
Jak sémantické porozumění ovlivňuje citace umělé inteligence
Zjistěte, jak sémantické porozumění ovlivňuje přesnost citací, přiřazování zdrojů a důvěryhodnost obsahu generovaného umělou inteligencí. Objevte roli analýzy k...
9 min čtení

Sémantická podobnost je výpočetní metrika, která měří významovou příbuznost mezi texty analýzou jejich pojmového obsahu místo přesné shody slov. Využívá vektorová zapouzdření a matematické metriky vzdálenosti k vyjádření toho, jak blízko si dva texty významově stojí, což umožňuje AI systémům chápat kontextové vztahy nad rámec povrchového porovnání klíčových slov.
Sémantická podobnost je výpočetní metrika, která měří významovou příbuznost mezi texty analýzou jejich pojmového obsahu místo přesné shody slov. Využívá vektorová zapouzdření a matematické metriky vzdálenosti k vyjádření toho, jak blízko si dva texty významově stojí, což umožňuje AI systémům chápat kontextové vztahy nad rámec povrchového porovnání klíčových slov.
Sémantická podobnost je výpočetní měřítko, které kvantifikuje významovou příbuznost mezi dvěma nebo více texty analýzou jejich pojmového obsahu, kontextových vztahů a hlubšího sémantického významu namísto spoléhání na přesné shody slov či povrchovou překryvnost klíčových slov. Na rozdíl od tradičních přístupů založených na klíčových slovech, které identifikují pouze texty se shodnou slovní zásobou, sémantická podobnost využívá pokročilé matematické modely a vektorová zapouzdření k pochopení toho, zda různé texty sdělují ekvivalentní nebo příbuzné významy, i když jsou vyjádřeny zcela odlišnými slovy či formulacemi. Tato schopnost se stala zásadní pro moderní systémy umělé inteligence, které tak mohou chápat lidský jazyk s nuancemi a kontextovým povědomím. Měření sémantické podobnosti se obvykle pohybuje od -1 do 1 (nebo 0 až 1 podle použité metriky), přičemž vyšší hodnoty znamenají vyšší sémantickou příbuznost mezi porovnávanými texty.
Myšlenka měření sémantických vztahů v textu pochází z raného výzkumu počítačové lingvistiky v 60. a 70. letech, ale praktické implementace byly omezené až do nástupu word embeddings v roce 2010. Zavedení Word2Vec výzkumníky Google v roce 2013 způsobilo revoluci v oboru tím, že ukázalo, že slova lze reprezentovat jako husté vektory ve vícerozměrném prostoru, kde se sémantické vztahy projevují jako geometrická blízkost. Tento průlom umožnil opustit symbolickou reprezentaci a využít sílu neuronových sítí pro uchopení sémantického významu. Následný vývoj GloVe (Global Vectors for Word Representation) výzkumníky ze Stanfordu nabídl alternativní přístup využívající statistiku společného výskytu, zatímco FastText tyto koncepty rozšířil na jazyky s bohatou morfologií a slova mimo slovník. Skutečnou transformaci přinesl BERT (Bidirectional Encoder Representations from Transformers) v roce 2018, který generoval kontextualizovaná zapouzdření chápající význam slov dle okolního kontextu. Dnes více než 78 % podniků využívá AI řešení, přičemž sémantická podobnost je klíčovou součástí monitorování obsahu, sledování značky a analýzy AI odpovědí na platformách jako ChatGPT, Perplexity, Google AI Overviews a Claude.
