
Sådan identificerer du AI-crawlere i dine serverlogs
Lær at identificere og overvåge AI-crawlere som GPTBot, ClaudeBot og PerplexityBot i dine serverlogs. Komplet guide med user-agent strings, IP-verificering og p...
8 min læsning

Lær at revidere AI-crawleres adgang til din hjemmeside. Find ud af, hvilke bots der kan se dit indhold og ret blokeringer, der forhindrer AI-synlighed i ChatGPT, Perplexity og andre AI-søgemaskiner.
Landskabet for søgning og opdagelse af indhold ændrer sig dramatisk. Med AI-drevne søgeværktøjer som ChatGPT, Perplexity og Google AI Overviews, der vokser eksplosivt, er dit indholds synlighed for AI-crawlere nu lige så afgørende som traditionel søgemaskineoptimering. Hvis AI-bots ikke kan få adgang til dit indhold, bliver din side usynlig for millioner af brugere, der benytter disse platforme til at finde svar. Indsatsen er større end nogensinde: mens Google måske genbesøger din side, hvis noget går galt, arbejder AI-crawlere efter et andet paradigme—og hvis du misser det første kritiske crawl, kan det betyde måneder med tabt synlighed og mistede muligheder for citationer, trafik og brandautoritet.
AI-crawlere opererer efter fundamentalt andre regler end Google- og Bing-bots, som du har optimeret for gennem årene. Den vigtigste forskel: AI-crawlere render ikke JavaScript, hvilket betyder, at dynamisk indhold, der indlæses via klient-side scripts, er usynligt for dem—i skarp kontrast til Googles avancerede renderingsmuligheder. Derudover besøger AI-crawlere sider med væsentligt højere frekvens, nogle gange 100 gange oftere end traditionelle søgemaskiner, hvilket både skaber muligheder og udfordringer for serverressourcer. I modsætning til Googles indekseringsmodel opretholder AI-crawlere ikke et vedvarende indeks, der opdateres; de crawler i stedet on-demand, når brugere forespørger i deres systemer. Det betyder, at der ikke er nogen re-indekseringskø, ingen Search Console til at anmode om gen-crawl, og ingen anden chance, hvis din side fejler ved første indtryk. At forstå disse forskelle er essentielt for at optimere din indholdsstrategi.
| Funktion | AI-crawlere | Traditionelle bots |
|---|---|---|
| JavaScript-rendering | Nej (kun statisk HTML) | Ja (fuld rendering) |
| Crawl-frekvens | Meget høj (100x+ oftere) | Moderat (ugentlig/månedlig) |
| Re-indekseringsmulighed | Ingen (kun on-demand) | Ja (løbende opdateringer) |
| Indholdskrav | Ren HTML, schema markup | Fleksibel (håndterer dynamisk indhold) |
| User-Agent-blokering | Specifik pr. bot (GPTBot, ClaudeBot osv.) | Generisk (Googlebot, Bingbot) |
| Caching-strategi | Kortsigtede snapshots | Langsigtet indeksvedligeholdelse |
Dit indhold kan være usynligt for AI-crawlere af grunde, du aldrig har overvejet. Her er de primære forhindringer, der forhindrer AI-bots i at få adgang til og forstå dit indhold:
Din robots.txt-fil er det primære redskab til at kontrollere, hvilke AI-bots der kan få adgang til dit indhold, og den fungerer via specifikke User-Agent-regler, der retter sig mod individuelle crawlere. Hver AI-platform bruger unikke user-agent-strenge—OpenAI’s GPTBot, Anthropics ClaudeBot, Perplexitys PerplexityBot—og du kan tillade eller nægte adgang til hver enkelt uafhængigt. Denne detaljerede kontrol gør det muligt at bestemme, hvilke AI-systemer der må træne på eller citere dit indhold, hvilket er afgørende for at beskytte fortrolige oplysninger eller håndtere konkurrencehensyn. Mange hjemmesider blokerer dog uforvarende AI-crawlere gennem alt for brede regler, der var designet til ældre bots, eller de undlader helt at implementere korrekte regler.
