
Optimering af crawl-budget for AI
Lær, hvordan du optimerer crawl-budgettet for AI-bots som GPTBot og Perplexity. Opdag strategier til at styre serverressourcer, forbedre AI-synlighed og kontrol...
9 min læsning

Crawl budget er det antal sider, som søgemaskiner tildeler ressourcer til at crawle på et website indenfor et specifikt tidsrum, bestemt af crawlkapacitetsgrænse og crawlefterspørgsel. Det repræsenterer de begrænsede ressourcer, som søgemaskiner fordeler på tværs af milliarder af websites for effektivt at opdage, crawle og indeksere indhold.
Crawl budget er det antal sider, som søgemaskiner tildeler ressourcer til at crawle på et website indenfor et specifikt tidsrum, bestemt af crawlkapacitetsgrænse og crawlefterspørgsel. Det repræsenterer de begrænsede ressourcer, som søgemaskiner fordeler på tværs af milliarder af websites for effektivt at opdage, crawle og indeksere indhold.
Crawl budget er det antal sider, som søgemaskiner tildeler ressourcer til at crawle på et website indenfor et specifikt tidsrum, typisk målt dagligt eller månedligt. Det repræsenterer en begrænset tildeling af computerressourcer, som søgemaskiner som Google, Bing og nye AI-crawlere fordeler på tværs af milliarder af websites på internettet. Konceptet opstod ud fra den grundlæggende realitet, at søgemaskiner ikke kan crawle alle sider på alle websites samtidigt—de må prioritere og fordele deres begrænsede infrastruktur strategisk. Crawl budget har direkte indflydelse på, om dit websites sider bliver opdaget, indekseret og til sidst rangeret i søgeresultater. For store websites med tusinder eller millioner af sider kan effektiv håndtering af crawl budget være forskellen på omfattende indeksering og at vigtige sider forbliver uopdagede i uger eller måneder.
Konceptet crawl budget blev formaliseret inden for søgemaskineoptimering omkring 2009, da Google begyndte at offentliggøre vejledninger om, hvordan deres crawlingsystemer fungerer. I starten fokuserede de fleste SEO-professionelle på traditionelle rangeringsfaktorer som søgeord og backlinks og ignorerede i høj grad den tekniske infrastruktur, der gjorde indeksering mulig. Men efterhånden som websites voksede eksponentielt i størrelse og kompleksitet, især med fremkomsten af e-handelsplatforme og indholdstunge sites, stod søgemaskinerne over for hidtil usete udfordringer med effektivt at crawle og indeksere alt tilgængeligt indhold. Google anerkendte denne begrænsning og introducerede begrebet crawl budget for at hjælpe webmastere med at forstå, hvorfor ikke alle deres sider blev indekseret, selvom de teknisk set var tilgængelige. Ifølge Google Search Central overstiger nettet Googles evne til at udforske og indeksere hver tilgængelig URL, hvilket gør crawl budget styring essentiel for websites i stor skala. I dag, hvor AI-crawlertrafik er steget med 96% mellem maj 2024 og maj 2025, og GPTBots andel sprang fra 5% til 30%, er crawl budget blevet endnu mere kritisk, da flere crawlingsystemer konkurrerer om serverressourcer. Denne udvikling afspejler det bredere skift mod generative engine optimization (GEO) og behovet for, at brands sikrer synlighed på både traditionelle søge- og AI-drevne platforme.
Crawl budget bestemmes af to primære komponenter: crawlkapacitetsgrænse og crawlefterspørgsel. Crawlkapacitetsgrænsen repræsenterer det maksimale antal samtidige forbindelser og tidsforsinkelsen mellem hentninger, som en søgemaskine kan bruge uden at overbelaste et websites servere. Denne grænse er dynamisk og justeres baseret på flere faktorer. Hvis et website reagerer hurtigt på crawler-forespørgsler og returnerer minimale serverfejl, stiger kapacitetsgrænsen, hvilket tillader søgemaskiner at bruge flere parallelle forbindelser og crawle flere sider. Omvendt, hvis et site oplever langsomme svartider, timeouts eller hyppige 5xx serverfejl, falder kapacitetsgrænsen som en beskyttelsesforanstaltning for at undgå overbelastning af serveren. Crawlefterspørgsel, den anden komponent, afspejler, hvor ofte søgemaskiner ønsker at genbesøge og crawle indhold baseret på dets opfattede værdi og opdateringsfrekvens. Populære sider med mange backlinks og høj søgetrafik får højere crawlefterspørgsel og bliver crawlet oftere. Nyhedsartikler og ofte opdateret indhold får højere crawlefterspørgsel end statiske sider som brugervilkår. Kombinationen af disse to faktorer—hvad serveren kan håndtere, og hvad søgemaskiner vil crawle—bestemmer dit effektive crawl budget. Denne balancerede tilgang sikrer, at søgemaskiner kan opdage friskt indhold, mens serverkapacitetsbegrænsninger respekteres.
