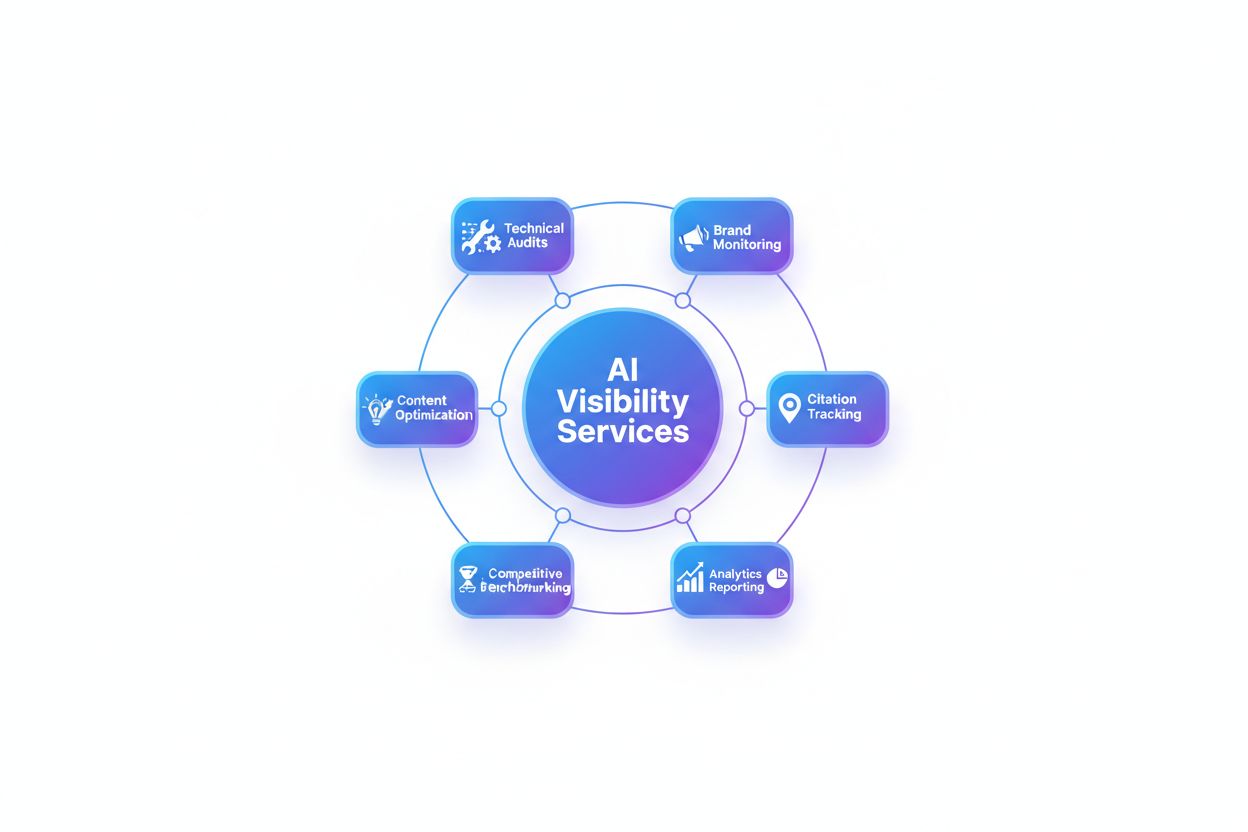
Hvad AI-synlighedstjenester omfatter: Omfang og leverancer
Opdag hvad AI-synlighedstjenester leverer: brandovervågning, citatsporing, analyser, konkurrentbenchmarking, indholdsoptimering og tekniske audits på tværs af C...
7 min læsning

Lær hvordan AI-synligheds-API’er muliggør realtids-overvågning af brand-omtaler på tværs af ChatGPT, Perplexity og Gemini. Opdag API-integrationsstrategier, workflow-automatisering og hvordan du bygger tilpassede dashboards for GEO-succes.