Sémantická podobnost funguje prostřednictvím vícestupňového procesu, který začíná reprezentací textu a končí číselným skórováním podobnosti. Prvním krokem je tokenizace, kdy je vstupní text rozdělen na zvládnutelné jednotky (slova, podslova nebo znaky), které může neuronová síť zpracovat. Tyto tokeny se následně převádějí na zapouzdření—vícerozměrné číselné vektory obvykle v rozsahu od 300 do 1 536 rozměrů—pomocí předtrénovaných jazykových modelů. Modely jako Sentence Transformers a SimCSE (Simple Contrastive Learning of Sentence Embeddings) jsou navrženy tak, aby generovaly zapouzdření, kde sémantická podobnost přímo koreluje s geometrickou blízkostí ve vektorovém prostoru. Jakmile jsou zapouzdření vytvořena, metriky podobnosti kvantifikují vztah mezi vektory. Kosinová podobnost, nejrozšířenější metrika v NLP aplikacích, počítá úhel mezi dvěma vektory podle vzorce: cos(θ) = (A · B) / (||A|| × ||B||), přičemž výsledek se pohybuje od -1 do 1. Eukleidovská vzdálenost měří přímou vzdálenost mezi vektory ve vícerozměrném prostoru, zatímco podobnost skalárním součinem zohledňuje směr i velikost vektoru. Volba metriky závisí na způsobu trénování zapouzdřovacího modelu—použití stejné metriky jako při tréninku zajišťuje optimální výkon. Například modely Sentence Transformers trénované s kosinovou podobností by při inferenci měly využívat kosinovou podobnost, zatímco modely trénované na skalární součin mají používat jeho skórování.
| Přístup/metrika | Dimenzionalita | Trénovací metoda | Nejlepší využití | Výpočetní náročnost | Kontextová citlivost |
|---|---|---|---|---|---|
| Word2Vec | 300-600 | Skip-gram/CBOW | Podobnost na úrovni slov, základní NLP | Nízká | Omezená (statická zapouzdření) |
| GloVe | 300-600 | Faktorizace matice společného výskytu | Obecná zapouzdření slov, sémantické vztahy | Střední | Omezená (statická zapouzdření) |
| FastText | 300-600 | N-gramy podslov | Jazyky s bohatou morfologií, OOV slova | Nízká-střední | Omezená (statická zapouzdření) |
| BERT | 768-1024 | Maskované jazykové modelování, obousměrné | Úlohy na úrovni tokenů, klasifikace | Vysoká | Vysoká (závislá na kontextu) |
| Sentence Transformers (SBERT) | 384-768 | Siamese networks, triplet loss | Podobnost vět, sémantické vyhledání | Střední | Vysoká (na úrovni vět) |
| SimCSE | 768 | Kontrastivní učení | Detekce parafrází, shlukování | Střední | Vysoká (kontrastivní) |
| Universal Sentence Encoder | 512 | Multitask learning | Mezilingvální podobnost, rychlé nasazení | Střední | Vysoká (na úrovni vět) |
| Kosinová podobnost | N/A | Na základě úhlu | NLP úlohy, normalizovaná zapouzdření | Velmi nízká | N/A (pouze metrika) |
| Eukleidovská vzdálenost | N/A | Na základě vzdálenosti | Úlohy citlivé na velikost, pixelová data | Velmi nízká | N/A (pouze metrika) |
| Podobnost skalárním součinem | N/A | Směr a velikost | Modely trénované LLM, úlohy řazení | Velmi nízká | N/A (pouze metrika) |
Základem sémantické podobnosti je pojem vektorových zapouzdření, která převádějí text do číselných reprezentací zachovávajících sémantický význam prostřednictvím geometrických vztahů. Když jazykový model generuje zapouzdření pro kolekci textů, sémanticky podobné texty se ve výsledném vektorovém prostoru přirozeně shlukují, zatímco odlišné texty zůstávají vzdálené. Tento jev, známý jako sémantické shlukování, vzniká při trénování modelů, které se učí umisťovat vektory tak, aby podobné významy zabíraly blízké oblasti. Sentence Transformers např. generují zapouzdření o 384 až 768 rozměrech optimalizovaných přímo pro úlohy podobnosti vět, což umožňuje zpracovat přes 40 000 vět za sekundu při zachování vysoké přesnosti. Kvalita zapouzdření přímo ovlivňuje výkon sémantické podobnosti—modely trénované na rozmanitých, rozsáhlých datových sadách produkují robustnější zapouzdření, která se dobře generalizují napříč různými doménami a typy textů. Problém anizotropie v zapouzdření BERTu (kdy vektorová zapouzdření vět kolabují do úzkých kuželů, což činí kosinovou podobnost málo diskriminační) byl vyřešen Sentence Transformers, které jemně dolaďují transformerové modely pomocí kontrastivních a triplet loss funkcí, jež explicitně optimalizují sémantickou podobnost. Toto přeformování vektorového prostoru zajišťuje, že parafráze se těsně shlukují (skóre podobnosti nad 0,9), zatímco nesouvisející věty se jasně oddělují (skóre pod 0,3), což činí zapouzdření spolehlivými pro praktické aplikace.
