
Co je MUM a jak ovlivňuje AI vyhledávání?
Zjistěte více o Google Multitask Unified Model (MUM) a jeho dopadu na AI výsledky vyhledávání. Pochopte, jak MUM zpracovává složité dotazy napříč různými formát...
8 min čtení
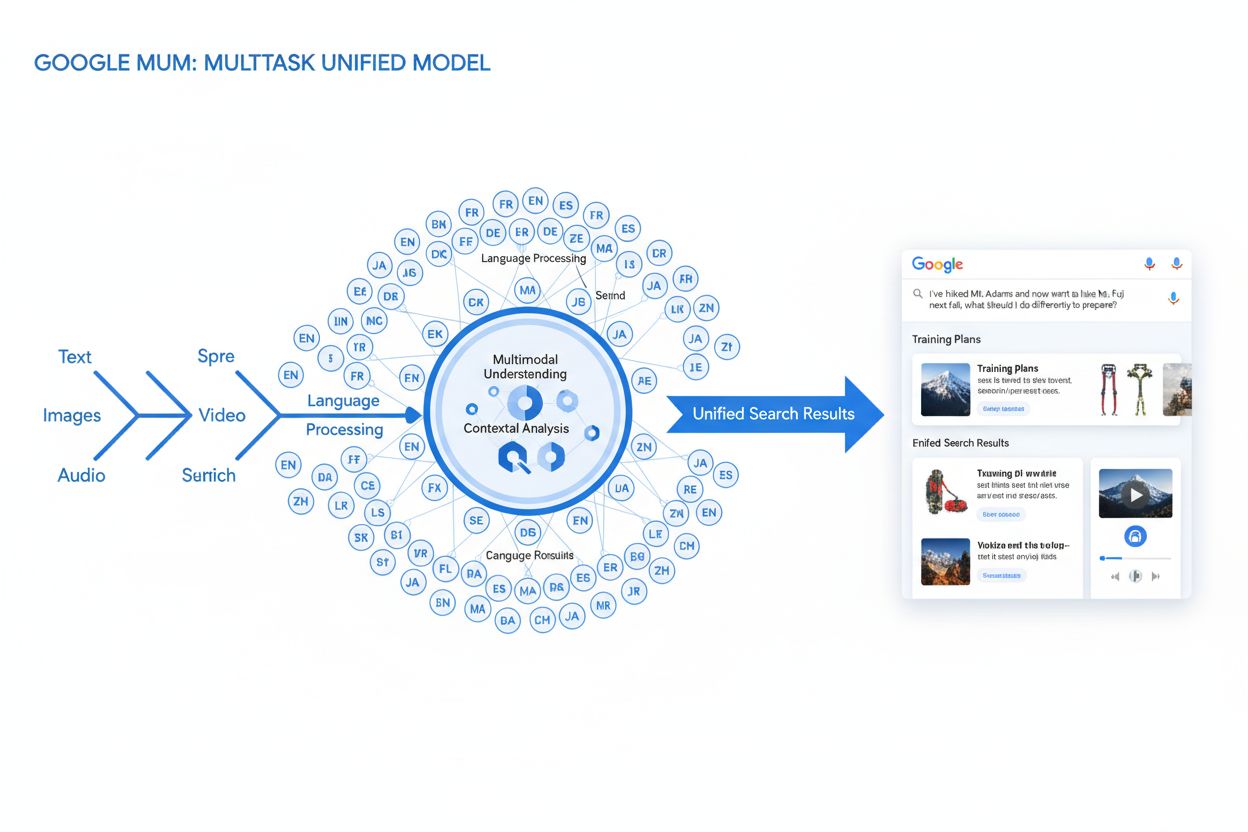
MUM (Multitask Unified Model) je pokročilý multimodální AI model od Googlu, který současně zpracovává text, obrázky, video a audio ve více než 75 jazycích, aby poskytoval komplexnější a kontextuálnější výsledky vyhledávání. Uveden v roce 2021, MUM je 1 000× výkonnější než BERT a znamená zásadní změnu v tom, jak vyhledávače rozumí a reagují na složité uživatelské dotazy.
