Definice schématu článku
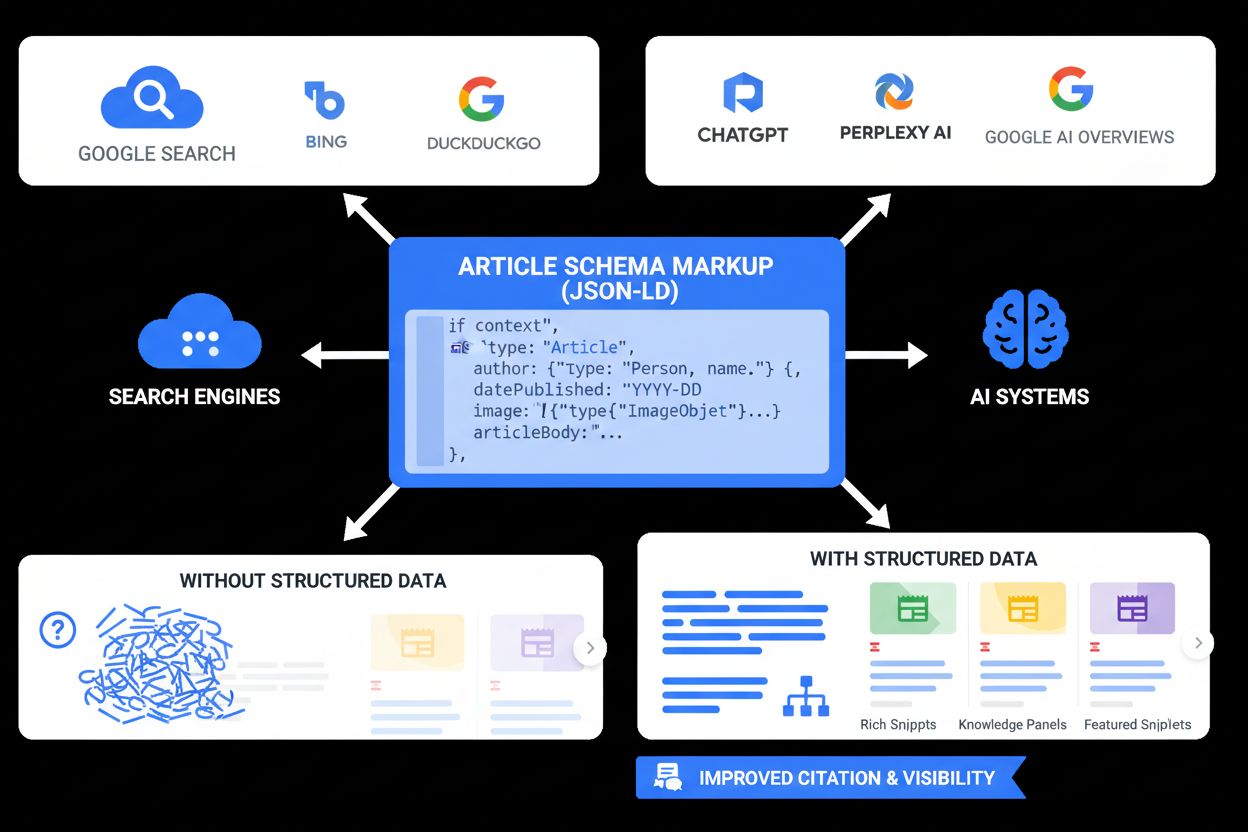
Schéma článku je typ strukturovaného datového označení z Schema.org, který explicitně definuje vlastnosti a metadata zpravodajských článků, blogových příspěvků a dalšího psaného obsahu. Implementované pomocí formátu JSON-LD, schéma článku sděluje klíčové informace o vašem obsahu vyhledávačům, AI systémům a dalším digitálním platformám. Toto označení zahrnuje zásadní vlastnosti jako headline, author, datePublished, dateModified, image a articleBody, což umožňuje strojům pochopit nejen, o čem je váš obsah, ale také kdo jej vytvořil, kdy byl publikován a jak by měl být prezentován. Schéma článku slouží jako most mezi webovým obsahem čitelným pro lidi a strojově čitelnými daty, díky čemuž jsou vaše články dohledatelné a citovatelné napříč vyhledávači, AI odpovědními enginy jako ChatGPT a Perplexity i novými AI platformami. Implementací schématu článku vydavatelé zajišťují, že jejich obsah je správně pochopen a správně přiřazen při citaci AI systémy, což je stále důležitější, protože AI-generované odpovědi se stávají hlavním způsobem objevování online obsahu.