AI-synligheds-API’er repræsenterer et fundamentalt skifte i, hvordan brands overvåger deres tilstedeværelse på tværs af generative AI-platforme. I modsætning til traditionel SEO-overvågning, der sporer placeringer i Googles søgeresultater, giver AI-synligheds-API’er programmatisk adgang til realtidsdata om, hvordan dit brand fremstår i AI-genererede svar fra ChatGPT, Perplexity, Gemini og Claude. Disse API’er eksponerer strukturerede data om citater (når AI-platforme linker til dit indhold), omtaler (når dit brand nævnes), sentiment (hvor positivt eller negativt du beskrives) og konkurrencepositionering (hvordan du rangerer mod konkurrenter i AI-svar). Skiftet fra traditionel søgemaskineoptimering til AI-søgesynlighed kræver fundamentalt forskellige overvågningsmetoder. Hvor Googles algoritme rangerer sider baseret på relevans og autoritet, henter og syntetiserer generative AI-systemer information fra flere kilder og prioriterer nøjagtighed, dækkende indhold og citatkvalitet. Det betyder, at dit brands synlighed ikke afhænger af keywordplaceringer, men af om AI-systemer anser dit indhold som autoritativt nok til at citere, når de besvarer brugerforespørgsler. Fremkomsten af AI-synligheds-API’er adresserer et kritisk hul: traditionelle analyseplatforme kan ikke spore omtaler i AI-genererede svar, hvilket efterlader marketingfolk blinde over for en hurtigt voksende kanal. ChatGPT behandler over 2,5 milliarder forespørgsler dagligt, Perplexity havde 153 millioner besøg i maj 2025, og Googles AI Overviews vises i 57% af søgeresultater. Disse platforme omformer, hvordan forbrugere opdager information, hvilket gør API-baseret overvågning uundværlig for konkurrencedygtig synlighed.
Valget mellem API-baseret overvågning og UI-scraping er afgørende for pålideligheden, lovligheden og skalerbarheden af din AI-synlighedsstrategi. Web scraping—at bruge automatiserede bots til at simulere brugere og udtrække data fra AI-platformes brugergrænseflader—kan virke attraktivt, fordi det er gratis og ikke kræver officielle partnerskaber. Men denne tilgang medfører alvorlige tekniske og juridiske risici, der underminerer overvågningens effektivitet på lang sigt. Scraping-nøjagtighed er fundamentalt begrænset: scrapers fanger kun én snæver brugerkonfiguration (f.eks. desktop ChatGPT med specifikke indstillinger) og overser mangfoldigheden i rigtige brugeroplevelser på mobile, stemmebaserede grænseflader og forskellige modelversioner. Det betyder, at din scraper måske viser 40% citatfrekvens, mens rigtige brugere ser 25%, fordi konfigurationen ikke matcher virkelige brugsmønstre. Compliance og juridisk eksponering er betydelig: de fleste AI-platforme forbyder specifikt automatiseret scraping i deres servicevilkår. Overtrædelse af disse vilkår kan føre til kontosuspension, IP-blokering og mulig retssag under Computer Fraud and Abuse Act. API-baseret overvågning er derimod fuldt ud compliant og skaber et revisionsspor til regulatorisk overholdelse.
