Definition af Artikel-Skema
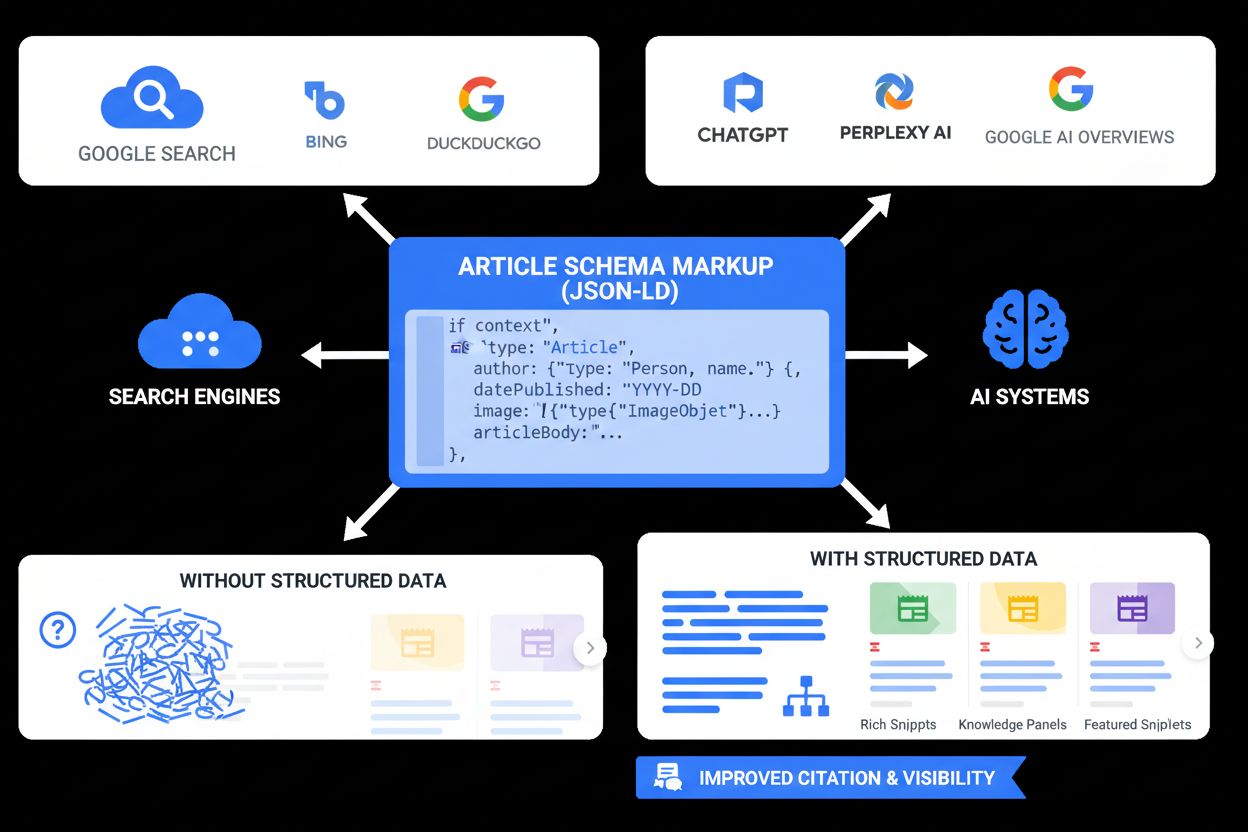
Artikel-Skema er en struktureret datamarkup-type fra Schema.org, der eksplicit definerer egenskaber og metadata for nyhedsartikler, blogindlæg og andet skriftligt indhold. Implementeret med JSON-LD-format formidler Artikel-Skema væsentlig information om dit indhold til søgemaskiner, AI-systemer og andre digitale platforme. Denne markup inkluderer centrale egenskaber som headline, author, datePublished, dateModified, image og articleBody, hvilket gør maskiner i stand til at forstå ikke blot, hvad dit indhold handler om, men også hvem der har skabt det, hvornår det blev udgivet, og hvordan det skal præsenteres. Artikel-Skema fungerer som bro mellem menneskelæsbart webindhold og maskinlæsbare data, hvilket gør dine artikler søgbare og citerbare på tværs af søgemaskiner, AI-svarmotorer som ChatGPT og Perplexity samt nye AI-drevne platforme. Ved at implementere Artikel-Skema sikrer udgivere, at deres indhold forstås korrekt og tilskrives korrekt, når det citeres af AI-systemer, hvilket bliver stadig vigtigere, da AI-genererede svar bliver en primær måde at opdage online-indhold på.
