
Optimering af stemmesøgning for AI-assistenter
Bliv ekspert i optimering af stemmesøgning for AI-assistenter med strategier for samtalenøgleord, udvalgte uddrag, lokal SEO og schema markup for at øge synligh...
8 min læsning
Lær, hvordan du optimerer spørgsmaalsbaseret indhold til konversationsbaserede AI-systemer som ChatGPT og Perplexity. Opdag struktur-, autoritets- og overvågningsstrategier for at maksimere AI-citater.
Brugeradfærden ved søgning har fundamentalt ændret sig de seneste fem år fra fragmenterede søgeordssætninger til naturlige, konversationsbaserede forespørgsler. Dette skifte blev accelereret af udbredt brug af stemmesøgning, mobilførste browseradfærd og markante algoritmeforbedringer som Googles BERT og MUM, der nu prioriterer semantisk forståelse frem for præcis søgeords-match. Brugere søger ikke længere med isolerede termer; de stiller komplette spørgsmål, der afspejler, hvordan de naturligt taler og tænker. Forskellen er tydelig:
Adoptionen af stemmesøgning har især haft stor indflydelse, hvor 50% af alle søgninger nu foregår via stemme, hvilket tvinger søgemaskiner og AI-systemer til at tilpasse sig længere og mere naturlige sprogmønstre. Mobile enheder er blevet den primære søgeflade for de fleste brugere, og konversationsforespørgsler føles mere naturlige på mobilen end indtastning af søgeord. Googles algoritmeopdateringer har gjort det klart, at forståelse af brugerens hensigt og kontekst er langt vigtigere end søgeordstæthed eller præcis ordlyd, hvilket fundamentalt ændrer, hvordan indhold skal skrives og struktureres for at forblive synligt i både traditionelle søgninger og AI-drevne systemer.
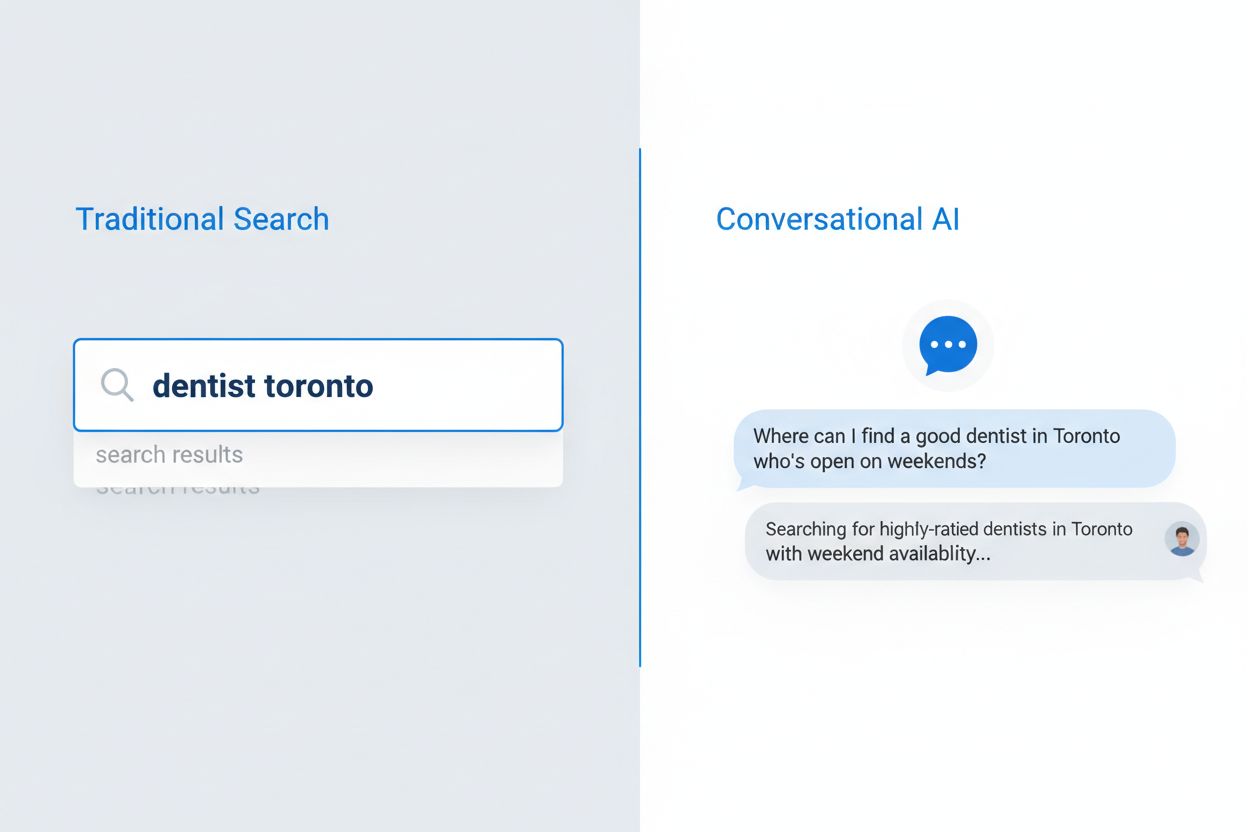
Konversationsbaseret AI-søgning repræsenterer et grundlæggende andet paradigme end traditionel søgeordsbaseret søgning med væsentlige forskelle i, hvordan forespørgsler behandles, resultater leveres, og brugerhensigten fortolkes. Hvor traditionelle søgemaskiner returnerer en liste over rangerede links, analyserer konversationsbaserede AI-systemer forespørgsler i kontekst, henter relevant information fra flere kilder og sammenfatter omfattende svar i naturligt sprog. Den tekniske arkitektur adskiller sig markant: traditionel søgning bygger på søgeords-match og linkanalyse, mens konversationsbaseret AI bruger store sprogmodeller med retrieval-augmented generation (RAG) til at forstå semantisk betydning og generere kontekstuelle svar. Forståelsen af disse forskelle er afgørende for indholdsskabere, der ønsker synlighed i begge systemer, da optimeringsstrategierne afviger på vigtige punkter.