Kontext a historický vývoj
Vývoj schématu článku odráží širší posun v tom, jak je digitální obsah objevován a konzumován. Schema.org, spuštěné v roce 2011 jako společná iniciativa Googlu, Bingu, Yahoo a Yandexu, vytvořilo standardizovaný slovník pro strukturovaná data. Schéma článku se objevilo jako jeden ze základních typů, navržený tak, aby pomáhal vyhledávačům porozumět povaze a kontextu publikovaného obsahu. Zpočátku se schéma článku používalo především ke zlepšení vzhledu výsledků vyhledávání prostřednictvím rich snippets, které přímo ve výsledcích zobrazovaly metadata jako datum publikace a informace o autorovi.
Účel a význam schématu článku se však dramaticky změnily s nástupem AI vyhledávačů a velkých jazykových modelů (LLM). Podle výzkumu společnosti Profound bylo mezi srpnem 2024 a červnem 2025 sledováno přibližně 680 milionů citací napříč ChatGPT, Google AI Overviews a Perplexity, což ukazuje, že AI systémy silně spoléhají na strukturovaná data při identifikaci a citování důvěryhodných zdrojů. Více než 80 % citací na hlavních AI platformách pochází z .com domén, přičemž neziskové .org stránky představují druhou největší kategorii s 11,29 % citací v ChatGPT. Tato data ukazují, že schéma článku je dnes zásadní nejen pro tradiční viditelnost ve vyhledávačích, ale i pro to, aby byl váš obsah rozpoznán a citován AI systémy, které nyní ovlivňují, jak miliardy lidí objevují informace.
Posun od vyhledávačů k AI systémům znamená zásadní změnu v přístupu vydavatelů ke schématu článku. Zatímco dříve šlo zejména o zlepšení vzhledu výsledků vyhledávání, dnes musejí vydavatelé zajistit, aby jejich schéma článku bylo dostatečně komplexní a přesné pro správnou extrakci, pochopení a přiřazení obsahu AI systémy. Tento vývoj učinil implementaci schématu článku klíčovou součástí Generative Engine Optimization (GEO) a strategie AI viditelnosti.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Technická implementace a vlastnosti
Schéma článku je implementováno jako blok JSON-LD (JavaScript Object Notation for Linked Data), umístěný v sekci <head> vašeho HTML dokumentu. JSON-LD je doporučeným formátem od Googlu, Bingu a všech hlavních vyhledávačů, protože udržuje strukturovaná data odděleně od hlavního HTML, což usnadňuje údržbu a snižuje chybovost. Základní struktura schématu článku zahrnuje vlastnost @context (určující slovník Schema.org), @type (identifikace obsahu jako Article, NewsArticle nebo BlogPosting) a různé vlastnosti popisující metadata článku.
