Listikler og AI: Hvorfor nummererede lister bliver citeret
Opdag hvorfor AI-modeller foretrækker listikler og nummererede lister. Lær hvordan du optimerer listebaseret indhold for ChatGPT-, Gemini- og Perplexity-citater med dokumenterede strategier.
Udgivet den Jan 3, 2026.Sidst ændret den Jan 3, 2026 kl. 3:24 am
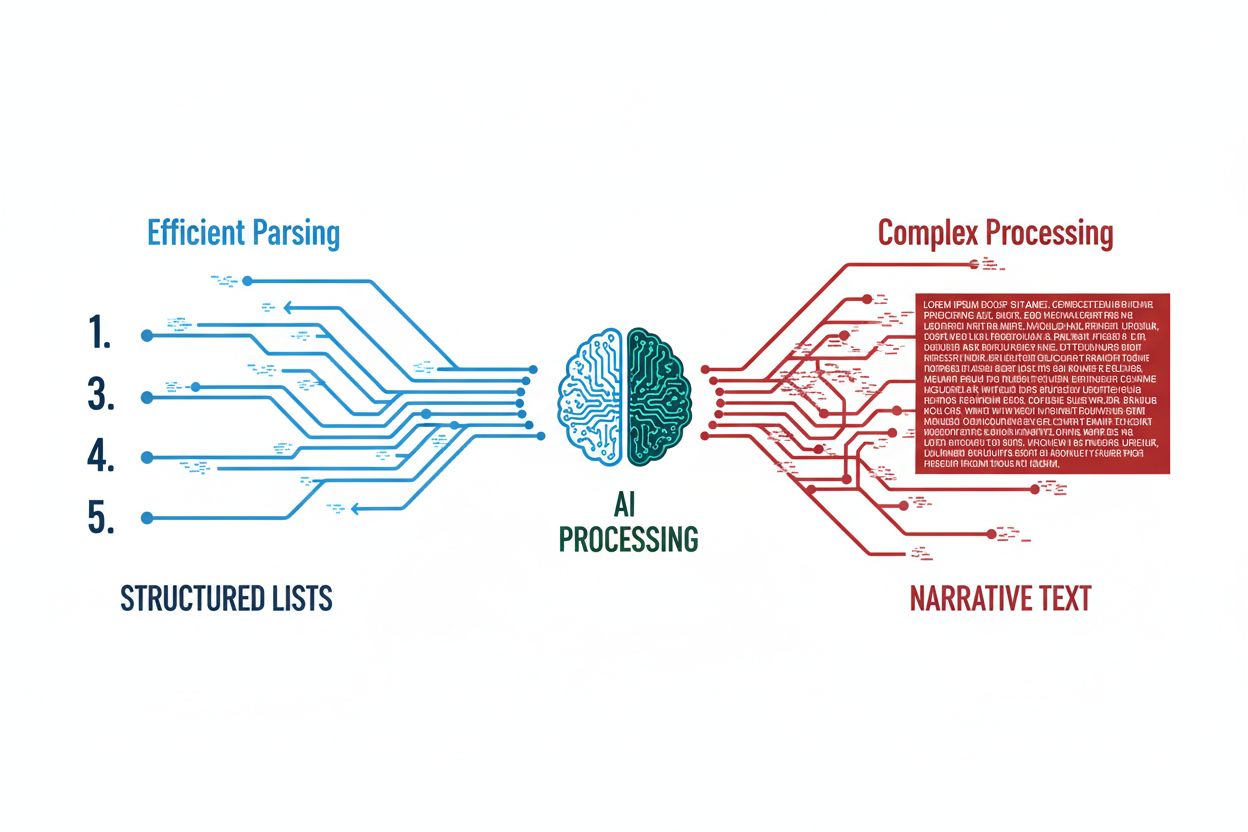
AI-modeller er grundlæggende mønstergenkendende maskiner, der udmærker sig ved at identificere og behandle information organiseret i forudsigelige, gentagelige formater. Når indholdet struktureres som en listikel, skabes et overskueligt, hierarkisk format, som LLM’er kan analysere langt mere effektivt end narrativ prosa. Struktureret indhold reducerer den beregningsmæssige kompleksitet, der kræves for, at sprogmodeller kan udtrække, forstå og citere specifik information, da hvert listepunkt fungerer som en diskret semantisk enhed. LLM-parsingen bliver mere ligetil, når modellen støder på nummererede eller punktlister, fordi den ikke behøver at udlede relationer mellem begreber—de er eksplicit defineret af listesystemet. Denne effektivitet omsættes direkte til højere citeringsrater, da AI-systemer mere selvsikkert kan udtrække og referere til enkelte listepunkter uden at skulle trække omfattende kontekst fra omkringliggende afsnit. Den forudsigelige karakter af listikler AI-formater betyder, at modeller bruger færre tokens på at håndtere strukturel tvetydighed og flere tokens på reel indholdskomprehension. Når du præsenterer information i en nummereret liste, taler du grundlæggende det store sprogsmodellers eget sprog.