Sémantická podobnost se stala nepostradatelnou pro AI monitorovací platformy, které sledují zmínky o značce, přisuzování obsahu a výskyty URL napříč různými AI systémy včetně ChatGPT, Perplexity, Google AI Overviews a Claude. Tradiční monitoring založený na klíčových slovech nedokáže odhalit parafrázované odkazy, kontextově související zmínky ani významově ekvivalentní citace—mezery, které sémantická podobnost dokonale vyplňuje. Když uživatel položí AI systému dotaz týkající se vaší značky, AI může generovat odpovědi odkazující na váš obsah, konkurenty nebo oborové poznatky, aniž by použila přesné názvy značek či URL. Algoritmy sémantické podobnosti umožňují monitorovacím platformám identifikovat tyto implicitní odkazy porovnáváním sémantického obsahu AI odpovědí s vaším známým obsahem, sdělením a pozicí značky. Například, pokud je vaše značka známá jako “řešení pro udržitelnou technologii”, sémantická podobnost odhalí, když AI odpověď hovoří o “ekologicky šetrných technologických inovacích” nebo “environmentálně uvědomělém výpočetnictví”, a rozpozná je jako významově ekvivalentní vaší značkové pozici. Tato schopnost sahá až k detekci duplicitního obsahu, kde sémantická podobnost identifikuje téměř shodné a parafrázované verze vašeho obsahu napříč AI platformami, což pomáhá prosazovat přisuzování obsahu a ochranu duševního vlastnictví. Podnikové nasazení monitoringu založeného na sémantické podobnosti výrazně zrychlilo, přičemž technologie vektorových databází (jež umožňuje sémantickou podobnost ve velkém) zaznamenala v roce 2024 nárůst produkčních nasazení o 377 %.
Sémantická podobnost přinesla revoluci do detekce plagiátorství a identifikace duplicitního obsahu tím, že překonala povrchové porovnání textů a analyzuje jejich hlubší význam. Tradiční systémy detekce plagiátorství se opírají o porovnávání řetězců nebo n-gramovou analýzu, což selhává při parafrázování, restrukturalizaci nebo překladu obsahu. Přístupy založené na sémantické podobnosti tyto limity překonávají porovnáváním pojmového obsahu dokumentů, což umožňuje zachytit plagiát i při podstatném přeformulování originálu. Systémy využívající Word2Vec zapouzdření dokážou identifikovat sémanticky podobné pasáže převodem dokumentů na vektorové reprezentace a výpočtem skóre podobnosti mezi všemi dvojicemi dokumentů. Pokročilejší systémy využívají Sentence Transformers nebo SimCSE pro detailní analýzu podobnosti na úrovni vět či odstavců, což umožňuje určit, které konkrétní části dokumentu jsou plagiovány nebo duplikovány. Výzkum ukazuje, že detekce plagiátorství založená na sémantické podobnosti dosahuje výrazně vyšší přesnosti než metody založené na klíčových slovech, zejména při detekci sofistikovaného plagiátorství zahrnujícího parafrázi, záměnu synonym a strukturální reorganizaci. V kontextu AI monitoringu umožňuje sémantická podobnost detekovat obsah, který byl parafrázován nebo shrnut AI systémy, což pomáhá značkám zjistit, kdy je jejich duševní vlastnictví citováno či odkazováno bez správného přisuzování. Schopnost detekovat sémantickou ekvivalenci místo přesné shody je zvláště cenná při odhalování téměř shodného obsahu napříč vícero AI platformami, kde mohou být stejné informace vyjádřeny různě podle tréninkových dat a generování AI systému.
