Kørsel af GEO-eksperimenter: Kontrolgrupper og variable
Bliv ekspert i GEO-eksperimenter med vores omfattende guide om kontrolgrupper og variable. Lær at designe, udføre og analysere geografiske eksperimenter for præcis markedsføringsmåling og AI-synlighedssporing.
Udgivet den Jan 3, 2026.Sidst ændret den Jan 3, 2026 kl. 3:24 am
Hvad er GEO-eksperimenter, og hvorfor er de vigtige
GEO-eksperimenter, også kendt som geo lift-tests eller geografiske eksperimenter, repræsenterer et grundlæggende skifte i, hvordan marketingfolk måler den sande effekt af deres kampagner. Disse eksperimenter opdeler geografiske regioner i test- og kontrolgrupper, hvilket gør det muligt at isolere den inkrementelle effekt af marketingindsatsen uden at skulle spore på individniveau. I en tid, hvor privatlivsregler som GDPR og CCPA strammer til, og tredjepartscookies udfases, tilbyder GEO-eksperimenter et privatlivssikkert, statistisk robust alternativ til traditionelle målemetoder. Ved at sammenligne resultater mellem regioner eksponeret for markedsføring og dem, der ikke er, kan organisationer sikkert besvare spørgsmålet: “Hvad ville være sket uden vores kampagne?” Denne metode er blevet afgørende for brands, der ønsker at forstå reel inkrementalitet og optimere deres marketingbudget med præcision.
Forståelse af kontrolgrupper i GEO-eksperimenter
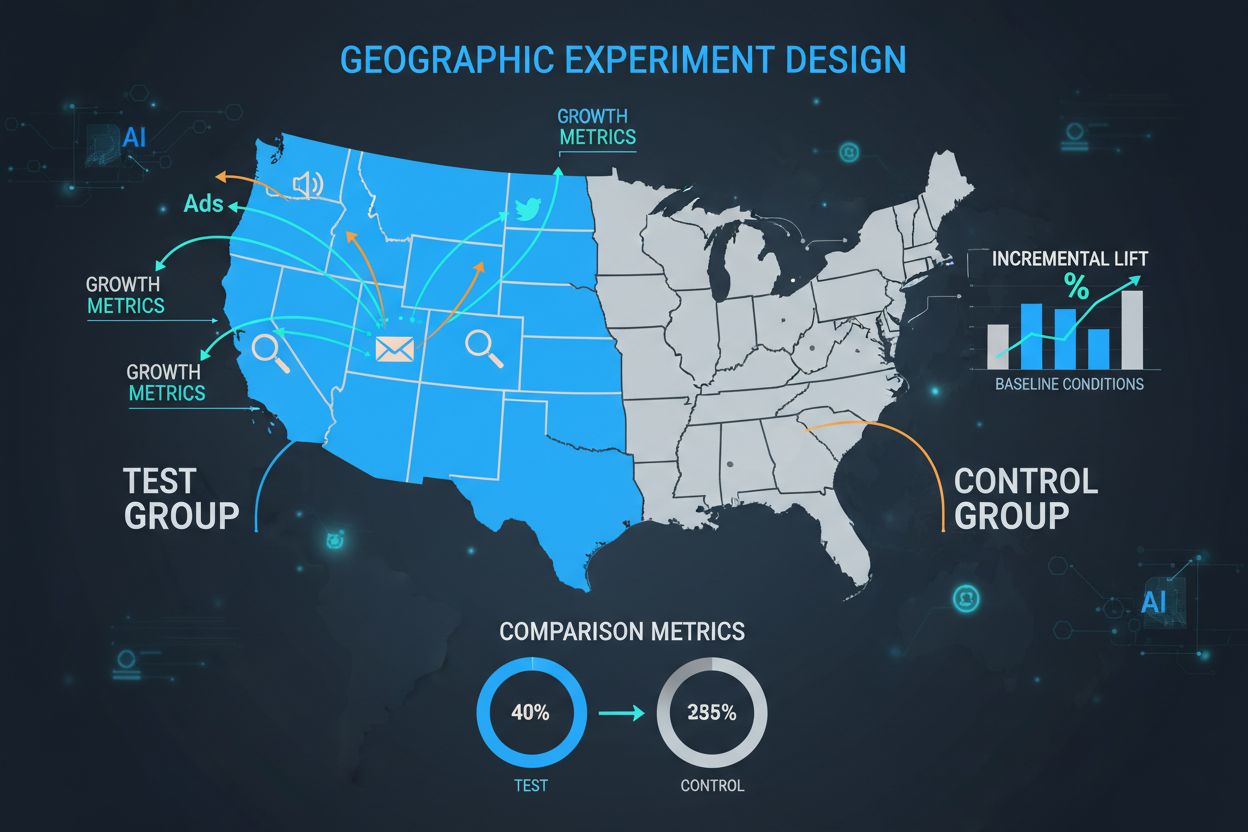
Kontrolgruppen er hjørnestenen i ethvert GEO-eksperiment og fungerer som det kritiske udgangspunkt, som alle behandlingseffekter måles imod. En kontrolgruppe består af geografiske regioner, der ikke modtager marketingindsatsen, så man kan observere, hvad der naturligt ville ske uden kampagnen. Kontrolgruppens styrke er dens evne til at tage højde for eksterne faktorer—sæsonudsving, konkurrentaktiviteter, økonomiske forhold og markedstendenser—som ellers ville forstyrre resultaterne. Når de er korrekt designet, gør kontrolgrupper det muligt at isolere den sande kausale effekt af marketingfremstød i stedet for blot at observere korrelation. Udvælgelsen af kontrolregioner kræver omhyggelig matching