MUM (Multitask Unified Model) je pokročilý multimodální AI model od Googlu, který současně zpracovává text, obrázky, video a audio ve více než 75 jazycích, aby poskytoval komplexnější a kontextuálnější výsledky vyhledávání. Uveden v roce 2021, MUM je 1 000× výkonnější než BERT a znamená zásadní změnu v tom, jak vyhledávače rozumí a reagují na složité uživatelské dotazy.
MUM (Multitask Unified Model) je pokročilý multimodální model umělé inteligence od Googlu, navržený s cílem zásadně proměnit způsob, jakým vyhledávače rozumějí a reagují na složité uživatelské dotazy. Ohlášen v květnu 2021 Pandu Nayakem, Google Fellow a viceprezidentem vyhledávání, MUM představuje zásadní posun v technologii vyhledávání informací. Je postaven na frameworku T5 text-to-text a obsahuje přibližně 110 miliard parametrů, což činí MUM 1 000× výkonnějším než BERT, předchozí průlomový model zpracování přirozeného jazyka od Googlu. Na rozdíl od tradičních vyhledávacích algoritmů, které zpracovávají text izolovaně, MUM současně zpracovává text, obrázky, video a audio a rozumí informacím nativně ve více než 75 jazycích. Tato multimodální a vícejazyčná schopnost umožňuje MUM chápat složité dotazy, které dříve vyžadovaly několik samostatných vyhledávání, a mění vyhledávání ze cvičení zaměřeného na klíčová slova na inteligentní, kontextově uvědomělý systém vyhledávání informací. MUM jazyk nejen rozumí, ale také jej generuje, což mu umožňuje syntetizovat informace z různých zdrojů a formátů a poskytovat komplexní a nuancované odpovědi, které pokrývají celou šíři uživatelského záměru.
Cesta Googlu k MUM představuje roky postupných inovací v oblasti zpracování přirozeného jazyka a strojového učení. Vývoj začal s Hummingbirdem (2013), který zavedl sémantické porozumění pro interpretaci významu dotazů namísto pouhého párování klíčových slov. Následoval RankBrain (2015), využívající strojového učení k pochopení long-tail klíčových slov a nových vyhledávacích vzorců. Neural Matching (2018) posunul tento vývoj dále použitím neuronových sítí k hlubšímu sémantickému párování dotazů s relevantním obsahem. BERT (Bidirectional Encoder Representations from Transformers), spuštěný v roce 2019, znamenal zásadní milník tím, že umožnil rozumět kontextu ve větách a odstavcích a zlepšil schopnost Googlu interpretovat nuancovaný jazyk. BERT však měl významná omezení—zpracovával pouze text, měl omezenou vícejazyčnou podporu a nedokázal řešit komplexní dotazy vyžadující syntézu informací napříč formáty. Podle výzkumu Googlu uživatelé zadávají v průměru osm samostatných dotazů, aby odpověděli na složité otázky, například při porovnávání dvou turistických destinací nebo výběru produktů. Tato statistika poukazovala na zásadní mezeru ve vyhledávací technologii, kterou měl MUM konkrétně řešit. Helpful Content Update (2022) a framework E-E-A-T (2023) dále upřesnily, jak Google upřednostňuje autoritativní a důvěryhodný obsah. MUM staví na všech těchto inovacích a zároveň zavádí schopnosti, které překonávají předchozí omezení, což znamená nejen postupné zlepšení, ale i zásadní změnu v tom, jak vyhledávače zpracovávají a doručují informace.