Správný výběr metriky podobnosti je pro sémantické aplikace klíčový, protože různé metriky zdůrazňují různé aspekty vztahů mezi vektory. Kosinová podobnost, počítaná jako kosinus úhlu mezi dvěma vektory, je dominantní metrikou v NLP aplikacích, protože měří podobnost směru nezávisle na velikosti vektoru. Tato vlastnost činí kosinovou podobnost ideální pro porovnávání normalizovaných zapouzdření, kde velikost nenese žádnou sémantickou informaci. Hodnoty kosinové podobnosti se pohybují od -1 (opačné směry) do 1 (identické směry), 0 znamená kolmé vektory. V praxi skóre nad 0,7 typicky značí silnou sémantickou podobnost, zatímco skóre pod 0,3 naznačuje minimální sémantický vztah. Eukleidovská vzdálenost, přímá vzdálenost mezi vektory ve vícerozměrném prostoru, je vhodnější, když velikost vektoru nese význam—například v doporučovacích systémech, kde velikost uživatelského preference vektoru značí intenzitu zájmu. Podobnost skalárním součinem kombinuje směr a velikost, což se hodí pro modely trénované na loss funkcích založených na skalárním součinu, zejména velké jazykové modely. Manhattanská vzdálenost (součet absolutních rozdílů) je výpočetně efektivní alternativou eukleidovské vzdálenosti, ale v úlohách sémantické podobnosti se používá méně často. Výzkum ukazuje, že sladění metriky podobnosti se způsobem tréninku zapouzdřovacího modelu je klíčové—použití kosinové podobnosti s modelem trénovaným na skalární součin nebo naopak výrazně snižuje výkon. Tento princip je natolik zásadní, že je zakódován v konfiguračních souborech předtrénovaných modelů, aby uživatelé vždy aplikovali správnou metriku automaticky.
Sémantická podobnost pohání moderní doporučovací systémy tím, že umožňuje algoritmům identifikovat položky s podobným sémantickým obsahem, uživatelskými preferencemi nebo kontextovou relevancí. Narozdíl od kolaborativního filtrování, které spoléhá na vzorce uživatelského chování, doporučení na základě sémantické podobnosti analyzují skutečný obsah položek—popisy produktů, texty článků, uživatelské recenze—a vyhledávají sémanticky příbuzné doporučení. Například zpravodajský systém doporučující články na základě sémantické podobnosti může navrhovat texty s podobnými tématy, pohledy nebo okruhy, i když nesdílejí žádná klíčová slova či kategorie. Tento přístup výrazně zlepšuje kvalitu doporučení a umožňuje cold-start doporučení pro nové položky bez uživatelské historie. Ve vyhledávání informací umožňuje sémantická podobnost sémantické vyhledávání, při kterém vyhledávače rozumí významu uživatelských dotazů a vyhledávají dokumenty podle pojmové relevance, nikoli podle klíčových slov. Uživatel hledající “nejlepší místa na dovolenou v létě” dostane výsledky o populárních letních destinacích, ne pouze dokumenty obsahující přesně tato slova. Sémantické vyhledávání nabývá na významu s tím, jak AI systémy jako Perplexity a Google AI Overviews upřednostňují vyhledávání podle významu před porovnáváním klíčových slov. Implementace sémantického vyhledávání obvykle spočívá v zakódování všech dokumentů v korpusu do zapouzdření (jednorázový předzpracovací krok), následném zakódování uživatelských dotazů a výpočtu skóre podobnosti vůči zapouzdření dokumentů. Tento přístup umožňuje rychlé, škálovatelné vyhledávání i v milionech dokumentů, což činí sémantickou podobnost praktickou pro rozsáhlé aplikace. Vektorové databáze jako Pinecone, Weaviate a Milvus optimalizují ukládání a vyhledávání zapouzdření ve velkém, přičemž trh s vektorovými databázemi má do roku 2034 dosáhnout 17,91 miliardy dolarů.