| Metrik | API-baseret overvågning | Web scraping |
|---|---|---|
| Nøjagtighed | 99,2% | 71-84% |
| Data-latenstid | 150 ms | 2-5 sekunder |
| Compliance-risiko | Ingen (godkendt) | Høj (TOS-overtrædelse) |
| Årlig pris | $1.200-3.500 | $8.000-15.000 |
| Skalerbarhed | Ubegrænset antal forespørgsler | Begrænset af infrastruktur |
| Datakvalitet | Struktureret JSON | Rå HTML kræver parsing |
| Vedligeholdelsesbyrde | Minimal (API-versionering) | Konstant (UI-ændringer ødelægger scrapers) |
| Tværplatformdækning | 8+ platforme samtidig | Én platform pr. scraper |
| Realtidskapacitet | Øjeblikkelige API-svar | Forsinket af scraping-cyklusser |
API-baseret overvågning leverer strukturerede, analyserbare data i JSON-format med korrekt metadata og eliminerer det parsing-overhead, som scraping kræver. Når en AI-platform opdaterer sin brugergrænseflade—hvilket sker ofte—bryder scrapers lydløst og returnerer ufuldstændige eller korrupte data uden varsel. API’er derimod bevarer bagudkompatibilitet via versionering, så dine integrationer fortsat virker, når platforme ændres. Omkostningseffektivitet peger markant på API’er: selvom scraping-infrastruktur virker gratis i starten, koster vedligeholdelse af proxynetværk, håndtering af anti-bot-detektion og løbende reparation typisk $8.000-15.000 årligt. Enterprise-grade API-adgang koster $1.200-3.500 årligt og inkluderer support, dokumentation og garanteret oppetid. Allervigtigst: API-baseret overvågning skalerer uendeligt, mens scraping rammer hårde grænser. Du kan udføre tusindvis af overvågningsforespørgsler på tværs af flere AI-platforme samtidig med API’er, mens scraping kræver separat infrastruktur for hver platform og udfordres af rate limiting. Datakvaliteten er også bemærkelsesværdigt bedre: API’er returnerer strukturerede svar med eksplicit metadata om, hvornår søgninger blev udløst, hvilke kilder blev citeret og confidence scores. Scrapers returnerer rå HTML, der kræver kompleks parsing og ofte indeholder fejl eller ufuldstændig information.
Enterprise AI-synligheds-API’er tilbyder omfattende overvågningsmuligheder, der rækker langt ud over simpel citatsporing. Forståelse af disse kernefunktioner er afgørende for at bygge effektive overvågnings- og automatiseringsworkflows:
Realtids citatsporing: API’er logger alle tilfælde, hvor dit indhold citeres af AI-systemer, inkl. den præcise forespørgsel, der udløste citatet, hvilken AI-model der citerede dig, positionen i svaret (headline vs. fodnote) og om citatet inkluderer hyperlink. Denne granularitet på forespørgselsniveau gør det muligt at forstå, hvilke emner og indholdsformater der driver citater.
Struktureret metadata og responsformat: I stedet for rå tekst returnerer API’er korrekt formateret JSON med eksplicitte felter for citat-URL’er, kildehenvisning, confidence scores og tidsstempel. Denne struktur muliggør direkte integration med databaser og BI-værktøjer uden specialiseret parsing.
Tværplatform-konsistens: API’er leverer ensartede datastrukturer på tværs af ChatGPT, Perplexity, Gemini, Claude og andre platforme og eliminerer behovet for at bygge separate integrationer. Konkurrencedata normaliseres til konsistente formater for nem sammenligning.
Batch- og streaming-endpoints: API’er understøtter både batchbehandling (indsend 1.000 forespørgsler og hent resultater asynkront) og realtidsstreaming (modtag citatopdateringer, når de sker). Denne fleksibilitet dækker forskellige overvågningsmønstre—batch til audits, streaming til realtidsalarmer.
Webhook-support og event-triggere: Avancerede API’er sender webhook-notifikationer, når bestemte begivenheder indtræffer (dit brand citeres, sentiment ændrer sig, en konkurrent får citater). Dette muliggør trigger-baseret automatisering uden konstant polling.
Historiske data og trendanalyse: API’er giver adgang til historiske citatdata, så du kan analysere trends, identificere sæsonmønstre og måle effekten af optimering over tid. De fleste platforme gemmer 12-36 måneders historiske data.
Konkurrenceindsigt: API’er returnerer ikke kun dine citater, men også konkurrenters citater i samme forespørgsler, så du kan beregne share of voice og benchmarking uden separate værktøjer.
