
Proč je originální výzkum klíčový pro AI viditelnost a citace
Zjistěte, proč je tvorba originálního výzkumu zásadní pro viditelnost v AI. Naučte se, jak originální výzkum pomáhá vaší značce být citována v AI odpovědích a z...
8 min čtení
Zjistěte, jak vytvářet originální data a výzkum, které aktivně citují AI systémy. Objevte strategie, jak zpřístupnit svá data ChatGPT, Perplexity, Google Gemini a Claude a zároveň budovat udržitelnou viditelnost v AI světě.
V době umělé inteligence se originální data stala novou konkurenční výhodou pro značky, které chtějí být viditelné i mimo tradiční žebříčky ve vyhledávání. Jak AI platformy jako ChatGPT, Perplexity, Google Gemini a Claude stále více ovlivňují, jak lidé objevují informace, pravidla viditelnosti se zásadně mění. Místo soupeření o pozici nula ve výsledcích Googlu musí organizace nyní vytvářet data, která chtějí AI systémy aktivně citovat a odkazovat. Tato proměna odráží širší posun od obsahového SEO k tomu, čemu odborníci říkají “Generative Engine Optimization” (GEO), kde AI citace nahrazuje tradiční žebříčky jako primární metrika viditelnosti. Platformy, které syntetizují informace do přímých odpovědí—ať už retrieval-augmented generation (RAG) nebo model-native syntézou—přirozeně upřednostňují zdroje poskytující jasný, extrahovatelný a autoritativní originální výzkum. Organizace, které tento posun pochopí a investují do tvorby originálních dat, vlastního výzkumu a jedinečných poznatků, si zajistí citace napříč více AI platformami současně, čímž budují povědomí a důvěryhodnost u publika, které už tradiční výsledky vyhledávání možná nikdy neuvidí.

Různé AI platformy využívají zásadně odlišné architektury pro objevování a citování zdrojů, což přímo ovlivňuje, jak se vaše originální data dostanou na povrch a získají uznání. Pochopení těchto mechanismů je klíčové pro optimalizaci viditelnosti obsahu v AI prostředí. Rozdíl mezi model-native syntézou (AI generuje odpovědi na základě vzorů v tréninkových datech) a retrieval-augmented generation (AI prohledává živé zdroje a syntetizuje z nalezených výsledků) vysvětluje, proč některé platformy poskytují explicitní citace, zatímco jiné odpovídají bez odkazu na zdroj. Platformy využívající RAG systémy mohou své odpovědi vysledovat ke konkrétním zdrojům, což činí citace srozumitelnými a dohledatelnými. Oproti tomu model-native systémy se spoléhají na pravděpodobnostní znalosti získané během tréninku, takže zpětné přiřazení zdroje je obtížné či nemožné bez dalších pluginů či integrací.
