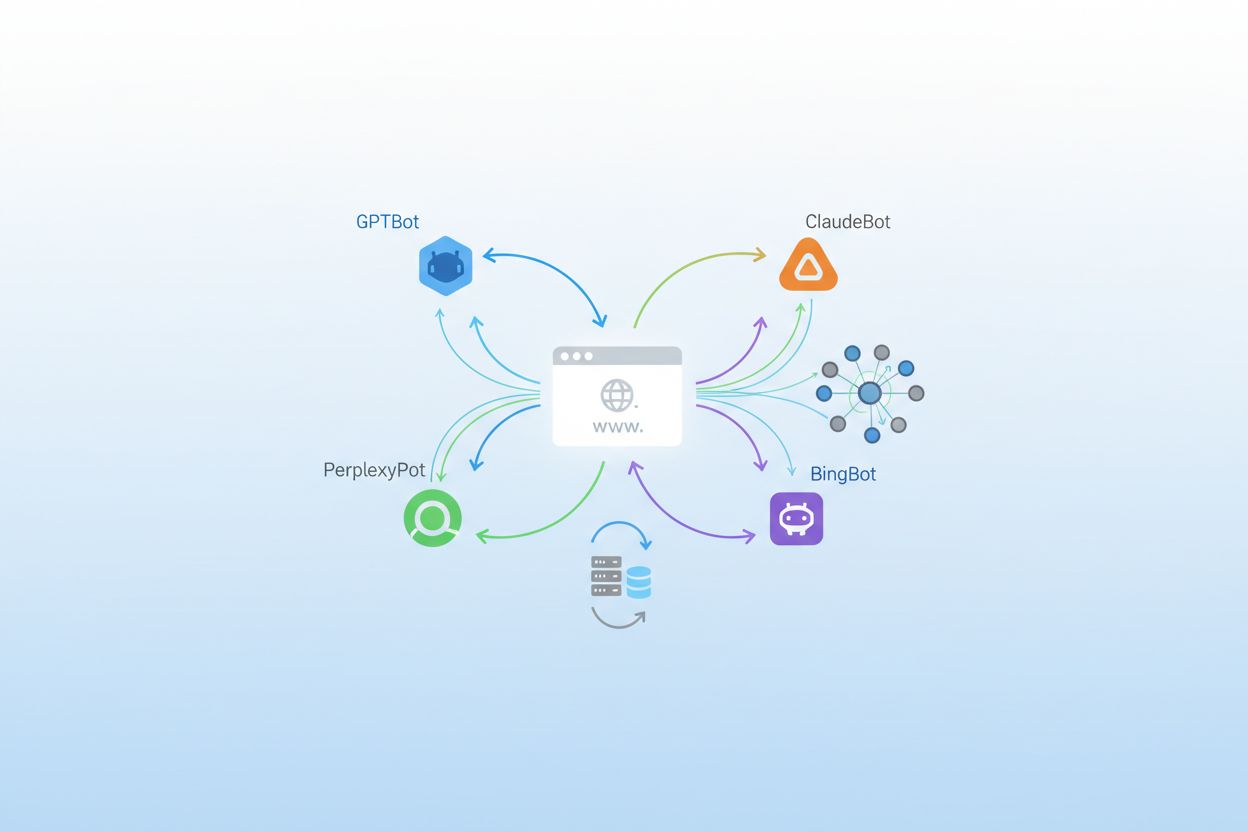
Komplet liste over AI-crawlere i 2025: Alle bots du bør kende
Omfattende guide til AI-crawlere i 2025. Identificér GPTBot, ClaudeBot, PerplexityBot og 20+ andre AI-bots. Lær hvordan du blokerer, tillader eller overvåger crawlere med robots.txt og avancerede teknikker.
Udgivet den Jan 3, 2026.Sidst ændret den Jan 3, 2026 kl. 3:24 am
AI-crawlere er automatiserede bots designet til systematisk at gennemse og indsamle data fra websites, men deres formål har fundamentalt ændret sig i de senere år. Hvor traditionelle søgemaskinecrawlere som Googlebot fokuserer på at indeksere indhold til søgeresultater, prioriterer moderne AI-crawlere indsamling af træningsdata til store sprogmodeller og generative AI-systemer. Ifølge nyere data fra Playwire udgør AI-crawlere nu cirka 80% af al AI-bottrafik, hvilket repræsenterer en dramatisk stigning i mængden og diversiteten af automatiserede besøgende på websites. Denne ændring afspejler den bredere transformation i, hvordan kunstig intelligens udvikles og trænes, hvor man bevæger sig væk fra offentligt tilgængelige datasæt mod indsamling af realtids webindhold. At forstå disse crawlere er blevet essentielt for websiteejere, udgivere og indholdsskabere, der skal træffe informerede beslutninger om deres digitale tilstedeværelse.