Doporučené vlastnosti schématu článku zahrnují:
- headline: Titulek článku, který by měl být stručný a výstižný
- image: URL adresy obrázků reprezentujících článek; Google doporučuje více poměrů stran (1x1, 4x3, 16x9) a minimálně 50 000 pixelů
- datePublished: Datum původního zveřejnění v ISO 8601 formátu
- dateModified: Datum poslední úpravy, důležité pro AI systémy pro určení aktuálnosti obsahu
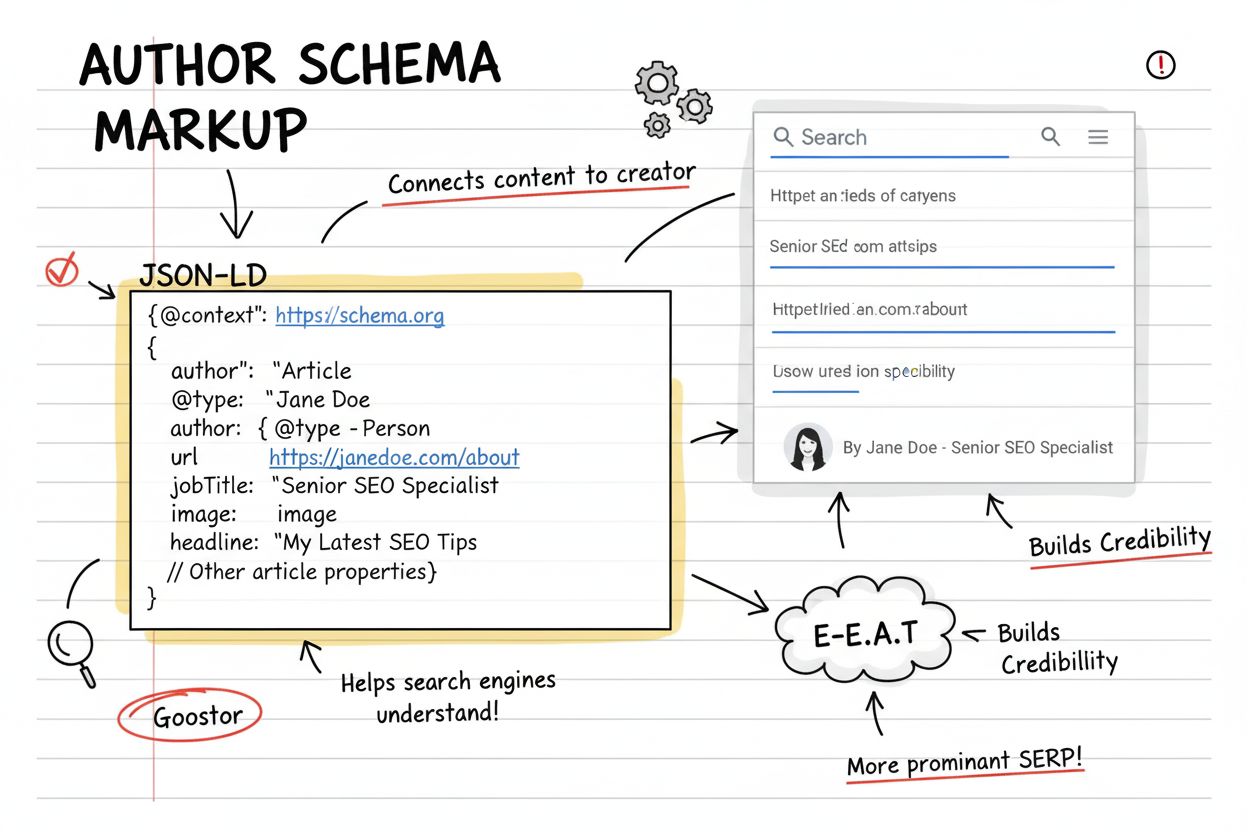
- author: Osoba nebo organizace zodpovědná za tvorbu obsahu, s vlastnostmi jméno a URL
- articleBody: Samotný textový obsah článku
- articleSection: Sekce nebo kategorie, do které článek patří (například „Technologie“, „Sport“)
- description: Krátké shrnutí obsahu článku
- publisher: Organizace, která článek publikuje
Podle dokumentace Google Search Central sice nejsou žádné vlastnosti povinné, ale zahrnutí těchto doporučených vlastností výrazně zvyšuje šanci na zobrazení ve zvýrazněných výsledcích a správné pochopení AI systémy. Vlastnost author je zvlášť důležitá pro AI citaci, protože potvrzuje autoritu obsahu a pomáhá AI systémům správně přiřadit informace. Výzkum společnosti Evertune ukazuje, že obsah optimalizovaný pro schéma umožňuje AI systémům snadné pochopení, extrakci a přesné citování informací, přičemž stránky s kvalitní implementací schématu se častěji objevují v AI-generovaných odpovědích.