| AI platforma | Způsob citace | Priorita zdroje dat | Dopad na viditelnost |
|---|---|---|---|
| ChatGPT | Model-native (výchozí); odkázané citace s pluginy/povoleným prohlížením | Tréninková data + živý web při povolení; upřednostňuje aktuální, autoritativní zdroje při aktivním retrieval | Nízká bez pluginů; střední při zapnutém vyhledávání; citace se zobrazují v textu odpovědi, pokud jsou dostupné |
| Perplexity | Retrieval-first s číslovanými inline citacemi | Výsledky živého vyhledávání na webu; upřednostňuje čerstvé, přímo relevantní zdroje; zdůrazňuje významnost zdroje | Vysoká; číslované citace s jasnými odkazy na zdroj; zdroje na prvním místě získávají nepoměrnou návštěvnost |
| Google Gemini | Integrované s Google Search a Knowledge Graph | Živě indexované stránky + entity v Knowledge Graph; upřednostňuje stránky se strukturovanými daty a signály E-E-A-T | Vysoká; citace se zobrazují jako odkazy ve zdrojích AI Overviews; strukturovaná data zvyšují pravděpodobnost citace |
| Claude | Model-native (výchozí); rozšiřování webového vyhledávání v roce 2025 | Tréninková data + selektivní živé vyhledávání; upřednostňuje bezpečné, autoritativní zdroje | Střední; citace se objevují při povoleném webovém vyhledávání; důraz na přesnost a důvěryhodnost zdrojů |
Praktické důsledky jsou zásadní: platformy jako Perplexity a Google Gemini, které aktivně prohledávají živý web, mohou váš obsah citovat okamžitě po publikaci, pokud splňuje jejich kvalitativní a relevantní kritéria. ChatGPT a Claude, které se více spoléhají na tréninková data, mohou vaše originální výzkumy začlenit až s odstupem, ale nabízejí jiné možnosti viditelnosti prostřednictvím pluginů a integrací. Pro tvůrce obsahu to znamená pochopit, jaké platformy využívá vaše cílová skupina, a podle toho svá data optimalizovat—zda zajistit extrahovatelný, dobře strukturovaný obsah pro živé vyhledávání Perplexity, nebo budovat signály autority ovlivňující začlenění do tréninkových dat pro model-native systémy.
Strukturovaná data se vyvinula z příjemného SEO doplňku v strategickou nutnost pro AI viditelnost. Implementací schema markup pomocí slovníku Schema.org nepomáháte jen Googlu rozumět vašemu obsahu—vytváříte strojově čitelnou vrstvu, o kterou se mohou AI systémy spolehlivě opírat při generování odpovědí. Tato vrstva strukturovaných dat, často nazývaná “content knowledge graph”, explicitně definuje entity (osoby, produkty, služby, místa, organizace) a vztahy mezi nimi, což AI systémům dramaticky zjednodušuje pochopení, co je vaše značka, co nabízí a jak by měla být vnímána. Podle nedávného výzkumu BrightEdge měly stránky s robustními strukturovanými daty vyšší míru citací v AI Overviews od Googlu, což naznačuje, že strukturovaná data přímo ovlivňují pravděpodobnost citace. Nově vznikající Model Context Protocol (MCP), který přijaly OpenAI i Google DeepMind, představuje další evoluci—v podstatě funguje jako standardizované API pro propojení AI modelů se strukturovanými datovými zdroji. Implementací schema markup ve velkém podniku vytváříte základ, který snižuje halucinace v AI odpovědích, zlepšuje ukotvení ve faktických informacích a činí vaše data snadněji dohledatelná napříč retrieval systémy. To je zvlášť důležité, protože AI systémy trénované pouze na nestrukturovaném textu často bojují s přesností; strukturovaná data poskytují kontextovou jasnost, díky níž mohou LLM generovat spolehlivější a lépe přiřaditelné odpovědi, které s důvěrou citují váš původní výzkum.

Nejefektivnější strategií pro získání AI citací je vytvářet originální data, která jsou sama o sobě extrahovatelná, autoritativní a v souladu s tím, jak AI systémy vyhledávají a syntetizují informace. Místo pouhého doufání, že bude váš stávající obsah citován, musíte vědomě navrhovat datové produkty, které AI platformy snadno objeví, pochopí a odkážou. Zde jsou klíčové strategie pro tvorbu citacehodných originálních dat:
Provádějte originální výzkum s transparentní metodologií: AI systémy upřednostňují zdroje, které prokazují rigorózní výzkumné postupy. Publikujte studie, průzkumy a analýzy s jasně zdokumentovanými metodikami, velikostmi vzorků a omezeními. Když ukážete, jak jste k výsledkům došli, AI platformy mohou vaše zjištění s jistotou citovat jako autoritativní. Příklady zahrnují odvětvová srovnání, studie chování zákazníků, průzkumy trhu a analýzy vlastních dat, které konkurence nemůže replikovat.