Tre kategorier af AI-crawlere
AI-crawlere kan klassificeres i tre distinkte kategorier baseret på funktion, adfærd og indvirkning på dit website. Træningscrawlere repræsenterer den største del og står for cirka 80% af AI-bottrafikken og er designet til at indsamle indhold til træning af maskinlæringsmodeller; disse crawlere opererer typisk med høj volumen og minimal henvisningstrafik, hvilket gør dem båndbreddekrævende, men usandsynlige til at sende besøgende tilbage til dit site. Søge- og citatcrawlere opererer med moderat volumen og er specifikt designet til at finde og referere indhold i AI-drevne søgeresultater og applikationer; i modsætning til træningscrawlere kan disse bots faktisk sende trafik til dit website, når brugere klikker sig videre fra AI-genererede svar. Brugerudløste fetchers udgør den mindste kategori og opererer on-demand, når brugere eksplicit anmoder om indhentning af indhold via AI-applikationer som ChatGPT’s browsing-funktion; disse crawlere har lav volumen, men høj relevans i forhold til den enkelte brugers forespørgsler.
OpenAI driver det mest forskelligartede og aggressive crawler-økosystem i AI-landskabet, med flere bots, der tjener forskellige formål på tværs af deres produktsuite. GPTBot er deres primære træningscrawler, ansvarlig for at indsamle indhold til at forbedre GPT-4 og fremtidige modeller, og har oplevet en svimlende 305% vækst i crawlertrafik ifølge Cloudflare-data; denne bot opererer med et 400:1 crawl-til-henvisning-forhold, hvilket betyder, at den downloader indhold 400 gange for hver besøgende, den sender tilbage til dit site. OAI-SearchBot har et helt andet formål og fokuserer på at finde og citere indhold til ChatGPT’s søgefunktion uden at bruge indholdet til modeltræning. ChatGPT-User repræsenterer den mest eksplosive vækstkategori med en bemærkelsesværdig 2.825% stigning i trafik og opererer, når brugere aktiverer “Browse with Bing”-funktionen for at hente realtidsindhold on-demand. Du kan identificere disse crawlere via deres user-agent-strenge: GPTBot/1.0, OAI-SearchBot/1.0 og ChatGPT-User/1.0, og OpenAI tilbyder IP-verifikationsmetoder til at bekræfte legitim crawlertrafik fra deres infrastruktur.
Anthropics og Googles AI-crawlere
Anthropic, firmaet bag Claude, driver en af branchens mest selektive, men intensive crawler-operationer. ClaudeBot er deres primære træningscrawler og opererer med et ekstraordinært 38.000:1 crawl-til-henvisning-forhold, hvilket betyder, at den downloader indhold langt mere aggressivt end OpenAI’s bots i forhold til trafik sendt retur; dette ekstreme forhold afspejler Anthropics fokus på omfattende dataindsamling til modeltræning. Claude-Web og Claude-SearchBot tjener forskellige formål, hvor førstnævnte håndterer brugerudløst indholdshentning, og sidstnævnte fokuserer på søge- og citatfunktionalitet. Google har tilpasset deres crawlerstrategi til AI-tidsalderen ved at introducere Google-Extended, et særligt token, der gør det muligt for websites at tilvælge AI-træning, mens de blokerer traditionel Googlebot-indeksering, samt Gemini-Deep-Research, der udfører dybdegående forespørgsler for brugere af Googles AI-produkter. Mange websiteejere debatterer, om de skal blokere Google-Extended, da det kommer fra samme firma, der styrer søgetrafikken, hvilket gør beslutningen mere kompleks end ved tredjeparts AI-crawlere.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Meta, Apple, Amazon og Perplexity
Meta er blevet en betydelig aktør på AI-crawler-markedet med Meta-ExternalAgent, som tegner sig for cirka 19% af AI-crawler-trafikken og bruges til at træne deres AI-modeller og drive funktioner på tværs af Facebook, Instagram og WhatsApp. Meta-WebIndexer har en komplementær funktion, idet den fokuserer på webindeksering til deres AI-drevne funktioner og anbefalinger. Apple introducerede Applebot-Extended for at understøtte Apple Intelligence, deres AI-funktioner på enheden, og denne crawler er vokset støt, efterhånden som virksomheden udvider sine AI-evner på iPhone, iPad og Mac-enheder. Amazon driver Amazonbot til at understøtte Alexa og Rufus, deres AI-shoppingassistent, hvilket gør den relevant for e-handelssites og produktfokuseret indhold. PerplexityBot repræsenterer en af de mest dramatiske væksthistorier på crawler-landskabet med en forbløffende 157.490% stigning i trafik, hvilket afspejler den eksplosive vækst hos Perplexity AI som et søgealternativ; trods denne massive vækst repræsenterer Perplexity stadig et mindre absolut volumen sammenlignet med OpenAI og Google, men udviklingen indikerer hurtigt stigende betydning.
