
Skal du blokere eller tillade AI-crawlere? Beslutningsramme
Lær at træffe strategiske beslutninger om blokering af AI-crawlere. Vurder indholdstype, trafikkilder, indtægtsmodeller og konkurrenceposition med vores omfatte...
11 min læsning
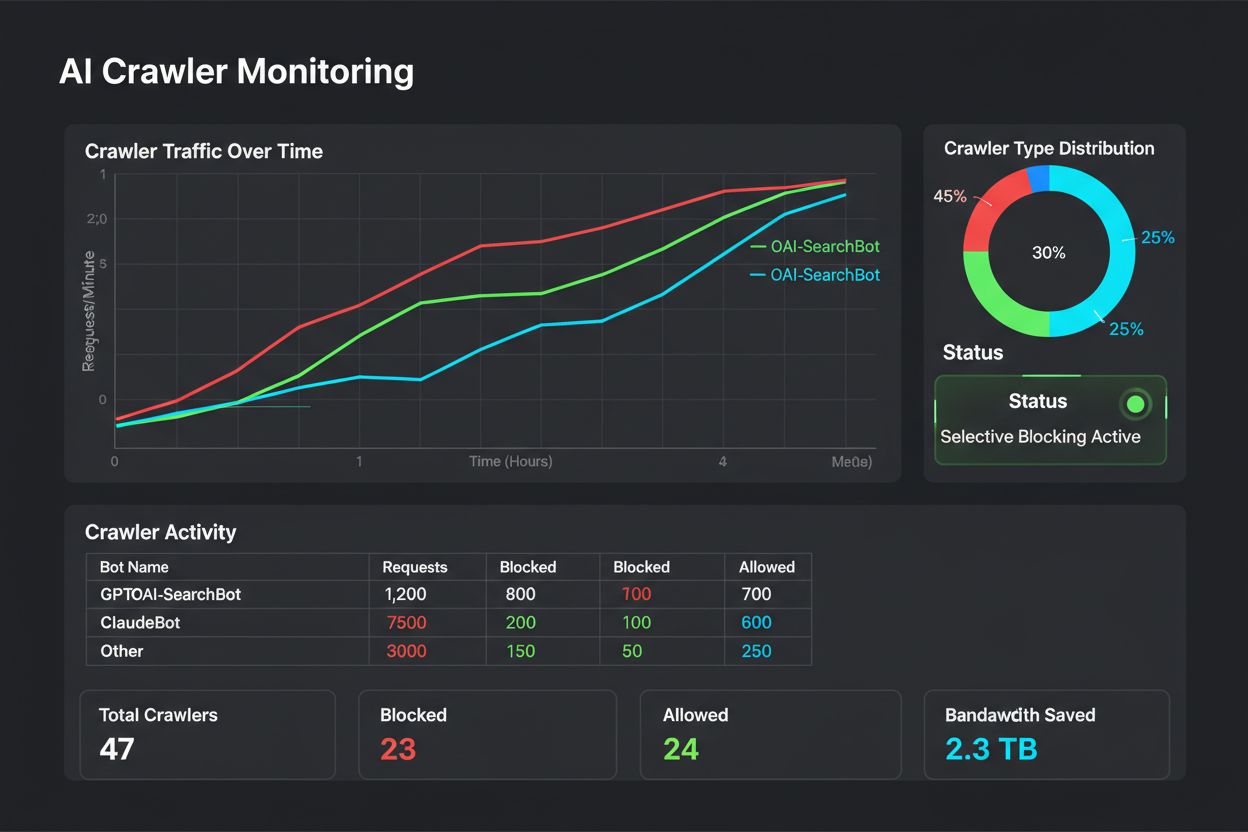
Lær hvordan du implementerer selektiv blokering af AI-crawlere for at beskytte dit indhold mod træningsbotter og samtidig bevare synligheden i AI-søgeresultater. Tekniske strategier for udgivere.