| Begreb | Definition | Måling | Indflydelse på indeksering | Primær kontrol |
|---|---|---|---|---|
| Crawl Budget | Samlet antal sider, søgemaskiner tildeler til crawl indenfor et tidsrum | Sider pr. dag/måned | Direkte—bestemmer hvilke sider der bliver opdaget | Indirekte (autoritet, hastighed, struktur) |
| Crawl Rate | Faktisk antal sider crawlet pr. dag | Sider pr. dag | Informativ—viser nuværende crawlingaktivitet | Serverrespons, sidehastighed |
| Crawlkapacitetsgrænse | Maksimalt samtidige forbindelser, serveren kan håndtere | Forbindelser pr. sekund | Begrænser crawl budgets loft | Serverinfrastruktur, hostingkvalitet |
| Crawlefterspørgsel | Hvor ofte søgemaskiner ønsker at gen-crawle indhold | Gen-crawlingfrekvens | Bestemmer prioritet indenfor budgettet | Indholdsaktualitet, popularitet, autoritet |
| Indeksdækning | Procentdel af crawlede sider, der faktisk er indekseret | Indekserede sider / crawlede sider | Resultatmetrik—viser succes med indeksering | Indholdskvalitet, kanonisering, noindex-tags |
| Robots.txt | Fil der styrer, hvilke URL’er søgemaskiner kan crawle | Blokerede URL-mønstre | Beskyttende—forhindrer spild af budget på uønskede sider | Direkte—du styrer via robots.txt-regler |
Crawl budget fungerer via et sofistikeret system af algoritmer og ressourceallokering, som søgemaskiner løbende justerer. Når Googlebot (Googles primære crawler) besøger dit website, evaluerer den flere signaler for at afgøre, hvor aggressivt der skal crawles. Crawleren vurderer først din servers sundhed ved at overvåge svartider og fejlprocenter. Hvis din server konsekvent svarer inden for 200-500 millisekunder og returnerer minimale fejl, tolker Google dette som en sund, velholdt server, der kan håndtere øget crawltrafik. Crawleren øger derefter crawlkapacitetsgrænsen og kan potentielt bruge flere parallelle forbindelser til at hente sider samtidigt. Dette er grunden til, at sidehastighedsoptimering er så kritisk—hurtigere sider gør det muligt for søgemaskiner at crawle flere URL’er på samme tid. Omvendt, hvis sider tager 3-5 sekunder at indlæse eller ofte timeouter, reducerer Google kapacitetsgrænsen for at beskytte din server mod overbelastning. Ud over serverens sundhed analyserer søgemaskiner dit sites URL-inventar for at bestemme crawlefterspørgsel. De undersøger, hvilke sider der har interne links, hvor mange eksterne backlinks hver side får, og hvor ofte indholdet opdateres. Sider, der er linket fra din forside, får højere prioritet end sider, der ligger dybt i sidens hierarki. Sider med nylige opdateringer og høj trafik får hyppigere gen-crawling. Søgemaskiner bruger også sitemaps som vejledning for at forstå dit sites struktur og indholdsprioriteter, selvom sitemaps er forslag og ikke absolutte krav. Algoritmen balancerer løbende disse faktorer og justerer dynamisk dit crawl budget baseret på realtidspræstationsmålinger og vurderinger af indholdets værdi.
