Anatomien af et AI-genereret svar: Hvor opstår citationer
Lær hvordan AI-modeller genererer svar og placerer citationer. Opdag hvor dit indhold optræder i ChatGPT, Perplexity og Google AI-svar, og hvordan du optimerer for AI-synlighed.
Udgivet den Jan 3, 2026.Sidst ændret den Jan 3, 2026 kl. 3:24 am
Anatomien af et AI-genereret svar: Hvor opstår citationer
AI-genererede svar er blevet den primære opdagelsesmetode for millioner af brugere og har fundamentalt ændret informationsstrømmen på internettet. Ifølge ny forskning steg AI-adoptionen blandt forskere til 84 % i 2025, hvor 62 % specifikt brugte AI-værktøjer til forsknings- og publiceringsopgaver—en dramatisk stigning fra blot 57 % samlet AI-brug i 2024. Alligevel er de fleste indholdsskabere uvidende om, at citeringsplaceringen i disse AI-genererede svar ikke er tilfældig; den følger en sofistikeret teknisk arkitektur, der afgør, hvilke kilder får synlighed, og hvilke der forbliver usynlige. At forstå hvor og hvorfor citationer optræder er nu essentielt for alle, der ønsker at bevare synlighed i det AI-drevne opdagelseslandskab.
Model-native syntese vs. Retrieval-Augmented Generation
Forskellen mellem model-native syntese og Retrieval-Augmented Generation (RAG) former grundlæggende, hvordan citationer optræder i AI-svar. Model-native syntese bygger udelukkende på viden indkodet under træningen, mens RAG dynamisk henter eksterne kilder for at forankre svar i aktuel information. Denne forskel har stor betydning for citeringsplacering og synlighed.
Egenskab
Model-native syntese
RAG
Definition
Svar genereret kun fra træningsdata
Svar forankret i realtids-hentede kilder
Hastighed
Hurtigere (ingen hentnings-overhead)
Langsommere (kræver hentning)
Nøjagtighed
Kan indeholde hallucinationer og forældet info
Højere nøjagtighed med aktuelle kilder
Citeringsmulighed
Begrænsede eller ingen citationer
Rige, sporbare citationer
Brugsscenarier
Almindelig viden, kreative opgaver
Nyheder, forskning, faktatjek, proprietære data
RAG-baserede systemer som Perplexity og Googles AI Overviews genererer naturligt flere citationer, fordi de skal referere til deres hentede kilder, mens model-native tilgange som traditionelle ChatGPT-svar ofte citerer sjældnere. Forståelse af hvilken tilgang en platform bruger, hjælper indholdsskabere med at forudsige citeringsandsynlighed og optimere derefter.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
