
Token
Zjistěte, co jsou tokeny v jazykových modelech. Tokeny jsou základní jednotky zpracování textu v AI systémech, představující slova, podslova nebo znaky jako čís...
10 min čtení

Zjistěte, jak limity tokenů ovlivňují výkon AI a objevte praktické strategie pro optimalizaci obsahu včetně RAG, chunkingu a sumarizačních technik.
Tokeny jsou základní stavební kameny, které AI modely používají ke zpracování a porozumění informacím. Namísto práce s celými slovy nebo větami rozkládají velké jazykové modely text na menší jednotky zvané tokeny, které mohou být jednotlivými znaky, částmi slov nebo celými slovy v závislosti na tokenizačním algoritmu. Každému tokenu je přiřazen jedinečný číselný identifikátor, který model používá interně pro výpočty. Tento proces tokenizace je zásadní, protože umožňuje AI systémům efektivně zpracovávat vstupy různé délky a udržovat konzistentní zpracování napříč různými typy obsahu. Pochopení tokenů je nezbytné pro každého, kdo s AI systémy pracuje, protože přímo ovlivňují výkon, náklady a kvalitu výsledků, kterých můžete dosáhnout.
Různé AI modely mají velmi odlišné limity tokenů, které určují maximální množství informací, které mohou zpracovat v rámci jednoho požadavku. Tyto limity se v posledních letech dramaticky vyvíjely a novější modely podporují výrazně větší kontextová okna. Limit tokenů zahrnuje jak vstupní tokeny (váš prompt a data), tak výstupní tokeny (odpověď modelu), což vytváří společný rozpočet, který je třeba pečlivě řídit. Porozumění těmto limitům je klíčové pro výběr správného modelu pro váš případ použití a odpovídající plánování architektury vaší aplikace.
| Model | Limit tokenů | Hlavní využití | Cenová úroveň |
|---|---|---|---|
| GPT-3.5 Turbo | 4 096 | Krátké konverzace, rychlé úkoly | Nízká |
| GPT-4 | 8 192 | Standardní aplikace, střední složitost | Střední |
| GPT-4 Turbo | 128 000 | Dlouhé dokumenty, komplexní analýzy | Vysoká |
| Claude 3.5 Sonnet | 200 000 | Rozsáhlé dokumenty, komplexní analýzy | Vysoká |
| Gemini 1.5 Pro | 1 000 000 | Obrovské datasety, celé knihy, analýza videa | Velmi vysoká |
Klíčová hlediska při hodnocení limitů tokenů:
Limity tokenů vytvářejí významná omezení, která přímo ovlivňují přesnost, spolehlivost a nákladovou efektivitu AI aplikací. Pokud překročíte limit tokenů modelu, aplikace zcela selže — nedojde k žádné elegantní degradaci nebo částečnému zpracování. I při dodržení limitů mohou naivní přístupy, jako je prosté zkracování, vážně snížit výkon odstraněním klíčového kontextu, který model potřebuje pro generování přesných odpovědí. To je obzvlášť problematické v oblastech jako právní analýza, lékařský výzkum nebo softwarové inženýrství, kde může i jediný opomenutý detail vést k chybným závěrům. Výzvou je i to, že různé typy obsahu spotřebovávají tokeny různou rychlostí — strukturovaná data jako kód nebo JSON vyžadují výrazně více tokenů než běžný anglický text kvůli symbolům a formátování.
Zkracování je nejjednodušší metoda pro zvládání limitů tokenů — jednoduše oříznete přebytečný obsah, když překročí kapacitu modelu. I když je toto řešení snadné na implementaci, nese s sebou významná rizika. Při zkracování textu nevyhnutelně přicházíte o informace a model nemá žádný způsob, jak zjistit, co bylo odstraněno. To může vést k neúplné analýze, opomenutí kontextu a halucinacím, kdy model generuje věrohodně znějící, ale nesprávné informace, aby zaplnil mezery ve svém porozumění.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
Sofistikovanější strategie zkracování rozlišuje mezi zásadním a volitelným obsahem. Můžete upřednostnit nezbytné prvky, jako je aktuální dotaz uživatele a klíčové instrukce, a volitelný kontext, například historii konverzace, přidat jen tehdy, pokud to prostor dovolí. Tento přístup zachovává klíčové informace a zároveň respektuje limity tokenů.