Her er et eksempel på, hvordan du kan konfigurere din robots.txt til forskellige AI-bots:
# Tillad OpenAI's GPTBot
User-agent: GPTBot
Allow: /
# Bloker Anthropics ClaudeBot
User-agent: ClaudeBot
Disallow: /
# Tillad Perplexity men begræns visse kataloger
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Standardregel for alle andre bots
User-agent: *
Allow: /
I modsætning til Google, som løbende crawler og re-indekserer din side, opererer AI-crawlere på et “one-shot”-princip—de besøger, når en bruger forespørger i deres system, og hvis dit indhold ikke er tilgængeligt i det øjeblik, er muligheden tabt. Denne grundlæggende forskel betyder, at din side skal være teknisk klar fra dag ét; der er ingen tilgivelsesperiode, ingen anden chance for at rette fejl før synligheden lider. En dårlig første crawl-oplevelse—uanset om det skyldes JavaScript-renderingsfejl, manglende schema markup eller serverfejl—kan føre til, at dit indhold udelades fra AI-genererede svar i uger eller måneder. Der er ingen manuel re-indekseringsmulighed, ingen “Anmod om indeksering”-knap i en konsol, hvilket gør proaktiv overvågning og optimering uundværlig. Presset for at lykkes første gang har aldrig været større.
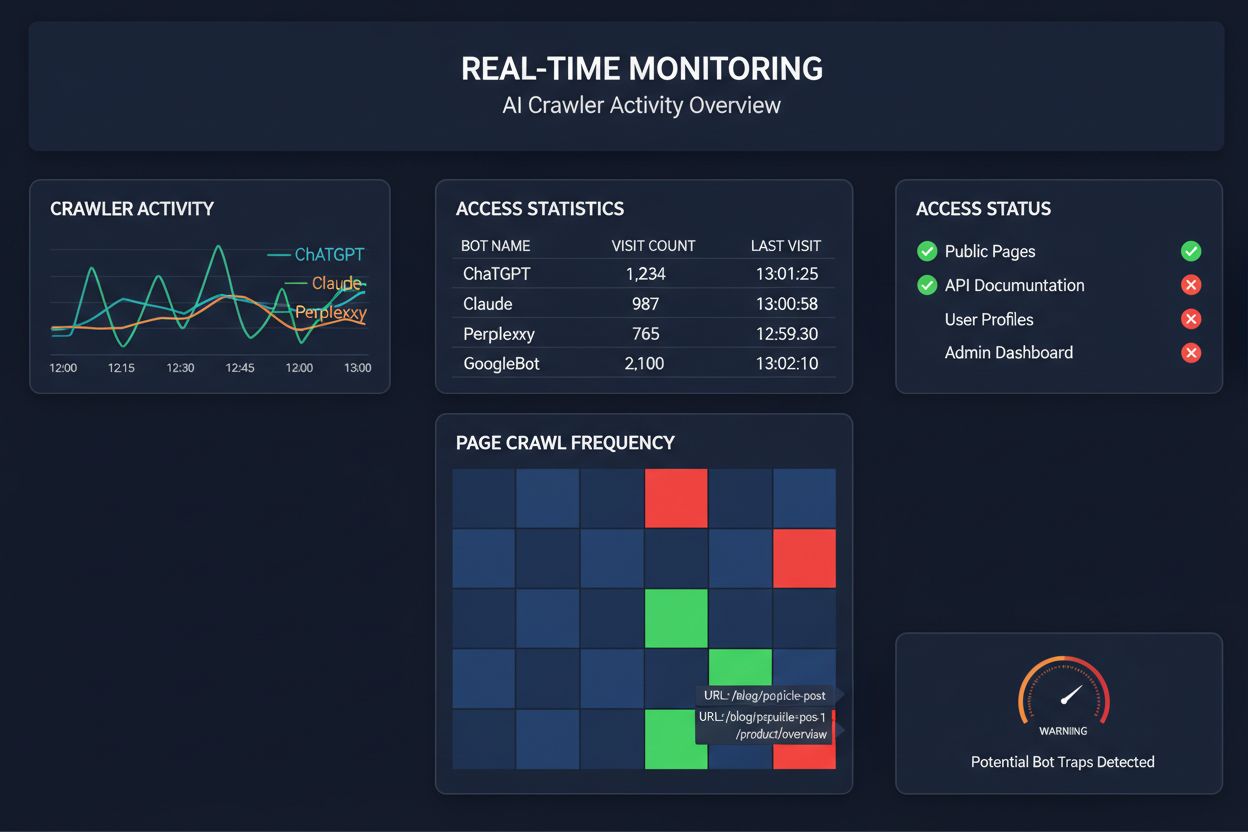
At stole på planlagte crawls til at overvåge AI-crawler-adgang svarer til kun at tjekke sit hus for brand én gang om måneden—du går glip af de kritiske øjeblikke, hvor problemer opstår. Realtids-overvågning registrerer problemer i samme øjeblik, de opstår, så du kan reagere, før dit indhold bliver usynligt for AI-systemer. Planlagte revisioner, der typisk køres ugentligt eller månedligt, skaber farlige