Srovnávací tabulka: Typy schémat článku a související označení
| Typ schématu | Nejlepší použití | Délka obsahu | Klíčový rozdíl | Priorita AI citace |
|---|
| Article | Obecný psaný obsah, blogy, články | 500+ slov | Nadřazený typ pro všechny články | Vysoká – univerzální akceptace |
| NewsArticle | Zpravodajství, aktuální zprávy | 300+ slov | Zahrnuje vlastnosti specifické pro zprávy | Velmi vysoká – zaměřeno na zpravodajské AI systémy |
| BlogPosting | Osobní, firemní blogy | 50–400 slov | Optimalizováno pro metadata blogů | Střední – blogové platformy |
| ScholarlyArticle | Akademické práce, výzkum | 1000+ slov | Obsahuje citační a výzkumné vlastnosti | Velmi vysoká – akademické AI systémy |
| TechArticle | Technologické návody, how-to | 500+ slov | Zahrnuje instrukce krok za krokem | Vysoká – technologické platformy |
| Report | Odborné zprávy, whitepapery | 2000+ slov | Formální struktura publikace | Vysoká – enterprise AI systémy |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Jak schéma článku ovlivňuje AI vyhledávání a citace
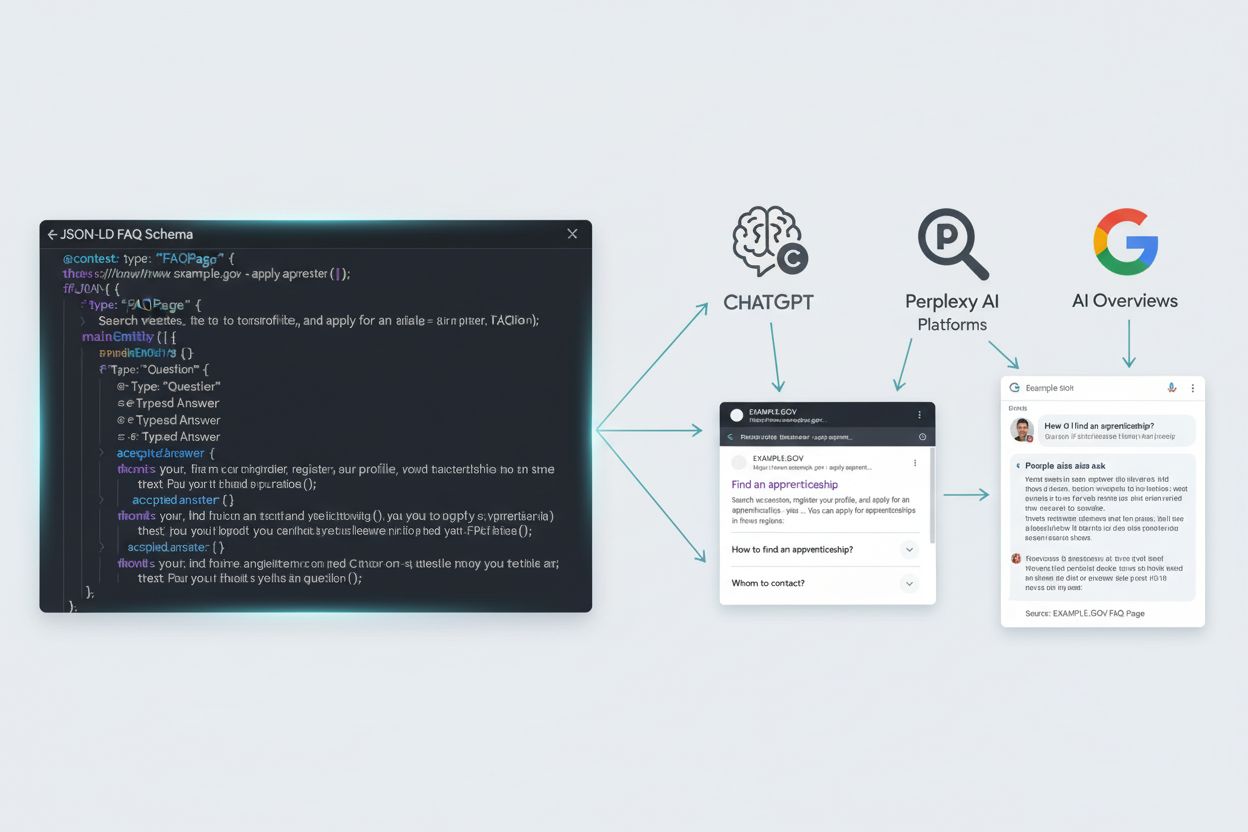
Vztah mezi schématem článku a AI viditelností se stal jedním z nejdůležitějších faktorů moderní obsahové strategie. Výzkum Profound analyzující 680 milionů citací napříč hlavními AI platformami odhalil rozdíly v tom, jak různé AI systémy získávají a citují informace. ChatGPT preferuje autoritativní zdroje jako Wikipedii (7,8 % všech citací), zatímco Google AI Overviews využívá více zdrojů, například Reddit (2,2 %), YouTube (1,9 %) a Quoru (1,5 %). Perplexity výrazně upřednostňuje komunitní obsah, přičemž Reddit tvoří 6,6 % jeho citací.