Kontekst og Historisk Udvikling
Udviklingen af Artikel-Skema afspejler det bredere skift i, hvordan digitalt indhold opdages og forbruges. Schema.org, lanceret i 2011 som et samarbejde mellem Google, Bing, Yahoo og Yandex, skabte et standardiseret vokabular for strukturerede data. Artikel-Skema opstod som en af de grundlæggende typer, designet til at hjælpe søgemaskiner med at forstå karakteren og konteksten for offentliggjort indhold. Oprindeligt blev Artikel-Skema primært brugt til at forbedre udseendet i søgeresultater via rich snippets, hvor ekstra metadata som udgivelsesdato og forfatter blev vist direkte i søgeresultatet.
Formålet og betydningen af Artikel-Skema har dog ændret sig markant med fremkomsten af AI-søgemaskiner og store sprogmodeller (LLMs). Ifølge forskning fra Profound blev cirka 680 millioner citater sporet på ChatGPT, Google AI Overviews og Perplexity mellem august 2024 og juni 2025, hvilket viser, at AI-systemer i høj grad er afhængige af strukturerede data for at identificere og citere autoritative kilder. Over 80 % af citaterne på de store AI-platforme kommer fra .com-domæner, mens non-profit .org-sider udgør den næststørste kategori med 11,29 % af ChatGPT-citaterne. Disse data demonstrerer, at Artikel-Skema nu er essentielt, ikke kun for traditionel søgesynlighed, men for at sikre, at dit indhold anerkendes og citeres af AI-systemer, som nu påvirker, hvordan milliarder af mennesker finder information.
Skiftet fra søgefokuseret til AI-fokuseret implementering udgør et grundlæggende brud i, hvordan udgivere bør gribe Artikel-Skema an. Hvor målet tidligere var at forbedre udseendet i søgeresultater, skal udgivere i dag sikre, at deres Artikel-Skema er så omfattende og nøjagtigt, at AI-systemer kan udtrække, forstå og korrekt tilskrive deres indhold. Denne udvikling har gjort Artikel-Skema-implementering til en kritisk komponent i Generative Engine Optimization (GEO) og AI-synlighedsstrategi.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Teknisk Implementering og Egenskaber
Artikel-Skema implementeres som et JSON-LD (JavaScript Object Notation for Linked Data)-blok placeret i <head>-sektionen af dit HTML-dokument. JSON-LD anbefales af Google, Bing og alle større søgemaskiner, da det holder strukturerede data adskilt fra hoved-HTML’en, hvilket gør det lettere at vedligeholde og mindre fejlbehæftet. Grundstrukturen for Artikel-Skema inkluderer @context-egenskaben (der specificerer Schema.org-vokabularet), @type-egenskaben (der identificerer indholdet som Article, NewsArticle eller BlogPosting) samt forskellige egenskaber, der beskriver artikelens metadata.
De anbefalede egenskaber for Artikel-Skema inkluderer:
- headline: Artikelens titel, som bør være kortfattet og beskrivende
- image: URLs til billeder, der repræsenterer artiklen; Google anbefaler flere billedforhold (1x1, 4x3, 16x9) og minimum 50K pixels