Zajistěte extrahovatelnost dat díky strukturovaným formátům: AI systémy preferují obsah uspořádaný do tabulek, seznamů, srovnávacích matic a FAQ stylu otázka-odpověď před hustými odstavci. Srovnávací tabulka vlastností konkurentů bude pravděpodobněji citována než stejné informace zahrabané v textu. Používejte nadpisy, odrážky a vizuální hierarchie, které umožní AI systémům klíčové poznatky rychle naskenovat a vytěžit.
Zajistěte aktuálnost dat a signály čerstvosti: AI platformy, zejména ty využívající živý web, upřednostňují aktuální informace. Uvádějte viditelná data publikace, časová razítka aktualizací a pravidelně obsah obnovujte. Když prokážete, že vaše data jsou aktuální a udržovaná, AI systémy je považují za spolehlivější než zastaralé zdroje. To je obzvlášť důležité pro časově citlivá data jako ceny, statistiky a tržní trendy.
Vybudujte autoritu autora a značky: AI systémy hodnotí důvěryhodnost zdroje před citací. Vybudujte jasné odborné profily autorů (bio s relevantní expertízou), autoritu organizace (zpětné odkazy, mediální zmínky, uznání v oboru) a signály odbornosti v daném oboru. Když je vaše značka uznávána jako lídr v kategorii, AI systémy vás citují častěji a na významnějších místech.
Používejte jasné definice entit a vztahů: Definujte klíčové entity explicitně—vaši firmu, produkty, služby, členy týmu a pojmy v oboru. Pomocí strukturovaných dat vymezte vztahy mezi těmito entitami. Když AI systém přesně chápe, kdo jste a jak souvisíte s širšími oborovými pojmy, může vás citovat přesněji a kontextuálně.
Dodržujte správné citace a uvádějte zdroje: Pokud vaše originální data navazují na jiné zdroje, transparentně je citujte. AI systémy vnímají a oceňují zdroje, které přiznávají své inspirace. Tím vytváříte řetězec důvěry, který zvyšuje celkovou důvěryhodnost a pravděpodobnost citace v celém ekosystému.
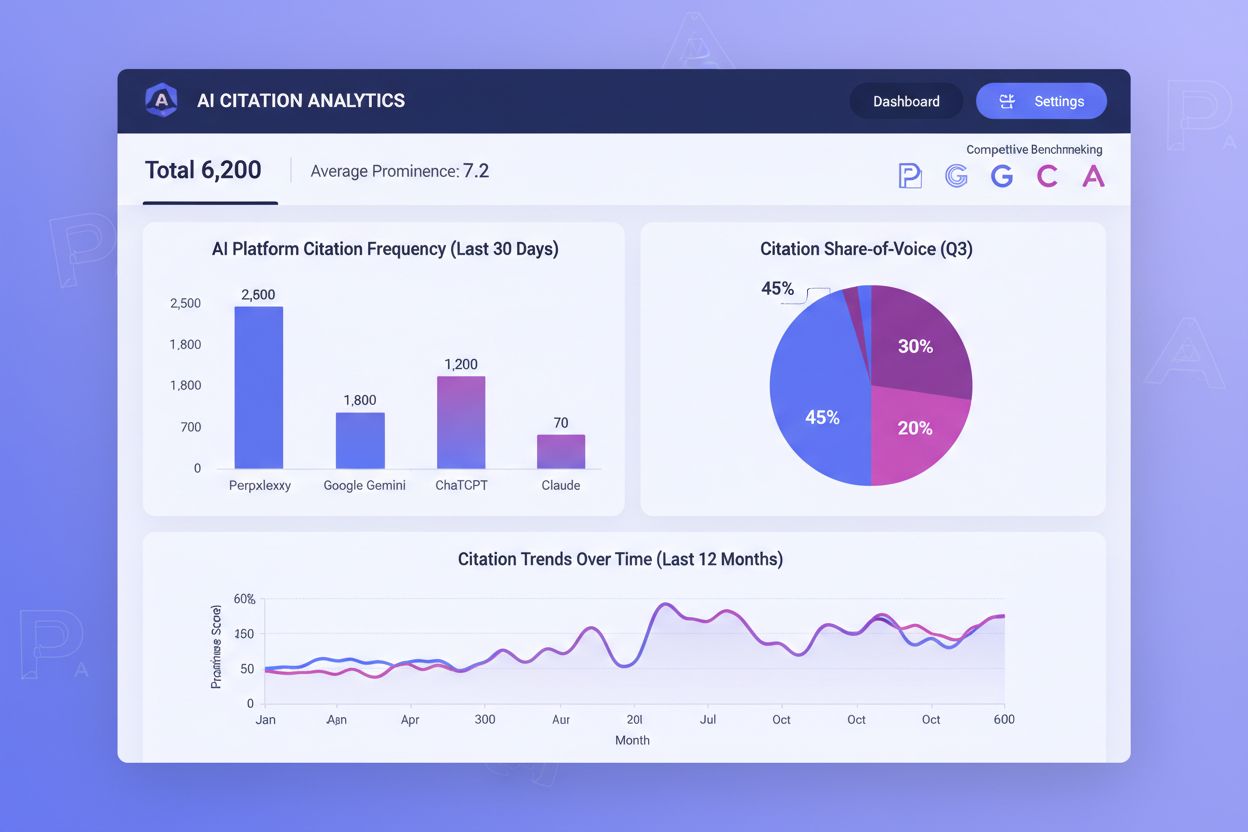