på flere dimensioner, herunder demografi, historiske præstationsmålinger, markedsstørrelse og forbrugsmønstre. Dårligt udvalgte kontrolgrupper medfører høj varians i resultater, brede konfidensintervaller og i sidste ende upålidelige konklusioner, der kan føre til dyre fejldisponeringer af marketingbudgettet.
Aspekt
Kontrolgruppe
Testgruppe
Marketingindsats
Ingen (Business as Usual)
Aktiv kampagne
Formål
Etablér baseline
Mål effekt
Geografisk udvælgelse
Matchet til test
Primært fokus
Datainnsamling
Samme målinger
Samme målinger
Stikprøvestørrelse
Sammenlignelig
Sammenlignelig
Confounders
Minimeret
Minimeret
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Succesfulde GEO-eksperimenter kræver omhyggelig håndtering af flere typer variable, der påvirker resultater og fortolkningsmuligheder. At forstå forskellen mellem uafhængige, afhængige, kontrol- og confounding-variable er afgørende for at designe eksperimenter, der giver handlingsrettede indsigter.
Uafhængige variable: Dette er de marketingtaktikker, du aktivt manipulerer og tester—f.eks. annoncens budget, kreative variationer, kanalvalg, målretningsparametre eller kampagnetilbud. Den uafhængige variabel er det, du ønsker at måle effekten af.
Afhængige variable: Dette er de resultater, du måler for at vurdere effekten af din marketingindsats—herunder omsætning, konverteringer, kundeanskaffelse, brand awareness, webtrafik og, vigtigt for moderne marketingfolk, AI-citationssynlighed og brandnævnelser i AI-systemer.
Kontrolvariable: Disse faktorer holdes konstante på tværs af test- og kontrolgrupper for at sikre retfærdig sammenligning, såsom ensartet budskab, tilbudsstruktur, kampagnens varighed og mediemix.
Confounding-variable: Uventede eksterne faktorer, der kan påvirke resultater uafhængigt af marketingindsatsen, f.eks. konkurrentkampagner, naturkatastrofer, store nyheder, sæsonudsving og økonomiske ændringer.
Målingsvariable: Specifikke KPI’er og målinger, du sporer, herunder inkrementelt løft, inkrementel ROAS (iROAS), inkrementel CAC (iCAC) og konfidensintervaller omkring dine estimater.