- datePublished: Den oprindelige udgivelsesdato i ISO 8601-format
- dateModified: Seneste redigeringsdato, vigtig for at AI-systemer forstår indholdets aktualitet
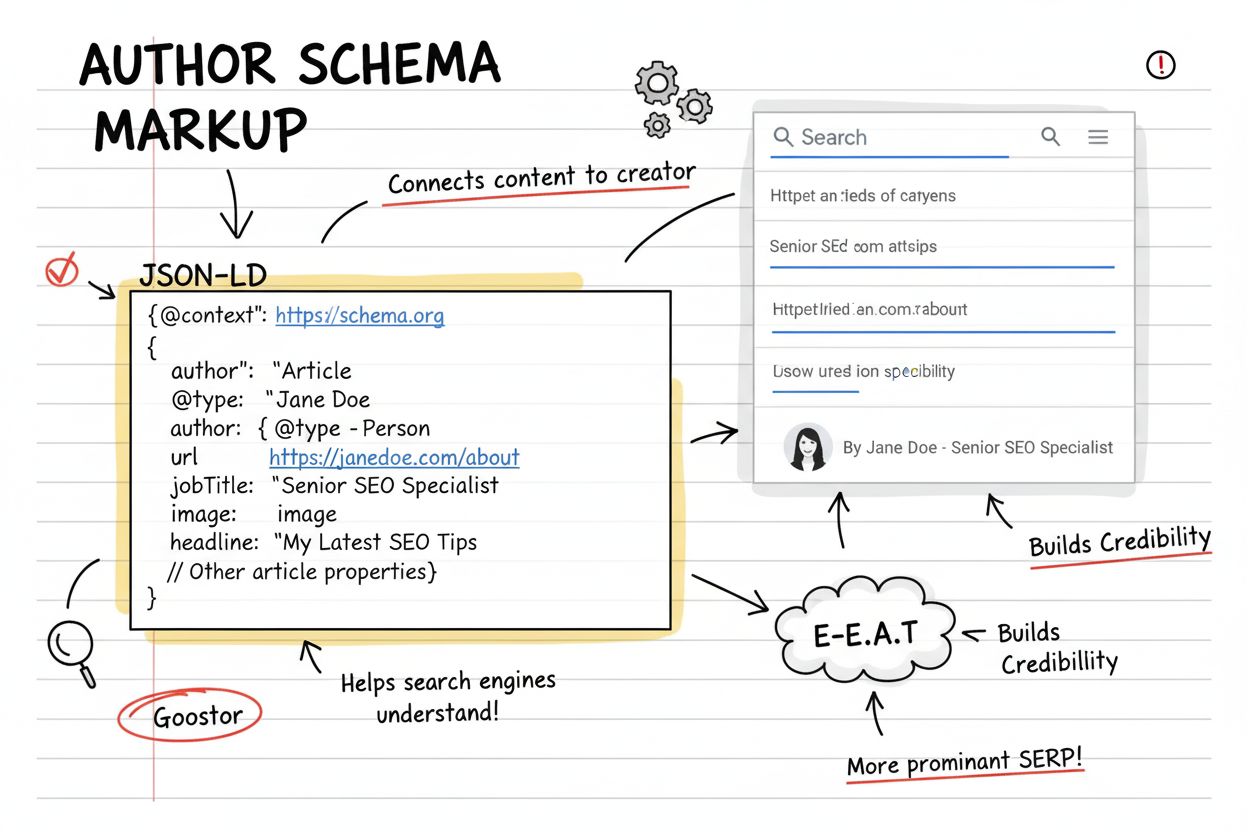
- author: Personen eller organisationen, der har skabt indholdet, med egenskaber for navn og URL
- articleBody: Selve tekstindholdet i artiklen
- articleSection: Sektionen eller kategorien, artiklen tilhører (fx “Teknologi”, “Sport”)
- description: En kort opsummering af artikelens indhold
- publisher: Organisationen, der udgiver artiklen
Ifølge dokumentationen fra Google Search Central er ingen egenskaber strengt påkrævede, men inklusion af disse anbefalede egenskaber øger markant dine chancer for at optræde i rich results og blive forstået korrekt af AI-systemer. author-egenskaben er især vigtig for AI-citering, da den etablerer indholdets autoritet og hjælper AI-systemer med korrekt tilskrivning. Forskning fra Evertune indikerer, at schema-optimeret indhold gør det nemt for AI-systemer at forstå, udtrække og citere information korrekt, og sider med velimplementeret skema optræder hyppigere i AI-genererede svar.
Sammenligningstabel: Typer af Artikel-Skema og Relateret Markup
| Schema Type | Bedste Anvendelse | Indholdslængde | Nøgleforskel | AI-citeringsprioritet |
|---|
| Article | Generelt skriftligt indhold, blogs, artikler | 500+ ord | Overordnet type, der dækker alle artikler | Høj - Universel accept |
| NewsArticle | Nyhedsudgivelser, breaking news | 300+ ord | Indeholder nyhedsspecifikke egenskaber | Meget høj - Nyhedsfokuserede AI-systemer |
| BlogPosting | Personlige blogs, virksomhedsblogs | 50-400 ord | Optimeret til blogspecifikke metadata | Mellem - Blogspecifikke platforme |
| ScholarlyArticle | Akademiske artikler, forskning | 1000+ ord | Indeholdt citat- og forsknings-egenskaber | Meget høj - Akademiske AI-systemer |
| TechArticle | Teknologivejledninger, how-tos | 500+ ord | Indeholder trin-for-trin instruktioner | Høj - Teknologifokuserede platforme |
| Report | Brancherapporter, whitepapers | 2000+ ord | Formelt publikationsformat | Høj - Enterprise AI-systemer |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Sådan Påvirker Artikel-Skema AI-søgning og Citering
Forholdet mellem Artikel-Skema og AI-synlighed er blevet en af de vigtigste faktorer i moderne indholdsstrategi. Forskning fra Profound, der analyserede 680 millioner citater på store AI-platforme, viser tydelige mønstre i, hvordan forskellige AI-systemer indhenter og citerer information. ChatGPT har en stærk præference for autoritative kilder som Wikipedia (7,8 % af det samlede antal citater), mens Google AI Overviews udviser en mere balanceret tilgang på tværs af Reddit (2,2 %), YouTube (1,9 %) og Quora (1,5 %). Perplexity favoriserer stærkt indhold drevet af fællesskabet, hvor Reddit udgør 6,6 % af det samlede antal citater.