| Dimension | Traditionel søgning | Konversationsbaseret AI |
|---|---|---|
| Input | Korte søgeord eller fraser (2-4 ord i gennemsnit) | Fuldstændige konversationsspørgsmål (8-15 ord i gennemsnit) |
| Output | Liste over rangerede links til brugerklik | Sammenfattet svar med kildehenvisninger |
| Kontekst | Begrænset til forespørgselsord og brugerens placering | Fuld samtalehistorik og brugerpræferencer |
| Brugerhensigt | Udledt fra søgeord og klikmønstre | Eksplicit forstået gennem naturligt sprog |
| Brugeroplevelse | Klik til eksternt site påkrævet | Svar leveres direkte i interfacet |
Denne forskel har store konsekvenser for indholdsstrategien. I traditionel søgning betyder en placering i top 10 synlighed; i konversationsbaseret AI er det at blive udvalgt som kilde til citation, der betyder noget. En side kan rangere højt på et søgeord, men aldrig blive citeret af et AI-system, hvis den ikke opfylder systemets kriterier for autoritet, dækkende indhold og klarhed. Konversationsbaserede AI-systemer evaluerer indhold anderledes og prioriterer direkte svar på spørgsmål, tydelig informationshierarki og dokumenteret ekspertise frem for blot søgeordsoptimering og backlink-profiler.
Store sprogmodeller bruger en avanceret proces kaldet Retrieval-Augmented Generation (RAG) til at udvælge, hvilket indhold de citerer, når de besvarer brugerens spørgsmål—og denne proces adskiller sig væsentligt fra traditionel søgningsrangering. Når en bruger stiller et spørgsmål, henter LLM’en først relevante dokumenter fra sine træningsdata eller indekserede kilder og vurderer dem ud fra flere kriterier, inden den beslutter, hvilke kilder den vil citere i sit svar. Udvælgelsesprocessen prioriterer flere nøglefaktorer, som indholdsskabere skal forstå:
Autoritetssignaler – LLM’er genkender domæneautoritet gennem backlink-profiler, domænealder og historisk performance i traditionelle søgeresultater og foretrækker etablerede, betroede kilder frem for nye eller mindre citerede domæner.
Semantisk relevans – Indholdet skal direkte besvare brugerens spørgsmål med høj semantisk lighed, ikke blot søgeords-match; LLM’er forstår betydning og kontekst på måder, søgeords-match ikke kan.