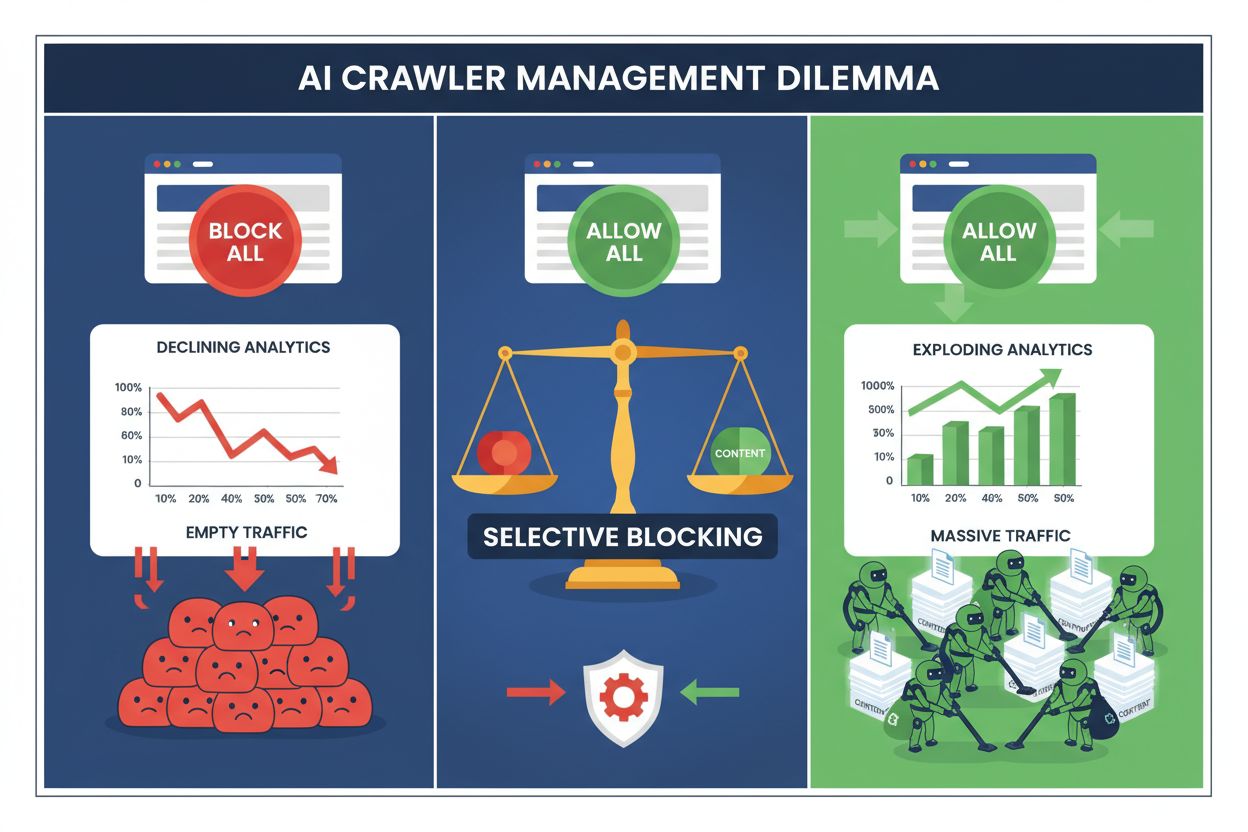
Udgivere står i dag over for et umuligt valg: blokér alle AI-crawlere og mist værdifuld søgemaskinetrafik, eller tillad dem alle og se dit indhold blive brugt til træningsdatasæt uden kompensation. Fremkomsten af generativ AI har skabt et todelt crawler-økosystem, hvor de samme robots.txt-regler gælder ubetinget for både søgemaskiner, der skaber indtjening, og træningscrawlere, der udtrækker værdi. Dette paradoks har tvunget fremsynede udgivere til at udvikle selektive crawlerkontrolstrategier, der skelner mellem forskellige typer AI-botter baseret på deres faktiske indvirkning på forretningsmål.