Det, der forener alle disse platforme, er deres afhængighed af strukturerede data for at forstå indholdets kontekst og autoritet. Når Artikel-Skema implementeres korrekt, kan AI-systemer:
- Identificere indholdstype og formål – AI-systemer forstår, om indholdet er nyheder, analyse eller mening
- Udtrække forfatter- og udgiverinformation – Korrekt tilskrivning bliver automatisk og nøjagtig
- Bestemme indholdets aktualitet –
dateModified-egenskaben hjælper AI-systemer med at afgøre, om informationen er opdateret - Forstå indholdsrelationer – Skemamarkup hjælper AI-systemer med at forbinde relaterede artikler og emner
- Vurdere indholdets autoritet – Forfatter-URL’er og udgiverinformation hjælper AI-systemer med at vurdere kildens troværdighed
BrightEdge-forskning viste, at skemamarkup forbedrede brands tilstedeværelse i Googles AI Overviews med højere citeringsrater på sider med robust skemamarkup. Dette er særligt væsentligt, fordi det viser, at Artikel-Skema ikke blot er et teknisk SEO-tiltag – det påvirker direkte, om dit indhold optræder i AI-genererede svar, som millioner nu bruger som deres primære søgegrænseflade.
Artikel-Skema vs. Traditionelle SEO-signaler
Forskellen mellem Artikel-Skema og traditionelle SEO-signaler repræsenterer et grundlæggende skift i, hvordan indhold opdages. Traditionelle SEO-signaler som backlinks, søgeordoptimering og domæneautoritet fungerer via indirekte slutning – søgemaskiner observerer, at indhold er populært og troværdigt ud fra eksterne signaler. Disse signaler fungerer godt for traditionelle søgeresultater, hvor brugerne ser flere links og selv træffer valg.
Artikel-Skema giver derimod udtrykkelige, direkte signaler om, hvad dit indhold repræsenterer. I stedet for at søgemaskiner skal slutte, at dit indhold er en artikel om teknologi, siger Artikel-Skema eksplicit: “Dette er en artikel, udgivet på [dato], skrevet af [forfatter], med denne overskrift og disse billeder.” Denne direktehed er afgørende for AI-systemer, fordi LLMs behandler information anderledes end traditionelle søgemaskiner. Hvor traditionelle søgemaskiner kan udlede mening fra kontekst og eksterne signaler, gavner AI-systemer af eksplicit metadata, der fjerner tvetydighed.
Ifølge Evertunes forskning: “Schema-optimeret indhold gør det nemt for AI-systemer at forstå, udtrække og citere information korrekt.” Dette er hovedpointen: Artikel-Skema hjælper ikke blot søgemaskiner; det ændrer grundlæggende, hvordan AI-systemer interagerer med dit indhold. Når Artikel-Skema mangler eller er ufuldstændigt, må AI-systemer udlede information fra sidens indhold, hvilket kan føre til forkert tilskrivning, ukorrekt kontekst eller udeladelse fra AI-genererede svar.
Den praktiske konsekvens er, at udgivere ikke længere kun kan stole på traditionelle SEO-taktikker. En veloptimeret artikel med fremragende backlinks og søgeordsfokus kan stadig undlade at optræde i AI-genererede svar, hvis den mangler korrekt Artikel-Skema-markup. Omvendt har en artikel med omfattende Artikel-Skema-markup væsentligt større chance for at blive citeret af AI-systemer, selv med moderate traditionelle SEO-metrics.