Namísto zkracování rozděluje chunking váš obsah na menší, zvládnutelné části, které lze zpracovat samostatně nebo selektivně. Chunking s pevnou velikostí dělí text na stejně velké segmenty, zatímco sémantický chunking používá embeddingy k určení přirozených zlomů na základě významu místo libovolného počtu tokenů. Posuvná okna s překryvem zachovávají kontext mezi chunkami a zajišťují, že důležité informace přesahující hranice chunků nejsou ztraceny.
Hierarchický chunking vytváří více úrovní abstrakce — jednotlivé odstavce na nejnižší úrovni, sekce na další a kapitoly na nejvyšší úrovni. Tento přístup umožňuje sofistikované strategie vyhledávání, kdy můžete rychle identifikovat relevantní části bez nutnosti zpracovávat celý dokument. Ve spojení s vektorovými databázemi a sémantickým vyhledáváním se chunking stává mocným nástrojem pro správu rozsáhlých znalostních bází při zachování relevance a přesnosti.
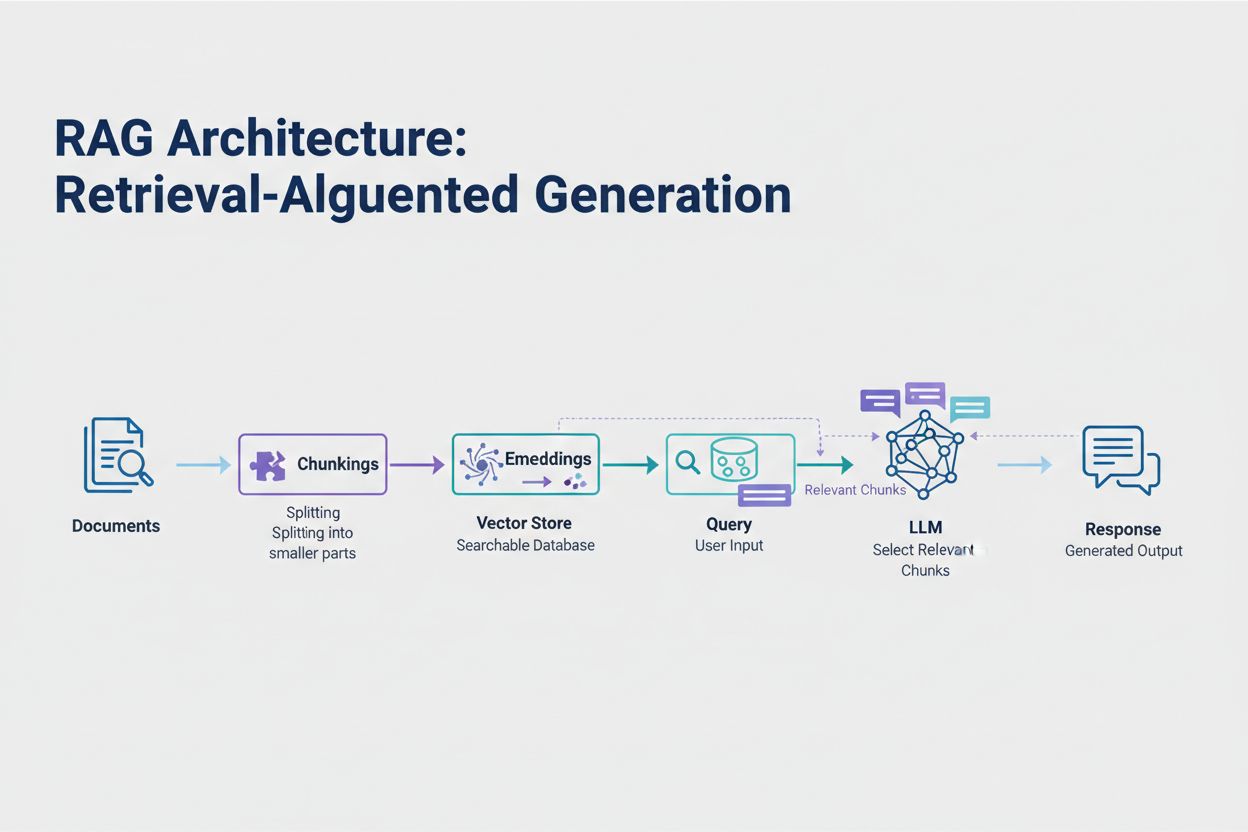
Retrieval-Augmented Generation (RAG) představuje nejúčinnější moderní přístup k řešení limitů tokenů. Místo snahy vměstnat všechna data do kontextového okna modelu RAG získává pouze nejrelevantnější informace v době dotazu. Proces začíná převodem vašich dokumentů na embeddingy — číselné reprezentace zachycující sémantický význam. Tyto embeddingy jsou uloženy ve vektorové databázi, což umožňuje rychlé vyhledávání podle podobnosti.