Implementace sémantické podobnosti v podnikovém měřítku vyžaduje pečlivý výběr modelu, infrastruktury a metodologie vyhodnocování. Organizace si musí vybrat mezi předtrénovanými modely (které umožňují rychlé nasazení, ale nemusí zachytit doménově specifickou sémantiku) a jemně doladěnými modely (vyžadují označená data, ale dosahují lepších výsledků v konkrétních úlohách). Sentence Transformers poskytuje rozsáhlou knihovnu předtrénovaných modelů optimalizovaných pro různé účely—sémantickou podobnost, sémantické vyhledávání, detekci parafrází a shlukování—což umožňuje organizacím volit modely podle konkrétních požadavků. Pro AI monitoring a sledování značky se obvykle volí specializované modely trénované na rozsáhlých a rozmanitých korpusech, aby bylo zajištěno spolehlivé rozpoznání parafrázovaného obsahu a kontextových zmínek napříč AI platformami. Infrastruktura pro škálování sémantické podobnosti zahrnuje vektorové databáze pro efektivní ukládání a dotazování na zapouzdření o vysoké dimenzionalitě, což umožňuje vyhledávání podobnosti mezi miliony či miliardami dokumentů během milisekund. Firmy by měly rovněž vytvořit rámce pro hodnocení, které měří výkon modelu sémantické podobnosti v doménově specifických úlohách. Pro monitoring značky to znamená vytvořit testovací sady známých zmínek (přesných, parafrázovaných i kontextových) a měřit schopnost modelu je detekovat s minimalizací falešně pozitivních výsledků. Dávkově zpracovávané pipelines, které pravidelně znovu kódují dokumenty a aktualizují indexy podobnosti, zajišťují, že systémy sémantické podobnosti zůstávají aktuální s nově publikovaným obsahem. Organizace by také měly zavést monitorování a upozorňování na skóre sémantické podobnosti v čase, což umožní detekovat anomálie nebo posuny v tom, jak se o jejich značce na AI platformách diskutuje.
Oblast sémantické podobnosti se rychle vyvíjí a několik nových trendů zásadně mění způsob měření a využívání významové příbuznosti. Multimodální sémantická podobnost, která rozšiřuje sémantickou podobnost mimo text na obrázky, zvuk a video, nabývá na důležitosti, protože AI systémy stále častěji zpracovávají různorodý obsah. Modely jako CLIP (Contrastive Language-Image Pre-training) umožňují porovnávat sémantickou podobnost mezi textem a obrázky, což otevírá nové možnosti pro mezimodální vyhledávání a párování obsahu. Doménově specifická zapouzdření získávají na významu, protože obecné modely nemusí zachytit odbornou terminologii nebo pojmy v oblastech jako medicína, právo či finance. Organizace proto jemně dolazují zapouzdřovací modely na doménově specifických korpusech za účelem zlepšení výkonu v konkrétních úlohách. Efektivní zapouzdření je další oblastí výzkumu, zaměřenou na snižování dimenzionality zapouzdření bez ztráty sémantické kvality—a tím umožnit rychlejší inferenci a nižší náklady na uložení. Matryoshka embeddings, vytvářející zapouzdření zachovávající kvalitu napříč různými dimenzionalitami, jsou příkladem tohoto trendu. V rámci AI monitoringu se sémantická podobnost vyvíjí směrem k detekci stále sofistikovanějších variací obsahu, včetně překladů, shrnutí a AI generovaných parafrází. S tím, jak AI systémy stále častěji generují a distribuují obsah, je schopnost detekovat sémantickou ekvivalenci klíčová pro přisuzování obsahu, ochranu duševního vlastnictví a monitoring značky. Integrace sémantické podobnosti s znalostními grafy a rozpoznáváním entit umožňuje sofistikovanější pochopení sémantických vztahů i nad rámec povrchové podobnosti textu. Dále roste význam vysvětlitelnosti v sémantické podobnosti, přičemž výzkum se zaměřuje na interpretovatelnost rozhodnutí o podobnosti—pomáhá uživatelům pochopit, proč jsou dva texty považované za sémanticky podobné a které konkrétní sémantické rysy skóre ovlivňují. Tyto pokroky slibují, že sémantická podobnost bude pro podnikové aplikace ještě výkonnější, efektivnější a důvěryhodnější.
Sémantická podobnost je dnes klíčová pro analýzu a monitoring AI generovaných odpovědí na platformách jako ChatGPT, Perplexity, Google AI Overviews a Claude. Tyto systémy při generování odpovědí na uživatelské dotazy často parafrázují, shrnují nebo rekontextualizují informace ze svých tréninkových dat či získaných zdrojů. Algoritmy sémantické podobnosti umožňují platformám zjistit, které zdrojové dokumenty nebo pojmy ovlivnily konkrétní AI odpověď, i když AI obsah výrazně přeformulovala. Tato schopnost je zvláště důležitá při sledování přisuzování obsahu, kdy organizace potřebují zjistit, jak je jejich obsah citován či odkazován v AI generovaných odpovědích. Porovnáváním sémantického obsahu AI odpovědí s korpusem známých zdrojů mohou monitorovací systémy určit, které zdroje byly pravděpodobně použity, odhadnout míru parafráze či shrnutí a sledovat, jak často se konkrétní obsah v AI odpovědích objevuje. Tyto informace jsou zásadní pro monitoring viditelnosti značky,
Shoda klíčových slov identifikuje texty, které sdílejí stejná slova, zatímco sémantická podobnost chápe význam bez ohledu na rozdíly ve slovní zásobě. Například 'Miluji programování' a 'Kódování je má vášeň' nemají žádnou shodu klíčových slov, ale vysokou sémantickou podobnost. Sémantická podobnost využívá zapouzdření pro zachycení kontextového významu, což je mnohem účinnější pro pochopení záměru v AI monitoringu, párování obsahu a sledování značky, kde je třeba detekovat parafrázovaný obsah.