Hvordan forskellige AI-platforme citerer lister
Forskellige AI-platforme udviser distinkte citeringspræferencer, der afslører hvordan nummererede lister LLM-systemer prioriterer indholdsopdagelse og validering. ChatGPT udviser en stærk præference for encyklopædisk indhold, hvor 47,9% af dets citater kommer fra Wikipedia—en platform, der i høj grad bygger på struktureret, listebaseret informationsarkitektur. Gemini viser mere balancerede kildevalg og citerer blogs i 39% af tilfældene og nyhedskilder i 26%, hvilket indikerer en præference for listikler AI, der blander autoritativ struktur med aktuelle indsigter. Perplexity AI, der er designet specifikt til forskningsorienterede forespørgsler, citerer blogindhold i 38% og nyheder i 23%, hvilket viser en tydelig præference for ekspertlister, der kombinerer dybde med tilgængelighed. Google AI Overviews foretrækker blogartikler i 46% af tilfældene, især dem, der bruger overskuelige, listebaserede formater, der matcher platformens fokus på hurtig informationshentning. Disse AI-citeringsmønstre afslører, at platforme konsekvent belønner indholdsskabere, der strukturerer information som listeformat AI-præsentationer fremfor tætte narrative afsnit. Ved at forstå disse platformsspecifikke præferencer kan indholdsstrateger skræddersy listikel-formater for at maksimere synligheden på tværs af flere AI-systemer samtidigt.
AI-platform
Primær citeringskilde
Procentdel
Indholdspræference
ChatGPT
Wikipedia
47,9%
Encyklopædisk, strukturerede lister
Gemini
Blogs
39%
Balancerede listikler med indsigt
Perplexity
Blogs
38%
Ekspertlister med dybde
Google AI Overviews
Blogartikler
46%
Overskuelige, listebaserede formater
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Den tekniske baggrund for, hvorfor lister klarer sig så godt i AI-systemer, ligger i semantisk chunking og vektorindlejringer—de matematiske repræsentationer, der gør det muligt for sprogmodeller at forstå betydning. Når indhold organiseres som en liste, skaber hvert punkt klare semantiske grænser, som gør det lettere for modellens indlejringslag at skelne mellem diskrete begreber og idéer. Nummererede sekvenser signalerer hierarki og vigtighed til AI-systemer på en måde, som narrativ tekst ikke kan, hvilket gør det muligt for modellerne at forstå, at punkt #1 fundamentalt adskiller sig fra punkt #5 i rang eller rækkefølge. Schema markup—især HowTo og FAQ-strukturerede data—forstærker findbarhed ved at give eksplicit metadata, som AI-crawlere og indekseringssystemer straks kan genkende og prioritere. Listeformat AI-optimering udvides til friskhedssignaler, hvor jævnligt opdaterede listikler sender stærkere signaler om aktualitet til søgealgoritmer end statisk narrativt indhold. Vektordatabaser, der bruges af moderne LLM’er, kan mere effektivt lagre og hente listebaseret indhold, fordi den semantiske afstand mellem listepunkter er mere ensartet og forudsigelig end mellem afsnit i flydende prosa. Denne tekniske fordel forstærkes over tid, da AI-systemer lærer at vægte listebaserede kilder tungere i både træningsdata og genfindingsprocesser.
