Citace z Wikipedie jako tréninková data AI: Efekt vlnění
Zjistěte, jak citace z Wikipedie formují tréninková data AI a vytvářejí efekt vlnění napříč LLM. Zjistěte, proč je vaše přítomnost na Wikipedii důležitá pro zmínky AI a vnímání vaší značky.
Publikováno dne Jan 3, 2026.Naposledy upraveno dne Jan 3, 2026 v 3:24 am
Wikipedie se stala základním tréninkovým datasetem pro prakticky každý hlavní velký jazykový model současnosti – od ChatGPT společnosti OpenAI a Gemini od Googlu až po Claude od Anthropic a vyhledávač Perplexity. V mnoha případech představuje Wikipedie největší zdroj strukturovaného, kvalitního textu v tréninkových datasetech těchto AI systémů a často tvoří 5–15 % celkového tréninkového korpusu v závislosti na modelu. Tato dominance vychází z jedinečných vlastností Wikipedie: její zásada neutrálního úhlu pohledu, důsledné komunitní ověřování faktů, strukturované formátování a volná licence z ní dělají bezkonkurenční zdroj pro výuku AI systémů, jak uvažovat, citovat zdroje a přesně komunikovat. Tento vztah však zásadně proměnil roli Wikipedie v digitálním ekosystému – už není jen cílovou stanicí pro lidské čtenáře hledající informace, ale stala se neviditelnou páteří pohánějící konverzační AI, se kterou denně přicházejí do kontaktu miliony lidí. Porozumění tomuto spojení odhaluje klíčový efekt vlnění: kvalita, zaujatost a mezery ve Wikipedii přímo ovlivňují schopnosti a omezení AI systémů, které dnes zprostředkovávají, jak miliardy lidí přistupují k informacím a chápou je.
Jak LLM skutečně využívají data z Wikipedie
Když velké jazykové modely zpracovávají informace během tréninku, nepřistupují ke všem zdrojům stejně – Wikipedie má v jejich rozhodovacím žebříčku výjimečně privilegované postavení. Při procesu rozpoznávání entit LLM identifikují klíčová fakta a pojmy a následně je ověřují v několika zdrojích, aby stanovily skóre důvěryhodnosti. Wikipedie v tomto procesu slouží jako „primární autoritativní kontrola“ díky transparentní historii úprav, komunitním ověřovacím mechanismům a zásadě neutrálního pohledu, což dohromady signalizuje AI systémům spolehlivost. Efekt násobitele důvěryhodnosti tuto výhodu ještě zvyšuje: když se informace objevuje konzistentně na Wikipedii, ve strukturovaných znalostních grafech, jako je Google Knowledge Graph nebo Wikidata, i v akademických zdrojích, LLM přiřazují těmto informacím exponenciálně vyšší důvěru. Tento systém vážení vysvětluje, proč je Wikipedie v tréninku výjimečná – slouží jako přímý zdroj znalostí i jako validační vrstva pro fakta převzatá z jiných zdrojů. Výsledkem je, že se LLM naučily považovat Wikipedii ne pouze za jeden z mnoha datových bodů, ale za základní referenci, která buď potvrzuje, nebo zpochybňuje informace z méně ověřených zdrojů.
