
Co jsou embeddingy ve vyhledávání pomocí AI?
Zjistěte, jak embeddingy fungují ve vyhledávačích a jazykových modelech s umělou inteligencí. Porozumějte vektorovým reprezentacím, sémantickému vyhledávání a j...
7 min čtení

Zjistěte, jak vektorové embeddingy umožňují AI systémům chápat sémantický význam a přiřazovat obsah k dotazům. Prozkoumejte technologii za sémantickým vyhledáváním a přiřazováním obsahu pomocí AI.

Vektorové embeddingy jsou číselným základem, který pohání moderní systémy umělé inteligence, a transformují surová data na matematické reprezentace, kterým stroje rozumí a které dokáží zpracovat. V jádru embeddingy převádějí text, obrázky, zvuk i další typy obsahu na pole čísel—obvykle v řádu desítek až tisíců rozměrů—která zachycují sémantický význam a kontextuální vztahy v těchto datech. Tato číselná reprezentace je zásadní pro to, jak AI systémy provádějí přiřazování obsahu, sémantické vyhledávání a doporučovací úlohy. Stroje díky ní chápou nejen to, jaká slova nebo obrázky jsou přítomné, ale i co skutečně znamenají. Bez embeddingů by AI systémy těžko rozpoznaly jemné vztahy mezi pojmy, a proto jsou embeddingy nezbytnou infrastrukturou pro jakoukoliv moderní AI aplikaci.
Transformace surových dat na vektorové embeddingy je umožněna sofistikovanými modely neuronových sítí, které jsou trénované na obrovských datových sadách, aby rozpoznaly smysluplné vzory a vztahy. Když do embeddingového modelu zadáte text, projde několika vrstvami neuronových sítí, které postupně extrahují sémantickou informaci a nakonec vytvoří vektor s pevnou velikostí, jenž reprezentuje podstatu tohoto obsahu. Oblíbené embeddingové modely jako Word2Vec, GloVE a BERT k tomu přistupují různě—Word2Vec využívá mělké neuronové sítě optimalizované na rychlost, GloVE kombinuje globální maticovou dekompozici s lokálním kontextem, zatímco BERT využívá transformerovou architekturu, aby pochopil oboustranný kontext.
| Model | Typ dat | Rozměry | Hlavní použití | Klíčová výhoda |
|---|---|---|---|---|
| Word2Vec | Text (slova) | 100-300 | Vztahy mezi slovy | Rychlý, efektivní |
| GloVE | Text (slova) | 100-300 | Sémantické vztahy | Kombinuje globální a lokální kontext |
| BERT | Text (věty/dokumenty) | 768-1024 | Kontextové porozumění | Oboustranné vnímání kontextu |
| Sentence-BERT | Text (věty) | 384-768 | Podobnost vět | Optimalizováno na sémantické vyhledávání |
| Universal Sentence Encoder | Text (věty) | 512 | Mezijazykové úlohy | Jazykově nezávislý |
Tyto modely produkují vysoce rozměrné vektory (často 300 až 1 536 rozměrů), přičemž každý rozměr zachycuje odlišný aspekt významu, od gramatických vlastností po konceptuální vztahy. Kouzlo této číselné reprezentace spočívá v tom, že umožňuje matematické operace—vektory lze sčítat, odečítat a porovnávat, což umožňuje objevovat vztahy, které by v surovém textu zůstaly skryté. Tento matematický základ umožňuje škálovatelné sémantické vyhledávání i inteligentní přiřazování obsahu.
Skutečná síla embeddingů se ukazuje v sémantické podobnosti, tedy schopnosti rozpoznat, že různé výrazy nebo fráze mohou znamenat v podstatě totéž ve vektorovém prostoru. Pokud jsou embeddingy vytvořeny efektivně, sémanticky podobné pojmy se přirozeně shlukují ve vysoko-dimenzionálním prostoru—“král” a “královna” jsou si blízko, stejně jako “auto” a “vozidlo”, přestože jde o různá slova. Pro měření této podobnosti využívají AI systémy metriky vzdálenosti jako kosinová podobnost (měří úhel mezi vektory) nebo skalární součin (měří velikost a směr), které kvantifikují, jak blízko si dva embeddingy jsou. Například dotaz na “automobilovou dopravu” bude mít vysokou kosinovou podobnost s dokumenty o “cestování autem”, což umožňuje systému přiřazovat obsah podle významu, ne jen podle přesné shody klíčových slov. Právě toto sémantické porozumění odlišuje moderní AI vyhledávání od pouhého porovnávání klíčových slov a umožňuje systémům chápat záměr uživatele a doručovat skutečně relevantní výsledky.
