
Co je meta tag noai a jak chrání váš obsah před AI?
Zjistěte, co je meta tag noai, jak funguje při prevenci sběru dat pro AI trénink, jaká má omezení a jak jej implementovat na svůj web pro ochranu obsahu před ge...
6 min čtení

Naučte se, jak implementovat meta tagy noai a noimageai pro kontrolu přístupu AI crawlerů k obsahu vašeho webu. Kompletní průvodce hlavičkami pro kontrolu přístupu AI a způsoby implementace.
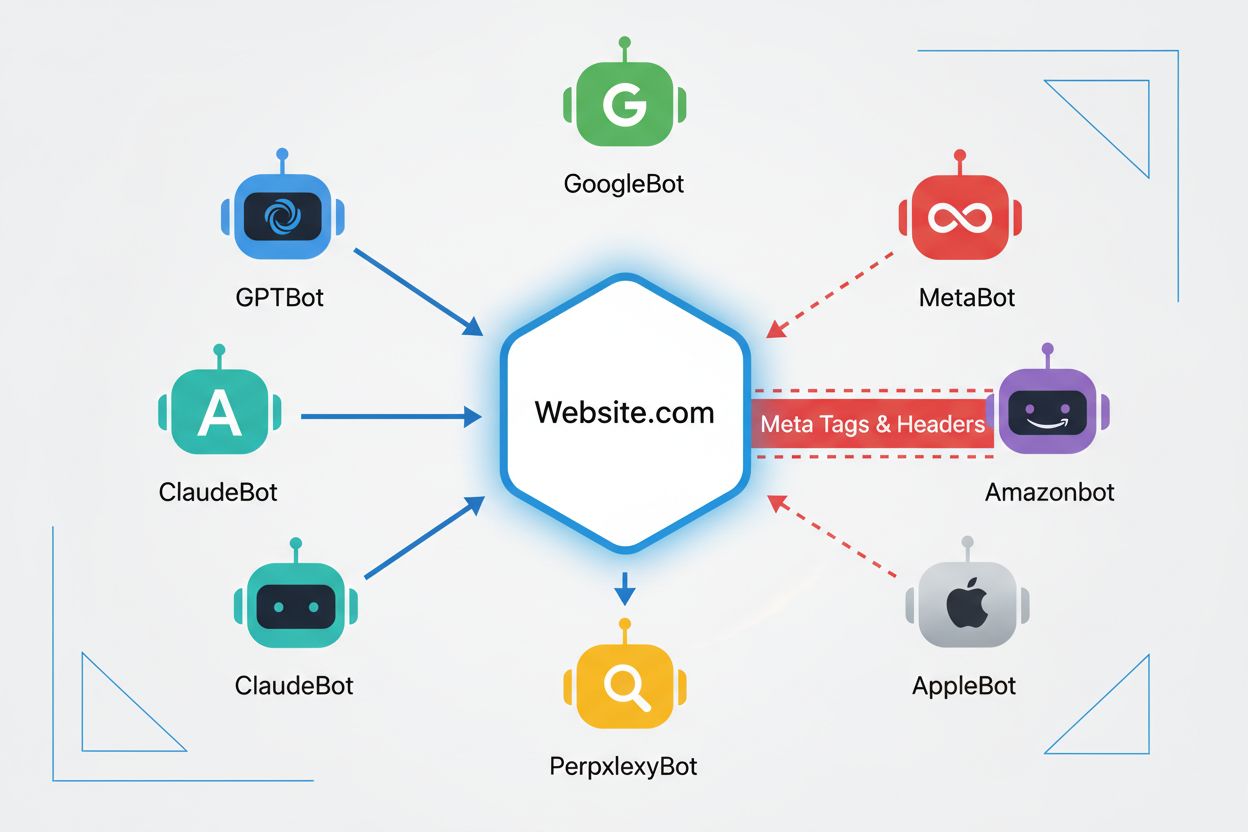
Web crawleři jsou automatizované programy, které systematicky procházejí internet a sbírají informace z webových stránek. Historicky tyto boty provozovaly především vyhledávače jako Google, jejichž Googlebot procházel stránky, indexoval obsah a posílal uživatele zpět na weby skrze výsledky vyhledávání – šlo o vzájemně výhodný vztah. S nástupem AI crawlerů se však tato dynamika zásadně změnila. Na rozdíl od tradičních vyhledávacích botů, kteří za přístup k obsahu poskytují odkazovaný provoz, AI tréninkové crawlery spotřebovávají obrovské množství webového obsahu pro tvorbu datasetů velkých jazykových modelů, přičemž často vracejí vydavatelům minimální nebo nulovou návštěvnost. Tento posun učinil meta tagy – malé HTML instrukce, které sdělují crawlerům pokyny – čím dál důležitější pro tvůrce, kteří chtějí mít kontrolu nad tím, jak jejich práce využívají systémy umělé inteligence.