Technický základ MUM spočívá v architektuře Transformer, konkrétně ve frameworku T5 (Text-to-Text Transfer Transformer), který Google vyvinul dříve. Framework T5 považuje všechny úkoly zpracování přirozeného jazyka za text-to-text problémy, převádí vstupy i výstupy do jednotných textových reprezentací. MUM rozšiřuje tento přístup zavedením schopností multimodálního zpracování, což mu umožňuje současně pracovat s textem, obrázky, videem i audiem v rámci jednoho modelu. Toto architektonické rozhodnutí je zásadní, protože umožňuje MUM chápat vztahy a kontext napříč různými typy médií způsoby, které předchozí modely nedokázaly. Například při zpracování dotazu na turistiku na Mt. Fuji v kombinaci s obrázkem konkrétních trekových bot MUM neanalyzuje text a obrázek odděleně—zpracuje je společně a chápe, jak vlastnosti bot souvisejí s kontextem dotazu. Model s 110 miliardami parametrů mu umožňuje uchovávat a zpracovávat obrovské množství znalostí o jazyce, vizuálních konceptech a jejich vztazích. MUM je trénován ve 75 různých jazycích a na mnoha úkolech současně, což mu umožňuje rozvíjet komplexnější porozumění informacím a světovým znalostem než modely trénované na jednom jazyce nebo úkolu. Tento multitaskový přístup znamená, že MUM se učí rozpoznávat vzory a vztahy, které lze přenášet mezi jazyky i doménami, což z něj činí robustnější a obecnější model než jeho předchůdci. Současné zpracování více jazyků během tréninku umožňuje MUM provádět přenos znalostí mezi jazyky, což znamená, že dokáže rozumět informacím napsaným v jednom jazyce a aplikovat toto porozumění na dotazy v jiném jazyce, čímž efektivně odstraňuje jazykové bariéry, které dříve omezovaly vyhledávací výsledky.
| Atribut | MUM (2021) | BERT (2019) | RankBrain (2015) | Framework T5 |
|---|---|---|---|---|
| Hlavní funkce | Multimodální porozumění dotazům a syntéza odpovědí | Kontextové porozumění textu | Interpretace long-tail klíčových slov | Text-to-text transfer learning |
| Vstupní modality | Text, obrázky, video, audio | Pouze text | Pouze text | Pouze text |
| Podpora jazyků | Nativně 75+ jazyků | Omezená vícejazyčná podpora | Převážně angličtina | Převážně angličtina |
| Počet parametrů | ~110 miliard | ~340 milionů | Neuvedeno | ~220 milionů |
| Porovnání výkonu | 1 000× výkonnější než BERT | Základ | Předchůdce BERT | Základ pro MUM |
| Schopnosti | Porozumění + generování | Pouze porozumění | Rozpoznávání vzorů | Transformace textu |
| Dopad na SERP | Obohacené výsledky v různých formátech | Lepší úryvky a kontext | Vyšší relevance | Základní technologie |
| Zvládání složitých dotazů | Složité vícestupňové dotazy | Kontext v jednom dotazu | Variace long-tail | Úlohy transformace textu |
| Přenos znalostí | Mezi jazyky i modalitami | Pouze uvnitř jazyka | Omezený přenos | Přenos mezi úlohami |
| Reálné použití | Google Search, AI Overviews | Hodnocení ve vyhledávači Google | Hodnocení ve vyhledávači Google | Technický základ MUM |