AI-crawlerlandskabet er opdelt i to forskellige kategorier med vidt forskellige formål og forretningsmæssige implikationer. Træningscrawlere – drevet af virksomheder som OpenAI, Anthropic og Google – er designet til at indsamle enorme mængder tekstdata for at bygge og forbedre store sprogmodeller, mens søgemaskinecrawlere indekserer indhold til genfinding og opdagelse. Træningsbotter udgør cirka 80% af al AI-relateret botaktivitet, men de genererer nul direkte indtægter for udgivere, mens søgemaskinecrawlere som Googlebot og Bingbot driver millioner af besøg og annoncevisninger årligt. Forskellen er vigtig, fordi en enkelt træningscrawler kan forbruge båndbredde svarende til tusindvis af menneskelige brugere, mens søgemaskinecrawlere er optimeret for effektivitet og typisk respekterer raterestriktioner.
| Botnavn | Operatør | Primært formål | Trafikpotentiale |
|---|---|---|---|
| GPTBot | OpenAI | Modelltræning | Ingen (dataudtræk) |
| Claude Web Crawler | Anthropic | Modelltræning | Ingen (dataudtræk) |
| Googlebot | Søgeindeksering | 243,8 mio. besøg (april 2025) | |
| Bingbot | Microsoft | Søgeindeksering | 45,2 mio. besøg (april 2025) |
| Perplexity Bot | Perplexity AI | Søgning + træning | 12,1 mio. besøg (april 2025) |
Tallene taler for sig selv: ChatGPT’s crawler alene sendte 243,8 millioner besøg til udgivere i april 2025, men disse besøg genererede nul klik, nul annoncevisninger og nul indtægter. Imens blev Googlebots trafik omsat til reel brugerengagement og indtjeningsmuligheder. At forstå denne forskel er det første skridt mod en selektiv blokeringsstrategi, der beskytter dit indhold og samtidig bevarer din synlighed i søgninger.
Total blokering af alle AI-crawlere er økonomisk selvdestruktivt for de fleste udgivere. Mens træningscrawlere udtrækker værdi uden kompensation, er søgemaskinecrawlere stadig en af de mest pålidelige trafikkilder i et stadig mere fragmenteret digitalt landskab. Det økonomiske argument for selektiv blokering bygger på flere nøglefaktorer:
Udgivere, der implementerer selektiv blokering, rapporterer om opretholdt eller forbedret søgetrafik, mens uautoriseret udtrækning af indhold reduceres med op til 85%. Den strategiske tilgang anerkender, at ikke alle AI-crawlere er ens, og at en nuanceret politik tjener forretningen langt bedre end en alt-eller-intet-tilgang.
Robots.txt-filen er fortsat det primære værktøj til at kommunikere crawler-tilladelser, og den er overraskende effektiv til at skelne mellem forskellige bottyper, når den er korrekt konfigureret. Denne simple tekstfil, placeret i dit websites rodmappe, bruger user-agent-direktiver til at angive, hvilke crawlere der kan få adgang til hvilket indhold. Til selektiv AI-crawlerkontrol kan du tillade søgemaskiner og blokere træningscrawlere med kirurgisk præcision.
Her er et praktisk eksempel, der blokerer træningscrawlere og tillader søgemaskiner:
# Bloker OpenAI's GPTBot
User-agent: GPTBot
Disallow: /
# Bloker Anthropics Claude crawler
User-agent: Claude-Web
Disallow: /
# Bloker andre træningscrawlere
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Tillad søgemaskiner
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Denne tilgang giver klare instruktioner til velopdragne crawlere og bevarer dit websites synlighed i søgeresultater. Men robots.txt er grundlæggende en frivillig standard – den er afhængig af, at crawler-operatører respekterer dine direktiver. For udgivere, der er bekymrede for overholdelse, er yderligere håndhævelseslag nødvendige.