Všechny tyto platformy však spojuje spolehnutí na strukturovaná data pro pochopení kontextu a autority obsahu. Při správné implementaci schématu článku umí AI systémy:
- Identifikovat typ a účel obsahu – AI rozpozná, jestli jde o zprávu, analýzu nebo komentář
- Získávat informace o autorovi a vydavateli – Správné přiřazení je automatické a přesné
- Určit aktuálnost obsahu – Vlastnost
dateModified pomáhá AI zjistit, zda jsou informace aktuální - Pochopit vztahy mezi obsahem – Schéma napomáhá AI propojit související články a témata
- Vyhodnotit autoritu obsahu – URL autora a informace o vydavateli umožňují AI hodnotit důvěryhodnost zdroje
Výzkum BrightEdge ukázal, že schéma zlepšuje přítomnost značky v Google AI Overviews, s vyšší mírou citací na stránkách s robustním označením. To je zásadní, protože dokládá, že schéma článku není pouze technickou SEO vychytávkou – přímo ovlivňuje, zda se váš obsah objeví v AI-generovaných odpovědích, které používají miliony lidí jako primární rozhraní vyhledávání.
Schéma článku vs. tradiční SEO signály
Rozdíl mezi schématem článku a tradičními SEO signály představuje zásadní změnu v tom, jak je obsah objevován. Tradiční SEO signály jako zpětné odkazy, optimalizace klíčových slov a doménová autorita fungují na základě nepřímých indicií – vyhledávače usuzují, že je obsah populární a důvěryhodný na základě vnějších signálů. Tyto signály dobře fungují v tradičních výsledcích vyhledávání, kde uživatelé vidí více odkazů a sami si vybírají.
Schéma článku naopak poskytuje explicitní, přímé signály o tom, co váš obsah reprezentuje. Místo toho, aby vyhledávač odvozoval, že se jedná o článek o technologii, schéma článku jasně říká: „Toto je článek, publikovaný dne [datum], napsaný autorem [autor], s tímto titulkem a těmito obrázky.“ Tato přímočarost je pro AI systémy klíčová, protože LLM zpracovávají informace jinak než tradiční vyhledávače. Zatímco tradiční vyhledávače mohou význam vyvozovat z kontextu a vnějších signálů, AI systémy těží z explicitních metadat, která odstraňují nejednoznačnost.
Podle výzkumu Evertune „obsah optimalizovaný pro schéma umožňuje AI systémům snadné pochopení, extrakci a přesné citování informací.“ To je klíčová myšlenka: schéma článku nepomáhá jen vyhledávačům – zásadně mění způsob, jakým s vaším obsahem AI systémy interagují. Pokud schéma článku chybí nebo je neúplné, musí AI informace odvozovat z obsahu stránky, což může vést k nesprávnému přiřazení, špatnému kontextu nebo úplnému vynechání z AI odpovědí.
Praktickým důsledkem je, že vydavatelé se již nemohou spoléhat pouze na tradiční SEO taktiky. Dobře optimalizovaný článek s kvalitními zpětnými odkazy a klíčovými slovy se může v AI odpovědích vůbec neobjevit, pokud mu chybí správné schéma článku. Naopak článek s komplexním označením má významně vyšší šanci být AI citován, i když jeho tradiční SEO signály jsou jen průměrné.
