Kanonické URL a AI: Prevence problémů s duplicitním obsahem
Zjistěte, jak kanonické URL předcházejí problémům s duplicitním obsahem v AI vyhledávačích. Objevte osvědčené postupy pro implementaci kanonických URL, které zlepší viditelnost v AI a zajistí správné přiřazení obsahu.
Publikováno dne Jan 3, 2026.Naposledy upraveno dne Jan 3, 2026 v 3:24 am
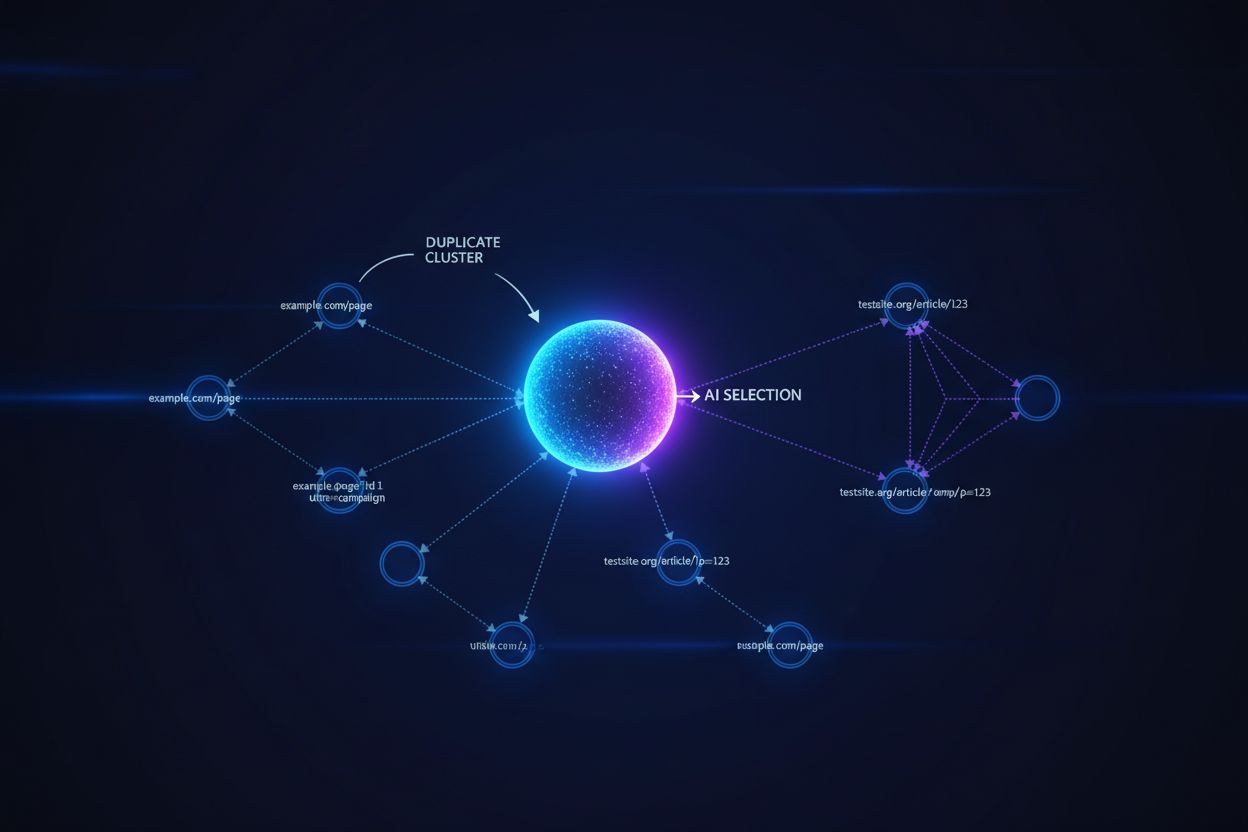
Velké jazykové modely a AI vyhledávače využívají sofistikované shlukovací algoritmy k identifikaci a seskupování téměř duplicitních URL, přičemž různé verze téhož obsahu považují za jediný subjekt pro účely hodnocení a citací. Když AI systémy narazí na duplicitní obsah, musí vybrat, kterou verzi upřednostní – toto rozhodnutí přímo ovlivňuje, která URL získá viditelnost, autoritativní signály a přiřazení uživatele. Kritický problém nastává, když AI zvolí nesprávnou verzi: pokud vaše kanonická URL ukazuje na preferovanou stránku, ale AI systém shlukuje a hodnotí místo toho méně kvalitní duplikát, váš obsah ztrácí viditelnost i kredit za citace. Signály záměru se rozptýlí mezi duplicitní verze, čímž se tříští autorita, která by měla být koncentrována na jediné URL, a každá duplicitní verze dostává slabší rankingové signály, než kdyby veškerá autorita směřovala na kanonickou verzi.