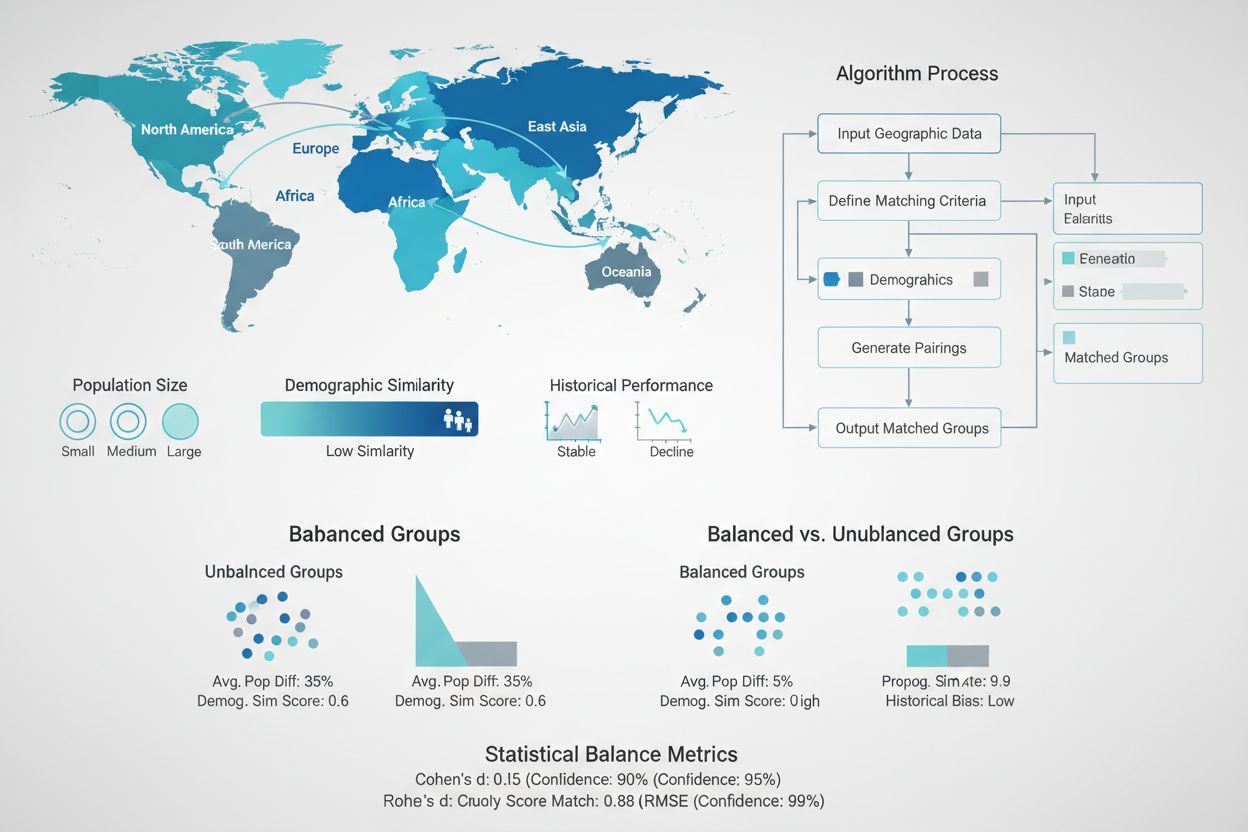
Design af balancerede test- og kontrolgrupper
At skabe statistisk ækvivalente test- og kontrolgrupper er en af de vigtigste og mest udfordrende aspekter af GEO-eksperimenter. I modsætning til randomiserede kontrollerede forsøg med millioner af individuelle brugere arbejder GEO-eksperimenter typisk kun med dusinvis til hundredevis af geografiske enheder, hvilket gør tilfældig tildeling ofte utilstrækkelig for at opnå balance. Avancerede matching-algoritmer og optimeringsteknikker er opstået for at løse denne udfordring. Syntetiske kontrolmetoder, udviklet af økonometri og udbredt af virksomheder som Wayfair og Haus, bruger historiske data til at identificere og vægte kontrolregioner, der bedst matcher testregionernes karakteristika. Disse algoritmer tager flere dimensioner i betragtning samtidigt—befolkningsstørrelse, demografi, historisk salgsdata, medieforbrug og konkurrencesituation—for at skabe kontrolgrupper, der fungerer som nøjagtige kontrafaktiske scenarier. Målet er at minimere forskellen mellem test- og kontrolgrupper på alle præ-behandlings-metrics, så eventuelle forskelle efter behandlingen med sikkerhed kan tilskrives marketingindsatsen frem for eksisterende forskelle.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Statistiske fundamenter og konfidensintervaller
Den statistiske stringens i GEO-eksperimenter adskiller dem fra tilfældige observationer eller anekdotisk evidens. Konfidensintervaller repræsenterer det interval, hvor den sande behandlingseffekt sandsynligvis ligger, udtrykt med en bestemt sikkerhed (typisk 95 %). Et smalt konfidensinterval indikerer høj præcision og sikkerhed, mens et bredt interval antyder betydelig usikkerhed. For eksempel, hvis et GEO-eksperiment viser et løft på 10 % med et 95 % konfidensinterval på ±2 %, kan du være ret sikker på, at den sande effekt ligger mellem 8 % og 12 %. Omvendt giver et løft på 10 % med ±8 % konfidensinterval (2 % til 18 %) langt mindre handlingsorienteret information. Bredden af konfidensintervaller afhænger af flere faktorer: stikprøvestørrelse (antal regioner), varians i resultater, testens varighed