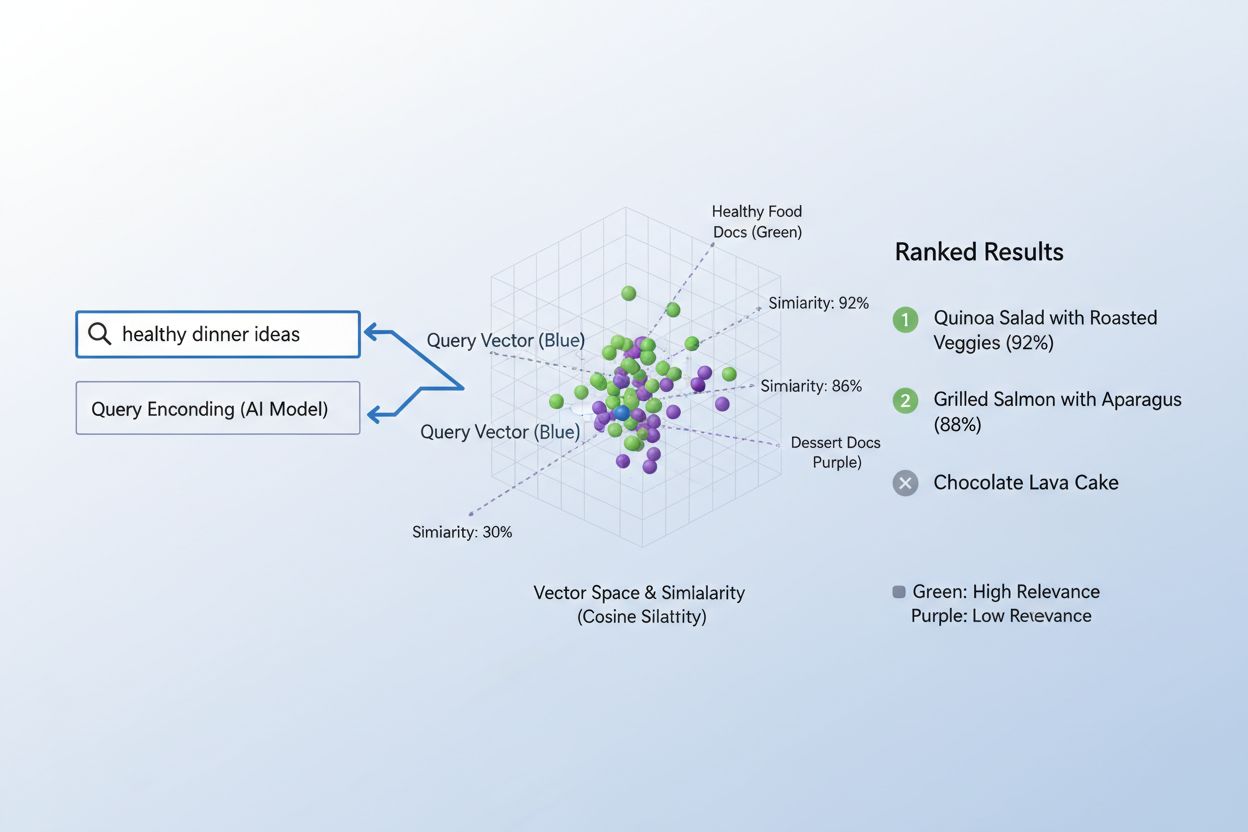
Proces přiřazování obsahu k dotazům pomocí embeddingů probíhá v elegantním dvoukrokovém workflow, které pohání vše od vyhledávačů po doporučovací systémy. Nejprve se jak uživatelský dotaz, tak dostupný obsah nezávisle převedou na embeddingy pomocí stejného modelu—dotaz typu “best practices for machine learning” se převede na vektor stejně jako každý článek, dokument nebo produkt v databázi systému. Následně systém vypočítá podobnost mezi embeddingem dotazu a embeddingem každého obsahu, typicky pomocí kosinové podobnosti, což dá skóre určující, jak relevantní je daný obsah k dotazu. Tato skóre podobnosti se seřadí a nejrelevantnější obsah je uživateli zobrazen na prvních místech výsledků. V reálném vyhledávači, když hledáte “jak trénovat neuronové sítě”, systém zakóduje váš dotaz, porovná jej s miliony embeddingů dokumentů a vrátí články o hlubokém učení, optimalizaci modelů a trénovacích technikách—aniž by vyžadoval přesnou shodu klíčových slov. Celý proces probíhá během milisekund, což jej činí praktickým pro aplikace v reálném čase s miliony uživatelů současně.