Nejlepší postupy pro implementaci schématu článku
Efektivní implementace schématu článku vyžaduje technickou přesnost i strategickou úplnost. Prvním doporučením je konzistence v reprezentaci autora. Při implementaci vlastnosti author používejte napříč všemi články stejného autora stejný formát jména i URL. Tato konzistence pomáhá AI systémům i vyhledávačům rozpoznat autora jako samostatnou entitu a budovat signály autority v čase. Pokud má autor profil na vašem webu, odkažte na něj pomocí vlastnosti url.
Druhé doporučení je kompletní označení obrázků. Google doporučuje poskytovat obrázky ve třech poměrech stran: 1x1 (čtverec), 4x3 (na šířku), 16x9 (širokoúhlé), přičemž každý obrázek musí mít alespoň 50 000 pixelů (šířka × výška). Obrázky by měly reprezentovat obsah článku, nikoli být pouze logem nebo dekorací. AI systémy obrázky využívají k pochopení kontextu článku a k zobrazování vizuálních náhledů v odpovědích.
Třetí doporučení je přesné označení dat. Vždy uvádějte jak datePublished (původní datum vydání), tak dateModified (datum poslední úpravy) ve formátu ISO 8601 včetně časového pásma. AI systémy tato data využívají k určení aktuálnosti, což je zvlášť důležité u zpravodajských a časově citlivých článků. Pokud článek výrazně upravíte, zajistěte, aby dateModified odpovídalo reálnému času úpravy.
Čtvrté doporučení je úplná informace o autorovi. Kromě jména autora přidejte vlastnost url odkazující na profil autora nebo jeho sociální sítě. To AI systémům pomáhá ověřit identitu autora a posoudit jeho odbornost. U organizací jako autorů přidejte URL webu a logo organizace. Tento kontext významně zlepšuje hodnocení autority AI systémy.
Páté doporučení je správná hierarchie a propojení schémat. Schéma článku by nemělo stát osamoceně. Propojujte jej s dalšími entitami jako vydavatel, autor či související články. Vzniká tím tzv. datový graf (podle Yoast), který AI systémům pomáhá pochopit, jak váš obsah zapadá do širšího informačního ekosystému. Dobře propojený datový graf zvyšuje šanci, že AI váš obsah rozpozná jako autoritativní a správně jej cituje.
Různé AI platformy mají různé preference, jak získávají a citují informace, což má dopad na strategii schématu článku. ChatGPT silně preferuje encyklopedické a autoritativní zdroje – Wikipedia tvoří téměř 48 % jeho deseti nejcitovanějších zdrojů. To naznačuje, že pro viditelnost v ChatGPT by schéma článku mělo zdůrazňovat komplexní, dobře prozkoumaný obsah s jasnými autorizačními údaji.
Google AI Overviews má vyváženější přístup a čerpá z Redditu (21 % top 10 zdrojů), YouTube (18,8 %) a Quory (14,3 %), vedle tradičních médií. AI systém Googlu oceňuje rozmanité pohledy a komunitní zapojení. Pro viditelnost v Google AI Overviews by mělo být schéma článku spojeno se strategií distribuce obsahu napříč platformami a komunitní angažovaností.
Perplexity nejvíce preferuje komunitní obsah – Reddit tvoří 46,7 % jeho deseti nejcitovanějších zdrojů. To znamená, že pro viditelnost v Perplexity je vhodné implementovat schéma článku na obsah řešící konkrétní otázky a problémy, které komunity aktivně diskutují.
Strategickým důsledkem je, že i když je implementace schématu článku univerzální, doprovodná obsahová strategie by měla být přizpůsobena platformě. Vydavatel zaměřený na ChatGPT by měl tvořit autoritativní, komplexní články se silnými autorizačními údaji. Pro Google AI Overviews je třeba kombinovat schéma článku se strategiemi distribuce a komunitního zapojení. Pro Perplexity je vhodné zaměřit se na obsah odpovídající na konkrétní komunitní dotazy.