Indholdsstruktur og klarhed – Veldisponeret indhold med tydelige overskrifter, direkte svar og logisk flow udvælges hyppigere, da LLM’er nemmere kan udtrække relevant information fra struktureret indhold.
Aktualitet og friskhed – Indhold, der for nylig er opdateret, vægtes tungere, især hvor opdateret information er vigtig; forældet indhold nedprioriteres, selv hvis det tidligere var autoritativt.
Dækkende indhold – Indhold, der grundigt belyser et emne fra flere vinkler, med data og ekspertperspektiver, citeres oftere end overfladisk eller ufuldstændigt dækkende indhold.
Selve citationsprocessen er ikke tilfældig; LLM’er er trænet til at citere de kilder, der bedst underbygger deres svar, og de viser i stigende grad kilder til brugere, hvilket gør kildeudvælgelse til et vigtigt synlighedsparameter for indholdsskabere.
Indholdsstruktur er blevet en af de vigtigste faktorer for AI-synlighed, men mange indholdsskabere optimerer stadig primært til menneskelige læsere uden at overveje, hvordan AI-systemer gennemgår og udtrækker information. LLM’er bearbejder indhold hierarkisk og bruger overskriftsstrukturer, sektionsopdelinger og formatering til at forstå informationsopbygning og udtrække relevante passager til citation. Den optimale struktur for AI-læselighed følger bestemte retningslinjer: hver sektion bør være 120-180 ord, så LLM’er kan udtrække meningsfulde bidder uden overdreven længde; H2- og H3-overskrifter skal tydeligt angive emnehierarki; og direkte svar bør stå tidligt i sektionerne i stedet for at være gemt væk i teksten.
Spørgsmaalsbaserede titler og FAQ-afsnit er særligt effektive, fordi de matcher præcist, hvordan konversationsbaserede AI-systemer fortolker brugerspørgsmål. Når en bruger spørger “Hvad er best practices for content marketing?”, kan et AI-system straks matche dette spørgsmål til et afsnit med titlen “Hvad er best practices for content marketing?” og udtrække relevant indhold. Denne strukturelle tilpasning øger sandsynligheden for citation markant. Her er et eksempel på korrekt struktureret indhold:
## Hvad er best practices for content marketing?
### Definér først din målgruppe
[120-180 ord med direkte, brugbart indhold, der besvarer dette specifikke spørgsmål]
### Opret en indholdskalender
[120-180 ord med direkte, brugbart indhold, der besvarer dette specifikke spørgsmål]
### Mål og optimer performance
[120-180 ord med direkte, brugbart indhold, der besvarer dette specifikke spørgsmål]
Denne struktur gør det muligt for LLM’er hurtigt at identificere relevante sektioner, udtrække komplette tanker uden fragmentering og citere specifikke afsnit med sikkerhed. Indhold uden denne struktur—lange afsnit uden klare overskrifter, skjulte svar eller uklar hierarki—bliver markant sjældnere valgt til citation, uanset kvalitet.