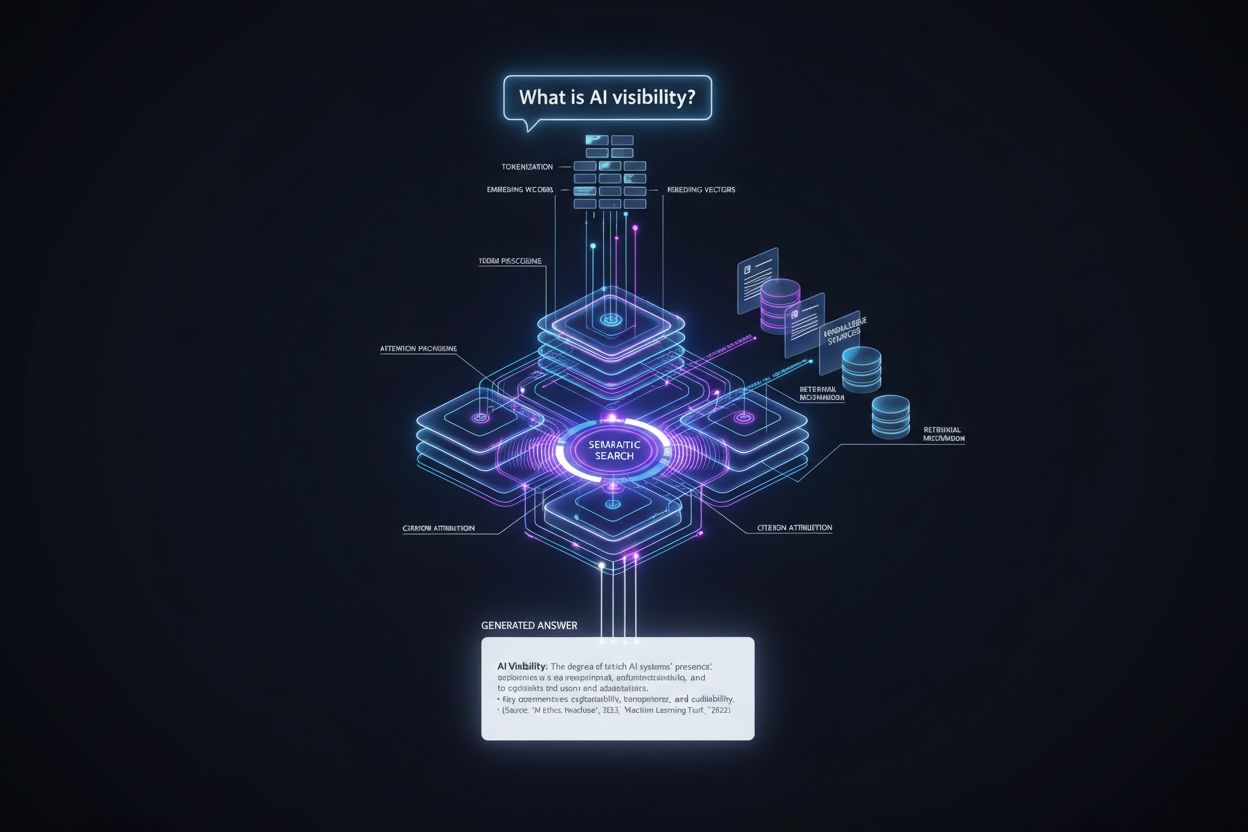
Rejsen fra brugerforespørgsel til citeret svar følger en præcis teknisk pipeline, der bestemmer citeringsplacering på flere trin. Sådan forløber processen:
Forespørgselsbehandling: Brugerens spørgsmål tokeniseres—opdeles i enheder, modellen forstår—og analyseres for intention, entiteter og semantisk mening via embedding-vektorer.
Informationshentning: Systemet søger i sin vidensbase (træningsdata, indekserede dokumenter eller realtidskilder) med semantisk søgning, matcher betydning frem for nøgleord, og returnerer kandidatkilder rangeret efter relevans.
Kontekst-samling: Hentet information organiseres i et kontekstvindue—den tekstmængde modellen kan bearbejde samtidig—med de mest relevante kilder fremhævet for at påvirke opmærksomhedsmekanismerne.
Token-generering: Modellen genererer svaret én token ad gangen ved hjælp af self-attention til at afgøre, hvilke tidligere tokens og kildeinformation der skal påvirke hver ny token og skabe sammenhængende, kontekstuelt forankrede svar.
Citeringstilskrivning: Når tokens genereres, sporer modellen hvilke kildedokumenter, der har påvirket bestemte udsagn, tildeler troværdighedsscorer og afgør, om der skal inkluderes eksplicitte citationer baseret på selvsikkerhed og platformskrav.
Output-levering: Det endelige svar formateres efter platformens specifikationer—inline citationer, fodnoter, kildepaneler eller hover-over-links—og leveres til brugeren med metadata om kildernes autoritet og relevans.
Citeringsplacering på tværs af større platforme
Citeringsplacering varierer markant mellem AI-platforme og skaber forskellige synlighedsmuligheder for indholdsskabere. Sådan håndterer store platforme citationer:
ChatGPT: Citationer vises i et separat “Kilder”-panel under svaret, og brugeren skal aktivt klikke for at se dem. Kilderne er typisk begrænset til 3-5 links med prioritet til højt autoritative domæner.
Perplexity: Citationer er indlejret inline gennem hele svaret med hævede tal og en samlet kildeoversigt i bunden. Hvert udsagn er sporbart, hvilket gør det til den mest citeringstransparente platform.