Den sande styrke ved AI-synligheds-API’er kommer til udtryk, når overvågningsdata forbindes til workflow-automatiseringsplatforme som n8n, Zapier og Make. Disse integrationer forvandler passiv overvågning til aktive, automatiserede reaktioner på synlighedsændringer. Et praktisk eksempel: Når din citatfrekvens falder under en tærskel (fx under 25% af relevante forespørgsler), kan et automatiseret workflow udløse flere handlinger samtidig. Workflowet modtager API-alarmen, forespørger dit CMS for at identificere underpræsterende sider, opretter automatisk en opgave i dit projektstyringsværktøj, sender en Slack-besked til dit indholdsteam og igangsætter en opdateringsproces. Hele denne sekvens sker uden manuel indgriben og muliggør hurtig respons på synlighedsændringer.
n8n-workflows giver størst fleksibilitet til komplekse automatiseringer. Du kan bygge multi-step-workflows, der kombinerer AI-synlighedsdata med andre datakilder: træk citatdata fra din API, sammenlign med Google Analytics for at identificere high-intent-trafikkilder, forespørg dit CRM for at se, hvilke citerede sider der driver konverteringer, og prioriter automatisk optimering baseret på omsætningseffekt frem for blot citatfrekvens. Workflowet kan derefter generere en prioriteret indholdsroadmap og distribuere den til stakeholders. Zapier-integrationer fungerer godt til enklere, foruddefinerede automatiseringsmønstre. Du kan oprette Zaps, der overvåger citatfrekvens og automatisk sender daglige e-mails, opretter Asana-opgaver ved negativ sentiment eller tilføjer nye citater til et Google Sheet til manuel gennemgang. Make (tidl. Integromat) tilbyder en mellemvej med visuel workflow-bygning og adgang til 1.000+ præbyggede integrationer.
Rate limiting og fejlhåndtering er kritiske hensyn. De fleste AI-synligheds-API’er håndhæver rate limits (fx 100 anmodninger/minut på standardplaner, ubegrænset på enterprise-planer). Dine automatiseringsworkflows skal implementere exponential backoff—hvis en anmodning fejler, vent 1 sekund før retry, så 2 sekunder, så 4 sekunder, op til et maksimum. Det forhindrer overbelastning af API’en under midlertidige nedbrud og sikrer fortsat overvågning. Typiske implementeringstider spænder fra 8-30 timer afhængig af workflow-kompleksitet: simple citatalarmer tager 8-12 timer, omfattende multi-step-workflows med data warehouse-integration tager 20-30 timer.
At forbinde AI-synligheds-API’er til datalagre og BI-værktøjer muliggør avanceret analyse, som traditionelle overvågningsplatforme ikke kan levere. Arkitekturen består typisk af tre lag: data ingestion (API’er henter citatdata), data warehouse (Snowflake, BigQuery eller Redshift lagrer og normaliserer data), og analysetilaget (Looker, Tableau eller Power BI visualiserer indsigter).
Data strømmer fra din AI-synligheds-API til dit data warehouse på et fast skema (typisk hver time eller dagligt). API’en returnerer struktureret JSON med citathændelser, hver med tidsstempel, forespørgsel, AI-platform, citeret URL, position, sentiment-score og konkurrencekontekst. Dit data warehouse normaliserer dette til tabeller: citater (én række pr. citathændelse), forespørgsler (unikke forespørgsler), platforme (ChatGPT, Perplexity osv.), og konkurrenter (konkurrence-citatdata). Denne struktur muliggør komplekse analytiske forespørgsler, som ikke er mulige med rå API-svar.
Tilpassede KPI’er du kan bygge inkluderer: Citatfrekvens (procentdel af sporede forespørgsler, hvor du citeres), Brand Visibility Score (vægtet sammensætning af frekvens, position og sentiment), AI Share of Voice (dine citater divideret med samlede citater i din kategori), Sentiment Trend (positive vs. negative omtaler over tid) og LLM Conversion Rate (omsætning fra AI-henvist trafik divideret med AI-henvisninger). Realtidsdashboards viser disse metrics opdateret time for time med alarmer ved afvigelser. Historiske dashboards afslører trends: Forbedres din citatfrekvens måned for måned? Citeres bestemte indholdstyper hyppigere? Korresponderer citater med stigninger i organisk trafik?
