
Hvad er embeddinger i AI-søgning?
Lær hvordan embeddings fungerer i AI-søgemaskiner og sprogmodeller. Forstå vektorrepræsentationer, semantisk søgning og deres rolle i AI-genererede svar.
8 min læsning

Lær hvordan vektorembeddinger gør det muligt for AI-systemer at forstå semantisk betydning og matche indhold med forespørgsler. Udforsk teknologien bag semantisk søgning og AI-indholdsmatchning.

Vektorembeddinger er det numeriske fundament, der driver moderne kunstig intelligens og omdanner rå data til matematiske repræsentationer, som maskiner kan forstå og behandle. I sin essens konverterer embeddinger tekst, billeder, lyd og andre indholdstyper til talrækker—typisk fra dusinvis til tusindvis af dimensioner—der indfanger den semantiske betydning og kontekstuelle relationer i dataene. Denne numeriske repræsentation er grundlaget for, hvordan AI-systemer udfører indholdsmatchning, semantisk søgning og anbefalinger, så maskinerne kan forstå ikke bare hvilke ord eller billeder der er til stede, men hvad de faktisk betyder. Uden embeddinger ville AI-systemer have svært ved at forstå de nuancerede relationer mellem begreber, hvilket gør dem til essentiel infrastruktur for enhver moderne AI-applikation.
Transformationen fra rå data til vektorembeddinger opnås gennem sofistikerede neurale netværksmodeller, der er trænet på massive datasæt for at lære meningsfulde mønstre og relationer. Når du indtaster tekst i en embeddingmodel, passerer den gennem flere lag af neurale netværk, der gradvist udtrækker semantisk information og til sidst producerer en vektor af fast størrelse, der repræsenterer essensen af indholdet. Populære embeddingmodeller som Word2Vec, GloVE og BERT har hver deres tilgang—Word2Vec bruger lave neurale netværk optimeret til hastighed, GloVE kombinerer global matrixfaktorisering med lokale kontekstvinduer, mens BERT udnytter transformer-arkitektur til at forstå tovejskontekst.
| Model | Data Type | Dimensions | Primary Use Case | Key Advantage |
|---|---|---|---|---|
| Word2Vec | Text (words) | 100-300 | Word relationships | Fast, efficient |
| GloVE | Text (words) | 100-300 | Semantic relationships | Combines global and local context |
| BERT | Text (sentences/docs) | 768-1024 | Contextual understanding | Bidirectional context awareness |
| Sentence-BERT | Text (sentences) | 384-768 | Sentence similarity | Optimized for semantic search |
| Universal Sentence Encoder | Text (sentences) | 512 | Cross-lingual tasks | Language-agnostic |
Disse modeller producerer højdimensionelle vektorer (ofte 300 til 1.536 dimensioner), hvor hver dimension fanger forskellige aspekter af betydning, fra grammatiske egenskaber til konceptuelle relationer. Skønheden ved denne numeriske repræsentation er, at den muliggør matematiske operationer—du kan lægge vektorer sammen, trække dem fra hinanden og sammenligne dem for at opdage relationer, som ville være usynlige i rå tekst. Dette matematiske grundlag er det, der gør semantisk søgning og intelligent indholdsmatchning mulig i stor skala.
Den sande styrke ved embeddinger kommer til udtryk gennem semantisk lighed, evnen til at genkende, at forskellige ord eller sætninger grundlæggende kan betyde det samme i vektorrummet. Når embeddinger oprettes effektivt, grupperes semantisk lignende begreber naturligt sammen i det højdimensionelle rum—“konge” og “dronning” ligger tæt på hinanden, ligesom “bil” og “køretøj”, selvom de er forskellige ord. For at måle denne lighed bruger AI-systemer afstandsmål som cosinus-lighed (måler vinklen mellem vektorer) eller dotprodukt (måler størrelse og retning), der kvantificerer, hvor tæt to embeddinger er på hinanden. F.eks. vil en forespørgsel om “automobiltransport” have høj cosinus-lighed med dokumenter om “bilrejser”, hvilket gør det muligt at matche indhold baseret på betydning i stedet for eksakt nøgleordsmatch. Denne semantiske forståelse adskiller moderne AI-søgning fra simpel nøgleordsmatchning og gør det muligt for systemerne at forstå brugerens hensigt og levere reelt relevante resultater.