Best Practice for Implementering af Artikel-Skema
Effektiv implementering af Artikel-Skema kræver både teknisk nøjagtighed og strategisk fuldstændighed. Den første best practice er konsistens i forfatterrepræsentation. Når du implementerer author-egenskaben, bør du bruge det samme navn og URL-format på tværs af alle artikler af samme forfatter. Denne konsistens hjælper AI-systemer og søgemaskiner med at genkende forfatteren som en særskilt entitet og opbygge autoritetssignaler over tid. Hvis din forfatter har en profilsiden på dit site, linkes der til den via url-egenskaben i author-objektet.
Den anden best practice er omfattende billedmarkup. Google anbefaler at inkludere billeder i tre billedforhold: 1x1 (kvadratisk), 4x3 (landskab) og 16x9 (bredformat), hvor hvert billede har mindst 50.000 pixels (bredde × højde). Disse billeder skal være repræsentative for artikelens indhold og ikke generiske logoer eller dekorative elementer. AI-systemer bruger disse billeder til at forstå artikelkonteksten og vise visuelle previews i genererede svar.
Den tredje best practice er nøjagtig datomarkup. Inkludér altid både datePublished (oprindelig udgivelsesdato) og dateModified (seneste opdateringsdato) i ISO 8601-format med tidszoneoplysning. AI-systemer bruger disse datoer til at forstå indholdets aktualitet og recency, hvilket er særligt vigtigt for nyheds- og tidssensitivt indhold. Hvis du foretager væsentlige ændringer i en artikel, bør dateModified afspejle det faktiske opdateringstidspunkt.
Den fjerde best practice er fuldstændig forfatterinformation. Ud over forfatterens navn bør du inkludere url-egenskaben, der peger på en forfatterprofilside eller social media-profil. Dette hjælper AI-systemer med at verificere forfatteridentitet og vurdere ekspertise. For organisationer som forfattere bør organisationens website-URL og logo inkluderes. Denne ekstra kontekst forbedrer markant, hvordan AI-systemer vurderer indholdets autoritet.
Den femte best practice er korrekt skemahierarki og forbindelser. Artikel-Skema bør ikke eksistere isoleret. Forbind dit artikel-skema til relaterede entiteter som udgiverorganisation, forfatterprofiler og relaterede artikler. Dette skaber, hvad Yoast kalder en “datagraf” – et netværk af forbindelser, der hjælper AI-systemer med at forstå, hvordan dit indhold passer ind i det bredere informationslandskab. En velopbygget datagraf øger sandsynligheden for, at AI-systemer anerkender dit indhold som autoritativt og citerer det korrekt.
Forskellige AI-platforme har forskellige præferencer for, hvordan de indhenter og citerer information, hvilket har betydning for Artikel-Skema-strategien. ChatGPT har en stærk præference for encyklopædiske, autoritative kilder, og Wikipedia står for næsten 48 % af de 10 mest citerede kilder. Det antyder, at synlighed i ChatGPT kræver, at Artikel-Skema lægger vægt på omfattende, veldokumenteret indhold med tydelige forfatteroplysninger og udgivelsesautoritet.
Google AI Overviews viser en mere balanceret tilgang og trækker på Reddit (21 % af top 10-kilder), YouTube (18,8 %) og Quora (14,3 %) sammen med traditionelle mediekilder. Det antyder, at Googles AI-system værdsætter forskellige perspektiver og fællesskabsinput. For synlighed i Google AI Overviews bør Artikel-Skema kombineres med strategier, der fremmer indholdsdistribution på tværs af flere platforme og fællesskabsengagement.
Perplexity viser den stærkeste præference for fællesskabsdrevet indhold, hvor Reddit tegner sig for 46,7 % af de 10 mest citerede kilder. Platformens tilgang antyder, at for synlighed i Perplexity bør Artikel-Skema implementeres på indhold, der besvarer specifikke spørgsmål og problemer, som fællesskaber aktivt diskuterer.
Den strategiske konsekvens er, at selvom Artikel-Skema-implementering er universel, bør den understøttende indholdsstrategi være platformspecifik. En udgiver, der sigter mod ChatGPT-synlighed, bør fokusere på autoritative, omfattende artikler med stærke forfatteroplysninger. En udgiver, der sigter mod Google AI Overviews, bør implementere Artikel-Skema sammen med en strategi for indholdsdistribution og fællesskabsengagement. En udgiver, der sigter mod Perplexity, bør fokusere på spørgsmål-svar-indhold, der adresserer specifikke fællesskabsbehov.