Den praktiske betydning af crawl budget for SEO-ydeevne kan ikke overvurderes, især for store websites og hurtigt voksende platforme. Når et websites crawl budget er opbrugt, før alle vigtige sider er opdaget, kan disse uopdagede sider ikke indekseres og derfor ikke rangere i søgeresultater. Dette har direkte indflydelse på indtægter—sider, der ikke indekseres, genererer ingen organisk trafik. For e-handelssider med hundredtusindvis af produktsider betyder ineffektiv håndtering af crawl budget, at nogle produkter aldrig vises i søgeresultaterne, hvilket direkte reducerer salget. For nyhedsudgivere betyder langsom crawl budget-udnyttelse, at breaking news historier tager dage om at dukke op i søgeresultater i stedet for timer, hvilket mindsker deres konkurrencefordel. Forskning fra Backlinko og Conductor viser, at sites med optimerede crawl budgets oplever markant hurtigere indeksering af nyt og opdateret indhold. En dokumenteret case viste, at et site, der forbedrede sideindlæsningstiden med 50%, oplevede en firedobling af daglig crawl volumen—fra 150.000 til 600.000 URL’er om dagen. Denne dramatiske stigning betød, at nyt indhold blev opdaget og indekseret inden for timer i stedet for uger. For AI-synlighed bliver crawl budget endnu mere kritisk. Da AI-crawlere som GPTBot, Claude Bot og Perplexity Bot konkurrerer om serverressourcer sammen med traditionelle søgemaskinecrawlere, kan websites med dårlig crawl budget optimering opleve, at deres indhold ikke bliver tilgængeligt ofte nok for AI-systemer til at blive citeret i AI-genererede svar. Dette påvirker direkte din synlighed i AI Overviews, ChatGPT-svar og andre generative søgeplatforme, som AmICited overvåger. Organisationer, der ikke optimerer crawl budget, oplever ofte kaskadeagtige SEO-problemer: nye sider tager uger at blive indekseret, indholdsopdateringer afspejles ikke hurtigt i søgeresultater, og konkurrenter med bedre optimerede sites fanger søgetrafik, som burde tilhøre dem.
Forståelse af, hvad der spilder crawl budget, er afgørende for optimering. Duplikeret indhold er en af de største kilder til spildt crawl budget. Når søgemaskiner støder på flere versioner af det samme indhold—hvad enten det er via URL-parametre, session-id’er eller flere domænevarianter—skal de behandle hver version separat, hvilket forbruger crawl budget uden at tilføre værdi til deres indeks. En enkelt produktside på en e-handelsside kan generere dusinvis af duplikerede URL’er gennem forskellige filterkombinationer (farve, størrelse, prisklasse), som hver især forbruger crawl budget. Redirect-kæder spilder crawl budget ved at tvinge søgemaskiner til at følge flere hop, før de når den endelige destinationsside. En redirect-kæde på fem eller flere hop kan forbruge betydelige crawlressourcer, og søgemaskinerne kan helt opgive at følge kæden. Døde links og soft 404-fejl (sider der returnerer en 200 statuskode, men ikke indeholder indhold) tvinger søgemaskiner til at crawle sider, der ikke giver værdi. Indhold af lav kvalitet—fx tynde sider med minimal tekst, auto-genereret indhold eller sider uden unikt indhold—forbruger crawl budget, som kunne bruges på indhold af høj værdi. Facetteret navigation og session-id’er i URL’er skaber nærmest uendelige URL-rum, der kan fange crawlere i loops. Ikke-indekserbare sider inkluderet i XML-sitemaps vildleder søgemaskiner om, hvilke sider der fortjener crawl-prioritet. Langsomme sideloadtider og server timeouts reducerer crawlkapaciteten ved at signalere til søgemaskinerne, at din server ikke kan håndtere aggressiv crawling. Dårlig intern linkstruktur begraver vigtige sider dybt i sitehierarkiet, hvilket gør dem sværere for crawlere at opdage og prioritere. Hver af disse problemer reducerer crawl effektivitet; samlet set kan de føre til, at søgemaskiner kun crawler en brøkdel af dit vigtige indhold.