Zpracování dotazů v MUM zahrnuje několik sofistikovaných kroků, které společně umožňují poskytovat komplexní a kontextuální odpovědi. Když uživatel zadá vyhledávací dotaz, MUM nejprve provede jazykově nezávislé předzpracování, tedy rozumí dotazu v kterémkoli z podporovaných jazyků bez nutnosti překladu. Toto nativní porozumění jazyku zachovává jazykové nuance a regionální kontext, které by se při překladu mohly ztratit. Následně MUM využívá sekvenční párování, analyzuje celý dotaz jako sled významů místo izolovaných klíčových slov. Tento přístup umožňuje MUM chápat vztahy mezi koncepty—například rozpoznat, že dotaz typu „příprava na Mt. Fuji po výstupu na Mt. Adams“ zahrnuje porovnání, přípravu a kontextovou adaptaci. Současně MUM provádí analýzu multimodálních vstupů, zpracovává obrázky, videa nebo jiná média připojená k dotazu. Model pak zapojuje paralelní zpracování dotazu, kdy vyhodnocuje více možných uživatelských záměrů najednou místo omezení na jediný výklad. To znamená, že MUM může rozpoznat, že dotaz na túru na Mt. Fuji může souviset s fyzickou přípravou, výběrem vybavení, kulturními zážitky či cestovní logistikou—a nabídne informace pro všechny tyto interpretace. Sémantické porozumění založené na vektorech převádí dotaz i indexovaný obsah do vícerozměrných vektorů reprezentujících sémantický význam, což umožňuje vyhledávání na základě konceptuální podobnosti, nikoli jen shody klíčových slov. MUM pak aplikuje filtrování obsahu prostřednictvím přenosu znalostí, využívá strojové učení trénované na vyhledávacích protokolech, datech o prohlížení a vzorcích chování uživatelů k upřednostnění kvalitních a autoritativních zdrojů. Nakonec MUM generuje multimediální obohacenou kompozici SERP, která kombinuje textové úryvky, obrázky, videa, související otázky a interaktivní prvky do jednoho vizuálně vrstveného vyhledávacího zážitku. Celý tento proces probíhá během milisekund a umožňuje MUM doručovat výsledky, které řeší nejen explicitní dotaz, ale i očekávané následné otázky a související informační potřeby.
Multimodální schopnosti MUM znamenají zásadní odklon od systémů vyhledávání založených jen na textu. Model může současně zpracovávat a chápat informace z textu, obrázků, videa i audia, získávat význam z každé modality a syntetizovat jej do ucelených odpovědí. Tato schopnost je mimořádně silná pro dotazy, které těží z vizuálního kontextu. Například pokud se uživatel zeptá „Mohou tyto trekové boty na Mt. Fuji?“ a ukáže obrázek svých bot, MUM porozumí vlastnostem bot z obrázku—materiál, vzorek podrážky, výška, barva—a spojí toto vizuální pochopení se znalostmi o terénu, klimatu a požadavcích na túru na Mt. Fuji, aby poskytl kontextuální odpověď. Vícejazyčný rozměr MUM je stejně převratný. Díky nativní podpoře více než 75 jazyků může MUM provádět přenos znalostí mezi jazyky, což znamená, že se učí ze zdrojů v jednom jazyce a aplikuje tyto znalosti na dotazy v jiném jazyce. Tím překonává zásadní bariéru, která dříve omezovala výsledky vyhledávání na obsah v rodném jazyce uživatele. Pokud jsou komplexní informace o Mt. Fuji především v japonských zdrojích—včetně místních turistických průvodců, sezónních klimatických údajů a kulturních poznatků—MUM tento japonsky psaný obsah pochopí a zobrazí relevantní informace uživatelům v angličtině. Podle testování Googlu MUM dokázal uvést 800 variant vakcín proti COVID-19 ve více než 50 jazycích během několika sekund, což ilustruje rozsah a rychlost jeho vícejazyčného zpracování. Toto vícejazyčné porozumění je zvláště cenné pro uživatele na netradičních trzích a pro dotazy na témata s bohatými informacemi ve více jazycích. Kombinace multimodálního a vícejazyčného zpracování znamená, že MUM dokáže zobrazovat nejrelevantnější informace bez ohledu na formát či původní jazyk, v němž byly publikovány, a vytváří tak skutečně globální vyhledávací zážitek.