og størrelsen af den forventede effekt. Minimum detectable effect (MDE)-beregninger hjælper med at afgøre på forhånd, om dit foreslåede eksperiment kan påvise det løft, du håber at måle. Power-analyser sikrer, at du har tilstrækkelig statistisk styrke—typisk 80 % eller højere—for at opdage reelle effekter, mens du kontrollerer for Type I-fejl (falske positive) og Type II-fejl (falske negative).
Almindelige faldgruber og hvordan man undgår dem
Selv veltilrettelagte GEO-eksperimenter kan give vildledende resultater, hvis almindelige faldgruber ikke undgås. At forstå disse faldgruber og implementere sikkerhedsforanstaltninger er afgørende for pålidelig måling.
Ubalancerede grupper: Når test- og kontrolregioner adskiller sig markant på vigtige præ-behandlings-metrics, gør den øgede varians det vanskeligt at opdage reelle effekter. Løsning: Brug matching-algoritmer og syntetiske kontrolmetoder for at sikre, at grupperne er statistisk ens på alle vigtige dimensioner.
Spillover-effekter: Brugere og medieeksponering respekterer ikke geografiske grænser. Folk rejser mellem regioner, og digital annoncering kan nå publikum uden for de tiltænkte områder. Løsning: Brug geografiske grænser, der minimerer krydskontaminering, overvej pendlerstrømme og anvend geofencing-teknologi for præcis kontrol.
Utilstrækkelig testvarighed: Kampagner kræver tid for at skabe resultater, og kunderejser varierer i længde. Korte testperioder overser forsinkede konverteringseffekter og sæsonmønstre. Løsning: Kør eksperimenter i mindst 4-6 uger, længere for produkter med lange overvejelsesperioder, og tag højde for post-behandlingsvinduer.
Ændringer i analyseplanen efterfølgende: At ændre analyseplanen efter at have set foreløbige resultater medfører bias og øger antallet af falske positive. Løsning: Foruddefiner din analysemetode, KPI’er og succeskriterier før eksperimentet startes.
Ignorering af eksterne chok: Naturkatastrofer, konkurrenthandlinger, store nyheder og økonomiske skift kan ugyldiggøre resultater. Løsning: Overvåg confoundere gennem hele testperioden og vær parat til at forlænge eller gentage eksperimentet ved væsentlige forstyrrelser.