Robots.txt kan ikke alene garantere overholdelse, fordi cirka 13% af AI-crawlere ignorerer robots.txt-direktiver fuldstændigt, enten af forsømmelse eller bevidst omgåelse. Serverbaseret håndhævelse via dit webserver- eller applikationslag giver en teknisk bagstopper, der forhindrer uautoriseret adgang uanset crawleradfærd. Denne tilgang blokerer anmodninger på HTTP-niveau, før de bruger nævneværdige ressourcer eller båndbredde.
Implementering af serverbaseret blokering med Nginx er ligetil og meget effektivt:
# I din Nginx serverblok
location / {
# Bloker træningscrawlere på serverniveau
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Bloker efter IP-intervaller om nødvendigt (for crawlere der spoof'er user agents)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Fortsæt med normal forespørgselsbehandling
proxy_pass http://backend;
}
Denne konfiguration returnerer et 403 Forbidden-svar til blokerede crawlere og bruger minimale serverressourcer, samtidig med at det klart kommunikeres, at adgangen nægtes. Kombineret med robots.txt skaber serverbaseret håndhævelse et todelt forsvar, der fanger både overholdende og ikke-overholdende crawlere. Omgåelsesraten på 13% falder til nær nul, når serverregler implementeres korrekt.
Content Delivery Networks og Web Application Firewalls giver et ekstra håndhævelseslag, der fungerer inden anmodninger når dine oprindelsesservere. Tjenester som Cloudflare, Akamai og AWS WAF gør det muligt at oprette regler, der blokerer specifikke user agents eller IP-intervaller ved kanten, så skadelige eller uønskede crawlere forhindres i at bruge dine infrastrukturressourcer. Disse tjenester vedligeholder opdaterede lister over kendte træningscrawler-IP-intervaller og user agents og blokerer dem automatisk uden manuel opsætning.
CDN-kontrol har flere fordele frem for serverbaseret håndhævelse: de reducerer belastningen på oprindelsesserveren, giver mulighed for geografisk blokering og tilbyder realtidsanalyse af blokerede anmodninger. Mange CDN-udbydere tilbyder nu AI-specifikke blokeringsregler som standardfunktion, da bekymringen omkring uautoriseret træningsdataudtrækning er udbredt blandt udgivere. For udgivere, der bruger Cloudflare, giver aktivering af “Block AI Crawlers”-indstillingen i sikkerhedsindstillinger ét klik beskyttelse mod de største træningscrawlere og bevarer samtidig søgemaskineadgang.
Effektiv selektiv blokering kræver en systematisk tilgang til klassificering af crawlere ud fra deres forretningsmæssige betydning og pålidelighed. I stedet for at behandle alle AI-crawlere ens, bør udgivere implementere en tredelt ramme, der afspejler den faktiske værdi og risiko, hver crawler udgør. Denne ramme muliggør nuancerede beslutninger, der balancerer indholdsbeskyttelse med forretningsmuligheder.