Listikler vs. narrativt indhold – citationssammenligning
Forskning viser konsekvent, at listikler AI-formater får 20-30% flere citater fra AI-systemer sammenlignet med tilsvarende information præsenteret i narrativ form. Denne citeringsfordel skyldes den grundlæggende forskel i, hvordan AI-systemer skal behandle og udtrække information fra hvert format: Narrativt indhold kræver, at modellen udfører kompleks udtrækning af kontekst og inferens for at identificere citerbare udsagn, mens lister præsenterer information som forudpakkede, selvstændige enheder. Nummererede lister LLM-systemer kan citere specifikke listepunkter uden at kræve omfattende omgivende kontekst, hvilket gør citeringsprocessen hurtigere og mere sikker for AI-modellen. Genanvendelsesfaktoren kan ikke overvurderes—når et AI-system støder på en veldesignet listikel, kan det udtrække enkelte punkter og citere dem uafhængigt, mens narrativt indhold ofte kræver citation af hele afsnit eller sektioner for at bevare konteksten. Data fra flere AI-overvågningsplatforme viser, at listikler konsekvent overgår narrativt indhold i citeringsfrekvens, position i AI-svar og sandsynlighed for at blive valgt som primær kilde. Denne præstationsforskel øges yderligere ved sammenligning af listikler med lang narrativ prosa, da den kognitive belastning for AI-systemer ved at analysere og citere fra tæt prosa stiger eksponentielt. For indholdsskabere med fokus på listikler AI-synlighed er beviset klart: Struktur slår narrativ hver gang.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Bedste praksis for AI-optimerede listikler
At skabe listikler, der maksimerer AI-citation, kræver opmærksomhed på specifikke strukturelle og formateringsmæssige elementer:
Brug klar H2/H3-hierarki for at etablere semantiske relationer og hjælpe AI-systemer med at forstå indholdsorganisationen
Start med et direkte svar ved at bruge BLUF-princippet (Bottom Line Up Front)—præsenter din hovedpointe først
Indsæt sammenligningstabeller i HTML-format (aldrig billeder) for at give strukturerede data, som AI-systemer kan analysere og citere
Tilføj schema markup ved brug af FAQ- og HowTo-strukturerede data for eksplicit at signalere indholdstype og struktur til AI-crawlere
Hold punkterne afbalancerede i dybde—undgå at ét punkt har 500 ord og andre kun 50, da inkonsistens forvirrer AI-parsing
Brug nummererede lister til sekventielle eller rangerede emner hvor rækkefølgen har betydning (Top 10, trin-for-trin guider, rangerede sammenligninger)
Brug punktlister til funktionslister og ikke-sekventiel information, hvor rækkefølgen er irrelevant
Opdater kvartalsvis for friskhed—AI-systemer belønner nyligt opdateret listeformat AI-indhold med højere citeringsprioritet
Virkelige eksempler på AI-citerede listikler
Praktiske eksempler demonstrerer styrken af veldesignede listikler til at drive AI-citater på tværs af flere platforme. “Top 5 AML Compliance-værktøjer”-listikler optræder konsekvent i Perplexity AI-svar, hvor de enkelte værktøjer citeres som autoritative anbefalinger i compliance-relaterede forespørgsler. “Bedste CRM-alternativer”-lister dominerer ChatGPT-svar, især når brugere beder om software-sammenligninger, hvor listikel-strukturen gør det muligt for AI at citere specifikke alternativer med sikkerhed. Produkt-sammenligningslistikler er blevet det dominerende format i Google AI Overviews, hvor den overskuelige struktur passer perfekt til platformens fokus på hurtig, brugbar information. Forskning fra MADX og Omnius tracking-data viser, at websites, der publicerer veldesignede listikler, oplever stigninger i citationer på 40-60% inden for 90 dage efter udgivelse. Tatareks analyse af nummererede lister LLM-performance viste, at listikler med fokus på “bedst i test”-kategorier får 3,2x flere citater end narrative anmeldelser af de samme produkter. Disse eksempler fra virkeligheden understreger, at listikler AI ikke kun er teoretisk overlegne—de leverer målbare, kvantificerbare forbedringer i AI-synlighed og citeringsfrekvens.
Sådan strukturerer du lister for maksimal AI-synlighed
Maksimering af AI-synlighed kræver en bevidst strukturel tilgang, der rækker ud over blot at nummerere punkter. Begynd med et TL;DR-afsnit øverst, der opsummerer hele listen i 2-3 sætninger, så AI-systemer straks forstår formålet og omfanget af dit indhold. Inkluder et kriterieafsnit, der eksplicit fortæller, hvorfor du har valgt netop disse punkter—denne gennemsigtighed hjælper AI-systemer med at forstå din metode og øger citerings-tilliden. Giv afbalanceret dækning af hvert listepunkt, og sørg for, at alle poster får proportional dybde og analyse fremfor at favorisere enkelte punkter med overdreven detaljegrad. Det er afgørende at inkludere både styrker og begrænsninger for hvert punkt, da AI-systemer genkender og belønner balanceret, nuanceret analyse fremfor ensidigt salgspræget indhold. Tilføj et prissammenligningsafsnit hvis relevant, da denne strukturerede data ofte citeres og refereres i AI-svar om produkt-sammenligninger. Implementer en sammenligningstabel i HTML-format (ikke screenshots eller billeder), så AI-systemer kan analysere og citere specifikke funktionssammenligninger direkte. Inkluder en FAQ-sektion, der besvarer almindelige spørgsmål om dine listepunkter, så AI-systemerne får ekstra struktureret data til indeksering og citation. Giv til sidst klare næste skridt og CTA’er, der guider brugeren til handling, hvilket signalerer til AI-systemer, at dit indhold er komplet og handlingsorienteret.