MUM zásadně mění způsob, jakým jsou výsledky vyhledávání zobrazovány a jak je uživatelé vnímají. Místo tradičního seznamu modrých odkazů, který dominoval vyhledávání po desetiletí, vytváří MUM obohacené, interaktivní SERPy, které kombinují různé formáty obsahu na jedné stránce. Uživatelé nyní mohou vidět textové úryvky, obrázky ve vysokém rozlišení, video karusely, související otázky i interaktivní prvky, aniž by opustili stránku s výsledky. Tento posun má zásadní dopady na způsob, jak uživatelé s vyhledáváním pracují. Místo několika samostatných hledání k získání informací o složitém tématu mohou uživatelé prozkoumat různé úhly pohledu a dílčí témata přímo v SERPu. Například dotaz „příprava na Mt. Fuji na podzim“ může zobrazit srovnání nadmořských výšek, předpovědi počasí, doporučení vybavení, videoprůvodce a uživatelské recenze—vše smysluplně uspořádané na jedné stránce. Integrace Google Lens poháněná MUM umožňuje uživatelům vyhledávat pomocí obrázků místo klíčových slov, takže i vizuální prvky na fotografiích se stávají interaktivními nástroji pro objevování. Panely „Věci, které byste měli vědět“ rozdělují složité dotazy do stravitelných dílčích témat a vedou uživatele různými aspekty tématu s relevantními úryvky ke každému. Obrázky ve vysokém rozlišení s možností přiblížení se objevují přímo ve výsledcích, což umožňuje vizuální porovnání a usnadňuje rozhodování už v raných fázích. Funkce „Upřesnit a rozšířit“ navrhuje související koncepty, které uživatelům umožňují buď jít více do hloubky, nebo prozkoumat příbuzná témata. Tyto změny znamenají posun od vyhledávání jako jednoduchého nástroje k získávání informací k interaktivnímu, objevovacímu zážitku, který předjímá potřeby uživatele a poskytuje komplexní informace přímo ve vyhledávacím rozhraní. Výzkumy ukazují, že tato bohatší podoba SERPu snižuje průměrný počet hledání potřebných k zodpovězení složitých otázek, i když to také znamená, že uživatelé mohou spotřebovávat informace přímo ve výsledcích, aniž by přecházeli na webové stránky.
Pro organizace, které sledují svou přítomnost napříč AI systémy, znamená MUM zásadní posun v tom, jak jsou informace objevovány a zobrazovány. Jak se MUM stále více integruje do Vyhledávání Google a ovlivňuje další AI systémy, je zásadní pochopit, jak se značky a domény objevují ve výsledcích poháněných MUM, aby si zachovaly viditelnost. Multimodální zpracování MUM znamená, že značky musí optimalizovat napříč formáty obsahu, nejen pro text. Značka, která se dříve spoléhala na umístění na konkrétní klíčová slova, musí nyní zajistit, že je její obsah objevitelný skrze obrázky, videa i strukturovaná data. Schopnost modelu syntetizovat informace z různých zdrojů znamená, že viditelnost značky závisí nejen na vlastních webových stránkách, ale i na tom, jak jsou její informace prezentovány v širším webovém ekosystému. Vícejazyčné schopnosti MUM přinášejí globálním značkám nové příležitosti i výzvy. Obsah publikovaný v jednom jazyce může být nyní objevitelný uživateli hledajícími v jiných jazycích, což rozšiřuje potenciální dosah. Zároveň však musí značky dbát na to, aby jejich informace byly přesné a konzistentní ve všech jazykových variantách, protože MUM může pro jeden dotaz zobrazit informace z více jazykových zdrojů. Pro AI monitorovací platformy jako AmICited je sledování vlivu MUM klíčové, protože ukazuje, jak moderní AI systémy získávají a prezentují informace. Při monitoringu, kde se značka objevuje v AI odpovědích—ať už v Google AI Overviews, Perplexity, ChatGPT nebo Claude—pomáhá porozumění technologii MUM vysvětlit, proč se určitý obsah zobrazuje a jak optimalizovat svou viditelnost. Posun k multimodálnímu, vícejazyčnému vyhledávání znamená, že značky potřebují komplexní monitoring, který sleduje jejich přítomnost napříč různými formáty a jazyky, nejen tradiční pořadí klíčových slov. Organizace, které porozumí schopnostem MUM, mohou lépe optimalizovat svou obsahovou strategii a zajistit si viditelnost v novém vyhledávacím prostředí.