Různé typy embeddingů slouží různým účelům podle toho, co potřebujete přiřazovat nebo analyzovat. Word embeddingy zachycují význam jednotlivých slov a jsou vhodné pro úlohy vyžadující detailní sémantické porozumění, zatímco sentence embeddingy a document embeddingy agregují význam přes delší úseky textu, což je ideální pro párování celých dotazů s články či dokumenty. Image embeddingy číselně reprezentují vizuální obsah, což umožňuje systémům nacházet vizuálně podobné obrázky nebo párovat obrázky s popisy, zatímco uživatelské embeddingy a embeddingy produktů zachycují vzorce chování a charakteristiky, a pohánějí doporučovací systémy, které navrhují položky podle preferencí uživatele. Výběr mezi těmito embeddingy je otázkou kompromisů: word embeddingy jsou výpočetně efektivní, ale ztrácí kontext; document embeddingy zachovávají úplný význam, ale vyžadují více výpočetních prostředků. Doménově specifické embeddingy, doladěné na specializovaných datových sadách (např. medicínská literatura či právní dokumenty), často předčí obecné modely v oborových aplikacích, ale vyžadují další trénovací data a výpočetní kapacitu.
V praxi embeddingy pohánějí některé z nejzásadnějších AI aplikací, které denně používáme—od výsledků vyhledávání po produkty doporučované online. Sémantické vyhledávače využívají embeddingy k pochopení záměru dotazu a zobrazují relevantní obsah bez ohledu na shodu klíčových slov, zatímco doporučovací systémy Netflixu, Amazonu a Spotify používají embeddingy uživatelů i položek, aby předpověděly, na co se budete chtít dívat, co koupit nebo poslouchat. Systémy pro moderaci obsahu využívají embeddingy k detekci škodlivého obsahu porovnáváním uživatelských příspěvků s embeddingy známých porušení pravidel, zatímco systémy pro odpovídání na dotazy párují uživatelské otázky s relevantními znalostními články hledáním sémanticky podobného obsahu. Personalizační enginy využívají embeddingy k pochopení uživatelských preferencí a šití zážitků na míru a systémy pro detekci anomálií rozpoznávají neobvyklé vzory, když nové datové body leží daleko od očekávaných embeddingových clusterů. V AmICited využíváme embeddingy ke sledování, jak jsou AI systémy využívány napříč internetem, párujeme uživatelské dotazy a obsah a sledujeme, kde se objevuje AI generovaný nebo AI asistovaný obsah, což pomáhá značkám chápat jejich AI stopu a zajistit správné uvedení zdroje.
Úspěšná implementace embeddingů vyžaduje pečlivé řešení několika technických aspektů, které ovlivňují výkon i náklady. Výběr modelu je zásadní—je třeba vyvážit sémantickou kvalitu embeddingů s výpočetními požadavky, přičemž větší modely typu BERT produkují bohatší reprezentace, ale vyžadují více výpočetních prostředků než lehčí alternativy. Dimenzionalita představuje klíčový kompromis: embeddingy s vyšším počtem rozměrů zachytí více nuancí, ale spotřebují více paměti a zpomalují výpočty podobnosti, zatímco embeddingy s nižším počtem rozměrů jsou rychlejší, ale mohou ztratit důležité sémantické informace. Pro efektivní párování ve velkém měřítku systémy využívají specializované indexovací strategie jako FAISS (Facebook AI Similarity Search) nebo Annoy (Approximate Nearest Neighbors Oh Yeah), které umožňují nalézt podobné embeddingy v milisekundách díky organizaci vektorů do stromových struktur či schémat citlivých na lokalitu. Doladění embeddingových modelů na doménově specifických datech může dramaticky zvýšit relevanci ve specializovaných aplikacích, ale vyžaduje označená trénovací data a dodatečné výpočetní náklady. Organizace neustále balancují rychlost vůči přesnosti, výpočetní náklady vůči sémantické kvalitě a obecné modely vůči specializovaným alternativám podle svých konkrétních potřeb a omezení.