Sledování AI citací je stejně důležité jako monitorování tradičních vyhledávacích pozic, přesto většina organizací nemá přehled o tom, jak často je jejich obsah citován napříč AI platformami. Frekvence citací, významnost citace a share-of-voice jsou tři klíčové metriky, které určují váš úspěch v AI zprostředkovaném objevování. Frekvence citací měří, jak často se váš obsah objevuje v AI odpovědích na vaše cílové dotazy—pokud jste citováni ve 40 % relevantních dotazů a konkurence v 60 %, máte jasný prostor pro optimalizaci. Významnost citace je ještě důležitější: citace na prvním místě v číslovaném seznamu Perplexity přináší nepoměrně vyšší viditelnost než na pátém místě. Share-of-voice ukazuje vaši konkurenční pozici—pokud vaše značka získává citace ve 25 % klíčových dotazů a vaše hlavní konkurence v 50 %, přicházíte o zásadní viditelnost.
Nástroje jako AmICited.com se stávají nezbytným řešením pro monitoring AI citací napříč platformami. Tyto platformy sledují, které vaše stránky získávají citace v Perplexity, Google AI Overviews, ChatGPT s vyhledáváním a dalších AI systémech, a odhalují, který obsah skutečně zvyšuje AI viditelnost. Sledováním vzorů citací v čase zjistíte, které typy, témata a formáty obsahu generují nejvíce citací a můžete tyto úspěšné strategie opakovat. Konkurenční srovnání v těchto nástrojích přesně ukazuje, kde ztrácíte citace vůči konkurenci, a umožňuje cílenou optimalizaci. Data odhalí, zda jsou vaše potíže s citacemi univerzální napříč AI platformami nebo specifické pro některé systémy—pokud jste často citováni v Perplexity, ale zřídka v Google AI Overviews, vaše optimalizační strategie by tomu měla odpovídat. Metriky zohledňující pozici chápou, že první citace mají nepoměrně vyšší hodnotu; nástroj, který váží citace na prvních pozicích silněji než ty na nižších, poskytuje praktičtější podněty než prostý počet citací. Pokud budete sledování AI citací brát jako klíčovou součást své obsahové strategie, můžete neustále optimalizovat originální data pro zvýšení frekvence i významnosti citací a přímo tak zlepšovat svou viditelnost v AI řízeném vyhledávání.