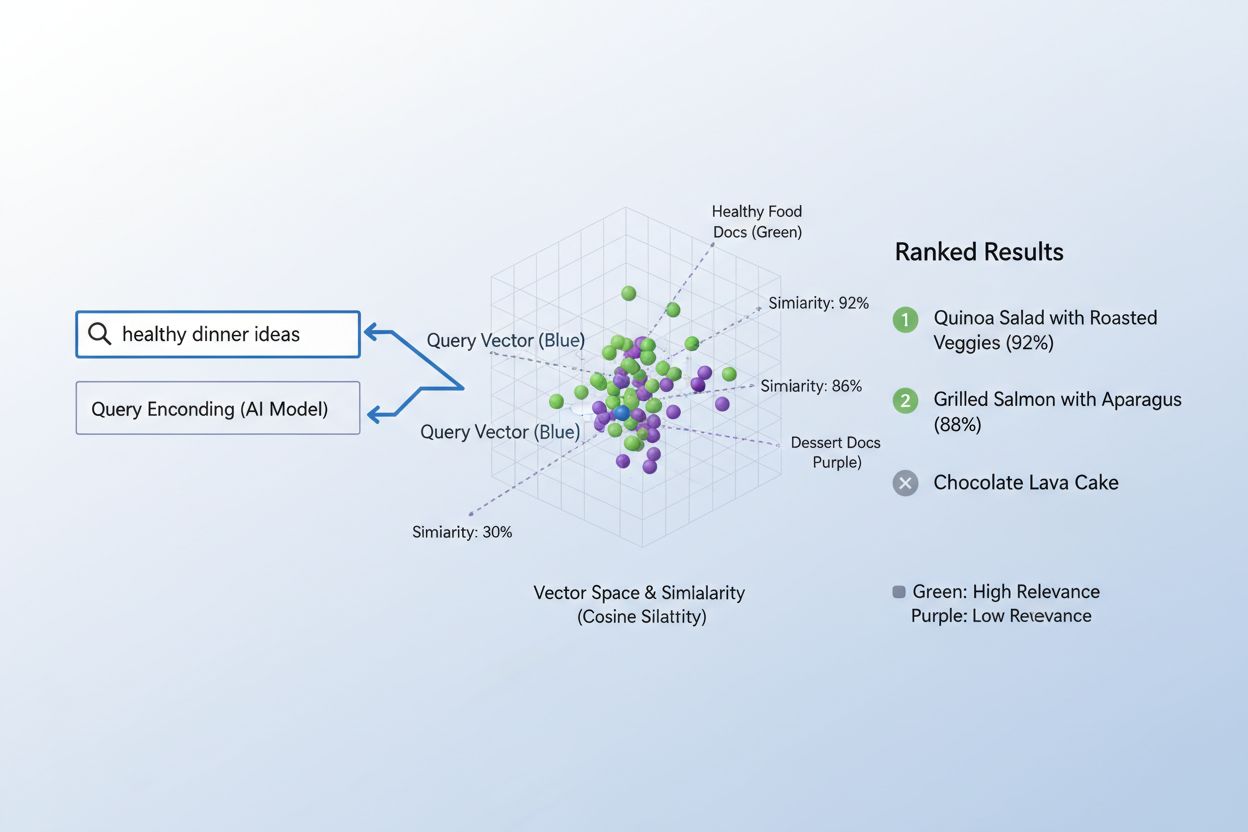
Processen med at matche indhold til forespørgsler ved hjælp af embeddinger følger et elegant totrinsworkflow, der driver alt fra søgemaskiner til anbefalingssystemer. Først konverteres både brugerens forespørgsel og det tilgængelige indhold uafhængigt til embeddinger ved hjælp af den samme model—en forespørgsel som “best practices for machine learning” bliver til en vektor, ligesom hver artikel, dokument eller produkt i systemets database. Dernæst beregner systemet ligheden mellem forespørgsels-embedding og alle indholds-embeddinger, typisk ved hjælp af cosinus-lighed, som giver en score for, hvor relevant hver indholdsenhed er i forhold til forespørgslen. Disse lighedsscorer rangeres derefter, og det indhold med den højeste score vises for brugeren som de mest relevante resultater. I en virkelig søgemaskinesituation, når du søger efter “hvordan træner man neurale netværk”, koder systemet din forespørgsel, sammenligner den med millioner af dokument-embeddinger og returnerer artikler om deep learning, modeloptimering og træningsteknikker—alt sammen uden at kræve nøjagtige nøgleordsmatch. Denne matchingproces sker på millisekunder og gør det praktisk for realtidsapplikationer, der betjener millioner af brugere samtidig.