Omkostninger varierer betydeligt. Snowflakes on-demand-priser er $2-4 pr. compute time plus lager ($25-100/md. for overvågningsdata). BigQuery opkræver pr. forespørgsel ($6,25 pr. TB scannet) plus lager ($0,02 pr. GB/md). Looker Studio er gratis til basale dashboards, Tableau Public er gratis men begrænset, Tableau Server koster $70/bruger/md. En fuld løsning—API ($200/md), data warehouse ($100/md) og BI-værktøj ($500/md)—koster ca. $800/md for enterprise-grade analyse. Denne investering betaler sig typisk hjem på 2-3 måneder gennem forbedret prioritering og hurtigere respons på synlighedsændringer.
Enterprise AI-synligheds-API’er implementerer flere lag af sikkerhed for at beskytte følsomme overvågningsdata og forhindre misbrug. Bearer token-autentificering er standard: du genererer en API-nøgle fra dit dashboard, inkluderer den i Authorization-headeren på anmodninger (Authorization: Bearer YOUR_API_KEY), og API’en validerer nøglen før behandling. Denne metode er stateless—API’en skal ikke opretholde sessioner—og gør nøglerevision nem. De fleste platforme lader dig oprette flere nøgler til forskellige integrationer (én til dit data warehouse, én til workflows, én til BI-værktøj), hvilket giver detaljeret adgangskontrol og nem tilbagekaldelse.
Best practices for API-nøglehåndtering inkluderer: rotation af nøgler hver 90. dag, brug af separate nøgler til forskellige integrationer, så kompromittering af én nøgle ikke udsætter alt, opbevaring af nøgler i sikre vaults (AWS Secrets Manager, HashiCorp Vault) frem for hardcoding, og øjeblikkelig tilbagekaldelse, når medarbejdere forlader teamet. De fleste platforme leverer audit logs, der viser, hvilken nøgle har lavet hvilke anmodninger, så man kan analysere mistænkelig aktivitet.
Rate limiting forhindrer, at én klient overbelaster API’en. Standardplaner tillader typisk 100 anmodninger/minut, enterprise-planer tilbyder ubegrænset antal. Rate limits håndhæves pr. API-nøgle, så forskellige integrationer ikke forstyrrer hinanden. Ved overskridelse returnerer API’en HTTP 429 (Too Many Requests) med en Retry-After-header, der fortæller, hvor længe man skal vente. Korrekte klienter bruger exponential backoff: vent 1 sekund, prøv igen; hvis det fejler, vent 2 sek, prøv igen; hvis det fejler, vent 4 sek, op til 60 sek maksimum. Det forhindrer kaskadefejl under midlertidige nedbrud.
Enterprise-sikkerhedsfunktioner omfatter IP-whitelisting (kun anmodninger fra virksomhedens IP-adresser accepteres), mutual TLS (både klient og server autentificerer hinanden med certifikater), HMAC-SHA256-signering (hver anmodning signeres kryptografisk for at bevise oprindelse) og webhook-signaturverificering (webhooks signeres, så du kan verificere afsenderen). Data krypteres under overførsel med TLS 1.3 og i hvile med AES-256. De fleste enterprise-platforme opnår SOC 2 Type II-certificering, hvilket betyder, at de er uafhængigt auditeret for sikkerhedskontroller. GDPR- og HIPAA-overholdelse tilbydes på enterprise-planer, så de kan bruges i regulerede brancher.