Autoritet er fortsat en afgørende faktor for AI-synlighed, men de signaler, der udgør autoritet, har udviklet sig ud over traditionelle SEO-metrics. LLM’er genkender autoritet via flere kanaler, og indholdsskabere skal opbygge troværdighed på flere niveauer for at maksimere sandsynligheden for citation. Forskning indikerer, at domæner med 32.000+ henvisende domæner oplever markant højere citationsrater, og Domain Trust-score korrelerer stærkt med AI-synlighed. Autoritet opbygges dog ikke kun gennem backlinks; det er et flerstrenget begreb, der også dækker:
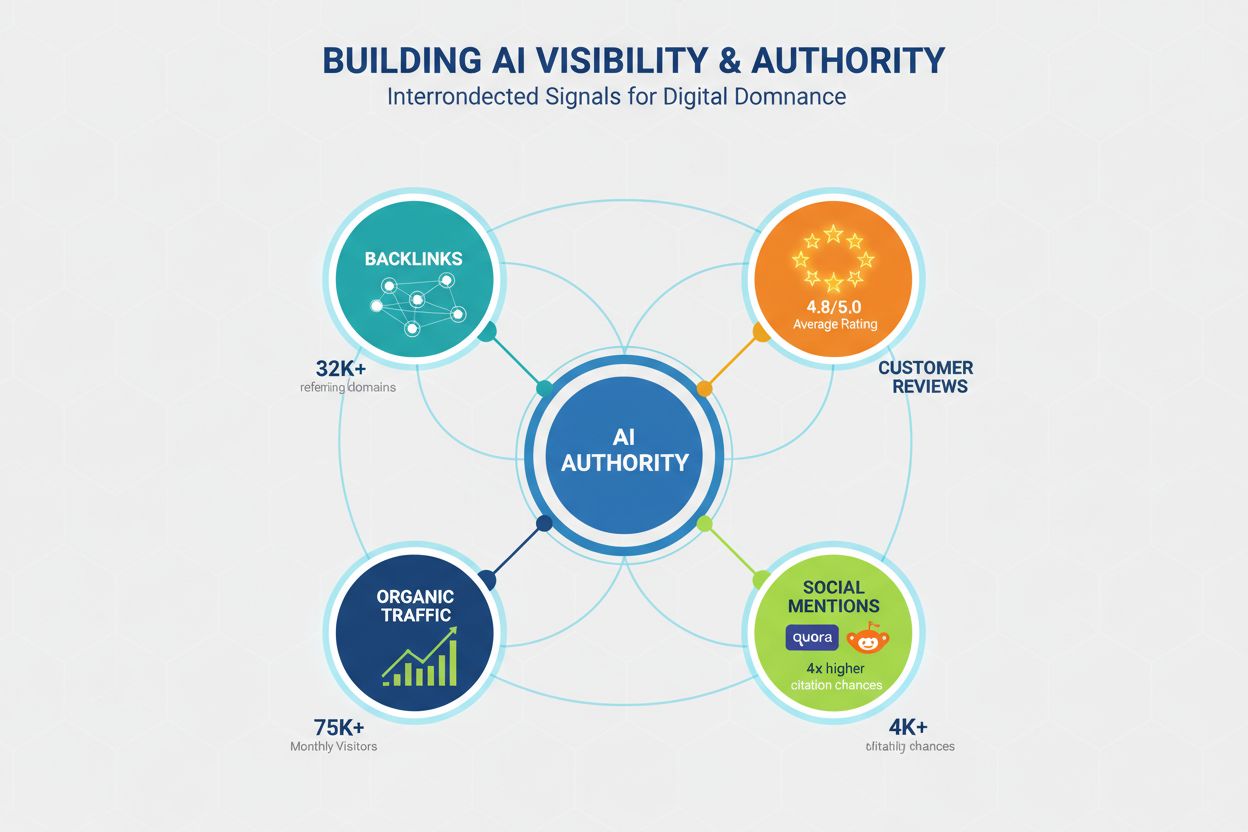
Backlink-profil – Kvalitetsbacklinks fra autoritative domæner signalerer ekspertise; 50+ højkvalitetsbacklinks medfører 4,8 gange højere citationsrate end domæner med få backlinks.
Social proof og community-tilstedeværelse – Omtaler på platforme som Quora, Reddit og branchefora signalerer, at dit indhold stoles på og henvises til af rigtige brugere; aktiv deltagelse her opbygger troværdighed.
Anmeldelsesplatforme og ratings – Tilstedeværelse på Trustpilot, G2, Capterra og lignende med positive anmeldelser opbygger tillidssignaler, som LLM’er genkender; brands med 4,5+ stjerner får 3,2 gange højere citationsrate.
Hjemmesidetrafik og brandgenkendelse – Direkte trafik til din hjemmeside indikerer brand awareness og tillid; LLM’er vægter indhold fra kendte brands tungere end ukendte kilder.
Ekspertkredentialer og bylines – Indhold skrevet af anerkendte eksperter med tydelige kredentialer og biografier vægtes tungere; forfatterekspertise er et selvstændigt autoritetssignal udover domæneautoritet.
At opbygge autoritet for AI-synlighed kræver en langsigtet strategi, der går ud over traditionel SEO og inkluderer community-engagement, anmeldelsesstyring og brandopbygning sammen med teknisk optimering.