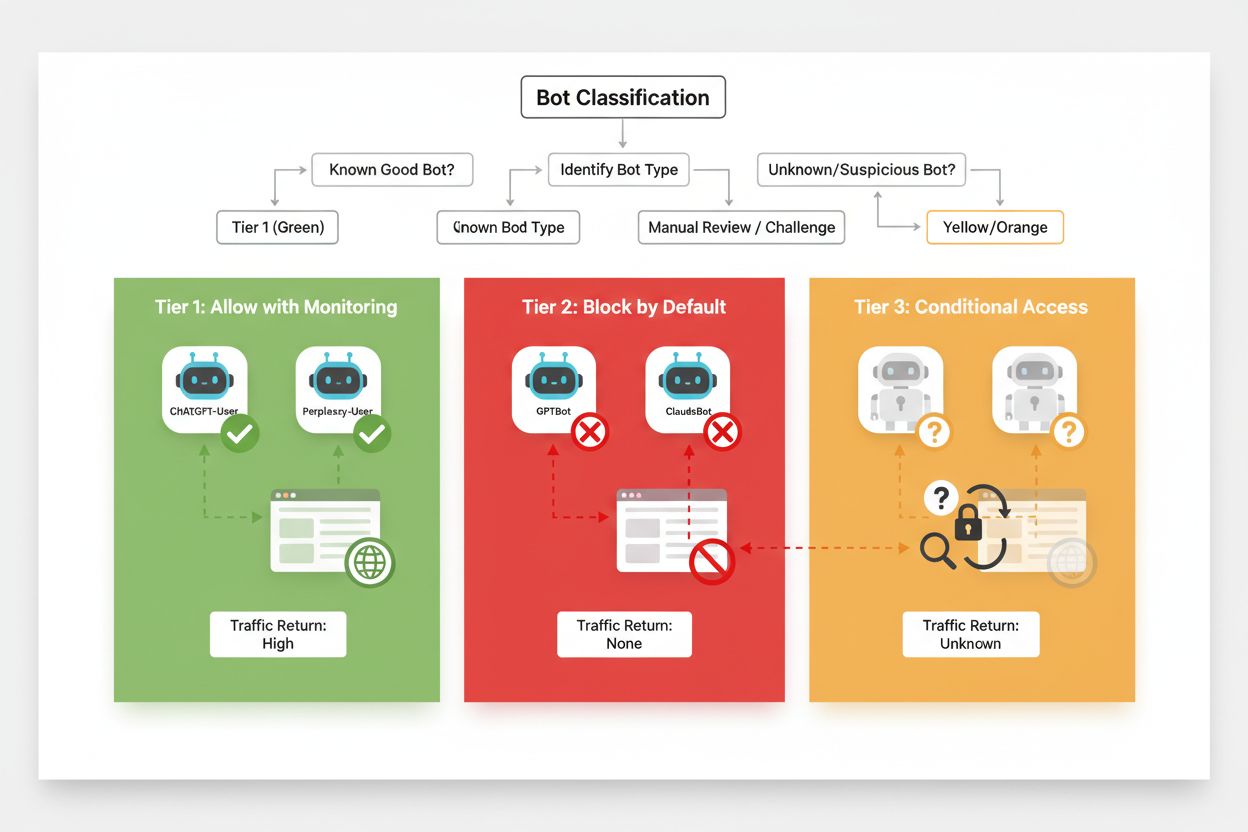
| Niveau | Klassifikation | Eksempler | Handling |
|---|---|---|---|
| Niveau 1: Indtægtsgeneratorer | Søgemaskiner og store henvisningskilder | Googlebot, Bingbot, Perplexity Bot | Tillad fuld adgang og optimer crawlbarhed |
| Niveau 2: Neutrale/Uafprøvede | Nye eller fremvoksende crawlere med uklar hensigt | Mindre AI-startups, forskningsbotter | Overvåg nøje, tillad med raterestriktioner |
| Niveau 3: Værdiekstraktorer | Træningscrawlere uden direkte fordel | GPTBot, Claude-Web, CCBot | Bloker fuldstændigt og håndhæv på flere lag |
Implementering af denne ramme kræver løbende research i nye crawlere og deres forretningsmodeller. Udgivere bør regelmæssigt tjekke adgangslogs for at identificere nye botter, undersøge operatørernes vilkår og kompensationspolitikker og justere klassificeringerne derefter. En crawler, der starter i niveau 3, kan rykke op til niveau 2, hvis operatøren begynder at tilbyde indtjeningsdeling, mens en tidligere pålidelig crawler kan rykke ned til niveau 3, hvis den begynder at overtræde raterestriktioner eller robots.txt.