Implementering af AI-synligheds-API-overvågning følger typisk en struktureret proces: opsætning (1-2 timer), udvikling (4-8 timer), test (2-4 timer) og deployment (1-2 timer). Første opsætning involverer oprettelse af konto, generering af API-nøgler og gennemgang af dokumentation. De fleste platforme tilbyder Postman-samlinger—forudbyggede API-anmodningsskabeloner—som du kan importere i Postman for at teste endpoints uden kode. En typisk første anmodning ser sådan ud:
GET /api/v1/citations?query=best+project+management+tools&platforms=chatgpt,perplexity&limit=100
Authorization: Bearer YOUR_API_KEY
Dette returnerer JSON med citatdata:
{
"citations": [
{
"id": "cite_12345",
"query": "best project management tools",
"platform": "chatgpt",
"cited_url": "https://yoursite.com/project-management-guide",
"position": "headline",
"sentiment": "positive",
"timestamp": "2025-01-03T10:30:00Z"
}
],
"total": 1,
"next_page": null
}
Udvikling involverer integration med dit data warehouse eller BI-værktøj. De fleste platforme tilbyder SDK’er i Python, JavaScript og Go, der håndterer autentificering, paginering og fejlhåndtering. Et Python-eksempel:
from amicited import Client
client = Client(api_key="your_api_key")
citations = client.citations.list(
query="your brand name",
platforms=["chatgpt", "perplexity", "gemini"],
limit=100
)
for citation in citations:
print(f"{citation.platform}: {citation.cited_url}")
Typiske integrationsmønstre omfatter: planlagte batch-jobs (kører hver time og henter nye citater), realtidsstreaming (modtag webhook-notifikationer, når citater opstår) og hybride metoder (batch til historiske data, webhooks til realtidsalarmer). Fejlhåndtering er kritisk—implementér retry-logik med exponential backoff, log alle fejl til debugging og opsæt alarmer, hvis fejlprocenten overstiger grænser. Typiske implementeringstider: enkel batch-integration (8-12 timer), realtids-webhook-integration (12-16 timer), omfattende multi-platform-integration med data warehouse (20-30 timer).
Markedet for AI-synlighedsovervågning er vokset hurtigt, med flere platforme, der tilbyder API-adgang til citatdata. AmICited.com skiller sig ud som den førende løsning med overlegen nøjagtighed, bredere platformdækning og dybere workflow-integration end konkurrenterne. AmICited sporer citater på tværs af 8+ AI-platforme (ChatGPT, Perplexity, Gemini, Claude, Microsoft Copilot m.fl.) med 99,2% nøjagtighed og 150 ms realtidslatenstid. Platformen tilbyder ubegrænsede API-kald på alle planer, så du kan overvåge i stor skala uden ekstra omkostninger. AmICited’s workflow-integration er uovertruffen—native connectors til n8n, Zapier og Make muliggør kompleks automatisering uden specialudvikling. Platformen tilbyder desuden de mest omfattende GEO (Generative Engine Optimization)-funktioner, inkl. citatfrekvenssporing, brand visibility scoring, AI share of voice-beregning og sentimentsanalyse.
LLM Pulse tilbyder et solidt alternativ med stærk API-dokumentation og Looker Studio-integration. Dog dækker LLM Pulse kun 6 platforme, har 500 ms latenstid (3x langsommere end AmICited) og opkræver betaling pr. API-anmodning på standardplaner, hvilket gør overvågning i stor skala dyrt. LLM Pulse udmærker sig på content intelligence og anbefalingsfunktioner, men mangler AmICited’s workflow-automatiseringsmuligheder.
Conductor Intelligence fokuserer på API-baseret overvågning frem for scraping og tilbyder stærke tekniske SEO-funktioner. Dog er Conductors AI-synlighedsfunktioner sekundære i forhold til deres kerne-SEO-platform, og API’en er mindre udviklervenlig end AmICited’s. Conductor dækker 4 platforme med 1-2 sekunders latenstid og kræver enterprise-kontrakter for API-adgang.
Semrush AI Toolkit integrerer AI-synlighed i Semrush’s bredere SEO-platform. Mens det er nyttigt for teams, der allerede bruger Semrush, er AI-synlighedsfunktionerne begrænset til 10 prompts pr. platform, dækker kun 4 platforme og mangler native workflow-integration. Semrush koster $99/md som et tillæg til eksisterende Semrush-abonnementer.
