
Når AI tager fejl: Håndtering af ukorrekte brandoplysninger
Lær hvordan du identificerer, forebygger og retter AI-misinformation om dit brand. Opdag 7 gennemprøvede strategier og værktøjer til at beskytte dit omdømme i A...
8 min læsning
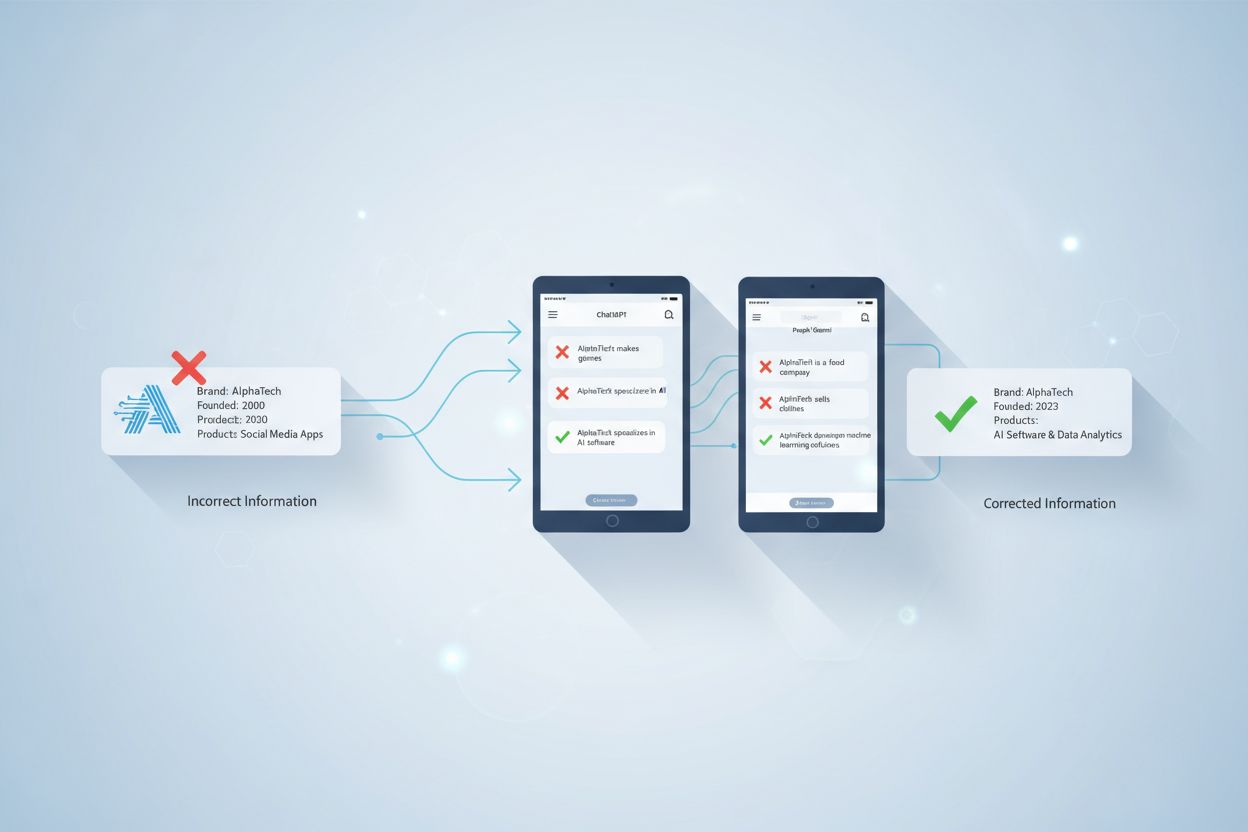
AI-fejlinformationskorrektion henviser til strategier og værktøjer til at identificere og adressere forkerte brandoplysninger, der optræder i AI-genererede svar fra systemer som ChatGPT, Gemini og Perplexity. Det indebærer overvågning af, hvordan AI-systemer repræsenterer brands og implementering af kildebaserede rettelser for at sikre, at nøjagtige oplysninger distribueres på tværs af betroede platforme. I modsætning til traditionel faktatjekning fokuserer det på at rette de kilder, som AI-systemerne stoler på, snarere end AI-outputtene selv. Dette er essentielt for at opretholde brandets omdømme og nøjagtighed i et AI-drevet søgemiljø.