Google Gemini: Citationer vises som inline-links i selve svaret, med en “Kilder”-sektion, der lister alle refererede materialer. Integration med Googles knowledge graph påvirker, hvilke kilder vælges.
Claude: Citationer præsenteres som fodnote-lignende referencer i klammer, så brugeren kan se kilder uden at forlade svarflowet. Claude lægger vægt på kildevariation og troværdighed.
DeepSeek: Citationer optræder som inline-hyperlinks med minimal visuel markering, hvilket afspejler en mere integreret tilgang, hvor kilder flettes naturligt ind i teksten.
Disse forskelle betyder, at en kilde citeret af Perplexity kan få direkte trafik, mens samme kilde citeret af ChatGPT kan forblive usynlig, medmindre brugeren klikker på kildelisten. Platforms-specifikke citeringsmønstre påvirker trafik og synlighed direkte.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Hentningssystemer og citeringsplacering
Hentningssystemet er dér, hvor beslutninger om citeringsplacering starter, længe før svaret genereres. Semantisk søgning konverterer både brugerens forespørgsel og indekserede dokumenter til vektor-embeddings—numeriske repræsentationer, der indfanger betydning frem for nøgleord. Systemet beregner derefter similaritetsscorer mellem forespørgsels-embedding og dokument-embeddings for at identificere de kilder, der semantisk ligger tættest på brugerens intention.
Rangeringsalgoritmer omorganiserer derefter disse kandidater baseret på flere signaler: relevansscore, domæneautoritet, opdateringsgrad, brugerengagement og kvaliteten af strukturerede data. Kilder med højeste rangering i denne hentningsfase har større sandsynlighed for at blive inkluderet i kontekstvinduet til genereringsmodellen og dermed blive citeret. Derfor bliver en veloptimeret, semantisk klar artikel fra et autoritativt domæne hentet og citeret oftere end en dårligt struktureret artikel fra et nyt domæne, selvom begge indeholder korrekte informationer. Hentningsfasen bestemmer i praksis citeringspuljen, før genereringen overhovedet starter.
Hvordan indholdsstruktur påvirker citeringsandsynlighed
Indholdsstruktur er ikke kun et UX-hensyn—det påvirker direkte, om AI-systemer kan udtrække, forstå og citere dit indhold. AI-modeller er afhængige af formateringssignaler for at identificere informationsgrænser og relationer. Her er de strukturelle elementer, der maksimerer citeringsandsynligheden:
Svar-først struktur: Indled med det direkte svar på almindelige spørgsmål, så AI-systemer hurtigt kan identificere og udtrække den mest relevante information uden at skulle igennem indledende materiale.
Klar overskriftstruktur: Brug beskrivende H2- og H3-overskrifter, der tydeligt angiver emnet for hvert afsnit, så AI-systemer kan forstå indholdsopbygningen og udtrække relevante dele til bestemte forespørgsler.
Optimal afsnitslængde: Hold afsnit på 3-5 sætninger, så AI-systemer lettere kan identificere afgrænsede udsagn og tilskrive dem til specifikke kilder uden tvetydighed.
Lister og tabeller: Strukturerede data i punktform og tabeller er lettere at analysere og citere end prosa, da AI-systemer tydeligt kan skelne enkelte udsagn og deres grænser.
Entitetsklaring: Nævn personer, organisationer, produkter og begreber eksplicit i stedet for at bruge pronominer, så AI-systemer forstår præcis, hvad hvert udsagn refererer til, og kan citere korrekt.
Schema markup: Implementer strukturerede data (Schema.org) for at give eksplicit metadata om indholdstype, forfatter, udgivelsesdato og udsagn, hvilket giver AI-systemer ekstra signaler til vurdering og citering.
Indhold, der følger disse strukturelle principper, citeres 2-3 gange oftere end dårligt struktureret indhold, uanset kvalitet, fordi det ganske enkelt er lettere for AI-systemer at udtrække og tilskrive.