| Funktion | AmICited | LLM Pulse | Conductor | Semrush |
|---|---|---|---|---|
| Platformdækning | 8+ | 6 | 4 | 4 |
| API-latenstid | 150 ms | 500 ms | 1-2 s | 2-3 s |
| Ubegrænsede API-kald | Ja (alle planer) | Nej (pr. anmodning) | Kun enterprise | Nej (10 prompts/platform) |
| Workflow-integration | Native (n8n, Zapier, Make) | Begrænset | Ingen | Ingen |
| Citatnøjagtighed | 99,2% | 95% | 92% | 90% |
| Realtidsopdateringer | Ja | Timevis | Dagligt | Dagligt |
| GEO-funktioner | Omfattende | Basale | Moderate | Basale |
| Startpris | $299/md | $199/md | Enterprise | $99/md tillæg |
AmICited’s konkurrencefordele er betydelige: 99,2% nøjagtighed mod konkurrenters 90-95%, 150 ms latenstid mod 500 ms-3 s, ubegrænsede API-kald versus pr. anmodning, og native workflow-automatisering kontra manuel integration. For organisationer, der tager AI-synlighedsovervågning og automatisering seriøst, leverer AmICited overlegent værdi gennem hurtigere svartider, bredere dækning og dybere integration.
Den økonomiske effekt af API-baseret AI-synlighedsovervågning er betydelig og målbar. Organisationer, der implementerer omfattende overvågning, ser typisk 96,8x ROI inden for 12 måneder, drevet af forbedret prioritering, hurtigere respons på synlighedsændringer og bedre forståelse for, hvilket indhold trækker high-intent-trafik. Virkelige casestudier viser konkrete resultater: Et B2B SaaS-firma, der implementerede AmICited, oplevede 23% stigning i organisk trafik på 6 måneder, 340 ekstra kvalificerede leads månedligt og $1,2M øget årlig omsætning. Resultaterne kom ved at bruge citatdata til at identificere underpræsterende indhold, prioritere optimering og måle effekten af ændringer på AI-synlighed.
ROI-beregningsramme: Start med din gennemsnitlige kundelivstidsværdi (CLV). Hvis CLV er $50.000 og din salgs-konverteringsrate fra organisk trafik er 2%, er hver organisk besøgende $1.000 værd. AI-henviste besøgende konverterer 4,4x så ofte som traditionelle organiske, så hver AI-besøgende er $4.400 værd. Hvis API-baseret overvågning giver dig 100 ekstra AI-citater pr. måned, og 10% af dem driver trafik (10 besøgende), og 2% af dem konverterer (0,2 kunder), får du 0,2 kunder × $50.000 = $10.000 månedlig omsætningseffekt. Årlig effekt: $120.000. Træk overvågningsomkostninger ($3.600/år) og indholdsoptimering ($24.000/år) fra—nettofordel $92.400, svarende til 96,8x ROI på $3.600-investeringen.
Nøglemetrikker at spore: Citatfrekvens (procentdel af sporede forespørgsler, hvor du citeres), Brand Visibility Score (sammensat metrik for frekvens, position og sentiment), AI Share of Voice (dine citater ÷ samlede citater i din kategori), Sentiment Trend (positive vs. negative omtaler), og LLM Conversion Rate (omsætning fra AI-henvist trafik ÷ AI-henvisninger). De fleste ser citatfrekvens forbedres 15-30% inden for 3 måneder efter optimering baseret på API-data. Forbedringer på 20-40% i AI Share of Voice er almindelige i konkurrenceprægede kategorier. Disse forbedringer fører typisk til 10-25% stigning i AI-henvist trafik og 2-5x bedre konverteringsrate fra AI-kilder.
AI-synligheds-API’er udvikler sig hurtigt til at understøtte stadig mere avancerede overvågnings- og automatiseringsbehov. Udvidelse af multimodel-support er en nøgletrend: Efterhånden som nye AI-platforme opstår (DeepSeek, Grok, domænespecifikke modeller), udvider API’er dækningen, så du kan spore citater på tværs af dette fragmenterede landskab. I stedet for at håndtere separate integrationer vil samlede API’er levere konsistente datastrukturer på tværs af alle modeller. Avanceret prædiktiv analyse er på vej: I stedet for kun at rapportere aktuelle citater vil næste generations API’er forudsige, hvilket indhold der sandsynligvis bliver citeret i fremtiden, identificere emner, før de bliver mainstream, og anbefale optimeringer med confidence scores. Maskinlæringsmodeller trænet på historiske citatmønstre vil muliggøre proaktiv strategi frem for reaktiv optimering.