Když uživatel zadá dotaz, systém embeddinguje dotaz a vyhledá nejrelevantnější části dokumentu z vektorového úložiště. Do promptu je vloženo pouze těchto několik relevantních částí spolu s otázkou uživatele, což dramaticky snižuje spotřebu tokenů a zároveň zvyšuje přesnost. Například při analýze 100stránkové právní smlouvy s RAG může stačit vložit do promptu jen 3–5 klíčových ustanovení, zatímco bez RAG by bylo nutné použít tisíce tokenů pro celý dokument.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
Sumarizace zhušťuje dlouhý obsah při zachování klíčových informací a efektivně snižuje spotřebu tokenů. Extraktivní sumarizace vybírá klíčové věty z původního textu, zatímco abstraktivní sumarizace generuje nový, stručný text, který vystihuje hlavní myšlenky. Hierarchická sumarizace vytváří několik úrovní shrnutí — nejprve sumarizuje jednotlivé sekce, poté tato shrnutí kombinuje do vyšších přehledů. Tento přístup je obzvlášť vhodný pro strukturované dokumenty, jako jsou vědecké práce nebo technické zprávy.
Komprese kontextu přistupuje k problému jinak — odstraňuje redundanci a prázdný obsah při zachování původního znění. Přístupy založené na znalostních grafech extrahují entity a vztahy z textu a poté rekonstruují kontext pouze s nejrelevantnějšími fakty. Tyto techniky dosahují snížení tokenů o 40–60 % při zachování sémantické přesnosti, což je cenné pro optimalizaci nákladů v produkčních systémech.
Správa tokenů přímo ovlivňuje náklady vaší AI aplikace. Každý token spotřebovaný během inference je zpoplatněn a náklady rostou lineárně s jejich využitím. Monitorování spotřeby tokenů je zásadní pro pochopení vaší nákladové struktury a identifikaci možností optimalizace. Mnoho AI platforem nyní nabízí nástroje na počítání tokenů a dashboardy v reálném čase, které sledují využití a pomáhají vám odhalit, které dotazy či funkce spotřebovávají nejvíce tokenů.
Efektivní monitoring odhalí příležitosti pro optimalizaci — například určité typy dotazů pravidelně překračují limity tokenů nebo některé funkce spotřebovávají neúměrné množství prostředků. Sledováním těchto vzorců můžete učinit informované rozhodnutí, jakou optimalizační strategii zvolit. Některé aplikace těží z přesměrování velkých požadavků na výkonnější (ale dražší) modely, jiné více z implementace RAG nebo sumarizace. Klíčem je měřit skutečný výkon a náklady, abyste ověřili správnost svých optimalizačních rozhodnutí.
Volba správné strategie správy tokenů závisí na vašem konkrétním případu použití, požadavcích na výkon a rozpočtových omezeních. Aplikace vyžadující vysokou přesnost s doloženými odpověďmi nejvíce těží z RAG, který zachovává věrnost informací a zároveň řídí spotřebu tokenů. Dlouhodobé konverzační aplikace těží z technik bufferování paměti, které sumarizují historii konverzace a přitom si uchovávají klíčová rozhodnutí a kontext. Aplikace pracující s rozsáhlými dokumenty, jako je právní analýza či výzkumné nástroje, často těží z hierarchické sumarizace v kombinaci se sémantickým chunkingem.
Testování a ověření jsou klíčové před nasazením jakékoli strategie správy tokenů do produkce. Vytvářejte testovací případy, které překračují limity tokenů modelu, a poté vyhodnoťte, jak různé strategie ovlivňují přesnost, latenci a náklady. Měřte metriky jako relevance odpovědí, faktická přesnost a efektivita využití tokenů, abyste zajistili, že zvolený přístup splní vaše požadavky. Běžné chyby zahrnují příliš agresivní sumarizaci vedoucí ke ztrátě klíčových detailů, vyhledávací systémy opomíjející relevantní informace a chunking, který rozděluje obsah v semanticky nevhodných místech.