Validering og Overvågning af Artikel-Skema
Efter implementering af Artikel-Skema er validering afgørende for at sikre, at markuppen er korrekt og fuldstændig. Googles Rich Results Test er det primære valideringsværktøj, hvor du kan indsætte din URL eller kode og få øjeblikkelig feedback om skemaimplementeringen. Værktøjet identificerer kritiske fejl, der forhindrer rich results i at blive vist, samt ikke-kritiske problemer, der kan reducere effektiviteten.
Schema Markup Validator (validator.schema.org) giver en alternativ valideringsmetode og tjekker din markup mod den officielle Schema.org-specifikation. Dette værktøj er især nyttigt til at identificere subtile fejl eller forældede egenskaber, der måske ikke udløser advarsler i Googles værktøj.
Google Search Console tilbyder løbende overvågning af din Artikel-Skema-ydelse. “Forbedringer”-rapporten viser, hvor mange af dine sider der har gyldig Artikel-Skema-markup, og om der er fundet fejl. Denne rapport er vigtig for at identificere sider, der eventuelt har mistet skemamarkup på grund af siteopdateringer eller tekniske problemer.
Ud over validering bør udgivere overvåge faktisk AI-citeringsydelse med værktøjer som AmICited, der sporer brandmentions og citater på tværs af ChatGPT, Perplexity, Google AI Overviews og Claude. Ved at sammenholde Artikel-Skema-implementering med citeringsfrekvens kan udgivere måle det reelle ROI af deres skemainvestering og finde muligheder for forbedring.
Fremtidig Udvikling af Artikel-Skema
Artikel-Skema udvikler sig fortsat, i takt med at AI-systemer bliver mere sofistikerede, og nye standarder opstår. Model Context Protocol (MCP) og Natural Language Web (NLWeb) repræsenterer fremvoksende standarder, der bygger videre på Schema.org-grundlaget for at muliggøre bedre interoperabilitet mellem AI-systemer. Disse protokoller bruger strukturerede data som Artikel-Skema som fundament, hvilket gør korrekt implementering i dag afgørende for fremtidig kompatibilitet.
Efterhånden som AI-systemer bliver mere udbredte i indholdsopdagelse, vil Artikel-Skema sandsynligvis blive lige så essentielt som traditionel SEO-optimering. Udgivere, der implementerer omfattende, nøjagtigt Artikel-Skema i dag, vil have en betydelig fordel, efterhånden som AI-søgning vokser. Skiftet fra søgeordsbaseret søgning til AI-genererede svar udgør et fundamentalt skift i, hvordan indhold opdages, og Artikel-Skema er broen, der forbinder traditionelt webindhold til denne nye opdagelsesparadigme.
Samtidig med at E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) får stigende betydning for både traditionel søgning og AI-systemer, vil Artikel-Skemas rolle i at etablere forfatterkvalifikationer og indholdsautoritet blive endnu vigtigere. Udgivere bør forvente, at fremtidige opdateringer til Artikel-Skema vil inkludere yderligere egenskaber til at demonstrere ekspertise og opbygge tillidssignaler, som AI-systemer kan evaluere.
Vigtige Pointer for Implementering af Artikel-Skema
Artikel-Skema er afgørende for AI-synlighed: Med over 680 millioner citater sporet på store AI-platforme påvirker korrekt implementering af Artikel-Skema direkte, om dit indhold optræder i AI-genererede svar.
Implementér omfattende metadata: Inkludér overskrift, billede (flere billedforhold), datePublished, dateModified, forfatter og articleBody-egenskaber for maksimal effekt.
Brug JSON-LD-format: JSON-LD anbefales af alle større søgemaskiner og AI-platforme og giver bedre vedligeholdelse og nøjagtighed end alternative formater.
Forbind dit skema til relaterede entiteter: Skab en datagraf ved at forbinde artikler til forfattere, udgivere og relateret indhold, hvilket hjælper AI-systemer med at forstå indholdets autoritet og kontekst.
Overvåg faktisk AI-citeringsydelse: Brug værktøjer som AmICited til at spore, hvordan din Artikel-Skema-implementering påvirker dit brands synlighed på ChatGPT, Perplexity, Google AI Overviews og Claude.
Oprethold konsistens på tværs af dit site: Brug konsistente forfatternavne, udgiverinformation og URL-formater for at hjælpe AI-systemer med at genkende og opbygge autoritetssignaler over tid.
Validér og overvåg regelmæssigt: Brug Googles Rich Results Test og Search Console for at sikre, at dit Artikel-Skema forbliver gyldigt, og for at identificere eventuelle implementeringsproblemer.