blinde vinkler, hvor din side kan fejle for AI-crawlere i dagevis uden din viden. Realtidsløsninger sporer crawler-adfærd kontinuerligt og advarer dig om JavaScript-renderingsfejl, schema markup-fejl, firewall-blokeringer eller serverproblemer, så snart de indtræffer. Denne proaktive tilgang forvandler din revision fra en reaktiv compliance-kontrol til en aktiv strategi for synlighedsstyring. Med AI-crawler-trafik, der potentielt er 100 gange højere end traditionelle søgemaskiner, kan omkostningerne ved blot få timers manglende tilgængelighed være betydelige.
Flere platforme tilbyder nu specialiserede værktøjer til overvågning og optimering af AI-crawler-adgang. Cloudflare AI Crawl Control giver infrastruktur-niveau styring af AI-bot-trafik, så du kan sætte rate limits og adgangspolitikker. Conductor tilbyder omfattende overvågningsdashboards, der sporer, hvordan forskellige AI-crawlere interagerer med dit indhold. Elementive fokuserer på tekniske SEO-revisioner med særligt fokus på AI-crawler-krav. AdAmigo og MRS Digital tilbyder specialiseret rådgivning og overvågningstjenester for AI-synlighed. Men for kontinuerlig, realtids-overvågning, der specifikt er designet til at spore AI-crawleres adgangsmønstre og advare dig om problemer, før de påvirker synligheden, udmærker AmICited sig som en dedikeret løsning. AmICited har specialiseret sig i at overvåge, hvilke AI-systemer der tilgår dit indhold, hvor ofte de crawler, og om de støder på tekniske barrierer. Dette særlige fokus på AI-crawler-adfærd—frem for traditionelle SEO-målepunkter—gør det til et uundværligt værktøj for organisationer, der tager AI-synlighed alvorligt.