noai a noimageai meta tagy jsou direktivy, které v roce 2022 vytvořil DeviantArt, aby pomohl tvůrcům zabránit použití jejich díla k trénování AI generátorů obrázků. Tyto tagy fungují podobně jako dlouhodobě zavedená direktiva noindex, která říká vyhledávačům, aby stránku neindexovaly. noai značí, že žádný obsah na stránce nemá být použit pro trénink AI, zatímco noimageai konkrétně brání použití obrázků pro trénink AI modelů. Tagy lze implementovat do sekce head vašeho HTML takto:
<!-- Blokuje veškerý obsah před tréninkem AI -->
<meta name="robots" content="noai">
<!-- Blokuje pouze obrázky před tréninkem AI -->
<meta name="robots" content="noimageai">
<!-- Blokuje obsah i obrázky -->
<meta name="robots" content="noai, noimageai">
Zde je srovnávací tabulka různých meta tag direktiv a jejich účelů:
| Direktiva | Účel | Syntaxe | Rozsah |
|---|---|---|---|
| noai | Zabraňuje použití veškerého obsahu pro trénink AI | content="noai" | Celý obsah stránky |
| noimageai | Zabraňuje použití obrázků pro trénink AI | content="noimageai" | Pouze obrázky |
| noindex | Zabraňuje indexaci vyhledávači | content="noindex" | Výsledky hledání |
| nofollow | Zabraňuje sledování odkazů | content="nofollow" | Odchozí odkazy |
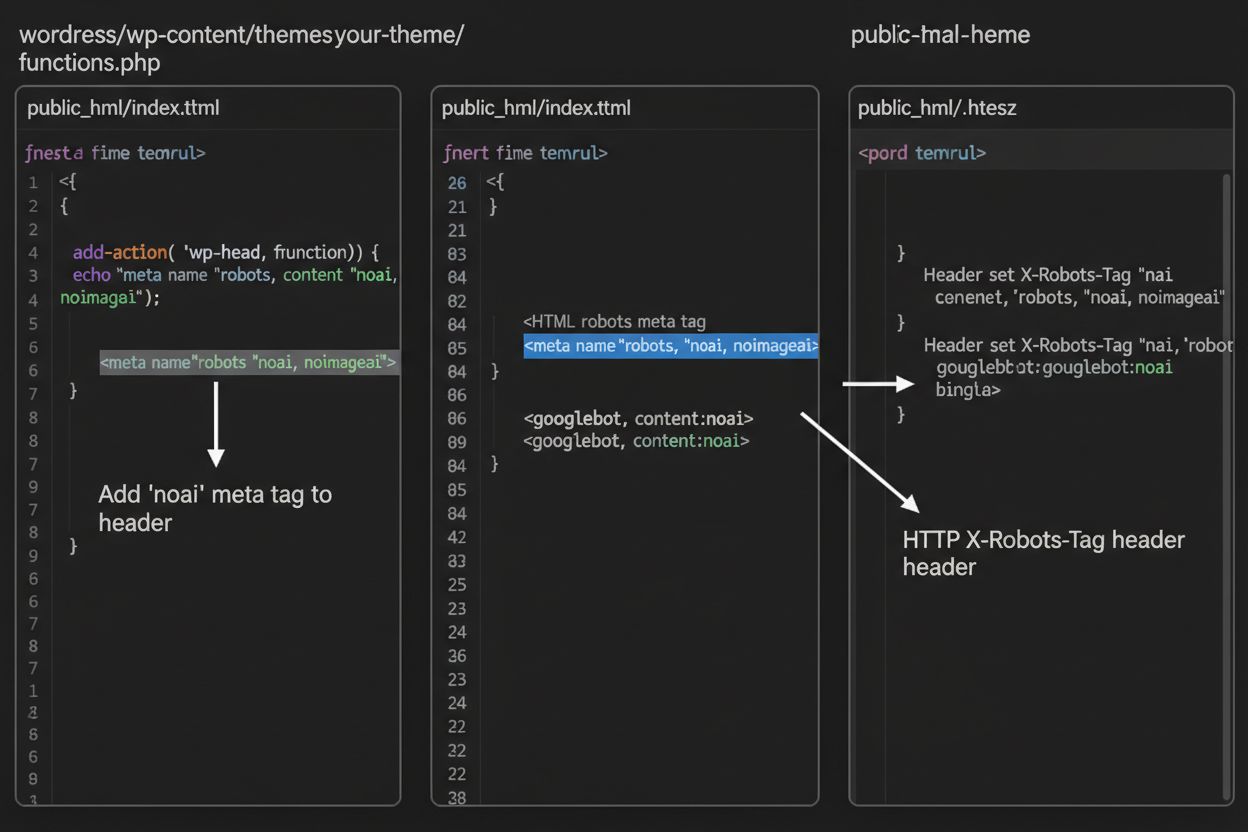
Zatímco meta tagy vkládáte přímo do HTML, HTTP hlavičky umožňují sdělit crawlerům pokyny na úrovni serveru. Hlavička X-Robots-Tag může obsahovat stejné instrukce jako meta tagy, ale funguje odlišně – je odeslána v HTTP odpovědi ještě před doručením obsahu stránky. Tento způsob je zvláště cenný pro kontrolu přístupu k ne-HTML souborům, jako jsou PDF, obrázky a videa, kam nelze HTML meta tagy vložit.
Na Apache serverech nastavíte X-Robots-Tag v souboru .htaccess:
<IfModule mod_headers.c>
Header set X-Robots-Tag "noai, noimageai"
</IfModule>
Na serverech NGINX přidejte hlavičku do konfigurace serveru:
location / {
add_header X-Robots-Tag "noai, noimageai";
}
Hlavičky poskytují globální ochranu napříč celým webem či konkrétními složkami, což je činí ideálními pro komplexní strategii kontroly přístupu AI.
Účinnost noai a noimageai tagů zcela závisí na tom, zda je crawlery respektují. Slušně se chovající crawlery od hlavních AI společností obvykle tyto direktivy dodržují:
Na druhou stranu špatně se chovající boty a škodlivé crawlery mohou tyto direktivy úmyslně ignorovat, protože neexistuje žádný vynucovací mechanismus. Na rozdíl od robots.txt, který vyhledávače uznávají jako průmyslový standard, není noai oficiálním webovým standardem, takže crawlery nejsou povinny se jím řídit. Proto odborníci na bezpečnost doporučují vícestupňový přístup, který kombinuje více metod ochrany, místo spoléhání pouze na meta tagy.
Implementace noai a noimageai tagů se liší podle vašeho webového systému. Zde jsou kroky pro nejběžnější platformy:
1. WordPress (přes functions.php) Přidejte tento kód do souboru functions.php vašeho dětského motivu:
function add_noai_meta_tag() {
echo '<meta name="robots" content="noai, noimageai">' . "\n";
}
add_action('wp_head', 'add_noai_meta_tag');
2. Statické HTML stránky
Přidejte přímo do sekce <head> vašeho HTML:
<head>
<meta name="robots" content="noai, noimageai">
</head>
3. Squarespace Přejděte na Nastavení > Pokročilé > Vložení kódu a vložte do sekce Hlavička:
<meta name="robots" content="noai, noimageai">
4. Wix Jděte do Nastavení > Vlastní kód, klikněte na „Přidat vlastní kód“, vložte meta tag, vyberte „Head“ a použijte na všechny stránky.