AI-fejlinformationskorrektion henviser til strategier og værktøjer til at identificere og adressere forkerte brandoplysninger, der optræder i AI-genererede svar fra systemer som ChatGPT, Gemini og Perplexity. Det indebærer overvågning af, hvordan AI-systemer repræsenterer brands og implementering af kildebaserede rettelser for at sikre, at nøjagtige oplysninger distribueres på tværs af betroede platforme. I modsætning til traditionel faktatjekning fokuserer det på at rette de kilder, som AI-systemerne stoler på, snarere end AI-outputtene selv. Dette er essentielt for at opretholde brandets omdømme og nøjagtighed i et AI-drevet søgemiljø.
AI-fejlinformationskorrektion henviser til de strategier, processer og værktøjer, der bruges til at identificere og adressere forkerte, forældede eller vildledende oplysninger om brands, der optræder i AI-genererede svar fra systemer som ChatGPT, Gemini og Perplexity. Nyere forskning viser, at cirka 45% af AI-forespørgsler giver fejlagtige svar, hvilket gør brandnøjagtighed i AI-systemer til en kritisk udfordring for virksomheder. I modsætning til traditionelle søgeresultater, hvor brands kan kontrollere deres egne lister, sammenfatter AI-systemer information fra flere kilder på nettet, hvilket skaber et komplekst landskab, hvor fejlinformation kan eksistere ubemærket. Udfordringen handler ikke kun om at rette enkelte AI-svar—det handler om at forstå, hvorfor AI-systemer får brandoplysninger galt fra starten, og om at implementere systematiske rettelser på kildeniveau.
AI-systemer opfinder ikke brandoplysninger fra bunden; de sammensætter dem ud fra det, der allerede findes på internettet. Denne proces skaber dog flere forudsigelige fejlpunkter, der fører til fejlagtig brandrepræsentation:
| Root Cause | How It Happens | Business Impact |
|---|---|---|
| Kildeinkonsistens | Brandet beskrevet forskelligt på tværs af hjemmesider, kataloger og artikler | AI udleder forkert konsensus ud fra modstridende information |
| Forældede autoritative kilder | Gamle Wikipedia-indlæg, kataloglister eller sammenligningssider indeholder forkerte data | Nyere rettelser ignoreres, fordi ældre kilder har højere autoritetssignaler |
| Entitetsforvirring | Lignende brandnavne eller overlappende kategorier forvirrer AI-systemer | Konkurrenter får æren for dine evner, eller brandet udelades helt |
| Manglende primære signaler | Manglende strukturerede data, tydelige Om os-sider eller konsistent terminologi | AI tvinges til at udlede information, hvilket fører til vage eller forkerte beskrivelser |
Når et brand beskrives forskelligt på tværs af platforme, har AI-systemer svært ved at afgøre, hvilken version der er autoritativ. I stedet for at bede om præcisering udleder de konsensus baseret på frekvens og opfattet autoritet—selv når denne konsensus er forkert. Små forskelle i brandnavne, beskrivelser eller positionering bliver ofte duplikeret på tværs af platforme, og når de gentages, bliver disse fragmenter til signaler, som AI-modeller opfatter som pålidelige. Problemet forværres, når forældede, men autoritative sider indeholder forkerte oplysninger; AI-systemer vægter ofte disse ældre kilder højere end nyere rettelser, især hvis rettelserne ikke er bredt spredt på betroede platforme.
At rette forkerte brandoplysninger i AI-systemer kræver en fundamentalt anderledes tilgang end traditionel SEO-oprydning. Ved traditionel SEO opdaterer brands deres egne lister, retter NAP-data (Navn, Adresse, Telefon) og optimerer indhold på siden. AI-brandkorrektion fokuserer på at ændre, hvad betroede kilder siger om dit brand, ikke på at kontrollere din egen synlighed. Du retter ikke AI direkte—du retter det, AI stoler på. Forsøg på at “rette” AI-svar ved gentagne gange at fremhæve forkerte påstande (selv for at afvise dem) kan have den modsatte effekt ved at forstærke den sammenhæng, du vil fjerne. AI-systemer genkender mønstre, ikke hensigt. Det betyder, at enhver rettelse skal begynde på kildeniveau og tage udgangspunkt i, hvor AI-systemerne faktisk lærer information fra.
Før du kan rette forkerte brandoplysninger, skal du have indsigt i, hvordan AI-systemer aktuelt beskriver dit brand. Effektiv overvågning fokuserer på:
Manuelle tjek er ikke pålidelige, fordi AI-svar varierer efter prompt, kontekst og opdateringscyklus. Strukturerede overvågningsværktøjer giver den nødvendige indsigt til at opdage fejl tidligt, før de bliver indlejret i AI-systemerne. Mange brands opdager først, at de bliver fejlagtigt repræsenteret i AI, når en kunde nævner det eller en krise opstår. Proaktiv overvågning forhindrer dette ved at fange uoverensstemmelser, før de spredes.