Indholdsdybde er en af de stærkeste forudsigere for AI-citation, og forskning viser, at omfattende, grundigt researcheret indhold får væsentligt flere citationer end overfladisk dækning. Minimumsgrænsen for konkurrencedygtig synlighed er ca. 1.900 ord, men virkelig dækkende indhold, der dominerer AI-citater, når typisk op på 2.900+ ord. Det handler ikke om ordantal i sig selv, men om informationsdybde, antallet af datakilder og bredden af perspektiver.
Tallene for indholdsdybde er overbevisende:
Effekt af ekspertcitater – Indhold med 4+ ekspertcitater modtager i gennemsnit 4,1 citationer, mod 2,4 for indhold uden ekspertperspektiver; LLM’er genkender ekspertinput som troværdighedssignal.
Tæthed af statistiske data – Indhold med 19+ statistiske datapunkter modtager i gennemsnit 5,4 citationer, mod 2,8 for indhold med få data; LLM’er prioriterer datadokumenterede påstande.
Omfattende dækning – Indhold, der behandler 8+ underemner inden for et hovedemne, modtager i gennemsnit 5,1 citationer, mod 3,2 for indhold med kun 3-4 underemner; bredden af dækning har stor betydning.
Original forskning – Indhold med original forskning, undersøgelser eller proprietære data modtager i gennemsnit 6,2 citationer og er den mest effektfulde indholdstype for AI-synlighed.
Dybde betyder noget, fordi LLM’er er trænet til at levere dækkende, veldokumenterede svar og naturligt søger mod indhold, hvor de kan citere flere perspektiver, datapunkter og ekspertudtalelser på én gang.
Indholdsfriskhed er en kritisk, men ofte overset faktor for AI-synlighed, og forskning viser, at nyligt opdateret indhold får væsentligt flere citationer end forældet materiale. Effekten er tydelig: Indhold opdateret inden for de seneste tre måneder får i gennemsnit 6,0 citationer, mod kun 3,6 citationer for indhold, der ikke er opdateret i over et år. Dette afspejler LLM’ers præference for opdateret information og deres erkendelse af, at frisk indhold oftere er korrekt og relevant.
En kvartalsvis opdateringsstrategi bør være standard for indhold, der sigter mod AI-synlighed. Det betyder ikke nødvendigvis omskrivning af hele indholdet; strategiske opdateringer, der tilføjer nye statistikker, opdaterer eksempler, opdaterer cases og inkorporerer nye udviklinger, er tilstrækkelige for at signalere friskhed. For tidssensitive emner som teknologi, marketingtrends eller branchenyheder kan månedlige opdateringer være nødvendige for at bevare citationskonkurrenceevnen. Opdateringsprocessen bør inkludere:
Indhold, der forbliver statisk, mens branchen udvikler sig, mister gradvist AI-synlighed, selv hvis det tidligere var autoritativt, fordi LLM’er genkender, at forældet information er mindre værdifuld for brugeren.
Teknisk performance er blevet stadig vigtigere for AI-synlighed, da LLM’er og de systemer, der forsyner dem, prioriterer indhold fra hurtige, velfungerende websites. Core Web Vitals—Googles målepunkter for sideoplevelse—korrelerer stærkt med citationsrater og indikerer, at LLM’er medregner brugeroplevelsessignaler, når de vælger kilder. Effekten er betydelig: sider med First Contentful Paint (FCP) under 0,4 sekunder får i gennemsnit 6,7 citationer, mod kun 2,1 citationer for sider med FCP over 2,5 sekunder.
Teknisk optimering for AI-synlighed bør fokusere på:
Largest Contentful Paint (LCP) – Mål under 2,5 sekunder; sider, der opfylder dette, får i gennemsnit 5,8 citationer mod 2,9 for langsommere sider.
Cumulative Layout Shift (CLS) – Hold score under 0,1; ustabilt layout signalerer dårlig kvalitet over for LLM’er og mindsker citationssandsynligheden.
Interaction to Next Paint (INP) – Optimer for responstid under 200ms; interaktive sider får i gennemsnit 5,2 citationer mod 3,1 for sløve sider.
Mobilresponsivitet – Mobilførste indeksering betyder, at mobilperformance er kritisk; sider med dårlig mobiloplevelse får 40% færre citationer.
Ren, semantisk HTML – Korrekt overskriftshierarki, semantiske tags og ren kodning hjælper LLM’er med at gennemgå indholdet mere effektivt og øger citationssandsynligheden.
