Sådan optimerer du dit indhold til AI-træningsdata og AI-søgemaskiner
Lær hvordan du optimerer dit indhold til inklusion i AI-træningsdata. Opdag best practices for at gøre dit website synligt for ChatGPT, Gemini, Perplexity og an...
9 min læsning

Sammenlign optimering af træningsdata og realtids-hentningsstrategier for AI. Lær hvornår du skal bruge finjustering vs. RAG, omkostningsimplikationer og hybride tilgange for optimal AI-ydeevne.
Optimering af træningsdata og realtids-hentning repræsenterer fundamentalt forskellige tilgange til at udstyre AI-modeller med viden. Optimering af træningsdata indebærer at indlejre viden direkte i modellens parametre gennem finjustering på domænespecifikke datasæt, hvilket skaber statisk viden, der forbliver uændret efter endt træning. Realtids-hentning holder derimod viden ekstern for modellen og henter relevant information dynamisk under inferens, hvilket muliggør adgang til dynamisk information, der kan ændre sig mellem forespørgsler. Den grundlæggende forskel ligger i, hvornår viden integreres i modellen: Optimering af træningsdata sker før implementering, mens realtids-hentning sker ved hver inferens. Denne forskel får betydning for alle aspekter af implementeringen, fra infrastrukturkrav over nøjagtighedsegenskaber til compliance-hensyn. At forstå denne forskel er essentielt for organisationer, der skal beslutte, hvilken optimeringsstrategi der passer til deres specifikke brugsscenarier og begrænsninger.
Optimering af træningsdata fungerer ved systematisk at justere en models interne parametre gennem eksponering for kuraterede, domænespecifikke datasæt under finjusteringsprocessen. Når en model gentagne gange møder træningseksempler, internaliserer den gradvist mønstre, terminologi og domæneekspertise via backpropagation og gradientopdateringer, der omformer modellens læringsmekanismer. Denne proces gør det muligt for organisationer at indkode specialiseret viden—hvad enten det er medicinsk terminologi, juridiske rammer eller proprietær forretningslogik—direkte i modellens vægte og bias. Den resulterende model bliver højt specialiseret til sit mål-domæne og opnår ofte ydeevne på niveau med meget større modeller; forskning fra Snorkel AI har vist, at finjusterede mindre modeller kan præstere lige så godt som modeller, der er 1.400 gange større. Nøgleegenskaber ved optimering af træningsdata inkluderer:
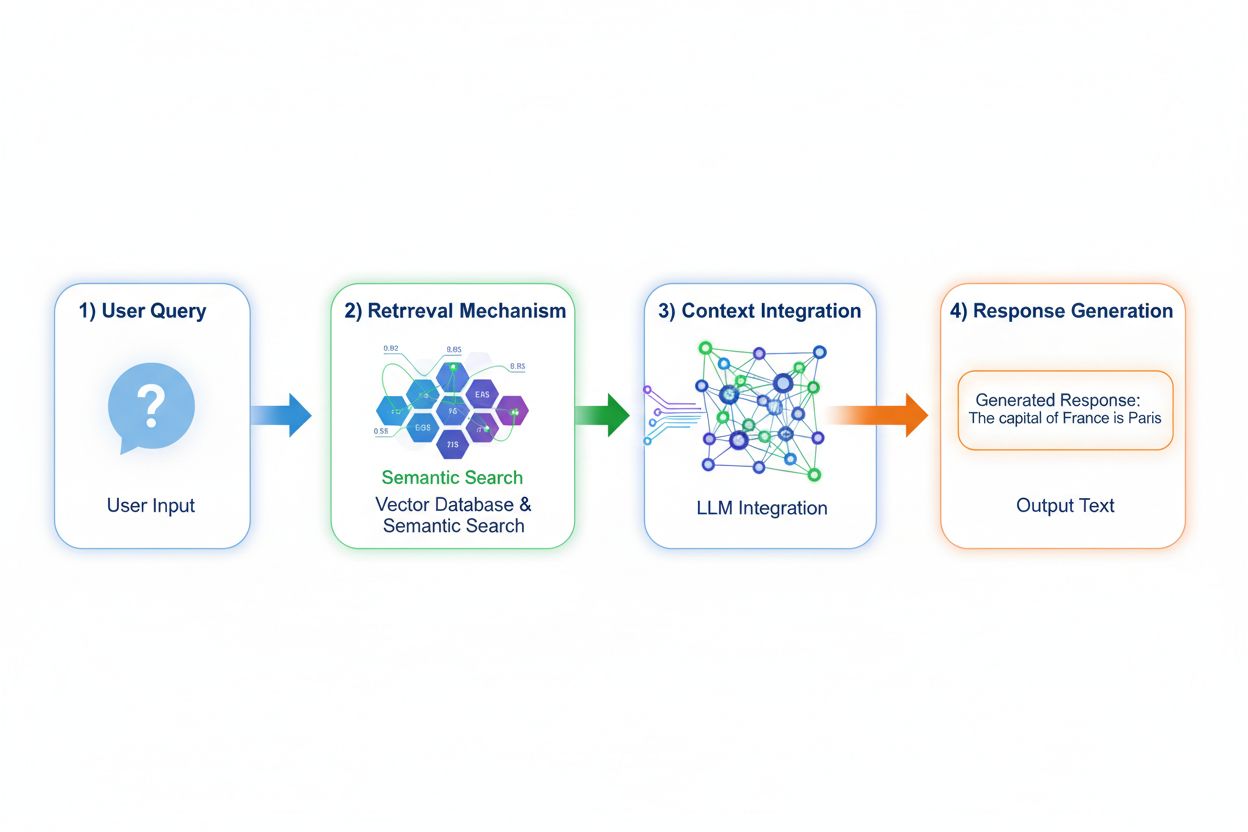