Utilstrækkelig stikprøvestørrelse: For få regioner begrænser den statistiske styrke og giver brede konfidensintervaller. Løsning: Udfør power-analyse på forhånd for at bestemme det nødvendige antal regioner til din forventede effektstørrelse.
Måling af inkrementalitet og løft
Inkrementalitet repræsenterer den sande kausale effekt af markedsføring—forskellen mellem, hvad der faktisk skete, og hvad der ville være sket uden indsatsen. Løft er det kvantitative mål for denne inkrementalitet, beregnet som forskellen i nøglemålinger mellem test- og kontrolgrupper. Hvis testregioner genererede 1.000.000 kr. i omsætning, mens matchede kontrolregioner genererede 900.000 kr., er det absolutte løft 100.000 kr. Den procentvise løft ville være 11,1 % (100.000 kr. / 900.000 kr.). Rå løfttal tager dog ikke højde for omkostningen ved marketingindsatsen. Inkrementel ROAS (iROAS) dividerer den inkrementelle omsætning med den inkrementelle udgift og viser afkastet for hver ekstra investeret krone. Hvis testregionen brugte ekstra 50.000 kr. på markedsføring for at generere de 100.000 kr. ekstra omsætning, ville iROAS være 2,0x. Tilsvarende måler inkrementel CAC (iCAC) omkostningen ved at erhverve hver ekstra kunde—vigtigt for at vurdere kanalernes effektivitet. Disse målinger bliver især værdifulde, når de forbindes til brandsynlighedsmåling—ikke kun at forstå salgs-løft, men også hvordan markedsføring påvirker AI-citater og brandnævnelser på tværs af GPT’er, Perplexity og Google AI Overviews.
GEO-eksperimenter for AI-synlighed og brandovervågning
I takt med at AI-systemer bliver primære opdagelseskanaler for forbrugere, er det blevet kritisk at måle, hvordan markedsføring påvirker brandsynlighed i AI-svar. GEO-eksperimenter giver en solid ramme for at teste forskellige indholdsstrategier og deres effekt på AI-citationsfrekvens og nøjagtighed. Ved at køre eksperimenter, hvor visse regioner modtager forbedret indholdsoptimering for AI-synlighed—forbedrede strukturerede data, tydeligere brandbudskab, optimerede indholdsformater—mens kontrolregioner bevarer baseline-praksis, kan marketingfolk kvantificere den inkrementelle effekt på AI-nævnelser. Dette er især værdifuldt for at forstå, hvilke indholdsformater, budskaber og informationsstrukturer AI-systemer foretrækker, når de citerer kilder. AmICited overvåger disse eksperimenter ved at spore, hvor ofte dit brand optræder i AI-genererede svar på tværs af forskellige geografiske regioner og perioder, hvilket giver datagrundlaget for at måle synlighedsløft. Inkrementaliteten af synlighedsforbedringer kan derefter forbindes til forretningsresultater: Har regioner med højere AI-citationsfrekvens øget webtrafik, brandsøgninger eller konverteringer? Denne sammenhæng forvandler AI-synlighed fra en forfængelighedsmetrik til en målbar driver for forretningsresultater og muliggør sikker budgetallokering til synlighedsfokuserede initiativer.
Avancerede metoder: Syntetisk kontrol og Bayesian approaches
Ud over simpel difference-in-differences-analyse er der opstået sofistikerede statistiske metoder for at forbedre nøjagtighed og pålidelighed i GEO-eksperimenter. Den syntetiske kontrolmetode konstruerer en vægtet kombination af kontrolregioner, der matcher præ-behandlingsforløbet for testregioner bedst muligt og skaber et mere præcist kontrafaktisk scenario end nogen enkelt kontrolregion kunne levere. Denne tilgang er især kraftfuld, hvis du har mange potentielle kontrolregioner og vil udnytte al tilgængelig information. Bayesian structural time series (BSTS) modeller, udbredt via Googles CausalImpact-pakke, udvider syntetisk kontrol ved at inkludere usikkerhedskvantificering og probabilistisk prognose. BSTS-modeller lærer det historiske forhold mellem test- og kontrolregioner i præ-behandlingsperioden og fremskriver derefter, hvordan testregionen ville have set ud uden intervention. Forskellen mellem faktiske og prognosticerede værdier repræsenterer behandlingseffekten, med troværdighedsintervaller for usikkerheden. Difference-in-differences (DiD)-analyse sammenligner ændringen i resultater før og efter behandling mellem test- og kontrolgrupper og fjerner dermed tidsinvariante forskelle. Hver metode har fordele og ulemper: Syntetisk kontrol kræver mange kontrolenheder, men antager ikke parallelle trends; BSTS fanger komplekse tidsdynamikker, men kræver omhyggelig modelspecifikation; DiD er enkel og intuitiv, men følsom over for brud på antagelsen om parallelle trends. Moderne platforme som Lifesight og Haus automatiserer disse metoder, så marketingfolk kan drage fordel af avanceret analyse uden behov for statistisk ekspertise.