Proč jsou kanonické URL důležité pro viditelnost v AI
Kanonické tagy slouží jako explicitní signály pro AI systémy, která verze duplicitního obsahu má být považována za autoritativní, a přímo ovlivňují, zda se vaše preferovaná URL objeví v AI generovaných odpovědích a získá správné přiřazení. Bez kanonických tagů musí AI systémy učinit vlastní rozhodnutí o shlukování na základě podobnosti obsahu, odkazových vzorců a signálů aktuálnosti – což často vede k tomu, že jako zdrojová kanonická verze je vybrána nesprávná varianta. Pokud existuje duplicitní obsah bez správné implementace kanonických, mohou AI odpovědi citovat syndikovanou verzi, uloženou kopii nebo méně kvalitní variantu místo vašeho původního obsahu, čímž se vaše viditelnost tříští mezi více URL. Kanonické URL zajišťují, že když AI systémy narazí na váš obsah napříč různými doménami, parametry nebo verzemi, chápou, která jediná URL by měla získat kredit a být uvedena v odpovědích.
Scénář
Bez kanonického
S kanonickým
Dopad na AI
AI samostatně shlukuje duplicity; může zvolit špatnou verzi pro hodnocení
AI rozpozná jediný autoritativní zdroj; konsoliduje všechny signály na kanonickou URL
Přiřazení citace
Přiřazení rozptýleno mezi více URL; slabší autorita pro jednotlivé URL
Všechny citace a autorita proudí na kanonickou URL; silnější viditelnost
Výsledek
Obsah se objeví v AI odpovědích, ale kredit získá špatná URL; roztříštěná viditelnost
Preferovaná URL se objeví v AI odpovědích se sjednocenými autoritativními signály
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Kanonické tagy a přesměrování mají v rámci správy duplicitního obsahu pro AI systémy různé účely: kanonické tagy říkají vyhledávačům a AI systémům, která verze je preferovaná, přičemž obě URL zůstávají dostupné, zatímco přesměrování trvale přesměruje uživatele a crawlery z jedné URL na druhou. Přesměrování (301 pro trvalé, 302 pro dočasné) jsou silnější signály, protože veškerou autoritu konsolidují do jedné URL a duplikát zcela eliminují z webu, což je ideální při trvalém rušení URL nebo konsolidaci domén. Kanonické tagy jsou vhodnější, pokud potřebujete z obchodních důvodů udržovat více URL – například pro sledování parametrů v analytice, zachování starších URL pro záložky uživatelů nebo poskytování různých verzí různým cílovým skupinám – a zároveň chcete AI systémům signalizovat, která verze je autoritativní. Přesměrování použijte při konsolidaci domén po migraci, odstraňování zastaralých verzí nebo eliminaci variant parametrů, které neslouží žádnému účelu. Kanonické tagy použijte, pokud musíte udržovat více URL, ale chcete zabránit penalizaci za duplicitní obsah a zajistit, aby AI systémy rozuměly vaší preferované verzi.