Selektiv blokering er ikke en konfigurer-og-glem-løsning – det kræver løbende overvågning og justering, efterhånden som crawler-økosystemet udvikler sig. Udgivere bør implementere omfattende logging og analyse for at spore, hvilke crawlere der tilgår deres indhold, hvor meget båndbredde de bruger, og om de respekterer de konfigurerede begrænsninger. Disse data informerer de strategiske beslutninger om, hvilke crawlere der skal tillades, blokeres eller raterestriktionsstyres.
Analyse af dine adgangslogs afslører crawleradfærd, der informerer politikjusteringer:
# Identificer alle AI-crawlere, der tilgår dit site
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Beregn båndbredde brugt af bestemte crawlere
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot båndbredde: " sum/1024/1024 " MB"}'
# Overvåg 403-responser til blokerede crawlere
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Regelmæssig analyse af disse data – gerne ugentligt eller månedligt – viser, om din blokeringsstrategi virker som tiltænkt, om der er kommet nye crawlere, og om tidligere blokerede crawlere har ændret adfærd. Disse oplysninger indarbejdes i din klassifikationsramme, så dine politikker forbliver i tråd med forretningsmål og teknisk virkelighed.
Udgivere, der implementerer selektiv blokering af crawlere, begår ofte fejl, der underminerer deres strategi eller skaber utilsigtede konsekvenser. Forståelse af disse faldgruber hjælper dig med at undgå dyre fejl og implementere en mere effektiv politik fra starten.
At blokere alle crawlere uden skelnen: Den mest almindelige fejl er at bruge alt for brede blokeringsregler, der også rammer søgemaskiner og dermed ødelægger søgesynligheden i forsøget på at beskytte indholdet.
At stole udelukkende på robots.txt: At tro, at robots.txt alene forhindrer uautoriseret adgang, ignorerer de 13% af crawlere, der ignorerer den helt, og efterlader dit indhold sårbart over for målrettet dataudtrækning.
Ikke at overvåge og justere: At implementere en statisk blokeringspolitik uden at revidere den betyder, at du overser nye crawlere, ikke tilpasser dig ændrede forretningsmodeller og måske blokerer fordelagtige crawlere, der har forbedret deres praksis.
Kun at blokere efter user agent: Avancerede crawlere spoof’er eller roterer user agents hyppigt, så blokering baseret på user agent er ineffektiv uden supplerende IP-regler og raterestriktioner.
At ignorere raterestriktioner: Selv tilladte crawlere kan bruge overdreven båndbredde uden raterestriktioner, hvilket forringer ydeevnen for menneskelige brugere og bruger unødvendige infrastrukturressourcer.
Forholdet mellem udgivere og AI-crawlere vil sandsynligvis i fremtiden indebære mere sofistikerede forhandlings- og kompensationsmodeller i stedet for simpel blokering. Indtil industristandarder opstår, er selektiv kontrol med crawlere dog den mest praktiske metode til at beskytte indhold og samtidig bevare søgesynligheden. Udgivere bør betragte deres blokeringsstrategi som en dynamisk politik, der udvikler sig med crawlerlandskabet, hvor man løbende vurderer, hvilke crawlere der fortjener adgang baseret på deres forretningsmæssige indvirkning og pålidelighed.
De mest succesfulde udgivere bliver dem, der implementerer lagdelte forsvar – kombinerer robots.txt-direktiver, serverbaseret håndhævelse, CDN-kontrol og løbende overvågning i en samlet strategi. Denne tilgang beskytter mod både overholdende og ikke-overholdende crawlere og bevarer samtidig den søgemaskinetrafik, der driver indtjening og brugerengagement. Efterhånden som AI-virksomheder i stigende grad anerkender værdien af udgiverindhold og begynder at tilbyde kompensation eller licensaftaler, kan den ramme, du bygger i dag, nemt tilpasses til nye forretningsmodeller og samtidig bevare kontrollen over dine digitale aktiver.