Virkelige casestudier og resultater
Førende organisationer har demonstreret styrken i GEO-eksperimenter gennem imponerende resultater. Wayfair udviklede en integer-optimeringsmetode til at tildele hundreder af geografiske enheder til test- og kontrolgrupper, mens de præcist balancerede på flere KPI’er samtidigt, hvilket gjorde dem i stand til at køre mere sensitive eksperimenter med mindre holdout-procenter. Polar Analytics’ analyse af hundredvis af geo-tests viste, at syntetiske kontrolmetoder giver cirka 4x mere præcise resultater end simple matched market-metoder, med snævrere konfidensintervaller og mere sikre beslutninger til følge. Haus introducerede fixed geo tests, specifikt designet til out-of-home og retail-kampagner, hvor marketingfolk ikke kan randomisere regioner, men skal måle effekten af forudbestemte geografiske udrulninger. Deres case med Jones Road Beauty viste, hvordan fixed geo tests præcist målte det inkrementelle løft af billboardkampagner i bestemte markeder. Lifesights arbejde med store brands på tværs af retail, CPG og DTC viser, at automatiserede geo-testplatforme kan forkorte testvarighed fra 8-12 uger til 4-6 uger, samtidig med at nøjagtigheden forbedres via avancerede matching-algoritmer. Disse casestudier viser konsekvent, at korrekt designede og udførte GEO-eksperimenter afslører overraskende indsigter: Kanaler, man troede var meget effektive, viser ofte kun beskeden inkrementalitet, mens underinvesterede kanaler ofte viser stærkt inkrementelt afkast, hvilket fører til betydelige budgetomfordelingsmuligheder.
Implementering af GEO-eksperimenter: Trin-for-trin-proces
At køre et succesfuldt GEO-eksperiment kræver systematisk eksekvering på tværs af flere faser:
Definér klare mål og KPI’er: Identificer, hvad du vil måle (omsætning, konverteringer, brand awareness, AI-citater) og sæt specifikke, målbare mål. Sikr alignment med forretningsmål og realistiske forventninger til effektstørrelse.
Vælg og match geografiske regioner: Vælg regioner, der repræsenterer dit målmarked og har tilstrækkeligt datavolumen. Brug matching-algoritmer for at finde kontrolregioner, der ligner testregioner på historiske metrics.
Sikr dataklarhed: Verificér, at du præcist kan spore KPI’er i alle regioner gennem hele testperioden. Udfør dataaudits for kvalitet, fuldstændighed og konsistens.
Design eksperimentparametre: Fastlæg testens varighed (typisk minimum 4-6 uger), specificér marketingindsatsen præcist og dokumentér alle antagelser og succeskriterier før opstart.
Eksekver kampagnen samtidigt: Start kampagnen i testregioner og oprethold baseline i kontrolregioner samtidigt. Koordiner på tværs af teams for at sikre ensartet eksekvering.
Overvåg løbende: Følg nøgletal dagligt for at identificere uventede mønstre, eksterne chok eller implementeringsproblemer, der kan kompromittere resultaterne.
Indsaml og analyser data: Saml data fra alle regioner og anvend din foruddefinerede analysemetodik. Beregn løft, konfidensintervaller og sekundære målinger.