I když MUM znamená významný pokrok, přináší také nové výzvy a omezení, se kterými se organizace musí vypořádat. Nižší míra prokliků je zásadní obavou vydavatelů a tvůrců obsahu, protože uživatelé mohou nyní konzumovat komplexní informace přímo ve výsledcích, aniž by přešli na web. Tento posun znamená, že tradiční metriky návštěvnosti jsou méně spolehlivým ukazatelem úspěchu obsahu. Vyšší technické požadavky na SEO znamenají, že aby byl obsah správně pochopen MUM, musí být dobře strukturovaný s odpovídajícím schema markup, sémantickým HTML a jasnými entitními vztahy. Obsah bez této technické základny nemusí být MUM správně indexován nebo pochopen. Saturace SERPu znamená těžší boj o viditelnost, protože více formátů soutěží o pozornost na jedné stránce. I kvalitní obsah může získat méně či žádné prokliky, pokud uživatel najde dost informací přímo v SERPu. Riziko zavádějících výsledků hrozí tam, kde MUM zobrazí informace z různých zdrojů, které si mohou protiřečit, nebo kde se při syntéze ztratí kontext. Závislost na strukturovaných datech znamená, že nestrukturovaný či špatně formátovaný obsah nemusí být MUM správně pochopen nebo zobrazen. Výzvy s jazykovými a kulturními nuancemi mohou vzniknout při přenosu znalostí mezi jazyky, což může vést k opomenutí kulturního kontextu či regionálních významových rozdílů. Požadavky na výpočetní zdroje pro provoz MUM v masovém měřítku jsou značné, i když Google investuje do zvyšování efektivity a snižování uhlíkové stopy. Obavy z biasu a férovosti vyžadují průběžnou pozornost, aby MUM nepřenášel předsudky z trénovacích dat nebo neznevýhodňoval určité perspektivy či komunity.
Vznik MUM vyžaduje zásadní změny v přístupu k SEO a obsahové strategii. Tradiční optimalizace zaměřená na klíčová slova ztrácí na účinnosti, když MUM rozumí záměru a kontextu i mimo přesné shody klíčových slov. Strategie založená na tématech je důležitější než ta založená na klíčových slovech, organizace musí vytvářet komplexní obsahové clustery, které téma pokryjí z více úhlů. Tvorba multimediálního obsahu už není volitelná—organizace musí investovat do kvalitních obrázků, videí i interaktivního obsahu, který doplňuje text. Implementace strukturovaných dat je zásadní, protože schema markup pomáhá MUM pochopit strukturu a vztahy v obsahu. Budování entit a sémantická optimalizace
Zatímco BERT (2019) se zaměřoval na porozumění přirozenému jazyku v textových dotazech, MUM představuje významnou evoluci. MUM je postaven na frameworku T5 text-to-text a je 1 000× výkonnější než BERT. Na rozdíl od BERT, který zpracovával pouze text, je MUM multimodální—současně zpracovává text, obrázky, video i audio. Navíc MUM nativně podporuje více než 75 jazyků, zatímco BERT měl při spuštění omezenou vícejazyčnou podporu. MUM dokáže jazyk nejen chápat, ale i generovat, což mu umožňuje zvládat složité, vícestupňové dotazy, které BERT efektivně řešit nedokázal.
Multimodální znamená schopnost MUM zpracovávat a chápat informace z více typů vstupních formátů současně. Místo toho, aby analyzoval text odděleně od obrázků nebo videa, MUM zpracovává všechny tyto formáty dohromady jednotným způsobem. To znamená, že když například hledáte "trekové boty na Mt. Fuji", MUM rozumí vašemu textovému dotazu, analyzuje obrázky bot, zhlédne videorecenze a získá audio popisy—vše najednou. Tento integrovaný přístup umožňuje MUM poskytovat bohatší, více kontextuální odpovědi, které berou v úvahu informace ze všech těchto různých médií.
