Wikipedia-citater som AI-træningsdata: Bølgeseffekten
Opdag hvordan Wikipedia-citater former AI-træningsdata og skaber en bølgeseffekt på tværs af LLM’er. Lær hvorfor din Wikipedia-tilstedeværelse betyder noget for AI-omtaler og brandopfattelse.
Udgivet den Jan 3, 2026.Sidst ændret den Jan 3, 2026 kl. 3:24 am
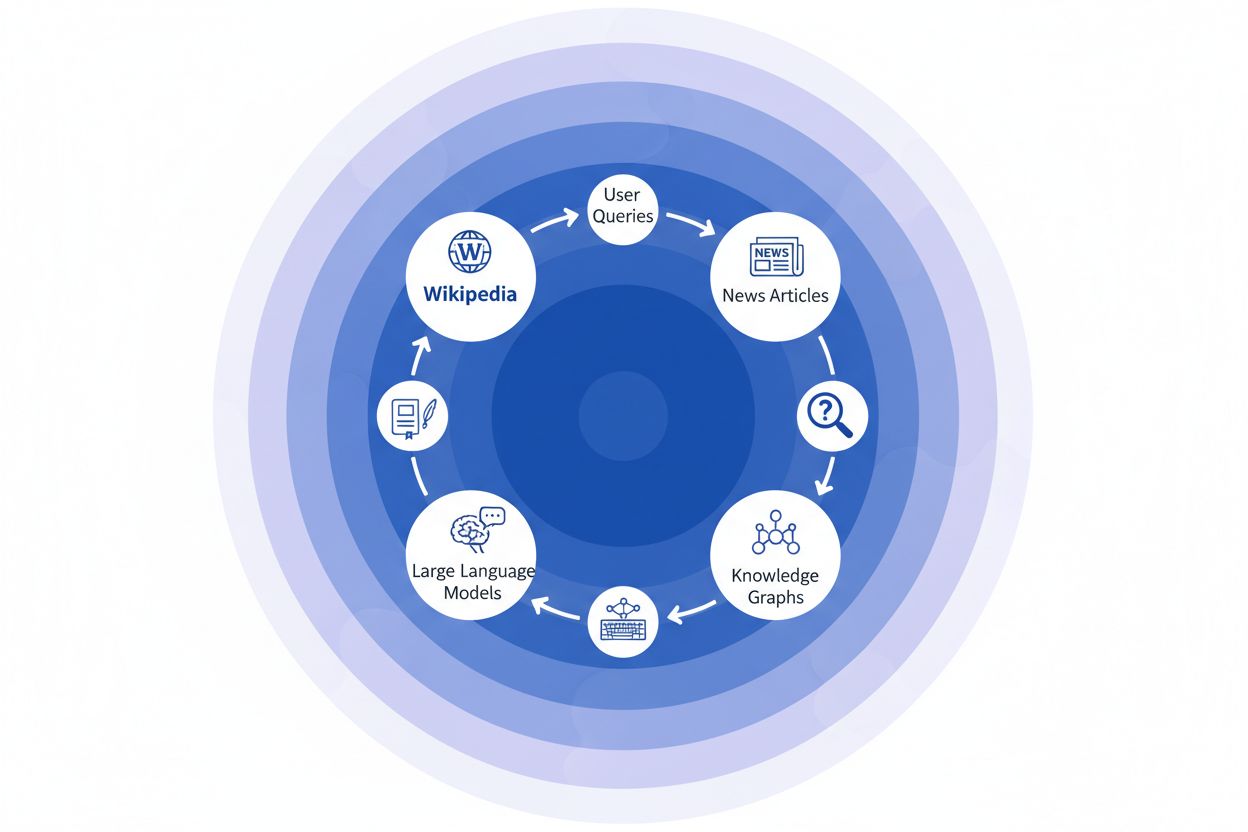
Wikipedia er blevet det grundlæggende træningsdatasæt for praktisk talt alle større store sprogmodeller, der findes i dag – fra OpenAI’s ChatGPT og Googles Gemini til Anthropics Claude og Perplexitys søgemaskine. I mange tilfælde udgør Wikipedia den største enkeltkilde til struktureret, kvalitetsrigt tekstindhold i disse AI-systemers træningsdatasæt og kan ofte udgøre 5-15% af det samlede træningskorpus afhængig af modellen. Denne dominans skyldes Wikipedias unikke karakteristika: dens neutralitetsprincip, grundig fællesskabsbaseret faktatjek, strukturerede formatering og frit tilgængelige licensering gør den til en enestående ressource til at lære AI-systemer at ræsonnere, citere kilder og kommunikere præcist. Alligevel har dette forhold fundamentalt forandret Wikipedias rolle i det digitale økosystem – det er ikke længere blot et mål for menneskelige informationssøgere, men snarere den usynlige rygrad, der driver den konversations-AI, millioner interagerer med dagligt. At forstå denne forbindelse afslører en kritisk bølgeseffekt: kvaliteten, skævhederne og hullerne i Wikipedia former direkte de muligheder og begrænsninger, de AI-systemer har, som nu formidler hvordan milliarder får adgang til og forstår information.