Retrieval Augmented Generation (RAG) ændrer grundlæggende, hvordan modeller får adgang til viden ved at implementere en firetrinsproces: forespørgselskodning, semantisk søgning, kontekst-rangering og generering med forankring. Når en bruger indsender en forespørgsel, konverterer RAG den først til en tæt vektorrepræsentation ved hjælp af embedding-modeller, og søger derefter i en vektordatabase, der indeholder indekserede dokumenter eller videnskilder. Hentningsstadiet bruger semantisk søgning til at finde kontekstuelt relevante passager i stedet for blot nøgleordsmatch, og rangerer resultaterne efter relevans. Til sidst genererer modellen svar, mens den bevarer eksplicitte referencer til de hentede kilder og forankrer dermed outputtet i faktisk data fremfor indlærte parametre. Denne arkitektur gør det muligt for modeller at få adgang til information, der ikke eksisterede under træning, hvilket gør RAG særligt værdifuld til applikationer, der kræver aktuel information, proprietære data eller ofte opdaterede vidensbaser. RAG-mekanismen forvandler i bund og grund modellen fra et statisk videnslager til en dynamisk informationssyntetisator, der kan inkorporere ny data uden gen-træning.
Nøjagtigheds- og hallucinationsprofilerne for disse tilgange adskiller sig markant på måder, der påvirker implementering i praksis. Optimering af træningsdata giver modeller med dyb domæneforståelse, men begrænset evne til at erkende vidensgrænser; når en finjusteret model møder spørgsmål udenfor dens træningsdistribution, kan den selvsikkert generere plausible, men forkerte svar. RAG reducerer markant hallucinationer ved at forankre svar i hentede dokumenter—modellen kan ikke påstå information, der ikke findes i kildematerialet, hvilket skaber naturlige rammer for fejlagtig opfindsomhed. Dog introducerer RAG andre nøjagtighedsrisici: hvis hentningsstadiet ikke finder relevante kilder eller rangerer irrelevante dokumenter højt, genererer modellen svar på et dårligt grundlag. Datatidssvarendehed bliver kritisk for RAG-systemer; optimering af træningsdata indfanger et statisk øjebliksbillede af viden under træningen, mens RAG løbende afspejler den aktuelle tilstand i kildedokumenterne. Kildehenvisning udgør en anden forskel: RAG muliggør iboende citat og verificering af udsagn, mens finjusterede modeller ikke kan henvise til specifikke kilder for deres viden, hvilket gør faktatjek og compliance sværere.