Tvorba originálních dat, která získávají AI citace, nemůže být jednorázovým projektem—vyžaduje vybudování udržitelné, mezioborové datové strategie, která považuje data za strategické aktivum hodné trvalé investice a správy. Organizace, které v AI viditelnosti uspějí, zavádějí strukturované procesy pro průběžné aktualizace dat, aby jejich originální výzkum zůstal aktuální a relevantní. To znamená zavést pravidelné cykly obnovy klíčových datasetů, aktualizovat statistiky při vzniku nových informací a udržovat signály čerstvosti, podle kterých AI systémy hodnotí důvěryhodnost zdroje. Kromě aktualizací obsahu úspěšné organizace slaďují datovou strategii napříč marketingem, SEO, obsahem, produktem i datovými týmy prostřednictvím správy entit—společných definic a taxonomií, které zajišťují konzistentní, přesné zastoupení vaší značky, produktů a oborových pojmů ve všech kontaktních bodech.
Nejsofistikovanější přístup chápe strukturovaná data a content knowledge graphs jako celopodnikovou infrastrukturu. Místo implementace schema markup stránku po stránce vedoucí organizace budují komplexní content knowledge graphs, které propojují všechny entity, témata a vztahy napříč digitálními kanály. To vyžaduje technické možnosti—nástroje a procesy pro správu schema markup ve velkém—a organizační sladění ohledně standardů kvality dat. Při správném nastavení tato infrastruktura slouží dvojímu účelu: zlepšuje vnější AI viditelnost a zároveň umožňuje interní AI iniciativy. Podle průzkumu Gartner’s 2024 AI Mandates for the Enterprise představuje dostupnost a kvalita dat hlavní překážku úspěšné implementace AI; investicí do strukturovaných dat a správy entit zároveň řešíte externí výzvy viditelnosti i interní AI rozvoj. Organizace, které v AI viditelnosti vítězí, chápou tvorbu originálních dat nikoli jako marketingovou taktiku, ale jako základní podnikový proces s vyhrazenými zdroji, jasnou zodpovědností a průběžnou optimalizací na základě sledování citací a konkurenčního srovnání.
Originální data znamenají vlastní výzkum, jedinečné datové sady a primární zjištění, která jste vytvořili nebo objevili sami. AI systémy upřednostňují originální data, protože poskytují autoritativní, extrahovatelné informace, které mohou s jistotou citovat. Běžný obsah často pouze syntetizuje existující informace, což snižuje jeho hodnotu pro AI citace. Originální data se stávají základem pro AI viditelnost, protože platformy jako Perplexity a Google Gemini aktivně vyhledávají a citují zdroje, které přinášejí jedinečné poznatky a výzkum.
Různé AI platformy využívají různé mechanismy objevování. Perplexity a Google Gemini používají retrieval-augmented generation (RAG), což znamená, že prohledávají živý web a mohou váš obsah citovat ihned po publikaci. ChatGPT a Claude se více spoléhají na tréninková data, takže začlenění vašeho obsahu může trvat déle, ale nabízí jiné možnosti viditelnosti. Všechny platformy těží ze strukturovaných dat (schema markup), která činí vaše data strojově čitelnými a snadněji pochopitelnými, což zvyšuje pravděpodobnost citace napříč všemi systémy.
Strukturovaná data využívající slovník Schema.org vytvářejí strojově čitelnou vrstvu, o kterou se AI systémy mohou spolehlivě opírat. Implementací schema markup jasně definujete entity (vaši firmu, produkty, služby) a jejich vztahy, což AI systémům výrazně usnadňuje pochopení a přesné citování vašeho obsahu. Výzkumy ukazují, že stránky s robustními strukturovanými daty získávají více citací v AI Overviews. Strukturovaná data také snižují halucinace tím, že AI systémům poskytují jasné, faktické informace pro odkazování.