Citeringstilskrivningsproces
Når kilder er hentet og samlet i kontekstvinduet, vurderer modellen hver kilde gennem flere troværdighedsfiltre, før den afgør, om den skal citeres. Kildetro-værdighedsvurdering tager højde for domæneautoritet (målt på backlinks, domænealder og brandgenkendelse), forfatterekspertise (opdaget via bylines, forfatterbios og credential-signaler) og emnerelevans (om kildens primære fokus matcher forespørgslen).
Relevansscoring måler, hvor direkte kilden adresserer den specifikke forespørgsel, hvor præcise svar scorer højere end mere perifere informationer. Opdateringsfaktorer påvirker, om nyere kilder foretrækkes over ældre—kritisk for nyheder, forskning og hurtigt udviklende emner. Autoritetssignaler inkluderer citationer fra andre autoritative kilder, omtale i akademiske databaser og tilstedeværelse i knowledge graphs. Metadata-indflydelse udgøres af title tags, meta descriptions og strukturerede data, der eksplicit kommunikerer indholdets formål og troværdighed. Endelig giver strukturerede data (Schema.org markup) eksplicitte troværdighedssignaler, som modellen kan læse direkte, inklusive forfatteroplysninger, udgivelsesdatoer, vurderinger og faktatjek-status. Kilder med omfattende schema markup citeres mere pålideligt, da modellen får maskinlæsbar bekræftelse af deres udsagn.
Almindelige mønstre for citeringsplacering
AI-platforme bruger forskellige citeringsstile, der påvirker, hvor synlige dine citationer er for brugeren. Her er de mest almindelige mønstre:
Inline-citationer (Perplexity-stil):
“Ifølge ny forskning steg AI-adoptionen blandt forskere til 84 % i 2025[1], hvor 62 % specifikt brugte AI-værktøjer til forskningsopgaver[2].”
Citering sidst i afsnit (Claude-stil):
“AI-adoptionen blandt forskere steg til 84 % i 2025, hvor 62 % specifikt brugte AI-værktøjer til forskningsopgaver. [Kilde: Wiley Research Report, 2025]”
Fodnote-stil citationer (Akademisk tilgang):
“AI-adoptionen blandt forskere steg til 84 % i 2025¹, hvor 62 % specifikt brugte AI-værktøjer til forskningsopgaver².”
Kildelister (ChatGPT-stil):
Svartekst uden inline-citationer, efterfulgt af en separat “Kilder”-sektion med 3-5 links.
Hover-over-citationer (Nyt mønster):
Understreget tekst, der afslører kildeinformation, når brugeren holder musen over, hvilket minimerer visuel støj, men bevarer sporbarheden.
Hver stil skaber forskellige brugeradfærd: inline-citationer skaber øjeblikkelige klik, kildelister kræver bevidst handling, og hover-over-citationer balancerer synlighed og æstetik. Din indholds citeringsandsynlighed varierer efter platform, så overvågning på tværs af platforme er essentiel.
Forretningsmæssig betydning af citeringsplacering
Forståelse for citeringsplacering omsættes direkte til målbare forretningsresultater. Trafikmæssige konsekvenser er umiddelbare: Kilder citeret inline af Perplexity får 3-5 gange mere henvisningstrafik end kilder, der kun optræder i ChatGPT’s Kilder-panel, fordi brugerne oftere klikker på inline-citationer under læsningen. Forholdet mellem synlighed og klikrate er ikke lineært—at blive citeret er kun værdifuldt, hvis brugerne faktisk klikker, hvilket afhænger af placering, platform og kontekst.
Branda-utoritet opbygges over tid: Kilder, der konsekvent citeres af flere AI-platforme, opbygger stærkere autoritetssignaler, hvilket forbedrer deres placering i traditionel søgning og øger sandsynligheden for fremtidige AI-citationer. Dette skaber en positiv spiral, hvor citeret indhold bliver mere autoritativt og tiltrækker flere citationer. Konkurrencefordel opstår for brands, der optimerer for AI-citation før konkurrenterne—first movers indenfor schema-implementering og optimering af indholdsstruktur får i øjeblikket uforholdsmæssigt mange citationer. SEO-konsekvenser rækker ud over AI: Indhold optimeret for AI-citation klarer sig typisk bedre i traditionel søgning, fordi de samme strukturelle og autoritetssignaler gavner begge systemer. AmICited-værdien bliver klar: I et AI-drevet opdagelseslandskab svarer det til ikke at kende sine søgeplaceringer, hvis man ikke ved, om man bliver citeret—et kritisk blind-spot i din synlighedsstrategi.