Forskellige typer embeddinger tjener forskellige formål afhængigt af, hvad du vil matche eller forstå. Word embeddinger indfanger betydningen af individuelle ord og fungerer godt til opgaver, der kræver finmasket semantisk forståelse, mens sentence embeddinger og dokumentembeddinger samler betydning på tværs af længere tekst, hvilket gør dem ideelle til at matche hele forespørgsler med hele artikler eller dokumenter. Billedeembeddinger repræsenterer visuelt indhold numerisk og gør det muligt for systemer at finde visuelt lignende billeder eller matche billeder med tekstbeskrivelser, mens brugerembeddinger og produktembeddinger indfanger adfærdsmønstre og karakteristika og driver anbefalingssystemer, som foreslår varer baseret på brugerpræferencer. Valget mellem disse embeddingtyper indebærer afvejninger: word embeddinger er beregningsmæssigt effektive, men mister kontekst, mens dokumentembeddinger bevarer fuld betydning, men kræver mere processorkraft. Domænespecifikke embeddinger, finjusteret på specialiserede datasæt som medicinsk litteratur eller juridiske dokumenter, overgår ofte generelle modeller til branchespecifikke applikationer, selvom de kræver yderligere træningsdata og computerressourcer.
I praksis driver embeddinger nogle af de mest indflydelsesrige AI-applikationer, vi bruger dagligt, fra de søgeresultater du ser, til de produkter du får anbefalet online. Semantiske søgemaskiner bruger embeddinger til at forstå forespørgselsintention og fremvise relevant indhold uanset nøgleordsmatch, mens anbefalingssystemer hos Netflix, Amazon og Spotify udnytter bruger- og itemembeddinger til at forudsige, hvad du vil se, købe eller lytte til næste gang. Indholdsmoderationssystemer bruger embeddinger til at opdage skadeligt indhold ved at sammenligne brugergenererede indlæg med embeddinger af kendte politikovertrædelser, mens spørgsmål-svar-systemer matcher brugerens spørgsmål med relevante vidensbaseartikler ved at finde semantisk lignende indhold. Personliggøringsmotorer bruger embeddinger til at forstå brugerpræferencer og tilpasse oplevelser, og anomalidetektionssystemer identificerer usædvanlige mønstre ved at genkende, når nye datapunkter falder langt fra forventede embeddingklynger. Hos AmICited udnytter vi embeddinger til at overvåge, hvordan AI-systemer bruges på internettet, matcher brugerforespørgsler og indhold for at spore, hvor AI-genereret eller AI-assisteret indhold optræder, hjælper brands med at forstå deres AI-aftryk og sikre korrekt attribuering.
Effektiv implementering af embeddinger kræver omhyggelig opmærksomhed på flere tekniske hensyn, der påvirker både ydeevne og omkostninger. Modelvalg er afgørende—du skal balancere embeddingernes semantiske kvalitet mod beregningskrav, hvor større modeller som BERT producerer rigere repræsentationer, men kræver mere processorkraft end lettere alternativer. Dimensionalitet indebærer en væsentlig afvejning: højdimensionelle embeddinger fanger flere nuancer, men bruger mere hukommelse og gør lighedsberegninger langsommere, mens lavdimensionelle embeddinger er hurtigere, men kan miste vigtig semantisk information. For effektiv håndtering af storstilet matching bruger systemer specialiserede indekseringsstrategier som FAISS (Facebook AI Similarity Search) eller Annoy (Approximate Nearest Neighbors Oh Yeah), der gør det muligt at finde lignende embeddinger på millisekunder i stedet for sekunder ved at organisere vektorer i træstrukturer eller locality-sensitive hashing-skemaer. Finjustering af embeddingmodeller på domænespecifikke data kan dramatisk forbedre relevansen for specialiserede applikationer, men kræver mærket træningsdata og ekstra beregningskraft. Organisationer skal konstant balancere hastighed versus nøjagtighed, computeromkostninger versus semantisk kvalitet og generelle modeller versus specialiserede alternativer afhængigt af deres specifikke brugssituationer og begrænsninger.