Vektorová zapouzdření převádějí text na vícerozměrná číselná pole, kde se sémanticky podobné texty shlukují ve vektorovém prostoru. Modely jako BERT a Sentence Transformers tato zapouzdření generují pomocí neuronových sítí trénovaných na rozsáhlých korpusech textů. Blízkost vektorů v tomto prostoru přímo koreluje se sémantickou podobností, což umožňuje algoritmům vypočítat skóre podobnosti pomocí metrik jako je kosinová podobnost, která měří úhel mezi vektory místo jejich velikosti.
Tři hlavní metriky jsou kosinová podobnost (měří úhel mezi vektory, rozsah -1 až 1), eukleidovská vzdálenost (přímá vzdálenost ve vícerozměrném prostoru) a podobnost skalárním součinem (zohledňuje směr i velikost). Kosinová podobnost je v NLP úlohách nejpopulárnější, protože je nezávislá na měřítku a zaměřuje se na směr místo velikosti. Výběr metriky závisí na způsobu trénování zapouzdřovacího modelu—shoda trénovací a vyhodnocovací metriky zajišťuje optimální výkon v aplikacích jako AI monitoring obsahu a detekce duplicit.
AI monitorovací platformy využívají sémantickou podobnost k detekci, kdy se zmínky o značce, obsahu nebo URL objevují v AI generovaných odpovědích napříč ChatGPT, Perplexity, Google AI Overviews a Claude. Místo vyhledávání přesných názvů značek sémantická podobnost identifikuje parafrázované odkazy, kontextově související obsah a významově ekvivalentní zmínky. To umožňuje značkám sledovat, jak je jejich obsah citován, objevovat konkurenční pozici v AI odpovědích a přesně monitorovat přisuzování obsahu napříč více AI platformami.
Transformerové modely jako BERT generují kontextualizovaná zapouzdření, která chápou význam slov na základě okolního kontextu, nikoli jen izolovaných definic. BERT zpracovává text obousměrně a zachycuje jemné sémantické vztahy. Zapouzdření vět v BERTu ale trpí anizotropií (shlukování do úzkých kuželů), proto jsou Sentence Transformers a specializované modely jako SimCSE účinnější pro úlohy podobnosti vět. Tyto jemně doladěné modely jsou přímo optimalizovány na sémantickou podobnost, takže kosinová podobnost spolehlivě odráží skutečné sémantické vztahy.
Sémantická podobnost pohání doporučovací systémy (navrhování podobných produktů nebo obsahu), detekci plagiátorství (identifikace parafrázovaného obsahu), detekci duplicit (hledání téměř shodných dokumentů), sémantické vyhledávání (výsledky podle významu, ne klíčových slov), systémy otázka-odpověď (párování dotazů na relevantní odpovědi) a shlukování (seskupování podobných dokumentů). V podnicích umožňuje správu obsahu, sledování souladu a inteligentní vyhledávání informací. Celosvětový trh s vektorovými databázemi, které jsou základem těchto aplikací, má dosáhnout 17,91 miliardy dolarů do roku 2034 s růstem 24 % CAGR.