MUM je trénován ve více než 75 jazycích, což je zásadní posun v globální dostupnosti vyhledávání. Tato vícejazyčná schopnost znamená, že MUM může přenášet znalosti mezi jazyky—pokud jsou užitečné informace o tématu v japonštině, MUM je pochopí a nabídne relevantní výsledky uživatelům v angličtině. Tím odstraňuje jazykové bariéry, které dříve omezovaly výsledky vyhledávání na obsah v rodném jazyce uživatele. Pro značky a tvůrce obsahu to znamená potenciální viditelnost napříč více jazykovými trhy a uživatelé po celém světě mají přístup k informacím bez ohledu na jazyk původní publikace.
T5 (Text-to-Text Transfer Transformer) je starší model od Googlu založený na transformerech, na kterém MUM staví. Framework T5 považuje všechny NLP úkoly za text-to-text problémy, tedy převádí vstupy i výstupy do textového formátu pro jednotné zpracování. MUM rozšiřuje možnosti T5 tím, že zavádí multimodální zpracování (práce s obrázky, videem a audiem) a škáluje model na přibližně 110 miliard parametrů. Toto základem umožňuje MUM nejen rozumět, ale i generovat jazyk při zachování efektivity a flexibility, díky nimž byl T5 úspěšný.
MUM zásadně mění způsob, jakým je obsah vyhledáván a zobrazován ve výsledcích hledání. Místo tradičních seznamů modrých odkazů vytváří MUM obohacené SERPy s více formáty obsahu—obrázky, videa, textové úryvky a interaktivní prvky—vše na jedné stránce. To znamená, že značky musí optimalizovat napříč různými formáty, nejen pro text. Obsah, který dříve vyžadoval proklik na více stránek, se může nyní objevit přímo ve výsledcích vyhledávání. Zároveň to však znamená nižší míru prokliků u některého obsahu, protože uživatelé mohou informace spotřebovat přímo na SERPu. Značky se nyní musí soustředit na viditelnost v rámci výsledků vyhledávání a zajistit, že jejich obsah je strukturovaný pomocí schema markup tak, aby ho MUM správně pochopil.
MUM je zásadní pro AI monitorovací platformy, protože představuje, jak moderní AI systémy rozumí a získávají informace. Jak se MUM stává běžnější součástí Vyhledávání Google a ovlivňuje další AI systémy, je sledování, kde se značky a domény objevují ve výsledcích poháněných MUM, klíčové. AmICited sleduje, jak jsou značky citovány a zobrazovány napříč AI systémy včetně vyhledávání vylepšeného MUM od Googlu. Porozumění multimodálním a vícejazyčným schopnostem MUM pomáhá organizacím optimalizovat svou přítomnost v různých formátech a jazycích, aby byly viditelné, když AI systémy jako MUM vyhledávají a zobrazují jejich informace uživatelům.
Ano, MUM dokáže zpracovávat obrázky a video se sofistikovaným porozuměním. Když nahrajete obrázek nebo zahrnete video do dotazu, MUM nerozpoznává jen objekty—extrahuje kontext, význam i vztahy. Například když MUM ukážete fotografii trekových bot a zeptáte se "mohu je použít na Mt. Fuji?", MUM chápe vlastnosti bot z obrázku a propojí toto pochopení s vaším dotazem, aby poskytl kontextuální odpověď. Tato multimodální schopnost je jednou z nejsilnějších předností MUM, která mu umožňuje odpovídat na otázky vyžadující vizuální porozumění v kombinaci s textovými znalostmi.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Zjistěte více o Google Multitask Unified Model (MUM) a jeho dopadu na AI výsledky vyhledávání. Pochopte, jak MUM zpracovává složité dotazy napříč různými formát...
Diskuse komunity vysvětlující Google MUM a jeho dopad na AI vyhledávání. Odborníci sdílejí, jak tento multimodální AI model ovlivňuje optimalizaci obsahu a vidi...

Ovládněte optimalizaci multimodálního AI vyhledávání. Naučte se, jak optimalizovat obrázky a hlasové dotazy pro výsledky vyhledávání poháněné AI, včetně strateg...