At gennemføre en omfattende AI-crawler-revision kræver en systematisk tilgang. Trin 1: Etabler en baseline ved at tjekke din nuværende robots.txt-fil og identificere, hvilke AI-bots du aktuelt tillader eller blokerer. Trin 2: Revidér din tekniske infrastruktur ved at teste din sides tilgængelighed for ikke-JavaScript-crawlere, tjekke server-responstider og sikre, at kritisk indhold serveres i statisk HTML. Trin 3: Implementér og valider schema markup på tværs af dit indhold, så forfatterskab, publiceringsdatoer, indholdstype og anden metadata struktureres korrekt i JSON-LD-format. Trin 4: Overvåg crawler-adfærd med værktøjer som AmICited for at spore, hvilke AI-bots der tilgår din side, hvor ofte, og om de støder på fejl. Trin 5: Analyser resultater ved at gennemgå crawl-logs, identificere fejlmønstre og prioritere rettelser baseret på indvirkning. Trin 6: Udfør rettelser begyndende med højimpakt-problemer som JavaScript-renderingsfejl eller manglende schema, og gå dernæst videre til sekundære optimeringer. Trin 7: Etabler løbende overvågning for at fange nye problemer, før de påvirker synligheden, og opsæt advarsler for crawl-fejl eller adgangsblokeringer.
Du behøver ikke en total ombygning for at forbedre AI-crawler-adgang—flere højeffektive ændringer kan implementeres hurtigt. Server kritisk indhold i ren HTML i stedet for at være afhængig af JavaScript-rendering; hvis du skal bruge JavaScript, så sørg for, at vigtig tekst og metadata også er tilgængelig i den initiale HTML-payload. Tilføj omfattende schema markup i JSON-LD-format, inklusive article schema, forfatteroplysninger, publiceringsdatoer og indholdsrelationer—det hjælper AI-crawlere med at forstå kontekst og korrekt tilskrive indhold. Sørg for tydelig forfatterinformation via schema markup og bylines, da AI-systemer i stigende grad prioriterer citation af autoritative kilder. Overvåg og optimer Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift), da langsomt indlæsende sider kan blive opgivet af crawlere, før de er færdige. Gennemgå og opdater din robots.txt for at sikre, at du ikke ved en fejl blokerer AI-bots, du ønsker skal tilgå dit indhold. Ret tekniske fejl som redirect-kæder, døde links og serverfejl, der kan få crawlere til at opgive din side midt i crawl-processen.
Ikke alle AI-crawlere tjener samme formål, og kendskab til disse forskelle hjælper dig med at træffe informerede beslutninger om adgangskontrol. GPTBot (OpenAI) bruges primært til indsamling af træningsdata og forbedring af modelkapaciteter, hvilket er relevant, hvis du ønsker, at dit indhold skal informere ChatGPT’s svar. OAI-SearchBot (OpenAI) crawler specifikt for søge-citation, hvilket betyder, at det er denne bot, der inkluderer dit indhold i ChatGPT’s søgeintegrerede svar. ClaudeBot (Anthropic) tjener lignende formål for Claude, Anthropics AI-assistent. PerplexityBot (Perplexity) crawler for citation i Perplexitys AI-drevne søgemaskine, som er blevet en betydelig trafikkilde for mange udgivere. Hver bot har forskellige crawl-mønstre, frekvenser og formål—nogle fokuserer på træningsdata, andre på realtids-søgecitation. Beslutningen om, hvilke bots du vil tillade eller blokere, bør afspejle din indholdsstrategi: hvis du vil have citationer i AI-søgeresultater, tillad de søgespecifikke bots; hvis du er bekymret for brug af træningsdata, kan du blokere dataindsamlingsbots, men tillade søgebots. Denne nuancerede tilgang til bot-styring er langt mere sofistikeret end den traditionelle “tillad alle” eller “blokér alle”-mentalitet.
En AI-crawler-revision er en omfattende vurdering af din hjemmesides tilgængelighed for AI-bots som ChatGPT, Claude og Perplexity. Den identificerer tekniske blokeringer, problemer med JavaScript-rendering, manglende schema markup og andre faktorer, der forhindrer AI-crawlere i at få adgang til og forstå dit indhold. Revisionen giver handlingsrettede anbefalinger til at forbedre din synlighed i AI-drevne søge- og svarmotorer.