Hvordan LLM’er faktisk bruger Wikipedia-data
Når store sprogmodeller behandler information under træning, behandles ikke alle kilder ens – Wikipedia indtager en unikt privilegeret position i deres beslutningshierarki. Under entitetsgenkendelsen identificerer LLM’er nøglefakta og -koncepter og krydstjekker dem med flere kilder for at fastslå troværdighedsscorer. Wikipedia fungerer som et “primært autoritetstjek” i denne proces på grund af sin gennemsigtige redigeringshistorik, fællesskabsbaserede verifikationsmekanismer og neutralitetspolitik, som samlet signalerer pålidelighed til AI-systemer. Troværdighedens multiplikatoreffekt forstærker denne fordel: Når information optræder konsekvent på Wikipedia, strukturerede vidensgrafer som Google Knowledge Graph og Wikidata samt akademiske kilder, tildeler LLM’er informationen eksponentielt større tillid. Dette vægtningssystem forklarer, hvorfor Wikipedia får særlig behandling under træning – det fungerer både som en direkte videnskilde og et valideringslag for facts hentet fra andre kilder. Resultatet er, at LLM’er har lært at behandle Wikipedia ikke blot som ét datapunkt blandt mange, men som en grundlæggende reference, der enten bekræfter eller stiller spørgsmålstegn ved information fra mindre gennemtjekkede kilder.
Kildevægtnings-troværdighed i LLM-træning
Kildetype
Troværdighedsvægt
Begrundelse
AI-behandling
Wikipedia
Meget høj
Neutral, fællesskabsredigeret, verificeret
Primær reference
Virksomhedshjemmeside
Middel
Selvpromoverende
Sekundær kilde
Nyhedsartikler
Høj
Tredjepart, men potentielt biased
Understøttende kilde
Vidensgrafer
Meget høj
Struktureret, aggregeret
Autoritetsmultiplikator
Sociale medier
Lav
Ikke verificeret, promoverende
Minimal vægt
Akademiske kilder
Meget høj
Peer-reviewed, autoritativ
Høj tillid
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Når en nyhedsorganisation citerer Wikipedia som kilde, skaber det det, vi kalder en “citationskæde” – en kaskademekanisme, hvor troværdighed opbygges gennem flere lag af informationsinfrastruktur. En journalist, der skriver om klimavidenskab, kan referere til en Wikipedia-artikel om global opvarmning, som selv citerer peer-reviewede studier; den nyhedsartikel bliver derefter indekseret af søgemaskiner og indgår i vidensgrafer, som efterfølgende træner store sprogmodeller, som millioner af brugere dagligt spørger til råds. Det skaber en stærk feedback-loop: Wikipedia → Vidensgraf → LLM → Bruger, hvor den oprindelige Wikipedias artikels vinkling og fremhævning subtilt kan forme, hvordan AI-systemer præsenterer information for slutbrugere – ofte uden at brugerne er klar over, at informationen stammer fra et crowdsourcet leksikon. Tag et konkret eksempel: Hvis Wikipedias artikel om en medicinsk behandling fremhæver visse kliniske forsøg og nedtoner andre, vil dette redaktionelle valg bølge gennem nyhedsdækningen, blive indlejret i vidensgrafer og i sidste ende påvirke, hvordan ChatGPT eller lignende modeller besvarer patienters spørgsmål om behandlingsmuligheder. Denne “bølgeseffekt” betyder, at Wikipedias redaktionelle beslutninger ikke kun påvirker de læsere, der besøger siden direkte – de former grundlæggende det informationslandskab, som AI-systemer lærer fra og reflekterer tilbage til milliarder af brugere. Citationskæden gør i praksis Wikipedia fra at være et referencepunkt til at være et usynligt, men indflydelsesrigt lag i AI-træningskæden, hvor nøjagtighed og bias ved kilden forstærkes i hele økosystemet.
Bølgeseffekten: Følgevirkninger nedstrøms
Bølgeseffekten i Wikipedia-til-AI-økosystemet er måske den mest betydningsfulde dynamik, brands og organisationer skal forstå. Én enkelt Wikipedia-redigering ændrer ikke kun én kilde – den sætter gang i et sammenkoblet netværk af AI-systemer, der hver især trækker på og forstærker informationen på måder, der mangedobler dens effekt eksponentielt. Når der opstår en unøjagtighed på en Wikipedia-side, forbliver den ikke isoleret; den udbredes i hele AI-landskabet og former, hvordan dit brand beskrives, forstås og præsenteres for millioner af brugere dagligt. Denne multiplikatoreffekt betyder, at investering i Wikipedia-nøjagtighed ikke kun handler om én platform – det handler om at kontrollere din fortælling på tværs af hele det generative AI-økosystem. For digitale PR- og brand management-professionelle ændrer denne realitet grundlæggende, hvor ressourcer og opmærksomhed bør fokuseres.