Teknisk performance handler ikke kun om brugeroplevelse; det er et direkte signal til AI-systemer om indholdskvalitet og troværdighed.
Spørgsmaalsbaseret optimering er den mest direkte måde at tilpasse indhold til konversationsbaserede AI-søgemønstre, og effekten er især markant for mindre domæner uden stor autoritet. Forskning viser, at spørgsmaalsbaserede titler har syv gange større effekt for mindre domæner (under 50.000 månedlige besøgende) end traditionelle søgeordstitler, hvilket gør denne strategi særligt værdifuld for nye brands. FAQ-afsnit er lige så effektive og fordobler sandsynligheden for citation, når de implementeres med klare spørgsmål-svar-par.
Forskellen mellem spørgsmaalsbaserede og traditionelle titler er tydelig:
Dårlig titel: “Top 10 marketingværktøjer”
God titel: “Hvilke er de 10 bedste marketingværktøjer for små virksomheder?”
Dårlig titel: “Content marketing-strategi”
God titel: “Hvordan bør små virksomheder udvikle en content marketing-strategi?”
Dårlig titel: “Best practices for e-mail marketing”
God titel: “Hvad er de bedste e-mail marketing-praksisser for e-handelsvirksomheder?”
Praktiske optimeringstiltag omfatter:
Titeloptimering – Indarbejd det primære spørgsmål, dit indhold besvarer; brug naturligt sprog i stedet for søgeordsmættede fraser.
FAQ-afsnit – Opret dedikerede FAQ-afsnit med 5-10 spørgsmål og direkte svar; dette fordobler citationssandsynligheden for konkurrenceprægede forespørgsler.
Underoverskriftsjustering – Brug H2- og H3-overskrifter, der matcher almindelige spørgsmålsmønstre; dette hjælper LLM’er med at matche brugerforespørgsler til dit indhold.
Placering af direkte svar – Placer direkte svar i starten af sektioner, ikke gemt i afsnit; LLM’er udtrækker svar mere effektivt, når de står fremme.
Spørgsmaalsbaseret optimering handler ikke om at snyde systemet, men om at tilpasse din indholdsstruktur til den måde, brugere faktisk stiller spørgsmål, og AI-systemer fortolker dem.
Mange indholdsskabere spilder tid og ressourcer på optimeringstiltag, der har ringe eller ingen effekt på AI-synlighed—eller endnu værre, ligefrem skader citationssandsynligheden. At kende disse misforståelser kan hjælpe dig med at fokusere indsatsen på strategier, der faktisk virker. En sejlivet myte er, at LLMs.txt-filer har stor betydning for synligheden; forskning viser, at disse filer har forsvindende lille effekt på citationsrater, og domæner med LLMs.txt ser kun marginalt anderledes citationsmønstre (3,8 vs 4,1 citationer i gennemsnit) end dem uden.
Almindelige misforståelser at undgå:
FAQ schema markup i sig selv hjælper ikke – FAQ-schema er nyttigt for traditionel søgning, men har minimal betydning for AI-synlighed; den reelle indholdsstruktur er langt vigtigere end markup. Indhold med FAQ-schema, men dårlig struktur, modtager i gennemsnit 3,6 citationer, mens velformateret indhold uden schema modtager 4,2 citationer.
Overoptimering reducerer citationer – Kraftigt optimerede URL’er, titler og meta-beskrivelser reducerer faktisk citationssandsynligheden; stærkt optimeret indhold modtager i gennemsnit 2,8 citationer, mens naturligt skrevet indhold får 5,9 citationer. LLM’er genkender og straffer åbenlyse optimeringsforsøg.
Søgeordsstuvning hjælper ikke LLM’er – I modsætning til traditionelle søgemaskiner forstår LLM’er semantisk betydning og opfatter søgeordsstuvning som et kvalitetssignal; indhold med naturligt sprog får betydeligt flere citationer.
Backlinks alene garanterer ikke synlighed – Autoritet betyder noget, men indholdskvalitet og struktur betyder mere; et højautoritet-domæne med dårligt struktureret indhold får færre citationer end et lavere autoritetsdomæne med fremragende struktur.