Hlavní rozdíly mezi kanonickými a přesměrováními:
Uživatelská zkušenost: Přesměrování pošle uživatele na jedinou URL; kanonické ponechávají uživatele na původní URL a pouze signalizují preferenci AI systémům
Konsolidace autority: Přesměrování plně konsoliduje autoritu do jedné URL; kanonické autoritu rozdělují, ale signalizují preferenci
Efektivita crawlování: Přesměrování snižuje zbytečné crawlování eliminací duplicit; kanonické stále vyžadují procházení obou verzí
Reverzibilita: Kanonické lze snadno měnit; přesměrování jsou trvalá a obtížněji vratná bez narušení uživatelské zkušenosti
Běžné problémy s duplicitním obsahem v AI vyhledávání
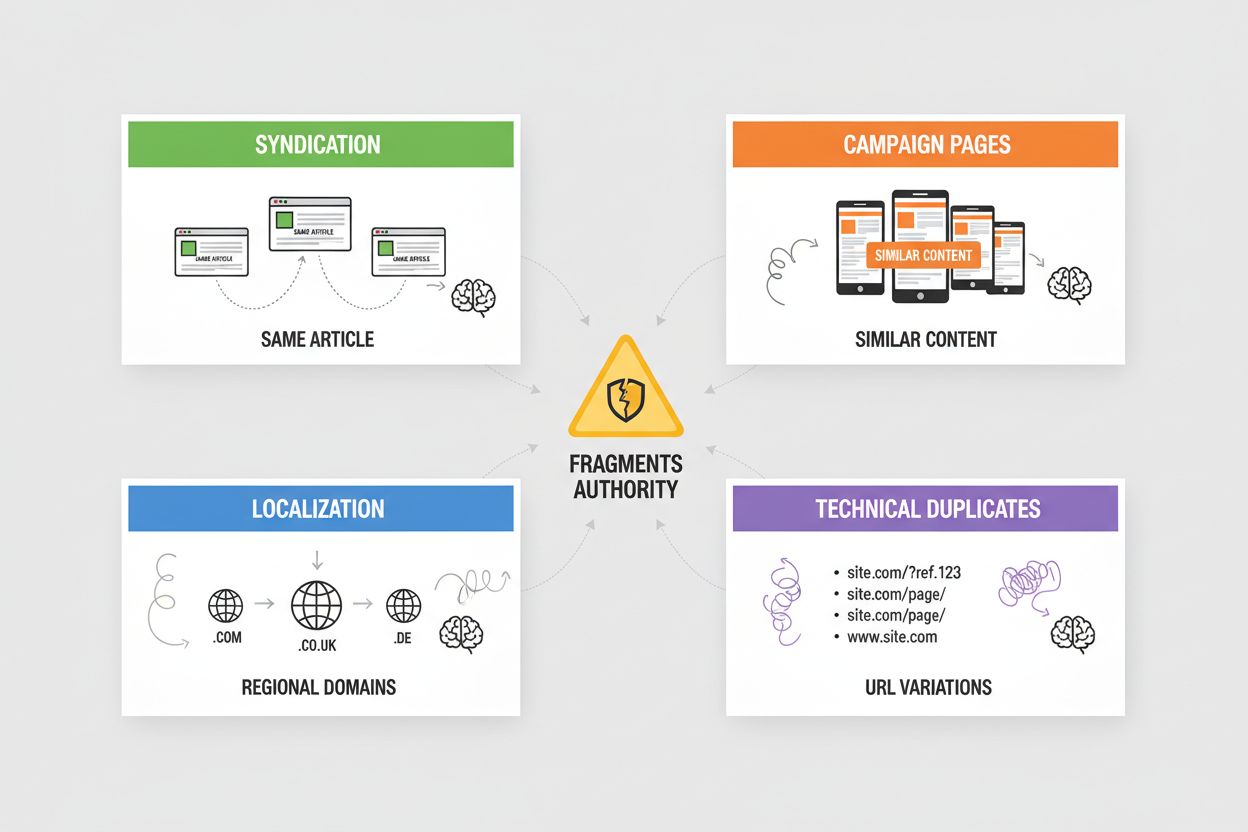
Syndikace vytváří rozsáhlý duplicitní obsah, když jsou vaše články přebírány na partnerských webech, agregátorech zpráv či obsahových sítích – AI systémy musí rozhodnout, zda kreditovat původní zdroj nebo syndikovanou verzi, často preferují tu, která se objeví první při crawlování. Kampaňové stránky generují duplicity, když vytváříte více landing pages s totožným nebo téměř totožným obsahem pro různé marketingové kanály, UTM parametry nebo A/B testování, což způsobuje, že AI systémy tříští autoritu mezi varianty, které by měly být sloučeny. Lokalizace a internacionalizace vytváří duplicity, pokud poskytujete podobný obsah na regionálních doménách (example.com, example.co.uk, example.de) nebo jazykových verzích, a je potřeba použít hreflang tagy a kanonické, aby AI systémy tyto varianty správně rozlišily jako záměrné, nikoli jako duplicity. Technické duplicity vznikají ze session ID, sledovacích parametrů, tiskových verzí a variant URL (www vs. non-www, http vs. https, lomítko na konci), které vedou k více URL se stejným obsahem – AI systémy tyto varianty vnímají jako duplicity a musí rozhodnout, kterou upřednostní. Každý z těchto scénářů rozptyluje autoritu, která by měla být soustředěna na vaši preferovanou URL, snižuje vaši viditelnost v AI odpovědích a způsobuje, že kredit za citaci je rozptýlen mezi více verzí.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Osvědčené postupy implementace kanonických URL
Vždy používejte absolutní URL ve svých kanonických tagách místo relativních URL, aby AI systémy a vyhledávače mohly jednoznačně identifikovat cílovou URL bez ohledu na umístění tagu. Zahrňte samoodkazující kanonické na své preferované stránky – i stránky bez duplicit by měly samy sebe označovat jako kanonické, čímž zabráníte tomu, aby AI systémy určovaly kanoniku na základě odkazových vzorců nebo podobnosti obsahu. Kanonické tagy umisťujte do části <head> vašeho HTML dokumentu a pro ne-HTML obsah (PDF, obrázky) implementujte kanonické pomocí HTTP hlaviček, abyste zajistili, že AI crawlery rozpoznají vaši preferenci bez ohledu na typ obsahu.