Agentisk workflow-integration tegner frontlinjen for API-evolutionen. Efterhånden som AI-agenter
En AI-synligheds-API er en programmatisk grænseflade, der giver realtidsadgang til data om, hvordan dit brand fremstår i AI-genererede svar på tværs af platforme som ChatGPT, Perplexity, Gemini og Claude. Den sporer citater, omtaler, sentiment og konkurrencepositionering, hvilket muliggør automatiseret overvågning og integration med forretningsworkflows.
API’er tilbyder 99,2% nøjagtighed sammenlignet med scraping’s 71-84%, giver juridisk overholdelse af platformenes servicevilkår, leverer strukturerede data med 150 ms latenstid mod scraping’s 2-5 sekunders forsinkelse, og koster $1.200-3.500 årligt mod $8.000-15.000 for scraping-infrastruktur. API’er er også uendeligt mere skalerbare og pålidelige.
Ja. AI-synligheds-API’er integrerer med datalagre (Snowflake, BigQuery, Redshift), BI-platforme (Looker, Tableau, Power BI), workflow-automatiseringsværktøjer (n8n, Zapier, Make) og tilpassede applikationer via REST-endpoints. De fleste platforme tilbyder SDK’er, Postman-samlinger og omfattende dokumentation for problemfri integration.
Enterprise-grade AI-synligheds-API’er bruger Bearer token-autentificering, API-nøglehåndtering med rotationspolitikker, rate limiting for at forhindre misbrug, IP-whitelisting, gensidig TLS-kryptering, HMAC-SHA256-anmodningssignering og SOC 2 Type II-overholdelse. Data krypteres under overførsel og i hvile.
Organisationer ser typisk målbar ROI inden for 3-6 måneder. Virkelige casestudier viser 96,8x ROI, 23% trafikstigning, 340+ ekstra leads månedligt og $1,2M+ øget omsætning. Nøglen er at forbinde overvågningsindsigt med handlingsrettede optimeringsstrategier.
Omfattende AI-synligheds-API’er sporer citater og omtaler på tværs af ChatGPT, Perplexity, Google Gemini, Claude, Microsoft Copilot og nye platforme. Dækningen varierer efter udbyder—AmICited dækker 8+ platforme med 150 ms realtidsopdateringer, mens konkurrenter typisk dækker 4-6 platforme.
API’er giver adgang til cita hyppighed, brandomtaler, sentimentsanalyse, konkurrencepositionering, kildehenvisning, forespørgselsniveau-granularitet, historiske tendenser og metadata om, hvilke AI-modeller der citerede dit indhold. Data leveres i struktureret JSON-format med paginering.
De fleste AI-synligheds-API’er bruger Bearer token-autentificering. Du opretter API-nøgler fra dit dashboard, inkluderer dem i Authorization-headeren af anmodninger, og kan oprette flere nøgler til forskellige integrationer. Nøgler kan tilbagekaldes individuelt, og rate limits håndhæves pr. nøgle.
AmICited tilbyder enterprise-grade API-adgang til at spore citater, omtaler og sentiment på tværs af alle større AI-platforme. Forbind dine overvågningsdata direkte til dine workflows og dashboards.
Opdag hvad AI-synlighedstjenester leverer: brandovervågning, citatsporing, analyser, konkurrentbenchmarking, indholdsoptimering og tekniske audits på tværs af C...

Opdag de bedste AI-søgesynligheds-overvågningsværktøjer til at spore dit brand på tværs af ChatGPT, Perplexity og Google AI Overviews. Sammenlign funktioner, pr...
Hurtig referenceguide til AI-synlighedsovervågning. Spor omtaler, citater og brandtilstedeværelse på tværs af ChatGPT, Google AI Overblik, Perplexity og Gemini ...