Nummererede lister vs. punktlister i AI-citation
Valget mellem nummererede lister og punktlister har stor betydning for, hvordan AI-systemer behandler og citerer dit indhold. Nummererede lister signalerer rækkefølge og rangering, hvilket er grunden til, at de dominerer “Top X”-listikler og trin-for-trin-guider—AI-systemer opfatter nummereringen som et eksplicit hierarki, der udtrykker vigtighed eller rækkefølge. Punktlister fungerer bedre til ikke-sekventiel information, såsom funktionslister eller sammenligninger af egenskaber, hvor der ikke er nogen indbygget rangering. Forskning viser, at AI-systemer betragter nummererede lister som mere autoritative og citerbare, især i svar på forespørgsler, der eksplicit beder om rangeret eller sekventiel information. Når brugere spørger ChatGPT eller Gemini “Hvad er de 5 bedste værktøjer til X?”, citerer AI-systemet fortrinsvis fra nummererede lister LLM-kilder, fordi nummereringen giver eksplicit rangering. Omvendt udmærker punktlister sig i funktionssammenligninger, hvor AI-systemer skal udtrække og citere specifikke egenskaber uden at antyde hierarki. At blande nummererede lister og punktlister i samme listikel skaber forvirring for AI-systemer, så fasthold konsekvent formatering i hele dit indhold for at maksimere listeformat AI-optimering.
Måling af listiklers performance i AI-søgning
At spore performance kræver systematisk overvågning på tværs af flere AI-platforme og værktøjer. AtomicAGI, Writesonic og Perplexity tracking-værktøjer giver automatisk overvågning af, hvor ofte dit listikler AI-indhold fremgår i AI-genererede svar. Manuel test på tværs af ChatGPT, Gemini og Perplexity er stadig nødvendig, da automatiserede værktøjer nogle gange overser nuancerede citeringsmønstre eller platformspecifikke adfærd. Fastlæg basismålinger ved at spore citeringsfrekvens og placering—overvåg ikke kun, om din listikel bliver citeret, men hvor den vises i AI-svaret, og hvor ofte den vælges som primær kilde. Overvåg hvilke punkter der citeres mest, da det afslører, hvilke specifikke anbefalinger eller indsigter der vækker størst genklang hos AI-systemer og brugere. Mål trafik fra AI-kilder separat fra traditionel søgetrafik, da AI-drevne besøg ofte viser andre konverteringsmønstre og brugerintention end organiske besøgende. Sammenlign resultater før og efter optimering, og implementer én strukturel ændring ad gangen for at isolere, hvilke forbedringer der driver øget citation. Etabler en månedlig overvågningsrutine for at identificere trends og sæsonudsving i, hvordan dit nummererede lister LLM-indhold klarer sig på tværs af forskellige AI-platforme og forespørgselstyper.
Almindelige listikel-fejl, der skader AI-synlighed
Selv velforberedte listikler kan undlade at opnå optimal AI-citation, hvis de indeholder strukturelle eller indholdsmæssige fejl, der forvirrer AI-parsingsystemer. Skæve lister, der favoriserer dit eget produkt eller din service over konkurrenter, signalerer lav troværdighed til AI-systemer, som i stigende grad straffer åbenlyst salgspræget indhold til fordel for balancerede anbefalinger. Uens dybde på punkterne—hvor nogle punkter får 200 ords analyse, mens andre kun får 50—skaber forvirring og antyder ufuldstændig research i AI-systemernes optik. Manglende sammenligningstabeller er en væsentlig forpasset mulighed, da AI-systemer prioriterer strukturerede data og citerer fra tabeller langt lettere end fra prosa. Ingen schema markup betyder, at du tvinger AI-systemer til selv at udlede din indholdsstruktur fremfor at erklære den eksplicit, hvilket mindsker citeringssikkerhed og findbarhed. Forældet information er særligt skadeligt for listikler, da AI-systemer genkender og straffer forældet indhold, især i hurtigt skiftende kategorier som softwareværktøjer eller compliance-krav. Dårlig struktur og hierarki med uklare H2/H3-relationer gør det svært for AI-systemer at analysere semantiske relationer mellem punkter. Endelig udvander keyword stuffing og alt for lange lister (50+ punkter) autoritet og fokus, så AI-systemer opfatter dem som mindre troværdige end fokuserede, kuraterede alternativer.