Váha důvěryhodnosti zdrojů při tréninku LLM
Typ zdroje
Váha důvěryhodnosti
Důvod
Zpracování AI
Wikipedie
Velmi vysoká
Neutrální, komunitně editovaná, ověřená
Primární reference
Firemní web
Střední
Sebeprezentační
Sekundární zdroj
Zpravodajské články
Vysoká
Nezávislé, ale potenciálně zaujaté
Potvrzující zdroj
Znalostní grafy
Velmi vysoká
Strukturované, agregované
Násobitel autority
Sociální sítě
Nízká
Neověřené, promoční
Minimální váha
Akademické zdroje
Velmi vysoká
Recenzované, autoritativní
Vysoká důvěra
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Řetězec citací: Jak Wikipedie ovlivňuje odpovědi AI
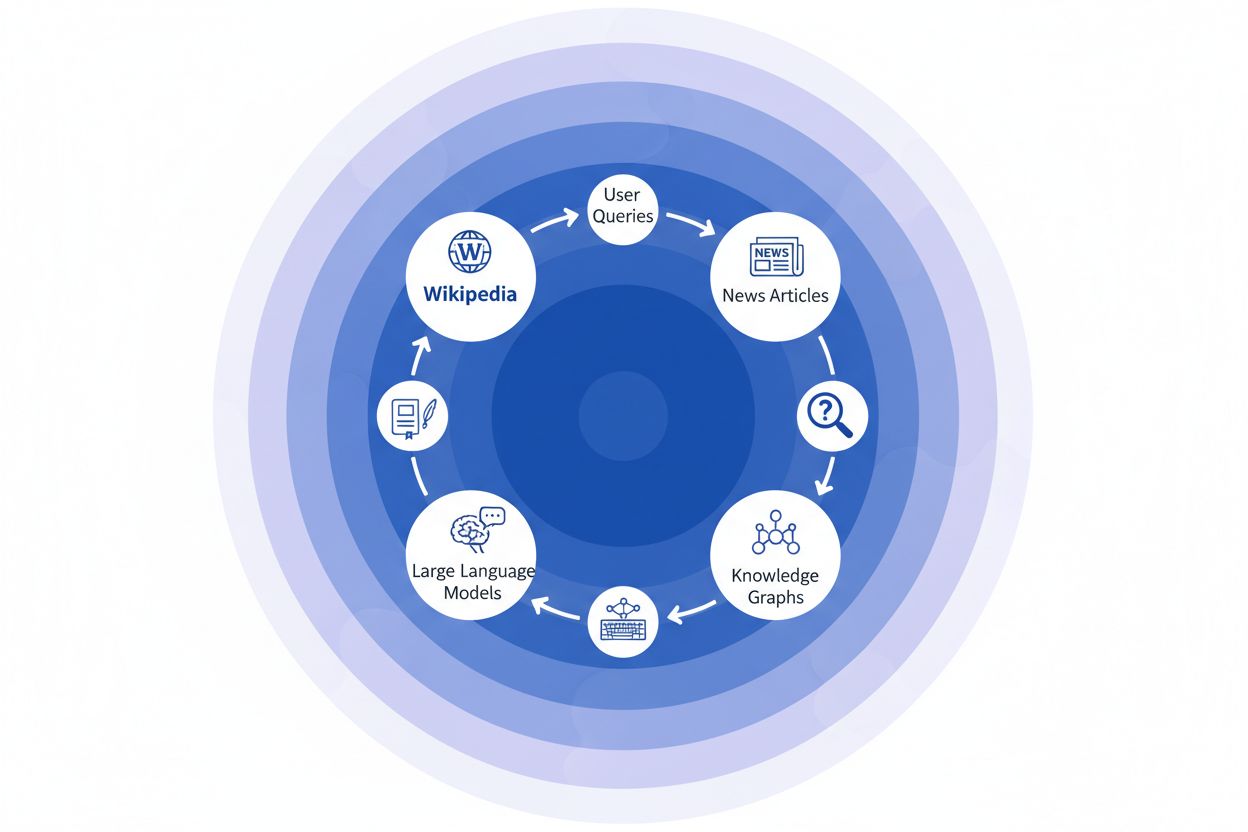
Když zpravodajská organizace cituje Wikipedii jako zdroj, vzniká to, čemu říkáme „řetězec citací“ – kaskádový mechanismus, kdy se důvěryhodnost násobí napříč několika vrstvami informační infrastruktury. Novinář píšící o klimatické vědě může odkázat na článek Wikipedie o globálním oteplování, který sám cituje recenzované studie; tento zpravodajský článek pak indexují vyhledávače a začlení jej do znalostních grafů, které následně trénují velké jazykové modely, které denně dotazuje miliony uživatelů. Vzniká tak silná zpětná vazba: Wikipedie → Znalostní graf → LLM → Uživatel, kde původní rámování a důrazy v článku na Wikipedii mohou nenápadně ovlivnit, jak AI systémy prezentují informace koncovým uživatelům – často aniž by si uvědomovali, že informace pochází z kolektivní encyklopedie. Uveďme příklad: pokud článek na Wikipedii o určitém farmaceutickém přípravku zdůrazňuje některé klinické studie, zatímco jiné opomíjí, toto redakční rozhodnutí se přenese do zpravodajství, zapíše se do znalostních grafů a nakonec ovlivní, jak ChatGPT nebo podobné modely odpovídají pacientům na otázky ohledně léčby. Tento „efekt vlnění“ znamená, že redakční rozhodnutí na Wikipedii neovlivňují jen čtenáře, kteří navštíví stránky přímo – zásadně formují informační krajinu, ze které se AI systémy učí a kterou následně odrážejí miliardám uživatelů. Řetězec citací tak proměňuje Wikipedii z cílového zdroje v neviditelnou, ale vlivnou vrstvu tréninkového procesu AI, kde přesnost a zaujatost na počátku mohou zesílit napříč celým ekosystémem.