Længde uden substans virker ikke – At fylde indhold for at nå mål for ordantal uden at tilføje værdi reducerer faktisk citationssandsynligheden; LLM’er genkender og straffer fyld.
Fokuser på ægte kvalitet, klar struktur og autentisk ekspertise i stedet for optimerings-tricks.
At overvåge, hvordan konversationsbaserede AI-systemer citerer dit indhold, er afgørende for at forstå din AI-synlighed og identificere optimeringsmuligheder, men de fleste indholdsskabere har ikke indsigt i denne kritiske måling. AmICited.com tilbyder en dedikeret platform til sporing af, hvordan ChatGPT, Perplexity, Google AI Overviews og andre konversationsbaserede AI-systemer henviser til dit brand og indhold. Denne overvågningsfunktion udfylder et væsentligt hul i indholdsskaberens værktøjskasse og supplerer traditionelle SEO-overvågningsværktøjer ved at give indsigt i et helt andet søgeparadigme.
AmICited sporer flere nøgletal, som traditionelle SEO-værktøjer ikke kan måle:
Citationsfrekvens – Hvor ofte dit indhold citeres på tværs af forskellige AI-systemer; dette afslører, hvilket indhold AI-algoritmer foretrækker, og hvilke emner der skal forbedres.
Citationsmønstre – Hvilke specifikke sider og indholdsstykker citeres hyppigst; dette hjælper med at identificere dit stærkeste indhold og afsløre huller i din dækning.
Konkurrenters AI-synlighed – Se hvordan dine AI-citationsrater sammenlignes med konkurrenternes; denne benchmarking hjælper dig med at forstå din position i AI-søgelandskabet.
Trendsporing – Overvåg hvordan din AI-synlighed ændrer sig over tid, efterhånden som du implementerer optimeringer; dette gør det muligt at måle effekten af ændringer i din indholdsstrategi.
Kilde-diversitet – Spor citationer på tværs af forskellige AI-platforme; synlighed i ChatGPT kan adskille sig fra Perplexity eller Google AI Overviews, og forståelse for disse forskelle hjælper dig med at optimere til specifikke systemer.
Integration af AmICited i din indholdsovervågningsstrategi giver de nødvendige data for at optimere specifikt til AI-synlighed i stedet for at gætte på, om dine indsatser virker.
Implementering af en spørgsmaalsbaseret indholdsstrategi til konversationsbaseret AI kræver en systematisk tilgang, der bygger på eksisterende indhold og indfører nye optimeringspraksisser fremadrettet. Implementeringsprocessen bør være metodisk og databaseret, begyndende med et audit af dit nuværende indhold og derefter strukturel optimering, autoritetsopbygning og kontinuerlig overvågning. Denne otte-trins ramme giver en praktisk køreplan for at transformere din indholdsstrategi og maksimere AI-synlighed.
Auditér eksisterende indhold – Analyser dine 50 bedste sider for at forstå nuværende struktur, ordantal, overskriftshierarki og opdateringsfrekvens; identificér hvilke sider, der allerede er veldisponerede, og hvilke der kræver optimering.
Identificér værdifulde spørgsmåls-søgeord – Research konversationsforespørgsler relateret til din branche med værktøjer som Answer the Public, Quora og Reddit; prioriter spørgsmål med høj søgevolumen og kommerciel intention.
Omstrukturer med Q&A-afsnit – Omorganisér eksisterende indhold for at inkludere spørgsmaalsbaserede overskrifter og direkte svar; konverter traditionelle søgeordstitler til spørgsmaalsbaserede titler, der matcher brugerforespørgsler.
Implementér overskriftshierarki – Sørg for, at alt indhold følger korrekt H2/H3-hierarki med tydelig emneopdeling; opdel lange sektioner i bidder på 120-180 ord adskilt af beskrivende underoverskrifter.
Tilføj FAQ-afsnit – Opret dedikerede FAQ-afsnit på dine 20 vigtigste sider med 5-10 spørgsmål og direkte svar; prioriter spørgsmål, der fremgår af søgedata og brugertilbagemeldinger.
Opbyg autoritet via backlinks – Udvikl en backlink-strategi med fokus på højkvalitetsdomæner i din branche; fokuser på at opnå links fra autoritative kilder frem for kvantitet.