Når du har identificeret forkerte brandoplysninger, skal rettelsen ske dér, hvor AI-systemerne faktisk lærer fra—ikke kun, hvor fejlen optræder. Effektive kildebaserede rettelser omfatter:
Hovedprincippet er: rettelser virker kun, når de udføres på kildeniveau. At ændre, hvad der vises i AI-output uden at rette de underliggende kilder, er kun midlertidigt. AI-systemer revurderer løbende signaler, når nyt indhold optræder og ældre sider genopstår. En rettelse, der ikke adresserer den oprindelige kilde, vil til sidst blive overskrevet af den oprindelige fejlinformation.
Når du retter forkerte brandoplysninger på tværs af kataloger, markedspladser eller AI-drevne platforme, kræver de fleste systemer verifikation, der forbinder brandet til den legitime ejer og brug. Ofte krævet dokumentation omfatter:
Målet er ikke mængde—det er konsistens. Platforme vurderer, om dokumentation, lister og offentligt tilgængelige branddata stemmer overens. At have disse materialer klar på forhånd reducerer afvisningscyklusser og fremskynder godkendelsen, når du retter forkerte brandoplysninger i stor skala. Konsistens på tværs af kilder signalerer til AI-systemer, at dine brandoplysninger er pålidelige og autoritative.
Flere værktøjer hjælper nu teams med at spore brandrepræsentation på tværs af AI-søgeplatforme og det bredere web. Selvom funktionerne overlapper, fokuserer de generelt på synlighed, attribuering og konsistens:
Disse værktøjer retter ikke direkte forkerte brandoplysninger. De hjælper derimod teams med tidligt at opdage fejl, identificere branddatadiskrepanser, før de spreder sig, validere om kildebaserede rettelser forbedrer AI-nøjagtighed og overvåge langsigtede tendenser i AI-attribuering og synlighed. Bruges de sammen med kildeforbedringer og dokumentation, giver overvågningsværktøjer den feedback-loop, der er nødvendig for at rette forkerte brandoplysninger bæredygtigt.
AI-søgenøjagtighed forbedres, når brands er klart definerede entiteter, ikke vage deltagere i en kategori. For at reducere fejlagtig brandrepræsentation i AI-systemer, fokuser på:
Målet er ikke at sige mere—det er at sige det samme overalt. Når AI-systemer møder konsistente branddefinitioner på tværs af autoritative kilder, stopper de med at gætte og begynder at gentage de korrekte oplysninger. Dette skridt er især vigtigt for brands, der oplever forkerte omtaler, konkurrentattribuering eller udeladelse fra relevante AI-svar. Selv efter du har rettet forkerte brandoplysninger, er nøjagtighed ikke permanent. AI-systemer revurderer løbende signaler, så vedvarende klarhed er afgørende.
Der findes ingen fast tidslinje for at rette fejlagtig brandrepræsentation i AI-systemer. AI-modeller opdaterer baseret på signalstyrke og konsensus, ikke indsendelsestidspunkter. Typiske mønstre omfatter:
Tidlige fremskridt viser sig sjældent som et pludseligt “rettet” svar. Kig i stedet efter indirekte signaler: mindre variation i AI-svar, færre modstridende beskrivelser, mere konsistente kildehenvisninger og gradvis inklusion af dit brand, hvor det tidligere blev udeladt. Stilstand ser anderledes ud—hvis den samme forkerte formulering vedvarer trods flere rettelser, indikerer det oftest, at den oprindelige kilde ikke er blevet rettet, eller at der skal forstærkes andre steder.
Den mest pålidelige måde at rette forkerte brandoplysninger på er at reducere de forhold, der får dem til at opstå. Effektiv forebyggelse indebærer:
Brands, der betragter AI-synlighed som et levende system—ikke et engangsoprydningsprojekt—kommer sig hurtigere over fejl og oplever færre gentagne tilfælde af fejlagtig brandrepræsentation. Forebyggelse handler ikke om at kontrollere AI-output. Det handler om at opretholde rene, konsistente input, som AI-systemer trygt kan gentage. Efterhånden som AI-søgning udvikler sig, er det de brands, der anerkender fejlinformationskorrektion som en løbende proces med kontinuerlig overvågning, kildehåndtering og strategisk forstærkning af korrekte oplysninger på tværs af betroede platforme, der får succes.
AI-fejlinformationskorrektion er processen med at identificere og rette forkerte, forældede eller vildledende oplysninger om brands, der optræder i AI-genererede svar. I modsætning til traditionel faktatjekning, fokuserer det på at rette de kilder, som AI-systemerne stoler på (kataloger, artikler, lister), i stedet for at forsøge at redigere AI-output direkte. Målet er at sikre, at brugere får nøjagtige oplysninger om dit brand, når de spørger AI-systemer.