Fortolk resultater med omhu: Vurder ikke kun statistisk, men også praktisk signifikans. Overvej konfidensintervallets bredde, effektstørrelse og forretningsmæssig betydning, når du drager konklusioner.
Dokumentér og del indsigter: Udarbejd en omfattende rapport, der dokumenterer metode, resultater og læringer. Del indsigter med interessenter for at informere fremtidig strategi.
Planlæg næste eksperimenter: Brug læringerne til at informere næste runde af tests og opbyg en kontinuerlig kultur for eksperimentering og optimering.
Værktøjer og platforme til GEO-eksperimenter
GEO-eksperimentlandskabet har udviklet sig markant med specialiserede platforme, der nu automatiserer meget af kompleksiteten. Haus tilbyder GeoLift til standard randomiserede geo-tests og Fixed Geo Tests til forudbestemte geografiske udrulninger, med særlig styrke i omnichannel-måling. Lifesight tilbyder fuldautomatisering fra design til analyse med proprietære matching-algoritmer og syntetisk kontrolmetode, der forkorter testvarighed og forbedrer præcision. Polar Analytics fokuserer på inkrementalitetstest med vægt på kausalt løft og præcise konfidensintervaller. Paramark har speciale i marketing mix modeling suppleret med validering via geo-eksperimenter, så brands kan kalibrere MMM-forudsigelser mod reelle testresultater. Når du evaluerer platforme, bør du se efter: automatiseret regionsmatching og balance, støtte til både digitale og offline-kanaler, realtidsovervågning og mulighed for tidlig afslutning, transparent metode og rapportering af konfidensintervaller samt integration med din eksisterende datainfrastruktur. AmICited supplerer disse platforme ved at levere lag til synlighedsmåling—sporing af, hvordan dit brand optræder i AI-genererede svar på tværs af test- og kontrolregioner, hvilket gør dig i stand til at måle inkrementaliteten af synlighedsfokuserede marketinginitiativer.
Best practices og anbefalinger
Succesfuld GEO-eksperimentering kræver overholdelse af gennemprøvede best practices, der maksimerer pålideligheden og handlingspotentialet:
Start med klare hypoteser: Definér specifikke, testbare hypoteser før eksperimentet startes. Undgå at fiske efter resultater ved at teste flere variable uden klare forudsigelser.
Investér i korrekt gruppematching: Brug tid på forhånd for at sikre, at test- og kontrolgrupper virkelig er sammenlignelige. Dårlig matching underminerer al efterfølgende analyse og spilder ressourcer.
Kør tests længe nok: Modstå fristelsen til at stoppe tidligt, hvis resultaterne ser lovende ud. For tidlig stopning giver bias og flere falske positive. Forpligt dig til hele den planlagte periode.
Overvåg confounders: Overvåg aktivt eksterne begivenheder, konkurrenthandlinger og markedssituationer gennem hele testen. Vær parat til at forlænge eller gentage eksperimentet ved væsentlige forstyrrelser.
Dokumentér alt: Opbevar detaljerede optegnelser over eksperimentdesign, eksekvering, analyse og resultater. Denne dokumentation muliggør læring, gentagelse og opbygning af institutionel viden.
Opbyg en testkultur: Gå fra enkeltstående eksperimenter til systematiske testprogrammer. Hvert eksperiment bør informere det næste og skabe en positiv spiral af læring og optimering.
Forbind til forretningsresultater: Sørg for, at eksperimenter måler metrikker, der direkte påvirker forretningsmål. Undgå forfængelighedsmetrikker, der ikke omsættes til omsætning eller strategiske mål.
Ofte stillede spørgsmål
Hvad er forskellen på GEO-eksperimenter og A/B-test?
GEO-eksperimenter testes på geografisk/regionalt niveau for at måle inkrementaliteten af kampagner, der ikke kan testes på individniveau, mens A/B-tests randomiserer individuelle brugere for digital optimering. GEO-eksperimenter er bedre til offline-medier, øvre-funnel kampagner og til at måle den sande kausale effekt, mens A/B-tests er bedst til at optimere digitale oplevelser med hurtigere resultater.