Fremvoksende og specialiserede crawlere
Ud over de store aktører indsamler adskillige nye og specialiserede AI-crawlere aktivt data fra websites på tværs af internettet. Bytespider, drevet af ByteDance (moderselskab til TikTok), oplevede et markant 85% fald i crawlertrafik, hvilket antyder enten et skift i strategi eller reduceret behov for træningsdata. Cohere, Diffbot og Common Crawl’s CCBot repræsenterer specialiserede crawlere med fokus på særlige anvendelser, fra sprogmodeltræning til udtræk af struktureret data. You.com, Mistral og DuckDuckGo driver hver især egne crawlere for at understøtte deres AI-drevne søge- og assistentfunktioner, hvilket øger kompleksiteten på crawler-landskabet. Der opstår jævnligt nye crawlere, hvor både startups og etablerede virksomheder løbende lancerer AI-produkter, der kræver webdata. At holde sig informeret om disse nye crawlere er afgørende, da blokering eller tilladelse kan have stor indflydelse på din synlighed i nye AI-drevne opdagelsesplatforme og applikationer.
Sådan identificerer du AI-crawlere
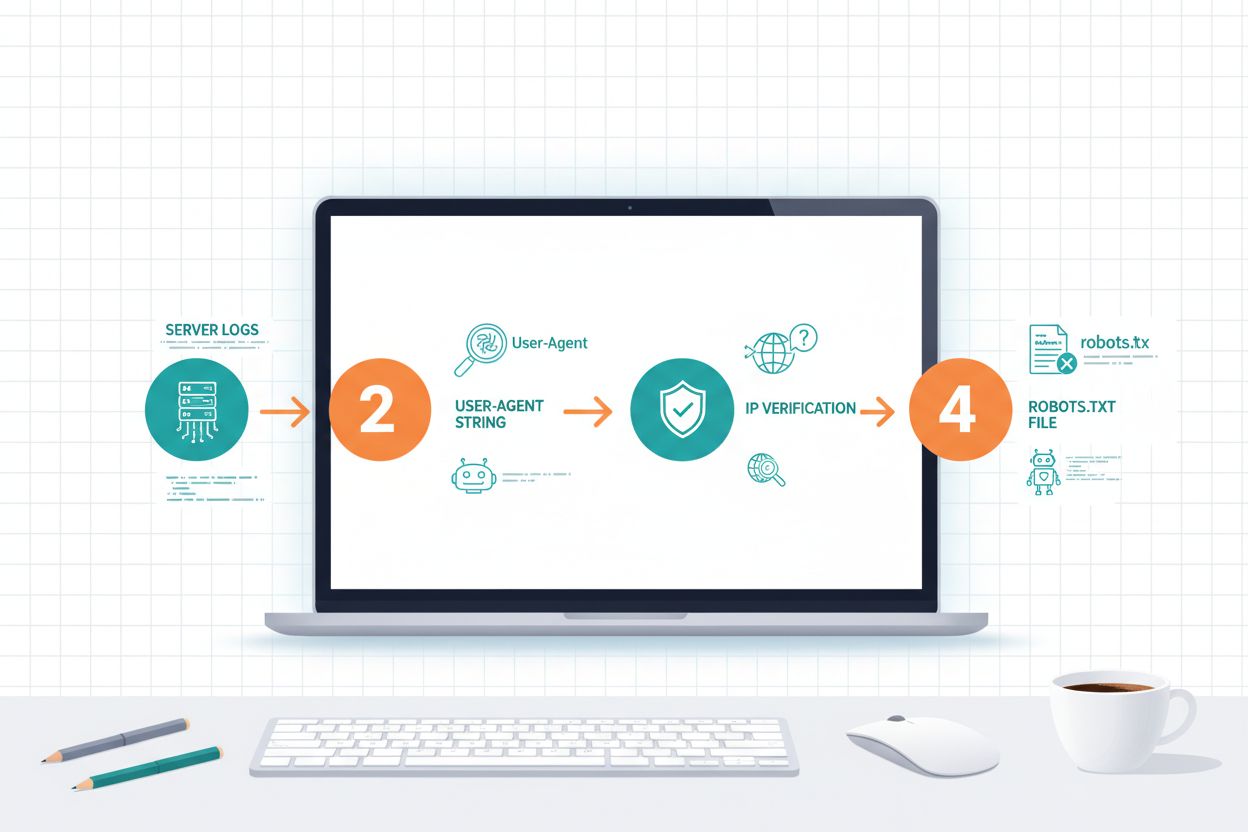
Identifikation af AI-crawlere kræver forståelse for, hvordan de identificerer sig selv, og analyse af dine servertrafikmønstre. User-agent-strenge er den primære identifikationsmetode, da hver crawler annoncerer sig med en specifik identifikator i HTTP-anmodninger; for eksempel bruger GPTBotGPTBot/1.0, ClaudeBot bruger Claude-Web/1.0, og PerplexityBot bruger PerplexityBot/1.0. Analyse af dine serverlogs (typisk placeret i /var/log/apache2/access.log på Linux-servere eller IIS-logs på Windows) lader dig se, hvilke crawlere der tilgår dit site, og hvor ofte. IP-verifikation er en anden vigtig teknik, hvor du kan kontrollere, at en crawler, der hævder at være fra OpenAI eller Anthropic, faktisk kommer fra deres legitime IP-intervaller, som disse firmaer offentliggør af sikkerhedshensyn. Gennemgang af din robots.txt-fil afslører, hvilke crawlere du eksplicit har tilladt eller blokeret, og sammenligning med din reelle trafik