AI systémy nejčastěji citují originální výzkum s transparentní metodikou, vlastní datové sady, odvětvová měřítka, studie chování zákazníků, analýzy trhu a jedinečné poznatky, které konkurence nemůže replikovat. Data prezentovaná v extrahovatelných formátech—tabulky, srovnávací matice, seznamy a FAQ styl otázka-odpověď—získávají více citací než stejná informace v hustých odstavcích. Přednost mají čerstvá, aktuální data s viditelným datem publikace a pravidelnými aktualizacemi před zastaralými informacemi. Signály autority jako odborná kvalifikace autora a uznání organizace také zvyšují pravděpodobnost citace.
Nástroje jako AmICited.com sledují AI citace napříč platformami a ukazují, jak často se váš obsah objevuje v odpovědích ChatGPT, Perplexity, Google AI Overviews a Claude. Tyto nástroje měří frekvenci citací (jak často jste citováni), význam citace (pozice v odpovědi) a share-of-voice (vaše citace ve srovnání s konkurencí). Monitorováním těchto metrik zjistíte, které typy obsahu a témata generují nejvíce citací, a podle toho optimalizujete svou datovou strategii. Metriky zohledňující pozici uznávají, že citace na prvním místě mají větší hodnotu než na nižších pozicích.
Frekvence citací měří, jak často je váš obsah citován v AI odpovědích na vaše cílové dotazy—pokud jste citováni ve 40 % relevantních dotazů, to je vaše frekvence citací. Významnost citace měří, kde se vaše citace v odpovědi objevuje—citace na prvním místě v číslovaném seznamu Perplexity přináší mnohem větší viditelnost než na pátém místě. Obě metriky jsou důležité pro AI viditelnost, ale významnost často převládá, protože uživatelé spíše kliknou nebo reagují na časné citace. Efektivní optimalizace vyžaduje zlepšování obou metrik současně.
Originální data by měla být aktualizována pravidelně podle rychlosti změn ve vašem odvětví. Pro rychle se vyvíjející obory jako technologie či finance mohou být nutné měsíční nebo čtvrtletní aktualizace. Ve stabilnějších odvětvích stačí aktualizace roční. Klíčové je udržovat viditelné signály aktuálnosti—data publikace, časová razítka aktualizací a indikátory obnovení—které AI systémům signalizují, že jsou vaše data aktuální a spolehlivá. Pravidelné aktualizace také zvyšují šanci na citování retrieval-based systémy jako Perplexity, které upřednostňují čerstvé informace. Údržbu dat berte jako průběžnou operativní činnost, nikoli jednorázový projekt.
Ano, AmICited.com obsahuje funkce pro srovnání s konkurencí, které ukazují vaše výsledky citací ve vztahu k definovaným konkurentům. Zjistíte, kteří konkurenti jsou citováni častěji, na významnějších pozicích a na kterých AI platformách. Tato konkurenční inteligence přesně odhalí, kde ztrácíte citace, a pomůže určit optimalizační strategie pro získání náskoku. Díky znalosti konkurenčního prostředí můžete soustředit tvorbu a optimalizaci dat na nejefektivnější příležitosti, aby vaše originální data získala zaslouženou viditelnost.
Sledujte, jak často jsou vaše originální data citována v ChatGPT, Perplexity, Google AI Overviews a dalších AI platformách. Získejte praktické poznatky pro optimalizaci obsahu na maximální AI viditelnost.
Zjistěte, proč je tvorba originálního výzkumu zásadní pro viditelnost v AI. Naučte se, jak originální výzkum pomáhá vaší značce být citována v AI odpovědích a z...

Zjistěte, jaké zásadní dovednosti potřebují specialisté na AI viditelnost: technické znalosti, obsahová strategie, datová analýza a neustálé vzdělávání. Ovládně...
Objevte 4 zásadní metriky AI viditelnosti, na kterých záleží zainteresovaným stranám: Signal Rate, Přesnost, Citace a Podíl hlasu. Naučte se měřit a reportovat ...