Træningscrawlere som GPTBot og ClaudeBot indsamler data for at bygge AI-modeller uden at returnere trafik til dit site. Søgemaskinecrawlere som OAI-SearchBot og PerplexityBot indekserer indhold til AI-søgemaskiner og kan føre betydelig henvisningstrafik tilbage til dit site. Det er afgørende at forstå denne forskel for at implementere en effektiv selektiv blokeringsstrategi.
Ja, dette er kernen i selektiv kontrol af crawlere. Du kan bruge robots.txt til at nægte træningsbotter adgang og samtidig tillade søgebotter, og derefter håndhæve det med serverbaserede kontroller for botter, der ignorerer robots.txt. Denne tilgang beskytter dit indhold mod uautoriseret træning og bevarer synligheden i AI-søgeresultater.
De fleste store AI-virksomheder hævder at respektere robots.txt, men det er frivilligt. Forskning viser, at omkring 13% af AI-botter ignorerer robots.txt-direktiver fuldstændigt. Derfor er serverbaseret håndhævelse essentiel for udgivere, der er seriøse omkring at beskytte deres indhold mod ikke-kompatible crawlere.
Betydelig og voksende. ChatGPT sendte 243,8 millioner besøg til 250 nyheds- og mediewebsites i april 2025, en stigning på 98% fra januar. At blokere disse crawlere betyder at miste denne nye trafikkilde. For mange udgivere udgør AI-søgetrafik nu 5-15% af den samlede henvisningstrafik.
Gennemgå dine serverlogs regelmæssigt med grep-kommandoer for at identificere bot-user agents, spore crawl-frekvens og overvåge overholdelse af dine robots.txt-regler. Gennemgå logs mindst månedligt for at identificere nye botter, usædvanlige mønstre og om blokerede botter faktisk holder sig væk. Disse data informerer strategiske beslutninger om din crawlerpolitik.
Du beskytter dit indhold mod uautoriseret træning, men mister synlighed i AI-søgeresultater, går glip af nye trafikkilder og risikerer færre brandomtaler i AI-genererede svar. Udgivere, der implementerer total blokering, oplever ofte 40-60% fald i søgesynlighed og mister muligheder for brandopdagelse via AI-platforme.
Mindst månedligt, da der konstant opstår nye botter, og eksisterende botter ændrer adfærd. AI-crawlerlandskabet ændrer sig hurtigt, med nye aktører der starter crawlere og eksisterende spillere, der fusionerer eller omdøber deres botter. Regelmæssig gennemgang sikrer, at din politik forbliver i tråd med forretningsmål og tekniske realiteter.
Det er antallet af sider, der crawles i forhold til besøgende, der sendes tilbage til dit site. Anthropic crawler 38.000 sider for hver besøgende, der sendes tilbage, mens OpenAI har et forhold på 1.091:1, og Perplexity ligger på 194:1. Lavere forhold indikerer større værdi for at tillade crawleren. Dette målepunkt hjælper dig med at beslutte, hvilke crawlere der fortjener adgang baseret på deres reelle forretningsmæssige effekt.
AmICited sporer hvilke AI-platforme, der citerer dit brand og indhold. Få indsigt i din AI-synlighed og sikre korrekt attribuering på tværs af ChatGPT, Perplexity, Google AI Overviews og mere.
Lær at træffe strategiske beslutninger om blokering af AI-crawlere. Vurder indholdstype, trafikkilder, indtægtsmodeller og konkurrenceposition med vores omfatte...

Lær hvordan du blokerer eller tillader AI-crawlere som GPTBot og ClaudeBot ved hjælp af robots.txt, server-niveau blokering og avancerede beskyttelsesmetoder. K...

Lær hvordan webapplikationsfirewalls giver avanceret kontrol over AI-crawlere ud over robots.txt. Implementer WAF-regler for at beskytte dit indhold mod uautori...