viser, om crawlere respekterer dine direktiver. Værktøjer som Cloudflare Radar giver realtidsindsigt i crawlertrafikmønstre og kan hjælpe dig med at identificere, hvilke bots der er mest aktive på dit site. Praktiske identifikationstrin omfatter: at tjekke din analyseplatform for bottrafik, gennemgå rå serverlogs for user-agent-mønstre, krydshenvise IP-adresser med offentliggjorte crawler-IP-intervaller og bruge online crawler-verifikationsværktøjer til at bekræfte mistænkelige trafikkilder.
Afvejninger: Blokering vs. tilladelse
At beslutte om du skal tillade eller blokere AI-crawlere indebærer at afveje flere konkurrerende forretningshensyn, som ikke har et entydigt svar. De primære afvejninger inkluderer:
Synlighed i AI-applikationer: Tilladelse af crawlere sikrer, at dit indhold vises i AI-drevne søgeresultater, opdagelsesplatforme og AI-assistent-svar, hvilket potentielt kan give trafik fra nye kilder
Båndbredde og serverbelastning: Træningscrawlere bruger betydelig båndbredde og serverressourcer, og nogle sites rapporterer 10-30% stigning i trafik alene fra AI-bots, hvilket kan øge hostingomkostningerne
Indholdsbeskyttelse vs. trafik: Blokering af crawlere beskytter dit indhold mod at blive brugt i AI-træning, men eliminerer muligheden for henvisningstrafik fra AI-drevne opdagelsesplatforme
Potentiale for henvisningstrafik: Søge- og citatcrawlere som PerplexityBot og OAI-SearchBot kan sende trafik til dit site, mens træningscrawlere som GPTBot og ClaudeBot typisk ikke gør det
Konkurrencepositionering: Konkurrenter, der tillader crawlere, kan opnå synlighed i AI-applikationer, mens du forbliver usynlig, hvilket påvirker din markedsposition i AI-drevet opdagelse
Da 80% af AI-bottrafik kommer fra træningscrawlere med minimal henvisningspotentiale, vælger mange udgivere at blokere træningscrawlere, mens de tillader søge- og citatcrawlere. Denne beslutning afhænger ultimativt af din forretningsmodel, indholdstype og strategiske prioriteter i forhold til AI-synlighed kontra ressourceforbrug.