Embeddingernes fremtid bevæger sig mod større sofistikering, effektivitet og integration med bredere AI-systemer og lover endnu mere effektive indholdsmatchnings- og forståelsesmuligheder. Multimodale embeddinger, der samtidig bearbejder tekst, billeder og lyd, er på vej, hvilket gør det muligt for systemer at matche på tværs af forskellige indholdstyper—finde billeder, der er relevante for tekstforespørgsler eller omvendt—og åbner helt nye muligheder for indholdsopdagelse og forståelse. Forskere udvikler stadig mere effektive embeddingmodeller, der leverer tilsvarende semantisk kvalitet med langt færre parametre, så avancerede AI-muligheder bliver tilgængelige for mindre organisationer og edge-enheder. Integration af embeddinger med store sprogmodeller skaber systemer, der ikke bare kan matche indhold semantisk, men også forstå kontekst, nuance og hensigt på hidtil usete niveauer. Efterhånden som AI-systemer bliver mere udbredte på internettet, bliver evnen til at spore, overvåge og forstå, hvordan indhold matches og bruges, stadig vigtigere—her udnytter platforme som AmICited embeddinger til at hjælpe organisationer med at overvåge deres brandtilstedeværelse, spore AI-brugsmønstre og sikre, at deres indhold tilskrives korrekt og bruges passende. Sammenløbet af bedre embeddinger, mere effektive modeller og sofistikerede overvågningsværktøjer skaber en fremtid, hvor AI-systemer er mere gennemsigtige, ansvarlige og i overensstemmelse med menneskelige værdier.
En vektorembedding er en numerisk repræsentation af data (tekst, billeder, lyd) i et højdimensionelt rum, der fanger semantisk betydning og relationer. Den konverterer abstrakte data til talrækker, som maskiner kan behandle og analysere matematisk.
Embeddinger konverterer abstrakte data til tal, som maskiner kan behandle, hvilket gør det muligt for AI at identificere mønstre, ligheder og relationer mellem forskellige stykker indhold. Denne matematiske repræsentation gør det muligt for AI-systemer at forstå betydning i stedet for blot at matche nøgleord.
Nøgleordsmatchning søger efter nøjagtige ord, mens semantisk lighed forstår betydning. Dette gør det muligt for systemer at finde relateret indhold selv uden identiske ord—for eksempel at matche 'automobil' med 'bil' baseret på semantisk relation frem for nøjagtigt tekstmatch.
Ja, embeddinger kan repræsentere tekst, billeder, lyd, brugerprofiler, produkter og mere. Forskellige embeddingmodeller er optimeret til forskellige datatyper, fra Word2Vec til tekst til CNN'er til billeder til spektrogrammer for lyd.
AmICited bruger embeddinger til at forstå, hvordan AI-systemer semantisk matcher og refererer til dit brand på tværs af forskellige AI-platforme og svar. Dette hjælper med at spore dit indholds tilstedeværelse i AI-genererede svar og sikre korrekt attribuering.
Nøgleudfordringer inkluderer valg af den rigtige model, håndtering af beregningsomkostninger, håndtering af højdimensionelle data, finjustering til specifikke domæner og afvejning mellem hastighed og nøjagtighed i lighedsberegninger.
Embeddinger muliggør semantisk søgning, som forstår brugerens hensigt og returnerer relevante resultater baseret på betydning frem for blot nøgleordsmatch. Dette gør det muligt for søgesystemer at finde indhold, der er konceptuelt relateret, selvom det ikke indeholder de nøjagtige forespørgselstermer.
Store sprogmodeller bruger embeddinger internt til at forstå og generere tekst. Embeddinger er fundamentale for, hvordan disse modeller behandler information, matcher indhold og genererer kontekstuelt passende svar.
Vektorembeddinger driver AI-systemer som ChatGPT, Perplexity og Google AI Overviews. AmICited sporer, hvordan disse systemer citerer og refererer til dit indhold, så du kan forstå dit brands tilstedeværelse i AI-genererede svar.
Lær hvordan embeddings fungerer i AI-søgemaskiner og sprogmodeller. Forstå vektorrepræsentationer, semantisk søgning og deres rolle i AI-genererede svar.

Lær hvad embeddings er, hvordan de fungerer, og hvorfor de er essentielle for AI-systemer. Opdag hvordan tekst omdannes til numeriske vektorer, der indfanger se...
Lær, hvordan vektorsøgning bruger maskinlærings-embeddings til at finde lignende elementer baseret på betydning fremfor eksakte nøgleord. Forstå vektordatabaser...