Efekt vlnění: Následné důsledky
Efekt vlnění v ekosystému Wikipedie a AI je možná nejzásadnějším dynamickým prvkem, který by měly značky a organizace znát. Jediná editace na Wikipedii nezmění jen jeden zdroj – rozšíří se napříč propojenou sítí AI systémů, z nichž každý čerpá a zesiluje informace způsoby, které jejich dopad násobí exponenciálně. Když se na stránce Wikipedie objeví nepřesnost, nezůstane izolovaná; naopak se rozšíří napříč celým AI prostředím a formuje, jak je vaše značka denně popisována, chápána a prezentována milionům uživatelů. Tento násobící efekt znamená, že investice do přesnosti Wikipedie není jen o jedné platformě – jde o kontrolu vašeho narativu napříč celým generativním AI ekosystémem. Pro specialisty na digitální PR a správu značky tato skutečnost zásadně mění, kam zaměřit zdroje a pozornost.
Klíčové efekty vlnění, které sledovat:
Kvalita stránky na Wikipedii přímo ovlivňuje, jak AI systémy popisují vaši značku — Špatný obsah na Wikipedii se stává základem pro to, jak ChatGPT, Gemini, Claude a další AI systémy charakterizují vaši organizaci
Jedna citace na Wikipedii ovlivňuje znalostní grafy, které ovlivňují AI přehledy — Citace proudí přes znalostní infrastrukturu Googlu a přímo ovlivňují, jak se informace objevují v AI generovaných souhrnech
Nepřesné informace na Wikipedii se šíří celým ekosystémem AI — Jakmile se dezinformace dostane do tréninkových dat, je mnohonásobně těžší ji opravit napříč různými platformami
Pozitivní přítomnost na Wikipedii se zesiluje napříč všemi hlavními AI platformami — Dobře spravovaná stránka na Wikipedii vytváří konzistentní a autoritativní sdělení v ChatGPT, Gemini, Claude, Perplexity a nově vznikajících AI systémech
Editace Wikipedie mají zpožděné, ale kumulativní účinky na trénink AI — Dnešní změny ovlivní výstupy AI modelů na měsíce či roky, jak se informace dostávají do nových trénovacích cyklů
Efekt vlnění zasahuje až do Google AI Overviews, doporučených úryvků a znalostních panelů — Wikipedie slouží jako autoritativní zdroj pro Google AI generované výsledky vyhledávání a strukturované datové panely
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Výzva udržitelnosti Wikipedie: Hrozba pro ekosystém
Nedávný výzkum z IUP studie Vetter a kol. osvětlil zásadní zranitelnost naší AI infrastruktury: udržitelnost Wikipedie jako tréninkového zdroje je stále více ohrožována právě tou technologií, kterou pomáhá pohánět. Jak se velké jazykové modely rozmnožují a jsou trénovány na stále větších datasetech generovaných obsahem LLM, objevuje se kumulativní problém „kolapsu modelu“, kdy umělé výstupy začínají kontaminovat datový bazén, což degraduje kvalitu modelů v dalších generacích. Tento jev je obzvlášť naléhavý, protože Wikipedie – kolektivní encyklopedie postavená na lidské expertíze a dobrovolné práci – se stala základním pilířem pro trénink pokročilých AI systémů, často bez explicitního uznání nebo odměny pro své přispěvatele. Etické dopady jsou zásadní: jak AI společnosti těží z volně přístupných znalostí z Wikipedie a zároveň zahlcují informační ekosystém syntetickým obsahem, motivační struktury, které přes dvě dekády držely komunitu dobrovolníků Wikipedie, čelí bezprecedentnímu tlaku. Bez cíleného zásahu na ochranu lidsky generovaného obsahu jako samostatného a chráněného zdroje riskujeme vznik zpětné vazby, kdy texty generované AI postupně nahrazují autentické lidské znalosti a nakonec podkopávají samotný základ, na němž moderní jazykové modely stojí. Udržitelnost Wikipedie proto není záležitostí pouze této encyklopedie, ale klíčovou otázkou pro celý informační ekosystém a budoucí životaschopnost AI systémů, které jsou závislé na autentických lidských znalostech.
Sledování vaší přítomnosti na Wikipedii: Kde se uplatňuje AmICited
S tím, jak se AI systémy stále více spoléhají na Wikipedii jako na základní zdroj znalostí, je sledování toho, jak se vaše značka objevuje v těchto AI generovaných odpovědích, zásadní pro moderní organizace. AmICited.com se specializuje na sledování citací z Wikipedie, jak se šíří napříč AI systémy, a poskytuje značkám přehled o tom, jak jejich přítomnost na Wikipedii přechází do zmínek a doporučení v AI. Zatímco alternativní nástroje jako FlowHunt.io nabízejí obecné možnosti webového monitoringu, AmICited se jedinečně zaměřuje na sledování konkrétního řetězce citací od Wikipedie k AI, tedy na zachycení okamžiku, kdy AI systémy citují váš záznam na Wikipedii a jak to ovlivňuje jejich odpovědi. Porozumění tomuto propojení je zásadní, protože citace z Wikipedie mají v tréninkových datech AI a generování odpovědí velkou váhu – dobře spravovaná přítomnost na Wikipedii neinformuje jen lidské čtenáře, ale formuje i to, jak AI systémy vnímají a prezentují vaši značku milionům uživatelů. Sledováním zmínek o vaší značce na Wikipedii přes AmICited získáte praktické poznatky o své AI stopě, které vám umožní optimalizovat vaši přítomnost na Wikipedii s plným vědomím jejího dopadu na AI podporované vyhledávání a vnímání značky.