AI-systemer som ChatGPT, Gemini og Perplexity påvirker nu, hvordan millioner af mennesker lærer om brands. Forskning viser, at 45% af AI-forespørgsler giver fejl, og forkerte brandoplysninger kan skade omdømmet, forvirre kunder og føre til tabt forretning. I modsætning til traditionel søgning, hvor brands kontrollerer deres egne lister, sammenfatter AI-systemer information fra flere kilder, hvilket gør brandnøjagtighed sværere at styre, men endnu vigtigere at håndtere.
Nej, direkte rettelser virker ikke effektivt. AI-systemer gemmer ikke brandoplysninger i redigerbare placeringer—de sammenfatter svar fra eksterne kilder. Gentagne gange at bede AI om at 'rette' oplysninger kan faktisk forstærke fejlopfattelser ved at styrke den sammenhæng, du forsøger at fjerne. I stedet skal rettelser ske på kildeniveau: opdatér kataloger, ret forældede lister og publicér nøjagtige oplysninger på betroede platforme.
Der er ingen fast tidslinje, fordi AI-systemer opdaterer baseret på signalstyrke og konsensus, ikke indsendelsesdatoer. Mindre faktuelle rettelser vises typisk inden for 2-4 uger, entitetsniveau-afklaringer tager 1-3 måneder, og konkurrencefortrængning kan tage 3-6 måneder eller længere. Fremskridt viser sig sjældent som et pludseligt 'løst' svar—se i stedet efter mindre variation i svarene og mere konsistente kildehenvisninger.
Flere værktøjer overvåger nu brandrepræsentation på tværs af AI-platforme: Wellows overvåger omtale og sentiment på ChatGPT, Gemini og Perplexity; Profound sammenligner synlighed på tværs af LLM'er; Otterly.ai analyserer brandsentiment i AI-svar; BrandBeacon leverer positioneringsanalyser; Ahrefs Brand Radar sporer web-omtaler; og AmICited.com har specialiseret sig i at overvåge, hvordan brands nævnes og repræsenteres i AI-systemer. Disse værktøjer hjælper med tidligt at opdage fejl og validere, om rettelser virker.
AI-hallucinationer opstår, når AI-systemer genererer information, der ikke er baseret på træningsdata eller afkodes forkert. AI-fejlinformation er falsk eller vildledende information, der optræder i AI-output, hvilket kan skyldes hallucinationer, men også forældede kilder, entitetsforvirring eller inkonsistente data på tværs af platforme. Fejlinformationskorrektion retter både hallucinationer og kildebaserede unøjagtigheder, der fører til forkert brandrepræsentation.
Overvåg hvordan AI-systemer beskriver dit brand ved at stille dem spørgsmål om din virksomhed, produkter og positionering. Se efter forældede oplysninger, forkerte beskrivelser, manglende detaljer eller konkurrenthenvisninger. Brug overvågningsværktøjer til at spore omtaler på ChatGPT, Gemini og Perplexity. Tjek om dit brand udelades fra relevante AI-svar. Sammenlign AI-beskrivelser med dine officielle brandoplysninger for at identificere uoverensstemmelser.
Det er en løbende proces. AI-systemer revurderer løbende signaler, efterhånden som nyt indhold optræder, og ældre sider dukker op igen. En engangsrettelse uden løbende overvågning vil til sidst blive overskrevet af den oprindelige fejlinformation. Brands, der lykkes, behandler AI-synlighed som et levende system, opretholder konsistente branddefinitioner på tværs af kilder, auditerer kataloger regelmæssigt og overvåger AI-omtaler løbende for at fange nye fejl, før de spreder sig.
Følg med i, hvordan AI-systemer som ChatGPT, Gemini og Perplexity repræsenterer dit brand. Få realtidsindsigt i brandomtaler, kildehenvisninger og synlighed på tværs af AI-platforme med AmICited.com.
Lær hvordan du identificerer, forebygger og retter AI-misinformation om dit brand. Opdag 7 gennemprøvede strategier og værktøjer til at beskytte dit omdømme i A...

Lær hvordan du bestrider unøjagtige AI-oplysninger, rapporterer fejl til ChatGPT og Perplexity, og implementerer strategier for at sikre, at dit brand er korrek...
Lær effektive strategier til at identificere, overvåge og korrigere unøjagtige oplysninger om dit brand i AI-genererede svar fra ChatGPT, Perplexity og andre AI...