Praktisk vejledning til indholdsskabere
Optimering for AI-citation kræver specifikke og handlingsorienterede ændringer i, hvordan du skaber og strukturerer indhold. Her er de mest effektfulde taktikker:
Strukturer for udtrækkelighed: Brug tydelige overskrifter, korte afsnit og lister, så dit indhold er let for AI-systemer at analysere og udtrække præcise udsagn uden tvetydighed.
Brug klare, citerbare fakta: Indled med specifikke statistikker, datoer og navngivne entiteter i stedet for vage generaliseringer. AI-systemer citerer konkrete udsagn oftere end abstrakte.
Implementér schema markup: Tilføj Schema.org markup for Article, NewsArticle eller ScholarlyArticle og inkluder forfatter, udgivelsesdato og påstandsspecifikke metadata, som AI-systemer kan læse direkte.
Bevar entitetskonsistens: Brug de samme navne for personer, organisationer og begreber overalt i indholdet, undgå pronominer og forkortelser, der skaber tvetydighed for AI-systemer.
Citer dine egne kilder: Når du citerer andre kilder i dit indhold, signalerer du til AI-systemer, at dit indhold er velresearchet og troværdigt, hvilket øger din egen citeringsandsynlighed.
Test med AI-værktøjer: Søg jævnligt på dine emner i ChatGPT, Perplexity, Gemini og Claude for at se, om dit indhold bliver citeret, og hvordan det præsenteres.
Overvåg præstation: Følg hvilke af dine indholdsstykker, der citeres, af hvilke platforme og i hvilken kontekst, og brug disse data til at forfine din optimeringsstrategi.
Indholdsskabere, der implementerer disse taktikker, oplever en stigning i citeringsraten på 40-60 % inden for 3-6 måneder, med tilsvarende stigning i henvisningstrafik og brandautoritet.
Overvågning og måling af citationer
Citeringsovervågning er ikke længere valgfrit—det er essentiel infrastruktur for forståelsen af din synlighed i det AI-drevne opdagelseslandskab. Hvorfor overvågning er vigtig er klart: Du kan ikke optimere det, du ikke måler, og citeringsmønstre ændrer sig, efterhånden som AI-systemer udvikler sig og nye platforme dukker op. Hvilke metrics du skal spore inkluderer citeringsfrekvens (hvor ofte du bliver citeret), citeringsplacering (inline vs. kildeliste), platformfordeling (hvilke platforme citerer dig mest), forespørgselskontekst (hvilke emner udløser dine citationer) og trafikatribuering (hvor meget henvisningstrafik kommer fra AI-citationer).
Identificering af muligheder kræver analyse af citeringshuller: emner, hvor konkurrenter citeres, men du ikke gør, platforme hvor du er underrepræsenteret, og indholdstyper der underpræsterer. Denne analyse afslører konkrete optimeringsmål—måske bliver dine how-to-guides ikke citeret, fordi de mangler schema markup, eller dit forskningsindhold ikke optræder i Perplexity, fordi det ikke er struktureret for inline-udtræk.
AmICited løser overvågningsudfordringen ved at spore dine citationer på tværs af ChatGPT, Perplexity, Gemini, Claude og andre større AI-platforme i realtid. I stedet for manuelt at søge på dine emner gentagne gange overvåger AmICited automatisk citeringsmønstre, advarer dig om nye citationer og giver konkurrencemæssige benchmarks, der viser, hvordan din citeringspræstation sammenlignes med konkurrenternes. For indholdsskabere, marketingfolk og SEO-professionelle forvandler AmICited citeringsovervågning fra en manuel, tidskrævende proces til et automatiseret system, der leverer handlingsrettet indsigt. I et AI-drevet opdagelseslandskab er synlighed i, hvor dit indhold citeres, lige så vigtigt som synlighed i søgeplaceringer—og AmICited gør den synlighed mulig i stor skala.