Každá platforma nabízí jinou úroveň kontroly – WordPress umožňuje implementaci na úrovni stránky přes pluginy, Squarespace a Wix poskytují globální možnosti pro celý web. Zvolte metodu, která odpovídá vašim technickým schopnostem a konkrétním potřebám.
Ačkoliv noai a noimageai tagy představují důležitý krok k ochraně tvůrců, mají významná omezení. Především nejde o oficiální webové standardy – vytvořil je DeviantArt jako komunitní iniciativu bez formální specifikace či vynucování. Dále dodržování je zcela dobrovolné. Slušně se chovající crawlery od velkých firem je respektují, ale špatně se chovající boty a scrapery je mohou bez následků ignorovat. Kvůli absenci standardizace se jejich používání liší – některé menší AI firmy a výzkumné organizace o těchto direktivách nemusí vůbec vědět, natož je podporovat. Nakonec meta tagy samy o sobě neochrání před odhodlanými útočníky – škodlivý crawler může vaše pokyny zcela obejít, proto jsou další vrstvy ochrany nezbytné pro skutečně bezpečný obsah.
Nejúčinnější strategie kontroly přístupu AI využívá více vrstev ochrany místo spoléhání na jedinou metodu. Srovnání různých přístupů:
| Metoda | Rozsah | Účinnost | Obtížnost |
|---|---|---|---|
| Meta tagy (noai) | Na úrovni stránky | Střední (dobrovolné dodržení) | Snadná |
| robots.txt | Celý web | Střední (jen doporučení) | Snadná |
| X-Robots-Tag hlavičky | Serverová úroveň | Středně vysoká (platí pro všechny typy souborů) | Střední |
| Pravidla firewallu | Síťová úroveň | Vysoká (blokace na infrastruktuře) | Obtížná |
| Povolení podle IP adres | Síťová úroveň | Velmi vysoká (jen ověření zdroje) | Obtížná |
Komplexní strategie může zahrnovat: (1) implementaci noai meta tagů na všechny stránky, (2) přidání pravidel do robots.txt blokujících známé AI tréninkové crawlery, (3) nastavení X-Robots-Tag hlaviček na úrovni serveru pro ne-HTML soubory a (4) monitorování serverových logů k identifikaci crawlerů, kteří vaše pokyny ignorují. Tento vícestupňový přístup výrazně ztěžuje práci útočníkům a zároveň zachovává kompatibilitu se slušně se chovajícími crawlery.
Po implementaci noai tagů a dalších direktiv byste měli ověřit, zda crawlery vaše pravidla skutečně respektují. Nejjednodušší je kontrola serverových přístupových logů na aktivitu crawlerů. Na serverech Apache můžete hledat konkrétní crawlery:
grep "GPTBot\|ClaudeBot\|PerplexityBot" /var/log/apache2/access.log
Pokud vidíte požadavky od crawlerů, které jste zablokovali, znamená to, že vaše direktivy ignorují. Na serverech NGINX zkontrolujte /var/log/nginx/access.log stejným příkazem grep. Dále nástroje jako Cloudflare Radar poskytují přehled o provozu AI crawlerů na vašem webu, zobrazují nejaktivnější boty a změny jejich chování v čase. Pravidelné sledování logů – alespoň měsíčně – vám pomůže odhalit nové crawlery a ověřit, že vaše opatření fungují dle očekávání.
V současnosti existují noai a noimageai v šedé zóně: jsou široce uznávány a respektovány hlavními AI společnostmi, ale zůstávají neoficiální a nestandardizované. Nicméně roste tlak na formální standardizaci. W3C (World Wide Web Consortium) a různé průmyslové skupiny diskutují, jak vytvořit oficiální standardy pro kontrolu přístupu AI, které by těmto direktivám daly váhu podobnou zavedeným standardům jako robots.txt. Pokud se noai stane oficiálním webovým standardem, bude jeho dodržování očekávanou praxí a jeho účinnost výrazně vzroste. Tento posun vnímání odráží širší změnu v přístupu technologického průmyslu k právům tvůrců obsahu a rovnováze mezi rozvojem AI a ochranou vydavatelů. S rostoucím počtem vydavatelů, kteří tyto tagy přijímají a žádají silnější ochranu, pravděpodobnost oficiální standardizace roste, což by mohlo kontrolu přístupu AI učinit stejně zásadní pro správu webu jako pravidla indexace vyhledávači.