De økonomiske profiler for disse tilgange skaber forskellige omkostningsstrukturer, som organisationer nøje skal overveje. Optimering af træningsdata kræver betydelige beregningsomkostninger i starten: GPU-klynger, der kører i dage eller uger for at finjustere modeller, dataannoteringstjenester til at skabe mærkede træningsdatasæt og ML-ingeniørekspertise til at designe effektive træningspipelines. Når modellen først er trænet, forbliver driftsomkostningerne relativt lave, da inferens kun kræver standard modelserveringsinfrastruktur uden eksterne opslag. RAG-systemer vender denne omkostningsstruktur på hovedet: lavere indledende træningsomkostninger, da der ikke sker finjustering, men løbende infrastruktur-udgifter til vedligeholdelse af vektordatabaser, embedding-modeller, hentningstjenester og dokumentindekserings-pipelines. Centrale omkostningsfaktorer inkluderer:
Sikkerheds- og complianceimplikationerne afviger markant mellem disse tilgange og påvirker organisationer i regulerede brancher. Finjusterede modeller skaber databeskyttelsesudfordringer, fordi træningsdata bliver indlejret i modelvægtene; at udtrække eller revidere, hvilken viden modellen rummer, kræver sofistikerede teknikker, og privatlivsproblemer opstår, når følsomme træningsdata påvirker modeladfærd. Overholdelse af regler som GDPR bliver kompleks, fordi modellen i praksis “husker” træningsdata på måder, der er svære at slette eller ændre. RAG-systemer tilbyder en anden sikkerhedsprofil: Viden forbliver i eksterne, reviderbare datakilder i stedet for modelparametre, hvilket gør det nemt at håndtere sikkerhedskontrol og adgangsbegrænsninger. Organisationer kan implementere detaljerede tilladelser på hentningskilder, revidere hvilke dokumenter modellen har brugt til hvert svar og hurtigt fjerne følsomme oplysninger ved at opdatere kildedokumenterne uden at gen-træne modellen. Dog introducerer RAG sikkerhedsrisici relateret til beskyttelse af vektordatabaser, embedding-modeller og sikring af, at hentede dokumenter ikke lækker følsomme oplysninger. HIPAA-regulerede sundhedsorganisationer og GDPR-underlagte europæiske virksomheder foretrækker ofte RAG’s gennemsigtighed og reviderbarhed, mens organisationer med fokus på modelportabilitet og offline-drift vælger finjusterings selvstændige tilgang.
Valget mellem disse tilgange kræver nøje evaluering af organisatoriske begrænsninger og brugsscenarier. Organisationer bør prioritere finjustering, når viden er stabil og usandsynlig at ændre sig ofte, når inferens-latenstid er kritisk, når modeller skal fungere offline eller i isolerede miljøer, eller når ensartet stil og domænespecifik formatering er nødvendig. Realtids-hentning er at foretrække, når viden ændres regelmæssigt, når kildehenvisning og reviderbarhed er vigtige for compliance, når vidensbasen er for stor til effektivt at blive indkodet i modelparametre, eller når organisationer har behov for at opdatere information uden gen-træning. Specifikke brugsscenarier illustrerer disse forskelle:
Hybride tilgange kombinerer finjustering og RAG for at opnå fordele fra begge strategier og afbøde individuelle begrænsninger. Organisationer kan finjustere modeller på domænefundament og kommunikationsmønstre, mens de bruger RAG til at hente aktuel, detaljeret information—modellen lærer hvordan den skal tænke om et domæne, mens den henter hvilke konkrete fakta, der skal indgå. Denne kombinerede strategi er særligt effektiv til applikationer, der kræver både specialiseret ekspertise og aktuel information: en finansiel rådgiverbot finjusteret på investeringsprincipper og terminologi kan hente realtids-markedsdata og virksomhedsregnskaber via RAG. Reelle hybride implementeringer inkluderer sundhedssystemer, der finjusterer på medicinsk viden og protokoller, mens de henter patientdata gennem RAG, og juridiske forskningsplatforme, der finjusterer på juridisk ræsonnement, mens de henter opdateret retspraksis. Synergieffekterne inkluderer reducerede hallucinationer (forankring i hentede kilder), forbedret domæneforståelse (fra finjustering), hurtigere inferens på almindelige forespørgsler (cachet finjusteret viden) og fleksibilitet til at opdatere specialiseret information uden gen-træning. Organisationer implementerer i stigende grad denne optimeringsmetode, efterhånden som computerressourcer bliver mere tilgængelige, og kompleksiteten i reelle applikationer kræver både dybde og aktualitet.