Ověření a monitoring schématu článku
Po implementaci schématu článku je zásadní ověření správnosti a úplnosti označení. Google Rich Results Test je hlavní validační nástroj, který umožňuje vložit URL nebo kód a okamžitě získat zpětnou vazbu k implementaci schématu. Identifikuje kritické chyby bránící zobrazení zvýrazněných výsledků i méně závažné problémy snižující účinnost schématu.
Schema Markup Validator (validator.schema.org) nabízí alternativní způsob kontroly, porovnávající vaše označení s oficiální specifikací Schema.org. Tento nástroj je užitečný pro odhalení subtilních chyb nebo zastaralých vlastností, které by v Google nástroji nemusely být označeny.
Google Search Console poskytuje průběžný monitoring výkonu vašeho schématu článku. V sekci „Vylepšení“ vidíte, kolik vašich stránek má platné schéma článku a zda byly detekovány chyby. Tento report je klíčový pro odhalení stránek, které mohly o označení přijít v důsledku aktualizací webu nebo technických problémů.
Nad rámec validace by měli vydavatelé sledovat reálný výkon AI citací pomocí nástrojů jako AmICited, které sledují zmínky a citace značky napříč ChatGPT, Perplexity, Google AI Overviews a Claude. Porovnáním implementace schématu článku s frekvencí citací lze měřit skutečnou návratnost investice do schématu a odhalit příležitosti ke zlepšení.
Budoucí vývoj schématu článku
Schéma článku se dále vyvíjí spolu s tím, jak se AI systémy zdokonalují a vznikají nové standardy. Model Context Protocol (MCP) a Natural Language Web (NLWeb) představují nové standardy, které staví na základech Schema.org a umožňují lepší interoperabilitu AI systémů. Tyto protokoly využívají strukturovaná data jako schéma článku za základ, což činí správnou implementaci dnes klíčovou pro budoucí kompatibilitu.
Jak budou AI systémy stále důležitější při objevování obsahu, schéma článku se pravděpodobně stane stejně zásadní jako tradiční SEO. Vydavatelé, kteří dnes implementují komplexní a přesné schéma článku, získají významnou výhodu s růstem AI vyhledávání. Přechod od vyhledávání podle klíčových slov k AI-generovaným odpovědím znamená zásadní změnu v tom, jak je obsah objevován, a schéma článku je mostem mezi tradičním webovým obsahem a tímto novým paradigmatu objevování.
Navíc, jak roste význam E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) jak pro tradiční vyhledávání, tak pro AI systémy, bude úloha schématu článku při prokazování autority autora a důvěryhodnosti obsahu ještě zásadnější. Lze očekávat, že budoucí aktualizace schématu článku přinesou další vlastnosti pro prokazování odbornosti a budování důvěryhodných signálů, které budou AI systémy schopny vyhodnocovat.
Klíčové body k implementaci schématu článku
Schéma článku je nezbytné pro AI viditelnost: S více než 680 miliony citací napříč hlavními AI platformami má správná implementace schématu článku přímý dopad na to, zda se váš obsah objeví v AI-generovaných odpovědích.
Implementujte kompletní metadata: Zahrňte vlastnosti headline, image (více poměrů stran), datePublished, dateModified, author a articleBody pro maximální efektivitu.
Používejte formát JSON-LD: JSON-LD je doporučený všemi hlavními vyhledávači i AI platformami a nabízí lepší údržbu i přesnost než alternativní formáty.
Propojujte schéma s dalšími entitami: Vytvářejte datový graf propojením článků s autory, vydavateli a souvisejícím obsahem, což AI systémům pomáhá chápat autoritu a kontext obsahu.
Sledujte reálný výkon AI citací: Využívejte nástroje jako AmICited, abyste zjistili, jak vaše implementace schématu článku ovlivňuje viditelnost značky napříč ChatGPT, Perplexity, Google AI Overviews a Claude.
Udržujte konzistenci na celém webu: Používejte konzistentní jména autorů, údaje o vydavateli a formáty URL, aby AI systémy mohly rozpoznat a budovat autoritativní signály v čase.
Pravidelně ověřujte a monitorujte: Používejte Google Rich Results Test a Search Console pro kontrolu platnosti schématu článku a identifikaci případných problémů s implementací.