižší poměry znamenají lepší hodnotu za umožnění přístupu crawleru. Tato metrika vám pomáhá rozhodnout, kterým crawlerům přístup povolit na základě jejich skutečného obchodního přínosu.
AmICited sleduje, které AI platformy citují vaši značku a obsah. Získejte přehled o své AI viditelnosti a zajistěte si správné přiřazení napříč ChatGPT, Perplexity, Google AI Overviews a dalšími.
Naučte se, jak blokovat nebo povolovat AI crawlery jako GPTBot a ClaudeBot pomocí robots.txt, blokování na úrovni serveru a pokročilých metod ochrany. Kompletní...

Naučte se, jak strategicky rozhodovat o blokování AI crawlerů. Vyhodnoťte typ obsahu, zdroje návštěvnosti, modely příjmů a konkurenční pozici pomocí našeho komp...

Zjistěte, které AI crawlery povolit nebo blokovat ve vašem robots.txt. Komplexní průvodce zahrnující GPTBot, ClaudeBot, PerplexityBot a 25+ AI crawlerů s ukázka...