Budoucnost embeddingů směřuje k větší sofistikovanosti, efektivitě a integraci s širšími AI systémy, což přinese ještě výkonnější možnosti párování a porozumění obsahu. Multimodální embeddingy, které současně zpracovávají text, obrázky i zvuk, umožní systémům párovat napříč různými typy obsahu—najít obrázky relevantní k textovým dotazům či naopak—a otevírají zcela nové možnosti pro objevování a porozumění obsahu. Výzkumníci vyvíjejí stále efektivnější embeddingové modely, které poskytují srovnatelnou sémantickou kvalitu s mnohem menším počtem parametrů, takže pokročilé AI schopnosti budou dostupné i menším organizacím a edge zařízením. Integrace embeddingů s velkými jazykovými modely vytváří systémy, které dokáží nejen sémanticky párovat obsah, ale zároveň porozumět kontextu, nuancím i záměru na dosud nevídané úrovni. Jak se AI systémy stávají všudypřítomnými na internetu, roste důležitost schopnosti sledovat, monitorovat a chápat, jak je obsah párován a využíván—právě zde platformy jako AmICited využívají embeddingy, aby organizacím pomohly sledovat přítomnost značky, monitorovat vzorce užití AI a zajistit správné uvedení a využití jejich obsahu. Konvergence lepších embeddingů, efektivnějších modelů a sofistikovaných monitorovacích nástrojů vytváří budoucnost, kde budou AI systémy transparentnější, odpovědnější a lépe sladěné s lidskými hodnotami.
Vektorový embedding je číselná reprezentace dat (textu, obrázků, audia) ve vícerozměrném prostoru, která zachycuje sémantický význam a vztahy. Převádí abstraktní data na pole čísel, která stroje mohou matematicky zpracovávat a analyzovat.
Embeddingy převádějí abstraktní data na čísla, která stroje mohou zpracovat, což umožňuje AI identifikovat vzorce, podobnosti a vztahy mezi různými částmi obsahu. Tato matematická reprezentace umožňuje AI systémům chápat význam, nikoliv pouze porovnávat klíčová slova.
Porovnávání klíčových slov hledá přesné shody slov, zatímco sémantická podobnost chápe význam. Díky tomu systémy najdou související obsah i bez stejných slov—například přiřadí 'automobil' ke 'car' na základě sémantického vztahu, nikoli přesné textové shody.
Ano, embeddingy mohou reprezentovat text, obrázky, audio, uživatelské profily, produkty a další. Různé embeddingové modely jsou optimalizovány pro různé typy dat, od Word2Vec pro text přes CNN pro obrázky až po spektrogramy pro audio.
AmICited využívá embeddingy k pochopení, jak AI systémy sémanticky přiřazují a odkazují na vaši značku napříč různými AI platformami a odpověďmi. To pomáhá sledovat přítomnost vašeho obsahu v AI generovaných odpovědích a zajistit správné uvedení zdroje.
Klíčové výzvy zahrnují výběr správného modelu, řízení výpočetních nákladů, práci s vysoce rozměrnými daty, ladění pro specifické domény a vyvažování rychlosti versus přesnosti při výpočtech podobnosti.
Embeddingy umožňují sémantické vyhledávání, které chápe záměr uživatele a vrací relevantní výsledky na základě významu, nikoliv pouze shody klíčových slov. Díky tomu vyhledávací systémy najdou obsah, který je pojmově příbuzný, i když neobsahuje přesné dotazované termíny.
Velké jazykové modely interně využívají embeddingy k pochopení a generování textu. Embeddingy jsou základem toho, jak tyto modely zpracovávají informace, přiřazují obsah a generují kontextově vhodné odpovědi.
Vektorové embeddingy pohání AI systémy jako ChatGPT, Perplexity a Google AI Overviews. AmICited sleduje, jak tyto systémy citují a odkazují na váš obsah, což vám pomáhá pochopit přítomnost vaší značky v AI generovaných odpovědích.
Zjistěte, jak embeddingy fungují ve vyhledávačích a jazykových modelech s umělou inteligencí. Porozumějte vektorovým reprezentacím, sémantickému vyhledávání a j...

Zjistěte, co jsou embeddings, jak fungují a proč jsou pro AI systémy nezbytné. Objevte, jak se text transformuje na číselné vektory, které zachycují sémantický ...
Zjistěte, jak vektorové vyhledávání využívá embeddingy strojového učení k nalezení podobných položek na základě významu, nikoliv přesných klíčových slov. Porozu...