Konfiguration af Robots.txt til AI-crawlere
Robots.txt-filen er dit primære værktøj til at kommunikere crawler-politikker til AI-bots, men det er vigtigt at forstå, at overholdelse er frivillig og ikke teknisk håndhævelig. Robots.txt bruger user-agent-matching til at målrette specifikke crawlere, så du kan lave forskellige regler for forskellige bots; for eksempel kan du blokere GPTBot, mens du tillader OAI-SearchBot, eller blokere alle træningscrawlere, men tillade søgecrawlere. Ifølge nyere forskning har kun 14% af de 10.000 største domæner implementeret AI-specifikke robots.txt-regler, hvilket indikerer, at de fleste websites endnu ikke har optimeret deres crawler-politikker til AI-tidsalderen. Filen bruger simpel syntaks, hvor du angiver et user-agent-navn efterfulgt af disallow- eller allow-direktiver, og du kan bruge wildcards til at matche flere crawlere med lignende navnemønstre.
Her er tre praktiske robots.txt-konfigurationsscenarier:
Husk, at robots.txt kun er vejledende, og ondsindede eller ikke-kompatible crawlere kan ignorere dine direktiver fuldstændigt. User-agent-matching er ikke følsom for store/små bogstaver, så gptbot, GPTBot og GPTBOT refererer til den samme crawler, og du kan bruge User-agent: * for at lave regler, der gælder for alle crawlere.
Avancerede beskyttelsesmetoder
Ud over robots.txt findes der flere avancerede metoder, der giver stærkere beskyttelse mod uønskede AI-crawlere, selvom de varierer i effektivitet og implementeringskompleksitet. IP-verifikation og firewall-regler giver dig mulighed for at blokere trafik fra specifikke IP-intervaller, der er tilknyttet AI-crawlere; du kan få disse intervaller fra crawler-operatørernes dokumentation og konfigurere din firewall eller Web Application Firewall (WAF) til at afvise anmodninger fra disse IP’er, selvom dette kræver løbende vedligeholdelse, da IP-intervaller ændrer sig. .htaccess-blokering på serverniveau giver Apache-serverbeskyttelse ved at tjekke user-agent-strenge og IP-adresser, inden indhold serveres, hvilket giver mere pålidelig håndhævelse end robots.txt, da det sker på serverniveau og ikke afhænger af crawlerens overholdelse.
Her er et praktisk .htaccess-eksempel på avanceret crawler-blokering:
# Bloker AI-træningscrawlere på serverniveau<IfModulemod_rewrite.c> RewriteEngine On# Bloker på user-agent-streng RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Bloker på IP-adresse (eksempel-IP'er - udskift med faktiske crawler-IP'er) RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Tillad specifikke crawlere, mens andre blokeres RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule># HTML meta tag-tilgang (tilføj til sidehoveder)# <meta name="robots" content="noarchive, noimageindex"># <meta name="googlebot" content="noindex, nofollow">
HTML meta-tags som <meta name="robots" content="noarchive"> og <meta name="googlebot" content="noindex"> giver kontrol på sideniveau, selvom de er mindre pålidelige end blokering på serverniveau, da crawlere skal læse HTML’en for at se dem. Det er vigtigt at bemærke, at IP-spoofing er teknisk muligt, hvilket betyder, at sofistikerede aktører kan udgive sig for at være legitime crawler-IP’er, så kombination af flere metoder giver bedre beskyttelse end at stole på én enkelt metode. Hver metode har forskellige fordele: robots.txt er let at implementere, men ikke håndhævet, IP-blokering er pålidelig men kræver vedligeholdelse, .htaccess giver serverniveau-håndhævelse, og meta-tags giver granularitet på sideniveau.