Vigtige bølgeseffekter at overvåge:
Kvaliteten af Wikipedia-siden påvirker direkte, hvordan AI-systemer beskriver dit brand — Dårligt Wikipedia-indhold bliver fundamentet for, hvordan ChatGPT, Gemini, Claude og andre AI-systemer karakteriserer din organisation
Et enkelt Wikipedia-citat påvirker vidensgrafer, som påvirker AI Overviews — Citater flyder gennem Googles videninfrastruktur og påvirker direkte, hvordan information vises i AI-genererede sammendrag
Unøjagtig Wikipedia-information udbredes i hele AI-økosystemet — Når misinformation først indgår i træningsdata, bliver det eksponentielt sværere at korrigere på tværs af flere platforme
Positiv Wikipedia-tilstedeværelse forstærkes på alle store AI-platforme — En velvedligeholdt Wikipedia-side skaber ensartet, autoritativ kommunikation på ChatGPT, Gemini, Claude, Perplexity og nye AI-systemer
Wikipedia-redigeringer har forsinkede, men sammensatte effekter på AI-træning — Ændringer i dag påvirker AI-modellernes output i måneder eller år, efterhånden som information cykler gennem gentræningsprocesser
Bølgen når ud til Google AI Overviews, featured snippets og knowledge panels — Wikipedia fungerer som den autoritative kilde, der fodrer ind i Googles AI-genererede søgeresultater og strukturerede datavisninger
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Wikipedias bæredygtighedsudfordring: Truslen mod økosystemet
Ny forskning fra IUP-studiet af Vetter m.fl. har belyst en kritisk sårbarhed i vores AI-infrastruktur: Wikipedias bæredygtighed som træningsressource er i stigende grad truet af den teknologi, den selv hjælper med at drive. Efterhånden som store sprogmodeller formerer sig og trænes på stadigt voksende datasæt af LLM-genereret indhold, står feltet over for et voksende “modelkollaps”-problem, hvor kunstige outputs begynder at forurene træningsdatapuljen og forringer modelkvaliteten gennem flere generationer. Dette fænomen er særligt udtalt, da Wikipedia – et crowdsourcet leksikon bygget på menneskelig ekspertise og frivilligt arbejde – er blevet en grundpille for træning af avancerede AI-systemer, ofte uden eksplicit anerkendelse eller kompensation til bidragyderne. De etiske implikationer er dybe: Mens AI-virksomheder udvinder værdi af Wikipedias frit bidragede viden, samtidig med at de oversvømmer informationsøkosystemet med syntetisk indhold, udsættes de incitamentsstrukturer, der har opretholdt Wikipedias frivillige fællesskab i over to årtier, for hidtil uset pres. Uden målrettet indsats for at bevare menneskeskabt indhold som en særskilt og beskyttet ressource risikerer vi at skabe en feedback-loop, hvor AI-genereret tekst gradvist erstatter autentisk menneskelig viden og i sidste ende underminerer det fundament, som moderne sprogmodeller hviler på. Wikipedias bæredygtighed er derfor ikke kun et anliggende for leksikonet selv, men et kritisk spørgsmål for hele informationsøkosystemet og for den fremtidige levedygtighed af AI-systemer, der er afhængige af ægte menneskelig viden.
Overvågning af din Wikipedia-tilstedeværelse: Hvor passer AmICited ind?
I takt med at AI-systemer i stigende grad baserer sig på Wikipedia som grundlæggende videnskilde, er det blevet essentielt for moderne organisationer at overvåge, hvordan deres brand fremstår i disse AI-genererede svar. AmICited.com er specialiseret i at spore Wikipedia-citater, efterhånden som de bølger gennem AI-systemer, og giver brands indsigt i, hvordan deres Wikipedia-tilstedeværelse oversættes til AI-omtale og anbefalinger. Mens alternative værktøjer som FlowHunt.io tilbyder generel webovervågning, fokuserer AmICited unikt på Wikipedia-til-AI-citationskæden og opfanger det specifikke øjeblik, hvor AI-systemer refererer til din Wikipedia-indgang og hvordan det påvirker deres svar. At forstå denne sammenhæng er kritisk, da Wikipedia-citater tillægges stor vægt i AI-træningsdata og responsgenerering – en velvedligeholdt Wikipedia-tilstedeværelse informerer ikke kun menneskelige læsere, men former, hvordan AI-systemer opfatter og præsenterer dit brand for millioner af brugere. Ved at overvåge dine Wikipedia-omtaler gennem AmICited får du handlingsorienteret indsigt i dit AI-aftryk, så du kan optimere din Wikipedia-tilstedeværelse med fuldt overblik over dens afledte effekt på AI-drevet opdagelse og brandopfattelse.