Limity tokenů se nadále rozšiřují s tím, jak jsou modely stále sofistikovanější a efektivnější. Nové techniky jako sparse attention mechanismy a efektivní transformery slibují snížení výpočetních nákladů na zpracování velkých kontextových oken. Multimodální modely, které zpracovávají text, obrázky, zvuk i video současně, přinášejí nové výzvy i příležitosti pro tokenizaci. Reasoning tokeny — speciální tokeny používané modely k „uvažování“ nad složitými problémy — představují novou kategorii spotřeby tokenů, která umožňuje sofistikovanější řešení, ale vyžaduje pečlivou správu.
Směr je jasný: jak se kontextová okna rozšiřují a zpracování tokenů je efektivnější, úzké hrdlo se přesouvá od samotné kapacity ke schopnosti inteligentního výběru obsahu. Budoucnost patří systémům, které dokážou efektivně identifikovat a získávat nejrelevantnější informace z obrovských znalostních bází, místo pouhého zpracování většího objemu dat. To činí techniky jako RAG a sémantické vyhledávání stále důležitějšími pro vytváření škálovatelných a nákladově efektivních AI aplikací.
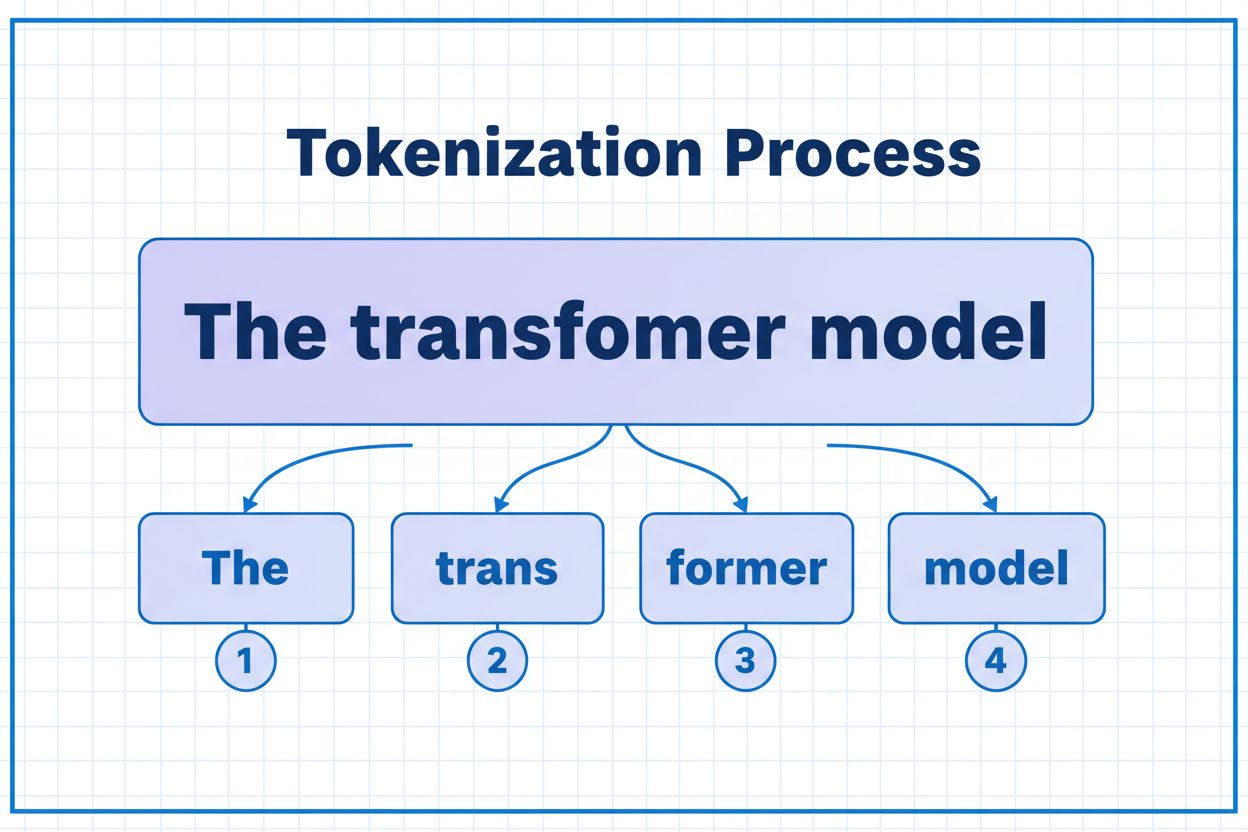
Token je nejmenší jednotka dat, kterou AI model zpracovává. Tokeny mohou být jednotlivé znaky, části slov nebo celá slova v závislosti na tokenizačním algoritmu. Například slovo 'transformer' může být rozděleno na 'trans' a 'former' jako dva samostatné tokeny. Každý token má přiřazen jedinečný číselný identifikátor, který model interně využívá pro výpočty.