Overvåg med AmICited – Opsæt overvågning for dit brand og nøgleindhold; fastlæg baseline-målinger og følg ændringer, når du implementerer optimeringer.
Kvartalsvise opdateringer – Indfør en plan for kvartalsvise indholdsopdateringer med nye statistikker, opdaterede eksempler og vedligeholdelse af friskhed; prioriter indhold med mest trafik og flest citationer.
Denne implementeringsstrategi transformerer dit indhold fra traditionel SEO-optimering til en omfattende tilgang, der maksimerer synlighed i både traditionelle søgninger og konversationsbaserede AI-systemer.
Spørgsmaalsbaseret indhold er materiale, der er struktureret omkring naturlige sprogspørgsmål, som brugere stiller konversationsbaserede AI-systemer. I stedet for at målrette søgeord som 'tandlæge København', målrettes der fulde spørgsmål som 'Hvor kan jeg finde en god tandlæge i København, der har åbent i weekenden?' Denne tilgang tilpasser indholdet til, hvordan folk naturligt taler, og hvordan AI-systemer fortolker forespørgsler.
Traditionel søgning returnerer en liste over rangerede links baseret på søgeords-match, mens konversationsbaseret AI sammenfatter direkte svar fra flere kilder. Konversationsbaseret AI forstår kontekst, bevarer samtalehistorik og giver et samlet svar med kildehenvisninger. Denne grundlæggende forskel kræver andre strategier for optimering af indholdet.
LLM'er gennemgår indhold hierarkisk ved at bruge overskriftsstrukturer og sektionsopdelinger for at forstå informationsorganisationen. Optimal struktur med sektioner på 120-180 ord, tydelig H2/H3-hierarki og direkte svar i starten af sektioner gør det lettere for AI-systemer at udtrække og citere dit indhold. Dårlig struktur reducerer sandsynligheden for citation uanset indholdets kvalitet.
Forskning viser, at ca. 1.900 ord er minimumsgrænsen for konkurrencedygtig AI-synlighed, hvor virkelig omfattende dækning når op på 2.900+ ord. Dog betyder dybde mere end længde—indhold med ekspertcitater, statistiske data og flere perspektiver får markant flere citationer end fyldindhold.
Indhold opdateret inden for de seneste tre måneder modtager i gennemsnit 6,0 citationer, sammenlignet med 3,6 for forældet indhold. Implementer en kvartalsvis opdateringsstrategi, der tilføjer nye statistikker, opdaterer eksempler og inkorporerer nylige udviklinger. Dette signalerer aktualitet til AI-systemer og opretholder konkurrenceevne for citationer.
Ja. Selvom store domæner har autoritetsfordele, kan mindre websites konkurrere gennem overlegen indholdsstruktur, spørgsmaalsbaseret optimering og fællesskabsengagement. Spørgsmaalsbaserede titler har syv gange større indflydelse for mindre domæner, og aktiv tilstedeværelse på Quora og Reddit kan give fire gange højere citationssandsynlighed.
AmICited overvåger, hvordan ChatGPT, Perplexity og Google AI Overviews citerer dit brand og indhold. Det giver synlighed i citationmønstre, identificerer indholdshuller, sporer konkurrenters AI-synlighed og måler effekten af dine optimeringsindsatser—målinger som traditionelle SEO-værktøjer ikke kan levere.
Nej. Selvom schema markup er nyttigt for traditionel søgning, giver det minimal fordel for AI-synlighed. Indhold med FAQ-schema modtager i gennemsnit 3,6 citationer, mens velformateret indhold uden schema modtager 4,2 citationer. Fokuser på faktisk indholdsstruktur og kvalitet frem for kun markup.
Se hvordan ChatGPT, Perplexity og Google AI Overviews henviser til dit brand med AmICited's AI-citationssporing.
Bliv ekspert i optimering af stemmesøgning for AI-assistenter med strategier for samtalenøgleord, udvalgte uddrag, lokal SEO og schema markup for at øge synligh...

Opdag de vigtigste tendenser, der former AI-søgningens udvikling i 2026, herunder multimodale funktioner, agentiske systemer, realtidsinformationshentning og ov...

Opdag ubesvarede prompter i AI-søgning og gør dem til indholdsmuligheder. Lær at identificere huller, hvor konkurrenter nævnes, men du ikke gør.