Modely sémantické podobnosti se hodnotí pomocí referenčních datových sad jako STS Benchmark, SICK a SemEval, které obsahují páry vět s lidsky anotovanými skóre podobnosti. Mezi hodnotící metriky patří Spearmanova korelace (porovnání skóre modelu s lidským hodnocením), Pearsonova korelace a úlohově specifické metriky jako Mean Reciprocal Rank pro úlohy vyhledávání. Podnikové AI monitorovací platformy hodnotí modely podle jejich schopnosti detekovat parafrázované zmínky o značce, identifikovat variace obsahu a udržovat nízkou míru falešných pozitiv při sledování výskytu v různých AI systémech.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Zjistěte, jak sémantické porozumění ovlivňuje přesnost citací, přiřazování zdrojů a důvěryhodnost obsahu generovaného umělou inteligencí. Objevte roli analýzy k...
Zjistěte, jak sémantické shlukování seskupuje data podle významu a kontextu s využitím NLP a strojového učení. Objevte techniky, aplikace a nástroje pro analýzu...
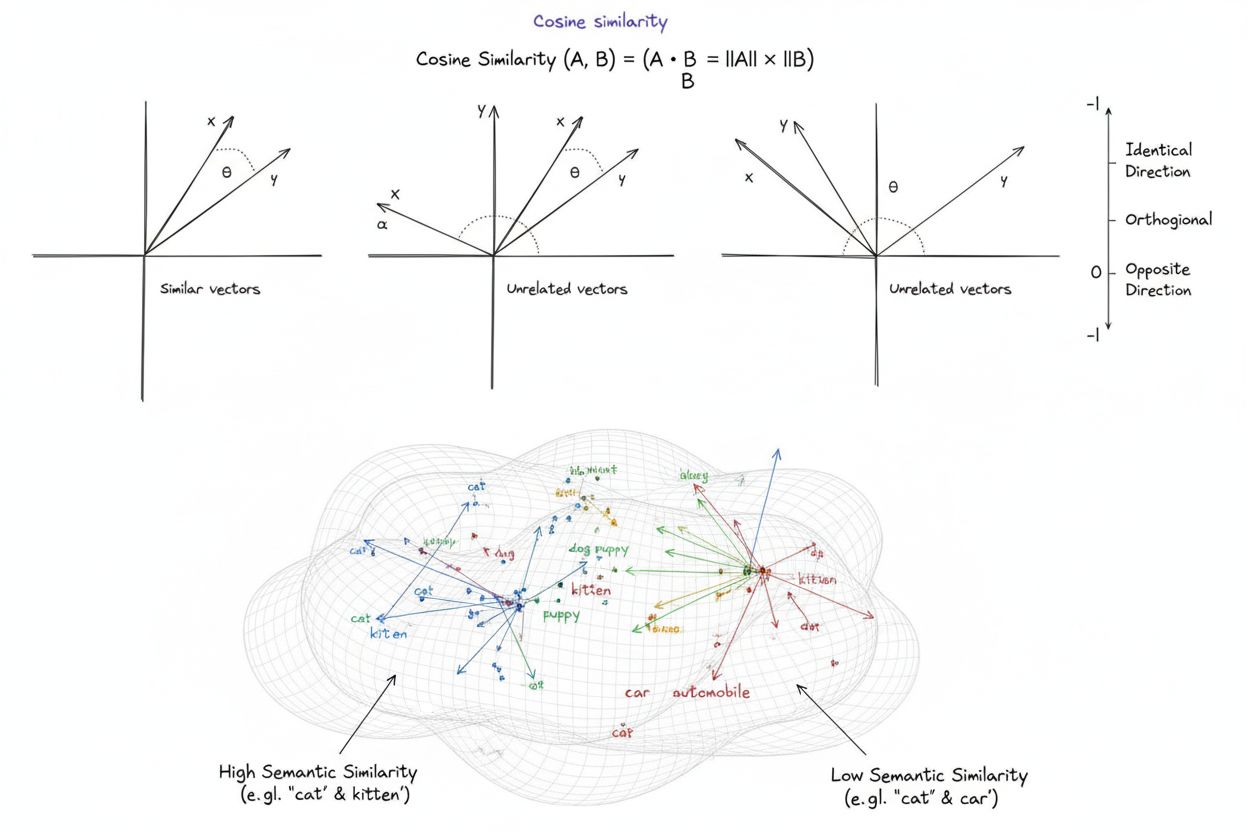
Kosínová podobnost je matematická metrika měřící zarovnání vektorů výpočtem kosínu úhlu mezi nimi. Nezbytná pro AI, NLP, sémantické vyhledávání a aplikace LLM....