Evnen til at overvåge AI-svar i realtid bliver stadig mere kritisk, efterhånden som organisationer implementerer disse optimeringsstrategier i stor skala, især for at forstå hvilken tilgang, der giver de bedste resultater til specifikke brugsscenarier. AI-overvågningssystemer sporer modeluddata, kvaliteten af hentning og brugertilfredshed, hvilket gør det muligt at måle om finjusterede modeller eller RAG-systemer bedst understøtter deres applikationer. Citationssporing afslører afgørende forskelle mellem tilgange: RAG-systemer genererer naturligt citater og kildehenvisninger, hvilket skaber et revisionsspor for, hvilke dokumenter der har påvirket hvert svar, mens finjusterede modeller ikke har nogen iboende mekanisme til svarmonitorering eller henvisning. Denne forskel har stor betydning for brandsikkerhed og konkurrenceefterretning—organisationer skal forstå, hvordan AI-systemer citerer deres konkurrenter, refererer til deres produkter eller tilskriver information til deres kilder. Værktøjer som AmICited.com udfylder dette hul ved at overvåge, hvordan AI-systemer citerer brands og virksomheder på tværs af forskellige optimeringsstrategier og giver realtids-sporing af citatmønstre og -frekvens. Ved at implementere omfattende overvågning kan organisationer måle, om deres valgte optimeringsstrategi (finjustering, RAG eller hybrid) faktisk forbedrer citationsnøjagtighed, reducerer hallucinationer om konkurrenter og sikrer korrekt kildehenvisning. Denne datadrevne tilgang til overvågning muliggør løbende forbedring af optimeringsstrategier baseret på faktiske resultater frem for teoretiske forventninger.
Branchen udvikler sig mod mere sofistikerede hybride og adaptive tilgange, der dynamisk vælger mellem optimeringsstrategier baseret på forespørgselskarakteristika og vidensbehov. Nye best practices inkluderer retrieval-forstærket finjustering, hvor modeller finjusteres på, hvordan de effektivt bruger hentet information fremfor at memorere fakta, samt adaptive systemer, der dirigerer forespørgsler til finjusterede modeller for stabil viden og RAG-systemer for dynamisk information. Tendenser peger på stigende brug af specialiserede embedding-modeller og vektordatabaser optimeret til specifikke domæner, hvilket muliggør mere præcis semantisk søgning og reduceret støj ved hentning. Organisationer udvikler mønstre for løbende modelforbedring, der kombinerer periodiske finjusteringsopdateringer med realtids RAG-udvidelse, hvilket skaber systemer, der forbedres over tid og samtidig bevarer adgang til opdateret information. Udviklingen af optimeringsstrategier afspejler en bredere erkendelse af, at ingen enkelt tilgang optimalt dækker alle brugsscenarier; fremtidige systemer vil sandsynligvis implementere intelligente selektionsmekanismer, der vælger mellem finjustering, RAG og hybride tilgange dynamisk baseret på forespørgselskontekst, vidensstabilitet, latenstidskrav og compliance. Efterhånden som disse teknologier modnes, vil den konkurrencefordel flytte sig fra valget af én tilgang til dygtig implementering af adaptive systemer, der udnytter styrkerne ved hver strategi.
Optimering af træningsdata indlejrer viden direkte i modellens parametre via finjustering, hvilket skaber statisk viden, der forbliver uændret efter træning. Realtids-hentning holder viden ekstern og henter relevant information dynamisk under inferens, hvilket muliggør adgang til dynamisk information, der kan ændre sig mellem forespørgsler. Den grundlæggende forskel er, hvornår viden integreres: Optimering af træningsdata sker før implementering, mens realtids-hentning sker ved hver inferens.