<!-- Správná implementace kanonického v HTML head --><linkrel="canonical"href="https://example.com/article/canonical-urls-ai" />
Zahrňte kanonické URL do svých XML sitemap pro posílení autority a kombinujte kanonické s hreflang tagy při správě mezinárodního nebo lokalizovaného obsahu, abyste zabránili tomu, že AI systémy budou regionální varianty považovat za duplicity. Vyhněte se běžným chybám: nikdy nevytvářejte řetězení kanonických (A→B→C), nikdy nesměřujte kanonické na stránky s noindex, a nikdy nepoužívejte kanonické k manipulaci s hodnocením odkazováním na nesouvisející obsah. Monitorujte implementaci kanonických pomocí nástrojů jako Google Search Console, Bing Webmaster Tools a AmICited.com, abyste ověřili, že AI systémy vaše preferované URL rozpoznávají a správně přiřazují obsah.
<!-- Správná implementace s hreflang pro mezinárodní obsah --><linkrel="canonical"href="https://example.com/article/canonical-urls-ai" />
<linkrel="alternate"hreflang="en-GB"href="https://example.co.uk/article/canonical-urls-ai" />
<linkrel="alternate"hreflang="de"href="https://example.de/artikel/canonical-urls-ai" />
Sledování a oprava problémů s kanonickými
Proveďte audit svých kanonických URL procházením celého webu nástroji jako Screaming Frog, SEMrush nebo Ahrefs, abyste identifikovali stránky s chybějícími kanonickými, rozbitými řetězci kanonických nebo kanonickými směřujícími na stránky s noindex – tyto problémy brání AI systémům v řádné konsolidaci autority. Použijte Přehled pokrytí v Google Search Console k identifikaci stránek s duplicitním obsahem a ověření, že Google vaše kanonické preference rozpoznává, a poté porovnejte s Bing Webmaster Tools, abyste zajistili konzistenci napříč AI vyhledávači. Implementujte IndexNow pro okamžité upozornění vyhledávačů a AI crawlerů při přidání, aktualizaci nebo odstranění kanonických tagů, což urychlí objevení vašich preferencí místo čekání na běžné crawlovací cykly. Sledujte AI citace pomocí nástrojů jako AmICited.com a manuálních vyhledávání v ChatGPT, Claude a Perplexity, abyste ověřili, že vaše preferované URL získávají přiřazení v AI odpovědích – pokud jsou místo nich citovány duplicity, znovu prověřte implementaci kanonických a ujistěte se, že tagy jsou správně formátované a umístěné. Pravidelně provádějte audit nového duplicitního obsahu vzniklého syndikací, spuštěním kampaní nebo technickými změnami a implementujte kanonické preventivně, abyste udrželi konzistentní AI viditelnost.
Často kladené otázky
Co je kanonická URL a proč je důležitá pro AI vyhledávání?
Kanonická URL je preferovaná verze stránky, kterou chcete, aby vyhledávače a AI systémy rozpoznaly jako autoritativní. Je důležitá pro AI vyhledávání, protože LLM seskupují téměř duplicitní URL a vybírají jednu verzi, která reprezentuje celou skupinu. Bez správné implementace kanonické URL může AI systém citovat nesprávnou verzi vašeho obsahu, což tříští vaši viditelnost a přiřazení napříč více URL.
Jak AI systémy zpracovávají duplicitní obsah jinak než tradiční vyhledávače?