Ofte stillede spørgsmål
Hvorfor foretrækker AI-modeller listikler frem for narrativt indhold?
AI-modeller er mønstergenkendende maskiner, der behandler strukturerede, overskuelige formater mere effektivt end tæt narrativ prosa. Listikler reducerer den beregningsmæssige kompleksitet ved at præsentere information som diskrete semantiske enheder, hvilket gør det muligt for LLM'er at analysere, udtrække og citere specifikke punkter med større sikkerhed og hastighed.
Hvad er forskellen på nummererede lister og punktlister for AI-citation?
Nummererede lister signalerer rækkefølge og rangering, hvilket gør dem ideelle til 'Top X'-listikler og trin-for-trin-guides. Punktlister fungerer bedre til ikke-sekventiel information som funktionssammenligninger. AI-systemer betragter nummererede lister som mere autoritative ved rangerede forespørgsler, mens punktlister er bedst i funktionsbaserede sammenhænge.
Hvor ofte skal jeg opdatere mine listikler for AI-synlighed?
Opdater dine listikler mindst kvartalsvis for at opretholde stærke friskhedssignaler. AI-systemer belønner nyligt opdateret indhold med højere citeringsprioritet. Selv små opdateringer—tilføjelse af nye datapunkter, opdatering af statistikker eller udvidelse af afsnit—hjælper med at opretholde citeringsberettigelse og synlighed.
Forbedrer schema markup virkelig AI-citater?
Ja, schema markup forbedrer AI-findbarhed markant. FAQ- og HowTo-strukturerede data kan øge sandsynligheden for citation med op til 10%. Schema markup giver eksplicit metadata, som AI-crawlere straks genkender og prioriterer, hvilket gør dit indhold lettere at indeksere og citere.
Kan jeg bruge listikler til alle typer indhold?
Listikler fungerer særligt godt til sammenligninger, rangeringer, vejledninger og anbefalinger. De er dog mindre egnede til narrativ historiefortælling, dybdegående analyser eller konceptuelle forklaringer. Vælg listeformat, når dit indhold naturligt kan opdeles i diskrete, sammenlignelige punkter.
Hvordan måler jeg, om mine listikler bliver citeret af AI?
Brug værktøjer som AtomicAGI, Writesonic eller Perplexity-tracking til automatisk overvågning. Test relevante forespørgsler manuelt på tværs af ChatGPT, Gemini og Perplexity for at følge citeringsfrekvens og placering. Overvåg hvilke specifikke listepunkter, der citeres mest, og mål trafik fra AI-kilder særskilt fra organisk søgning.
Hvad er den ideelle længde for en listikel for at få AI-citater?
Kvalitet er vigtigere end kvantitet. Fokuser på 5-10 velresearchede punkter fremfor 50+. Hvert punkt bør have afbalanceret, proportional dybde (150-300 ord). For lange lister udvander autoritet og forvirrer AI-parsing, mens fokuserede, kuraterede listikler præsterer markant bedre.
Skal jeg inkludere mit eget produkt i sammenligningslistikler?
Ja, men oprethold gennemsigtighed og balance. Inkluder dit produkt sammen med konkurrenter, giv ærlige styrker og begrænsninger, og sørg for lige dybde i dækningen. Skæve lister, der favoriserer dit eget produkt, signalerer lav troværdighed til AI-systemer, som i stigende grad straffer åbenlyst salgspræget indhold.
Overvåg dit brands AI-synlighed
Følg med i hvor ofte dit indhold bliver citeret af ChatGPT, Gemini og Perplexity med AmICiteds AI-overvågningsplatform. Få indsigt i realtid om din tilstedeværelse i AI-søgninger.
Foretrækker AI-søgemaskiner listicles? Komplet guide til AI-optimeret indhold
Find ud af, om AI-søgemaskiner som ChatGPT og Perplexity foretrækker listicles. Lær, hvordan du optimerer listebaseret indhold for AI-citater og synlighed.
Lær hvordan komparative indholdsstrukturer optimerer information til AI-systemer. Opdag hvorfor AI-platforme foretrækker sammenligningstabeller, matricer og sid...
Lær, hvordan strukturerede data og schema markup hjælper AI-systemer med at forstå, citere og referere dit indhold nøjagtigt. Komplet guide til JSON-LD-implemen...
9 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.