Brug finjustering når viden er stabil og usandsynlig at ændre sig ofte, når inferens-latenstid er kritisk, når modeller skal fungere offline, eller når ensartet stil og domæne-specifik formatering er essentiel. Finjustering er ideel til specialiserede opgaver som medicinsk diagnose, analyse af juridiske dokumenter eller kundeservice med stabile produktinformationer. Dog kræver finjustering betydelige indledende computerressourcer og bliver upraktisk, når information ofte ændres.
Ja, hybride tilgange kombinerer finjustering og RAG for at opnå fordelene fra begge strategier. Organisationer kan finjustere modeller på domænefundamental viden, mens de bruger RAG til at hente aktuel, detaljeret information. Denne tilgang er særligt effektiv til applikationer, der kræver både specialiseret ekspertise og aktuel information, såsom finansielle rådgiverbots eller sundhedssystemer, der har brug for både medicinsk viden og patient-specifikke data.
RAG reducerer markant hallucinationer ved at forankre svar i hentede dokumenter—modellen kan ikke påstå information, der ikke optræder i kildematerialet, hvilket skaber naturlige begrænsninger for opdigtede oplysninger. Finjusterede modeller kan derimod selvsikkert generere plausible, men forkerte informationer, når de møder spørgsmål udenfor deres træningsdistribution. RAG’s kildehenvisninger muliggør også verificering, mens finjusterede modeller ikke kan pege på specifikke kilder til deres viden.
Finjustering kræver betydelige indledende omkostninger: GPU-timer (10.000-100.000+ USD per model), dataannotering (0,50-5 USD per eksempel) og ingeniørtimer. Når modellen først er trænet, forbliver driftsomkostningerne relativt lave. RAG-systemer har lavere startomkostninger, men løbende udgifter til infrastruktur for vektordatabaser, embedding-modeller og hentningsservices. Finjusterede modeller skalerer lineært med inferensmængden, mens RAG-systemer skalerer med både inferensvolumen og størrelsen af vidensbasen.
RAG-systemer genererer naturligt citater og kildehenvisninger, hvilket skaber et revisionsspor for, hvilke dokumenter der har påvirket hvert svar. Dette er afgørende for brandsikkerhed og konkurrenceefterretning—organisationer kan følge, hvordan AI-systemer citerer deres konkurrenter og refererer til deres produkter. Værktøjer som AmICited.com overvåger, hvordan AI-systemer citerer brands på tværs af forskellige optimeringsstrategier og giver realtids-sporing af citatmønstre og -frekvens.
RAG er generelt bedre til brancher med høje compliance-krav som sundhedssektoren og finans. Viden forbliver i eksterne, reviderbare datakilder i stedet for modelparametre, hvilket muliggør ligetil sikkerhedskontrol og adgangsbegrænsninger. Organisationer kan implementere detaljerede tilladelser, revidere hvilke dokumenter modellen har fået adgang til, og hurtigt fjerne følsom information uden gen-træning. HIPAA-regulerede sundhedsorganisationer og GDPR-underlagte virksomheder foretrækker ofte RAG’s gennemsigtighed og reviderbarhed.
Implementer AI-overvågningssystemer, der sporer modeluddata, kvaliteten af hentning og brugertilfredshedsmål. For RAG-systemer skal du overvåge præcisionen af hentningen og kvaliteten af citater. For finjusterede modeller skal du følge nøjagtighed på domænespecifikke opgaver og hallucinationsrater. Brug værktøjer som AmICited.com til at overvåge, hvordan dine AI-systemer citerer information og sammenligne ydeevne på tværs af forskellige optimeringsstrategier baseret på faktiske resultater.
Følg realtids-citater på tværs af GPT'er, Perplexity og Google AI Overblik. Forstå hvilke optimeringsstrategier dine konkurrenter bruger, og hvordan de bliver nævnt i AI-svar.
Lær hvordan du optimerer dit indhold til inklusion i AI-træningsdata. Opdag best practices for at gøre dit website synligt for ChatGPT, Gemini, Perplexity og an...
Fællesskabsdiskussion om forskellen mellem AI-træningsdata og live-søgning (RAG). Praktiske strategier til at optimere indhold for både statiske træningsdata og...
Forstå forskellen mellem AI-træningsdata og live-søgning. Lær hvordan viden-afskæringer, RAG og realtids-hentning påvirker AI-synlighed og indholdsstrategi....