Overvågning og verifikation
Implementering af crawler-politikker er kun halvdelen af opgaven; du skal aktivt overvåge, om crawlere respekterer dine direktiver og justere din strategi baseret på reelle trafikmønstre. Serverlogs er din primære datakilde, typisk placeret i /var/log/apache2/access.log på Linux-servere eller i IIS logs-mappen på Windows-servere, hvor du kan søge efter specifikke user-agent-strenge for at se, hvilke crawlere der tilgår dit site, og hvor ofte. Analyseplatforme som Google Analytics, Matomo eller Plausible kan konfigureres til at spore bottrafik separat fra menneskelige besøgende, så du kan se mængden og adfærden af forskellige crawlere over tid. Cloudflare Radar giver realtidsindsigt i crawlertrafikmønstre på tværs af internettet og kan vise dig, hvordan dit sites crawlertrafik sammenlignes med branchens gennemsnit. For at verificere at crawlere respekterer dine blokeringer, kan du bruge onlineværktøjer til at tjekke din robots.txt-fil, gennemgå dine serverlogs for blokerede user-agents og krydstjekke IP-adresser med offentliggjorte crawler-IP-intervaller for at bekræfte, at trafikken faktisk kommer fra legitime kilder. Praktiske overvågningstrin omfatter: opsætning af ugentlig loganalyse for at spore crawlervolumen, konfigurering af advarsler for usædvanlig crawleraktivitet, månedlig gennemgang af din analysedashboard for bottrafiktendenser og kvartalsvise gennemgange af dine crawler-politikker for at sikre, at de stadig matcher dine forretningsmål. Regelmæssig overvågning hjælper dig med at identificere nye crawlere, opdage policy-overtrædelser og træffe datadrevne beslutninger om, hvilke crawlere du skal tillade eller blokere.
Fremtiden for AI-crawlere
AI-crawler-landskabet udvikler sig hurtigt, med nye aktører på markedet og eksisterende crawlere, der udvider deres kapaciteter i uventede retninger. Fremvoksende crawlere fra firmaer som xAI (Grok), Mistral og DeepSeek er begyndt at indsamle webdata i stor skala, og hver ny AI-startup, der lanceres, vil sandsynligvis introducere deres egen crawler til at understøtte modeltræning og produktfunktioner. Agentiske browsere repræsenterer en ny grænse inden for crawler-teknologi, med systemer som ChatGPT Operator og Comet, der kan interagere med websites som mennesker, klikke på knapper, udfylde formularer og navigere komplekse grænseflader; disse browserbaserede agenter udgør unikke udfordringer, da de er sværere at identificere og blokere med traditionelle metoder. Udfordringen med browserbaserede agenter er, at de måske ikke identificerer sig tydeligt i user-agent-strenge og potentielt kan omgå IP-blokering ved at bruge bolig-proxies eller distribueret infrastruktur. Nye crawlere dukker op jævnligt, nogle gange uden varsel, hvilket gør det essentielt at holde sig informeret om udviklingen i AI-rummet og justere sine politikker derefter. Udviklingen tyder på, at crawlertrafikken vil fortsætte med at vokse, hvor Cloudflare rapporterer en 18% samlet stigning i crawlertrafik fra maj 2024 til maj 2025, og denne vækst vil sandsynligvis accelerere, efterhånden som flere AI-applikationer når mainstream. Websiteejere og udgivere må forblive årvågne og omstillingsparate, regelmæssigt gennemgå deres crawler-politikker og overvåge nye udviklinger for at sikre, at deres strategier forbliver effektive i dette hurtigt udviklende landskab.
Overvåg dit brand i AI-svar
Selvom det er vigtigt at styre crawleradgang til dit website, er det lige så kritisk at forstå, hvordan dit indhold bruges og citeres i AI-genererede svar. AmICited.com er en specialiseret platform designet til at løse dette problem ved at spore, hvordan AI-crawlere indsamler dit indhold, og overvåge om dit brand og indhold bliver korrekt citeret i AI-drevne applikationer. Platformen hjælper dig med at forstå, hvilke AI-systemer der bruger dit indhold, hvor ofte din information optræder i AI-svar, og om korrekt kildeangivelse gives til dine originale kilder. For udgivere og indholdsskabere giver AmICited.com værdifuld indsigt i din synlighed i AI-økosystemet, så du kan måle effekten af din beslutning om at tillade eller blokere crawlere og forstå den reelle værdi, du får fra AI-drevet opdagelse. Ved at overvåge dine citationer på tværs af flere AI-platforme kan du træffe mere informerede beslutninger om dine crawler-politikker, identificere muligheder for at øge dit indholds synlighed i AI-svar og sikre, at din intellektuelle ejendom bliver korrekt krediteret. Hvis du er seriøs omkring at forstå dit brands tilstedeværelse på det AI-drevne web, tilbyder AmICited.com den transparens og overvågningskapacitet, du har brug for for at holde dig informeret og beskytte dit indholds værdi i denne nye æra af AI-drevet opdagelse.
Ofte stillede spørgsmål
Hvad er forskellen på træningscrawlere og søgecrawlere?