Limity tokenů určují maximální množství informací, které může váš AI model zpracovat v jednom požadavku. Pokud tento limit překročíte, vaše aplikace zcela selže. I při dodržení limitů mohou naivní přístupy, jako je zkracování, snížit přesnost tím, že odstraní klíčový kontext. Limity tokenů také přímo ovlivňují náklady, protože obvykle platíte za každý spotřebovaný token.
Vstupní tokeny jsou tokeny ve vašem promptu a datech, které posíláte modelu, zatímco výstupní tokeny jsou tokeny, které model generuje ve své odpovědi. Sdílí společný rozpočet definovaný kontextovým oknem modelu. Pokud váš vstup využije 90 % z 128K tokenového okna, zbývá pouze 10 % pro výstup modelu.
Zkracování je jednoduché na implementaci, ale riskantní. Odstraňuje informace, aniž by model věděl, co bylo ztraceno, což vede k neúplné analýze a možným halucinacím. Jako poslední možnost může být užitečné, ale lepšími přístupy jsou RAG, chunking nebo sumarizace, které zachovávají věrnost informací a zároveň efektivněji řídí spotřebu tokenů.
Retrieval-Augmented Generation (RAG) získává pouze nejrelevantnější informace v době dotazu místo zahrnutí celých dokumentů. Vaše dokumenty jsou převedeny na embeddingy a uloženy ve vektorové databázi. Při dotazu uživatele systém vyhledá pouze relevantní části a vloží je do promptu, což výrazně snižuje spotřebu tokenů a zvyšuje přesnost.
Většina AI platforem nabízí nástroje na počítání tokenů a dashboardy v reálném čase pro sledování vzorců využití. Sledujte, které dotazy nebo funkce spotřebovávají nejvíce tokenů, a implementujte strategie optimalizace, jako je RAG pro aplikace pracující s dokumenty, sumarizace pro dlouhé konverzace nebo směrování na větší modely pro složitější úlohy. Měřte skutečný výkon a náklady, abyste ověřili své volby.
AI služby obvykle účtují za každý spotřebovaný token. Náklady rostou lineárně s využitím tokenů, takže optimalizace tokenů má přímý dopad na vaše výdaje. Snížení spotřeby tokenů o 20 % znamená 20% úsporu nákladů. Pochopení efektivity tokenů vám pomáhá zvolit správnou optimalizační strategii s ohledem na rozpočet.
Limity tokenů se nadále rozšiřují, jak se modely stávají sofistikovanějšími. Nové techniky jako sparse attention mechanismy slibují snížit výpočetní náročnost zpracování velkých kontextů. Budoucnost se zaměřuje na inteligentní výběr a získávání obsahu místo pouhé surové kapacity, což činí techniky jako RAG stále důležitějšími pro škálovatelné AI aplikace.
Pochopte efektivitu tokenů a sledujte, jak AI modely citují vaši značku pomocí komplexní platformy pro monitoring AI citací AmICited.
Zjistěte, co jsou tokeny v jazykových modelech. Tokeny jsou základní jednotky zpracování textu v AI systémech, představující slova, podslova nebo znaky jako čís...

Zjistěte, jak AI modely zpracovávají text pomocí tokenizace, embeddingů, transformer bloků a neuronových sítí. Pochopte celý proces od vstupu až po výstup....

Prozkoumejte, jak AI systémy rozpoznávají a zpracovávají entity v textu. Seznamte se s NER modely, architekturami transformerů a reálnými aplikacemi porozumění ...