Noai meta tag je direktiva umístěná v sekci head vašeho HTML, která signalizuje AI crawlerům, že váš obsah nemá být použit pro trénink modelů umělé inteligence. Funguje tak, že sděluje vaše preference slušně se chovajícím AI botům, nicméně nejde o oficiální webový standard a někteří crawlery jej mohou ignorovat.
Ne, noai a noimageai nejsou oficiální webové standardy. Vznikly na DeviantArt jako komunitní iniciativa, která má pomoci tvůrcům chránit jejich tvorbu před tréninkem AI. Nicméně velké AI společnosti jako OpenAI, Anthropic a další začaly tyto direktivy ve svých crawlerech respektovat.
Hlavní AI crawlery včetně GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) a další respektují direktivu noai. Některé menší nebo hůře se chovající crawlery ji však mohou ignorovat, proto se doporučuje vícestupňová ochrana.
Meta tagy se vkládají do sekce head vašeho HTML a platí pro jednotlivé stránky, zatímco HTTP hlavičky (X-Robots-Tag) se nastavují na úrovni serveru a lze je použít globálně nebo pro konkrétní typy souborů. Hlavičky fungují i pro ne-HTML soubory jako PDF a obrázky, takže jsou univerzálnější pro komplexní ochranu.
Ano, noai tagy lze na WordPressu implementovat několika způsoby: přidáním kódu do souboru functions.php vašeho motivu, použitím pluginu jako WPCode nebo pomocí nástrojů na stavbu stránek jako Divi a Elementor. Nejčastější je metoda přes functions.php, kdy vložíte jednoduchý hook pro vložení meta tagu do hlavičky webu.
To záleží na vašich obchodních cílech. Blokování tréninkových crawlerů chrání váš obsah před použitím v tréninku AI modelů. Blokováním vyhledávacích crawlerů, jako je OAI-SearchBot, však můžete snížit svou viditelnost ve výsledcích vyhledávání poháněných AI a na objevovacích platformách. Mnozí vydavatelé volí selektivní přístup – blokují tréninkové crawlery, ale povolují vyhledávací.
Můžete zkontrolovat serverové logy na aktivitu crawlerů pomocí příkazů jako grep pro hledání konkrétních user agentů botů. Nástroje jako Cloudflare Radar poskytují přehled o provozu AI crawlerů. Pravidelně sledujte logy, zda blokované crawlery stále přistupují k vašemu obsahu – to značí, že vaše direktivy ignorují.
Pokud crawlery ignorují vaše meta tagy, použijte další vrstvy ochrany jako pravidla robots.txt, HTTP hlavičky X-Robots-Tag a blokování na úrovni serveru přes .htaccess nebo firewall. Pro silnější ověření použijte povolování přístupu podle IP adres – povolte požadavky pouze z ověřených IP adres zveřejněných hlavními AI společnostmi.
Použijte AmICited k sledování, jak systémy AI jako ChatGPT, Perplexity a Google AI Overviews citují a zmiňují váš obsah napříč různými AI platformami.
Zjistěte, co je meta tag noai, jak funguje při prevenci sběru dat pro AI trénink, jaká má omezení a jak jej implementovat na svůj web pro ochranu obsahu před ge...

Zjistěte, co jsou NoAI meta tagy, jak fungují při ochraně před AI scrapingem, jak je implementovat a jak účinně chrání váš obsah před neoprávněným použitím k tr...

Pochopte, jak fungují AI crawleři jako GPTBot a ClaudeBot, v čem se liší od tradičních crawlerů vyhledávačů a jak optimalizovat svůj web pro viditelnost ve vyhl...