Træningscrawlere som GPTBot og ClaudeBot indsamler indhold for at opbygge datasæt til udvikling af store sprogmodeller, så det bliver en del af AI'ens vidensbase. Søgecrawlere som OAI-SearchBot og PerplexityBot indekserer indhold til AI-drevne søgeoplevelser og kan sende henvisningstrafik tilbage til udgivere via citater.
Bør jeg blokere alle AI-crawlere eller kun træningscrawlere?
Det afhænger af dine forretningsprioriteter. Blokering af træningscrawlere beskytter dit indhold mod at blive inkorporeret i AI-modeller. Blokering af søgecrawlere kan reducere din synlighed på AI-drevne opdagelsesplatforme som ChatGPT-søgning eller Perplexity. Mange udgivere vælger selektiv blokering, der retter sig mod træningscrawlere, mens de tillader søge- og citatcrawlere.
Hvordan kan jeg verificere, om en crawler er legitim eller spoofet?
Den mest pålidelige verifikationsmetode er at tjekke anmodningens IP mod officielt offentliggjorte IP-intervaller fra crawler-operatørerne. Store virksomheder som OpenAI, Anthropic og Amazon offentliggør deres crawler-IP-adresser. Du kan også bruge firewall-regler til at tillade verificerede IP'er og blokere anmodninger fra uverificerede kilder, der udgiver sig for at være AI-crawlere.
Vil blokering af Google-Extended påvirke mine søgerangeringer?
Google udtaler officielt, at blokering af Google-Extended ikke påvirker søgerangeringer eller inddragelse i AI Overviews. Dog har nogle webmastere udtrykt bekymringer, så overvåg din søgepræstation efter at have implementeret blokeringer. AI Overviews i Google Search følger standard Googlebot-regler, ikke Google-Extended.
Hvor ofte skal jeg opdatere min AI-crawler-blockliste?
Der opstår jævnligt nye AI-crawlere, så gennemgå og opdater din blockliste mindst kvartalsvist. Følg ressourcer som ai.robots.txt-projektet på GitHub for fællesskabsvedligeholdte lister. Tjek serverlogs månedligt for at identificere nye crawlere, der besøger dit site, men som ikke er i din nuværende konfiguration.
Kan AI-crawlere ignorere robots.txt-direktiver?
Ja, robots.txt er vejledende og ikke håndhævelig. Velopdragne crawlere fra store firmaer respekterer generelt robots.txt-direktiver, men nogle crawlere ignorerer dem. For stærkere beskyttelse skal du implementere blokering på serverniveau via .htaccess eller firewall-regler og verificere legitime crawlere ved hjælp af offentliggjorte IP-adresseintervaller.
Hvilken indvirkning har AI-crawlere på mit websites båndbredde?
AI-crawlere kan generere betydelig serverbelastning og båndbreddeforbrug. Nogle infrastrukturprojekter rapporterede, at blokering af AI-crawlere reducerede båndbreddeforbruget fra 800GB til 200GB dagligt, hvilket sparer ca. $1.500 om måneden. Udgivere med meget trafik kan opleve betydelige besparelser ved selektiv blokering.
Hvordan kan jeg overvåge, hvilke AI-crawlere der tilgår mit site?
Tjek dine serverlogs (typisk på /var/log/apache2/access.log på Linux) for user-agent-strenge, der matcher kendte crawlere. Brug analyseplatforme som Google Analytics eller Cloudflare Radar til at spore bottrafik separat. Opsæt advarsler for usædvanlig crawler-aktivitet og gennemfør kvartalsvise gennemgange af dine crawler-politikker.
Overvåg dit brand i AI-svar
Følg hvordan AI-platforme som ChatGPT, Perplexity og Google AI Overviews refererer til dit indhold. Få realtidsadvarsler, når dit brand nævnes i AI-genererede svar.
Sådan Tillader du AI-bots at Crawle Dit Website: Komplet robots.txt & llms.txt Guide
Lær hvordan du tillader AI-bots som GPTBot, PerplexityBot og ClaudeBot at crawle dit website. Konfigurer robots.txt, opsæt llms.txt og optimer for AI-synlighed....
Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit s...
Skal du blokere eller tillade AI-crawlere? Beslutningsramme
Lær at træffe strategiske beslutninger om blokering af AI-crawlere. Vurder indholdstype, trafikkilder, indtægtsmodeller og konkurrenceposition med vores omfatte...
11 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.