Hvor længe skal et GEO-eksperiment køre?
Typisk mindst 4-6 uger, men det afhænger af din konverteringscyklus og sæsonudsving. Længere tests giver mere pålidelige resultater, men også højere omkostninger. Testperioden skal være lang nok til at fange hele kunderejsen og tage højde for forsinkede konverteringseffekter.
Hvad er den mindste markedsstørrelse for et GEO-eksperiment?
Der er ikke et fast minimum, men du skal have tilstrækkeligt datavolumen for at opnå statistisk signifikans. Generelt behøver du nok regioner og transaktioner til at kunne opdage din forventede effekts størrelse med tilstrækkelig statistisk styrke (typisk 80 % eller højere). Mindre markeder kræver længere testperioder.
Hvordan forhindrer man overlap mellem test- og kontrolregioner?
Brug geografiske grænser, der minimerer krydskontaminering, overvej pendlerstrømme og medieoverlap, brug geofencing-teknologi for præcis kontrol, og vælg regioner, der er geografisk isolerede. Overlap opstår, når brugere eller medieeksponering krydser mellem test- og kontrolregioner og udvander resultaterne.
Hvilket konfidensniveau bør jeg sigte efter i GEO-eksperimenter?
Standarden er 95 % konfidens (p < 0,05), hvilket betyder, at du kan være 95 % sikker på, at den observerede effekt er reel og ikke skyldes tilfældigheder. Overvej dog din forretningskontekst—omkostningen ved falske positive kontra falske negative—når du fastsætter dit konfidensniveau.
Kan GEO-eksperimenter måle brand awareness og AI-synlighed?
Ja, via undersøgelser, brand lift-studier og AI-citattracking. Du kan måle, hvordan markedsføring påvirker brand awareness, favorabilitet og vigtigst, hvor ofte dit brand optræder i AI-genererede svar på tværs af forskellige regioner, hvilket muliggør måling af inkremental synlighed.
Hvordan påvirker eksterne hændelser GEO-eksperimenter?
Naturkatastrofer, konkurrentkampagner, store nyhedsbegivenheder og økonomiske skift kan ugyldiggøre resultater ved at introducere confoundere. Overvåg disse gennem hele testen og vær parat til at forlænge testperioden eller gentage eksperimentet, hvis der opstår væsentlige forstyrrelser.
Hvad er ROI ved at køre GEO-eksperimenter?
GEO-eksperimenter betaler sig typisk selv ved at forhindre spild på ineffektive kanaler og muliggøre sikker budgetomfordeling til effektive taktikker. De giver ground truth, der forbedrer al nedstrømsmåling og beslutningstagning, fra MMM-kalibrering til kanaloptimering.
Overvåg din brands AI-synlighed med AmICited
GEO-eksperimenter afslører, hvordan din markedsføring påvirker synlighed. AmICited sporer, hvordan AI-systemer citerer dit brand på tværs af GPT'er, Perplexity og Google AI Overviews, så du kan måle den reelle inkrementelle forbedring af synlighed.
Hvordan tester du egentlig, om din GEO-strategi virker? Søger målingsrammer
Fællesskabsdiskussion om test af GEO-strategiens effektivitet. Rammer og metoder til at måle, om dine Generative Engine Optimization-indsatser faktisk virker.
Sådan måler du tidlig GEO-succes: Nøglemålinger og KPI'er for AI-synlighed i søgning
Lær at måle GEO-succes med AI-citation tracking, brandnævn og synlighedsmålinger på tværs af ChatGPT, Perplexity, Google AI Overviews og Claude. Spor tidlige ge...
GEO Budgetallokeringsguide: Hvor meget skal du bruge på geografisk målretning
Lær hvor meget budget du skal afsætte til kampagner med geografisk målretning (GEO). Opdag branchebenchmarks, beregningsmetoder og optimeringsstrategier for mak...
10 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.