Ofte stillede spørgsmål
Hvad er forskellen på model-native og RAG-baserede svar?
Model-native svar kommer fra mønstre lært under træning, mens RAG henter live-data før svar genereres. RAG giver typisk bedre citationer, fordi det forankrer svar i specifikke kilder, hvilket gør det mere gennemsigtigt og sporbart for brugere og indholdsskabere.
Hvorfor citerer nogle AI-platforme kilder, mens andre ikke gør?
Forskellige platforme bruger forskellige arkitekturer. Perplexity og Gemini prioriterer RAG med citationer, mens ChatGPT som standard bruger model-native generering, medmindre browsing er aktiveret. Valget afspejler hver platforms designfilosofi og tilgang til gennemsigtighed.
Hvordan påvirker indholdsstruktur, om AI citerer dit indhold?
Klart, velstruktureret indhold med direkte svar, korrekte overskrifter og schema markup er lettere for AI-systemer at udtrække. Indhold, der starter med svar og bruger lister og tabeller, har større sandsynlighed for at blive citeret, fordi det er nemmere for AI at analysere og tilskrive.
Hvilken rolle spiller schema markup i citeringsplacering?
Schema markup hjælper AI-systemer med at forstå indholdsstruktur og entitetsrelationer, hvilket gør det lettere korrekt at tilskrive og citere dit indhold. Korrekt schema-implementering øger citeringsandsynligheden og hjælper AI-systemer med at verificere dit indholds troværdighed.
Kan jeg optimere mit indhold til at optræde i AI-genererede svar?
Ja. Fokuser på svar-først struktur, klar formatering, faktuel nøjagtighed, troværdige kilder og korrekt schema-implementering. Overvåg dine citationer og iterér baseret på præstationsdata for løbende at forbedre din AI-synlighed.
Hvordan sporer jeg, hvor mit brand optræder i AI-genererede svar?
Værktøjer som AmICited overvåger dine brandomtaler på tværs af ChatGPT, Perplexity, Google AI Overviews og andre platforme, og viser præcis hvor og hvordan du bliver citeret i AI-svar. Dette giver handlingsorienteret indsigt til optimering.
Påvirker det min søgerangering at blive citeret af AI?
Selvom AI-citationer ikke direkte påvirker Google-rangeringer, øger de brandsynlighed og autoritetssignaler. At blive citeret af AI kan drive trafik og styrke din samlede online tilstedeværelse, hvilket giver indirekte SEO-fordele.
Hvad er forholdet mellem traditionel SEO og AI-citeringsoptimering?
De supplerer hinanden. Traditionel SEO fokuserer på at rangere i søgeresultater, mens AI-citeringsoptimering fokuserer på at optræde i AI-genererede svar. Begge dele er vigtige for omfattende synlighed i det moderne opdagelseslandskab.
Overvåg din AI-synlighed på alle platforme
Forstå præcis hvor dit brand optræder i AI-genererede svar. Spor citationer på tværs af ChatGPT, Perplexity, Google AI Overviews og mere med AmICited.
Citationsposition i AI-svar: Sådan citerer forskellige AI-platforme kilder
Lær hvordan citationsposition fungerer på tværs af ChatGPT, Perplexity, Google AI Overviews og andre AI-systemer. Forstå strategier for citatplacering, og hvord...
Hvilke Sider Bliver Oftest Citeret af AI? Citeringsmønstre på tværs af ChatGPT, Perplexity & Google
Opdag hvilke websites og sider, der oftest bliver citeret af AI-systemer som ChatGPT, Perplexity og Google AI Overviews. Lær citeringsmønstre, domænepræferencer...
Hvordan Beslutter AI-Modeller, Hvad de Skal Citere i AI-Svar
Lær, hvordan AI-modeller som ChatGPT, Perplexity og Gemini vælger kilder at citere. Forstå citatmekanismerne, rangeringsfaktorerne og optimeringsstrategierne fo...
12 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.