Vi anbefaler at foretage en omfattende revision mindst kvartalsvist, eller når du foretager væsentlige ændringer af din hjemmesides tekniske infrastruktur, indholdsstruktur eller robots.txt-fil. Kontinuerlig overvågning i realtid er dog ideel for at fange problemer, så snart de opstår. Mange organisationer benytter automatiske overvågningsværktøjer, der advarer dem om crawl-fejl i realtid, suppleret med kvartalsvise dybdegående revisioner.
At tillade AI-crawlere betyder, at dit indhold kan tilgås, analyseres og potentielt citeres af AI-systemer, hvilket kan øge din synlighed i AI-genererede svar og anbefalinger. At blokere AI-crawlere forhindrer dem i at få adgang til dit indhold og beskytter fortrolige oplysninger, men kan samtidig reducere din synlighed i AI-søgeresultater. Det rette valg afhænger af dine forretningsmål, indholdets følsomhed og din konkurrencesituation.
Ja, absolut. Din robots.txt-fil giver dig detaljeret kontrol via User-Agent-regler. Du kan blokere GPTBot, mens du tillader PerplexityBot, eller tillade søgefokuserede bots (som OAI-SearchBot), mens du blokerer dataindsamlingsbots (som GPTBot). Denne nuancerede tilgang gør det muligt at optimere din indholdsstrategi ud fra, hvilke AI-platforme der er vigtigst for din virksomhed.
Hvis AI-crawlere ikke kan få adgang til dit indhold, er din side reelt usynlig for AI-drevne søgemaskiner og svarplatforme. Dit indhold bliver hverken citeret, anbefalet eller inkluderet i AI-genererede svar, selvom det er meget relevant. Det kan føre til tabt trafik, reduceret brand-synlighed og mistede muligheder for at opbygge autoritet i AI-søgeresultater.
Du kan tjekke dine serverlogs for User-Agent-strenge fra kendte AI-crawlere (GPTBot, ClaudeBot, PerplexityBot m.fl.), eller bruge specialiserede overvågningsværktøjer som AmICited, der sporer AI-crawleraktivitet i realtid. Disse værktøjer viser, hvilke bots der tilgår din side, hvor ofte de crawler, hvilke sider de besøger, og om de støder på fejl eller blokeringer.
Det afhænger af din specifikke situation. Hvis dit indhold er fortroligt, følsomt, eller du er bekymret for brugen til træningsdata, kan blokering være passende. Hvis du derimod ønsker synlighed i AI-søgeresultater og citationer fra AI-systemer, er det essentielt at tillade crawlere. Mange organisationer vælger et kompromis: de tillader søgefokuserede bots, der giver citationer, men blokerer dataindsamlingsbots.
AI-crawlere render ikke JavaScript, hvilket betyder, at indhold, der indlæses dynamisk via klient-side scripts, er usynligt for dem. Hvis din side er stærkt afhængig af JavaScript til kritisk indhold, navigation eller strukturerede data, vil AI-crawlere kun se den rå HTML og gå glip af vigtig information. Det kan i høj grad påvirke, hvordan dit indhold forstås og vises i AI-svar. At servere kritisk indhold i statisk HTML er afgørende for, at AI-crawlere kan tilgå det.
Få realtidsindsigt i, hvilke AI-bots der tilgår dit indhold, og hvordan de ser din hjemmeside. Start din gratis revision i dag og sikr, at dit brand er synligt på alle AI-søgeplatforme.
Lær at identificere og overvåge AI-crawlere som GPTBot, ClaudeBot og PerplexityBot i dine serverlogs. Komplet guide med user-agent strings, IP-verificering og p...

Lær hvordan du tester, om AI-crawlere som ChatGPT, Claude og Perplexity kan få adgang til dit websites indhold. Opdag testmetoder, værktøjer og best practices f...

Lær hvordan du sporer og overvåger AI-crawler-aktivitet på din hjemmeside ved hjælp af serverlogs, værktøjer og bedste praksis. Identificer GPTBot, ClaudeBot og...