Často kladené otázky
Je Wikipedie opravdu používána pro trénink každého LLM?
Ano, každé hlavní LLM včetně ChatGPT, Gemini, Claude a Perplexity zahrnuje Wikipedii ve svých tréninkových datech. Wikipedie je často největším zdrojem strukturovaných, ověřených informací v tréninkových datasetech LLM, obvykle tvoří 5–15 % celkového tréninkového korpusu.
Jak Wikipedie ovlivňuje to, co AI systémy říkají o mé značce?
Wikipedie slouží jako kontrolní bod důvěryhodnosti pro AI systémy. Když LLM generuje informace o vaší značce, více zohledňuje popis z Wikipedie než z jiných zdrojů, což z vaší stránky na Wikipedii dělá klíčový vliv na to, jak vás AI systémy reprezentují napříč ChatGPT, Gemini, Claude a dalšími platformami.
Co je to „efekt vlnění“ v kontextu Wikipedie a AI?
Efekt vlnění označuje, jak jediná citace nebo editace na Wikipedii vytváří následné důsledky napříč celým ekosystémem AI. Jediná změna na Wikipedii může ovlivnit znalostní grafy, které ovlivňují AI přehledy, které následně ovlivňují, jak více AI systémů popisuje vaši značku milionům uživatelů.
Může nepřesná informace na Wikipedii poškodit mou značku v AI systémech?
Ano. Protože LLM považují Wikipedii za velmi důvěryhodnou, nepřesné informace na vaší stránce na Wikipedii se rozšíří do AI systémů. To může ovlivnit, jak ChatGPT, Gemini a další AI platformy popisují vaši organizaci, což může poškodit vnímání vaší značky.
Jak mohu sledovat, jak Wikipedie ovlivňuje mou značku v AI systémech?
Nástroje jako AmICited.com sledují, jak je vaše značka citována a zmiňována napříč AI systémy včetně ChatGPT, Perplexity a Google AI Overviews. To vám pomůže pochopit efekt vlnění vaší přítomnosti na Wikipedii a podle toho optimalizovat.
Mám si vytvořit nebo upravit stránku na Wikipedii sám?
Wikipedie má přísné zásady proti sebeprezentaci. Jakékoliv úpravy by měly dodržovat pravidla Wikipedie a vycházet ze spolehlivých, nezávislých zdrojů. Mnoho organizací spolupracuje se specialisty na Wikipedii, aby zajistily soulad s pravidly a zároveň udržely přesnou prezentaci.
Jak dlouho trvá, než se změny na Wikipedii projeví v AI systémech?
LLM jsou trénována na snímcích dat, takže změny potřebují čas, než se rozšíří. Znalostní grafy se ale aktualizují častěji, takže efekt vlnění může začít během týdnů až měsíců v závislosti na AI systému a době jeho přetrénování.
Jaký je rozdíl mezi Wikipedií a znalostními grafy při tréninku AI?
Wikipedie je primární zdroj používaný přímo při tréninku LLM. Znalostní grafy, jako je Google Knowledge Graph, agregují informace z více zdrojů včetně Wikipedie a předávají je AI systémům, což vytváří další vrstvu vlivu na to, jak AI systémy informace chápou a prezentují.
Sledujte svou přítomnost na Wikipedii v AI systémech
Sledujte, jak se citace z Wikipedie šíří přes ChatGPT, Gemini, Claude a další AI systémy. Porozumějte své AI stopě a optimalizujte svou přítomnost na Wikipedii s AmICited.
Role Wikipedie v trénovacích datech pro AI: Kvalita, dopad a licencování
Zjistěte, jak Wikipedie slouží jako klíčový dataset pro trénování AI, jaký má vliv na přesnost modelů, licenční ujednání a proč na ní firmy vyvíjející umělou in...
Jak být citován v článcích na Wikipedii: Ne-manipulativní přístup
Naučte se etické strategie, jak získat zmínku o vaší značce na Wikipedii. Pochopte pravidla obsahu Wikipedie, spolehlivé zdroje a jak využít citace pro viditeln...
Role Wikipedie v AI citacích: Jak ovlivňuje AI-generované odpovědi
Zjistěte, jak Wikipedie ovlivňuje AI citace v ChatGPT, Perplexity a Google AI. Dozvíte se, proč je Wikipedie nejdůvěryhodnějším zdrojem pro trénink AI a jak to ...
12 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.