Ofte stillede spørgsmål
Bliver Wikipedia virkelig brugt til at træne alle LLM'er?
Ja, alle større LLM'er inklusive ChatGPT, Gemini, Claude og Perplexity inkluderer Wikipedia i deres træningsdata. Wikipedia er ofte den største enkeltkilde til struktureret, verificeret information i LLM-træningsdatasæt og udgør typisk 5-15% af det samlede træningskorpus.
Hvordan påvirker Wikipedia, hvad AI-systemer siger om mit brand?
Wikipedia fungerer som et troværdighedstjekpunkt for AI-systemer. Når en LLM genererer information om dit brand, vægtes Wikipedias beskrivelse tungere end andre kilder, hvilket gør din Wikipedia-side til en kritisk indflydelse på, hvordan AI-systemer repræsenterer dig på tværs af ChatGPT, Gemini, Claude og andre platforme.
Hvad er 'bølgeseffekten' i forbindelse med Wikipedia og AI?
Bølgeseffekten refererer til, hvordan et enkelt Wikipedia-citat eller en redigering skaber følgevirkninger på tværs af hele AI-økosystemet. Én Wikipedia-ændring kan påvirke vidensgrafer, som påvirker AI-oversigter, som igen påvirker, hvordan flere AI-systemer beskriver dit brand for millioner af brugere.
Kan upræcis Wikipedia-information skade mit brand i AI-systemer?
Ja. Fordi LLM'er betragter Wikipedia som meget troværdig, vil upræcis information på din Wikipedia-side blive videreført gennem AI-systemer. Dette kan påvirke, hvordan ChatGPT, Gemini og andre AI-platforme beskriver din organisation og potentielt skade din brandopfattelse.
Hvordan kan jeg overvåge, hvordan Wikipedia påvirker mit brand i AI-systemer?
Værktøjer som AmICited.com sporer, hvordan dit brand nævnes og citeres på tværs af AI-systemer, herunder ChatGPT, Perplexity og Google AI Overviews. Dette hjælper dig med at forstå bølgeseffekten af din Wikipedia-tilstedeværelse og optimere derefter.
Bør jeg selv oprette eller redigere min Wikipedia-side?
Wikipedia har strenge politikker mod selvpromovering. Enhver redigering bør følge Wikipedias retningslinjer og være baseret på pålidelige tredjepartskilder. Mange organisationer arbejder sammen med Wikipedia-specialister for at sikre overholdelse og samtidig opretholde en nøjagtig tilstedeværelse.
Hvor lang tid tager det, før Wikipedia-ændringer påvirker AI-systemer?
LLM'er trænes på datamængder fra bestemte tidspunkter, så ændringer tager tid at slå igennem. Vidensgrafer opdateres dog hyppigere, så bølgeseffekten kan begynde inden for uger til måneder afhængigt af AI-systemet og hvornår det gen-trænes.
Hvad er forskellen på Wikipedia og vidensgrafer i AI-træning?
Wikipedia er en primær kilde, der bruges direkte i LLM-træning. Vidensgrafer som Googles Knowledge Graph samler information fra flere kilder, herunder Wikipedia, og føder det ind i AI-systemer, hvilket skaber et ekstra lag af indflydelse på, hvordan AI-systemer forstår og præsenterer information.
Overvåg din Wikipedia-tilstedeværelse i AI-systemer
Følg hvordan Wikipedia-citater bølger gennem ChatGPT, Gemini, Claude og andre AI-systemer. Forstå dit AI-aftryk og optimer din Wikipedia-tilstedeværelse med AmICited.
Wikipedias rolle i AI-træningsdata: Kvalitet, indflydelse og licensering
Opdag hvordan Wikipedia fungerer som et kritisk AI-træningsdatasæt, dets indflydelse på modelnøjagtighed, licensaftaler, og hvorfor AI-virksomheder er afhængige...
Bliv citeret i Wikipedia-artikler: En ikke-manipulerende tilgang
Lær etiske strategier til at få dit brand citeret på Wikipedia. Forstå Wikipedias indholdspolitikker, pålidelige kilder, og hvordan du kan udnytte citationer fo...
Wikipedias Rolle i AI-citater: Sådan Former Det AI-genererede Svar
Opdag hvordan Wikipedia påvirker AI-citater på tværs af ChatGPT, Perplexity og Google AI. Lær hvorfor Wikipedia er den mest betroede kilde til AI-træning, og hv...
12 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.