AI systémy používají shlukovací algoritmy ke seskupení téměř duplicitních URL do jednotlivých celků a poté vybírají jednu verzi, která reprezentuje celý shluk. To se liší od tradičních vyhledávačů, protože AI odpovědi vyžadují jedinou zdrojovou URL pro přiřazení. Pokud není vaše kanonická správně implementována, může AI vybrat syndikovanou verzi, uloženou kopii nebo méně kvalitní variantu místo vašeho preferovaného URL.
Mám použít kanonické tagy nebo přesměrování pro řešení duplicitního obsahu?
Kanonické tagy použijte tehdy, když potřebujete udržovat více URL z obchodních důvodů (sledovací parametry, starší URL, různé cílové skupiny) a zároveň signalizovat preferenci AI systémům. Přesměrování použijte, pokud trvale rušíte URL, konsolidujete domény nebo odstraňujete varianty parametrů, které nemají smysl. Přesměrování jsou silnější signály, protože plně konsolidují autoritu, zatímco kanonické pouze signalizují preferenci a rozdělují autoritu.
Jaké jsou nejčastější problémy s duplicitním obsahem ovlivňující AI viditelnost?
Nejčastější problémy jsou: syndikace (přebírání článků na partnerských webech), kampaně (více landing pages se stejným obsahem), lokalizace (podobný obsah na regionálních doménách) a technické duplicity (URL parametry, session ID, lomítka na konci). Každý z těchto problémů tříští autoritu mezi více URL a snižuje viditelnost v AI generovaných odpovědích.
Jak správně implementovat kanonické URL?
Vždy používejte absolutní URL (https://example.com/page, ne /page), umístěte kanonické tagy do části head v HTML, zahrňte samoodkazující kanonické na všechny stránky a vyhněte se řetězení kanonických (A→B→C). Pro ne-HTML obsah, jako jsou PDF, použijte HTTP hlavičky. Zahrňte kanonické do XML sitemap a kombinujte je s hreflang tagy pro mezinárodní obsah.
Jak mohu ověřit, že AI systémy rozpoznávají mé kanonické URL?
Použijte Google Search Console a Bing Webmaster Tools pro ověření rozpoznání kanonických, sledujte AI citace pomocí AmICited.com a manuálních vyhledávání v ChatGPT/Claude/Perplexity a prověřte web nástroji jako Screaming Frog nebo SEMrush. Pokud jsou místo kanonické citovány duplicity, zkontrolujte implementaci a ujistěte se, že tagy jsou správně formátované a umístěné v HTML head.
Co je IndexNow a jak pomáhá s implementací kanonických URL?
IndexNow je protokol, který okamžitě upozorňuje vyhledávače a AI crawlery, když přidáte, aktualizujete nebo odstraníte kanonické tagy, místo čekání na běžné crawlovací cykly. To urychluje objevení vašich kanonických preferencí a pomáhá zajistit, že AI systémy rychleji rozpoznají vaše preferované URL, čímž snižuje dobu, kdy se duplicity objevují v AI odpovědích.
Může AI systém přepsat mé kanonické tagy?
Ano, kanonické tagy jsou silné signály, ale nejsou direktivní. AI systémy mohou vaši kanonickou preferenci přepsat, pokud určí, že jiná verze je autoritativnější na základě kvality obsahu, odkazového profilu, aktuálnosti nebo jiných signálů. Proto je důležitá správná implementace v kombinaci se silným obsahem a autoritou – tím se zvyšuje pravděpodobnost, že AI systémy budou respektovat vaši kanonickou preferenci.
Sledujte své AI citace s AmICited
Sledujte, jak AI systémy jako ChatGPT, Claude a Perplexity citují váš obsah. Ujistěte se, že vaše kanonické URL jsou správně rozpoznávány a že vaše značka je řádně uváděna v AI odpovědích.
Jak AI vyhledávače zacházejí s duplicitním obsahem? Je to jiné než u Googlu?
Diskuze komunity o tom, jak AI systémy zacházejí s duplicitním obsahem odlišně než tradiční vyhledávače. SEO profesionálové sdílí postřehy k jedinečnosti obsahu...
Naučte se, jak spravovat a předcházet duplicitnímu obsahu při použití AI nástrojů. Objevte kanonické tagy, přesměrování, nástroje na detekci a osvědčené postupy...
Znovupublikování obsahu pro AI: Úvahy o duplicitním obsahu
Zjistěte, jak znovupublikování obsahu vytváří problémy s duplicitním obsahem, které poškozují viditelnost ve vyhledávání AI mnohem více než v tradičním vyhledáv...
8 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.