Optimering af crawl budget kræver en flerstrenget tilgang, der adresserer både teknisk infrastruktur og indholdsstrategi. Forbedr sidehastighed ved at optimere billeder, minimere CSS og JavaScript, udnytte browsercaching og bruge content delivery networks (CDN’er). Hurtigere sider gør det muligt for søgemaskiner at crawle flere URL’er på samme tid. Konsolider duplikeret indhold ved at implementere korrekte redirects for domænevarianter (HTTP/HTTPS, www/ikke-www), bruge canonical tags til at angive foretrukne versioner og blokere interne søgeresultatsider fra crawling via robots.txt. Håndter URL-parametre ved at bruge robots.txt til at blokere parametertilpassede URL’er, der skaber duplikeret indhold, eller ved at implementere URL parameterhåndtering i Google Search Console og Bing Webmaster Tools. Ret døde links og redirect-kæder ved at gennemgå dit site for døde links og sikre, at redirects peger direkte på slutdestinationen i stedet for at skabe kæder. Ryd op i XML-sitemaps ved at fjerne ikke-indekserbare sider, udløbet indhold og sider, der returnerer fejlstatuskoder. Inkludér kun sider, du ønsker indekseret, og som har unik værdi. Forbedr intern linkstruktur ved at sikre, at vigtige sider har flere interne links, der peger på dem, og skab et fladt hierarki, der distribuerer linkautoritet gennem dit site. Blokér sider af lav værdi med robots.txt for at forhindre crawlere i at spilde budget på admin-sider, duplikerede søgeresultater, indkøbskurvsider og andet ikke-indekserbart indhold. Overvåg crawlstatistik regelmæssigt via Google Search Consoles Crawl Stats-rapport for at følge dagligt crawlvolumen, identificere serverfejl og spotte tendenser i crawlingsadfærd. Øg serverkapaciteten, hvis du konsekvent ser crawl rates ramme din servers kapacitetsgrænse—dette signalerer, at søgemaskiner vil crawle mere, men din infrastruktur kan ikke følge med. Brug strukturerede data til at hjælpe søgemaskiner med bedre at forstå dit indhold, hvilket potentielt øger crawlefterspørgslen for sider af høj kvalitet. Vedligehold opdaterede sitemaps med <lastmod>-tagget for at signalere, hvornår indhold er opdateret, så søgemaskiner kan prioritere gen-crawling af frisk indhold.
Forskellige søgemaskiner og AI-crawlere har forskellige crawl budgets og adfærd. Google er stadig den mest gennemsigtige omkring crawl budget og tilbyder detaljerede Crawl Stats-rapporter i Google Search Console med dagligt crawl volumen, serverrespons og fejlprocenter. Bing giver lignende data via Bing Webmaster Tools, dog typisk med mindre detaljer. AI-crawlere som GPTBot (OpenAI), Claude Bot (Anthropic) og Perplexity Bot opererer med deres egne crawl budgets og prioriteter, ofte med fokus på autoritativt og kvalitetsindhold. Disse AI-crawlere har vist eksplosiv vækst—GPTBots andel af crawlertrafikken steg fra 5% til 30% på bare ét år. For organisationer, der bruger AmICited til at overvåge AI-synlighed, er det kritisk at forstå, at AI-crawlere har separate crawl budgets fra traditionelle søgemaskiner. En side kan være velindekseret af Google, men sjældent crawlet af AI-systemer, hvis den mangler tilstrækkelig autoritet eller emnemæssig relevans. Mobil-første indeksering betyder, at Google primært crawler og indekserer mobilversioner af sider, så crawl budget optimering skal tage højde for mobilsite-præstation. Hvis du har separate mobil- og desktop-sites, deler de crawl budget på samme host, så mobilsidens hastighed påvirker direkte indekseringen af desktop-sider. JavaScript-tunge sites kræver yderligere crawl-ressourcer, fordi søgemaskiner skal gengive JavaScript for at forstå indholdet, hvilket forbruger mere crawl budget pr. side. Sites der bruger dynamisk rendering eller server-side rendering kan reducere crawl budget-forbrug ved at gøre indholdet tilgængeligt med det samme uden at kræve rendering. Internationale sites med hreflang-tags og flere sprogversioner forbruger mere crawl budget, da søgemaskiner skal crawle varianter for hvert sprog og region. Korrekt implementering af hreflang hjælper søgemaskiner med at forstå, hvilken version de skal crawle og indeksere for hvert marked, hvilket forbedrer crawl effektiviteten.
Fremtiden for crawl budget omformes af den eksplosive vækst i AI-søgning og generative søgemaskiner. Da AI-crawlertrafik steg med 96% mellem maj 2024 og maj 2025, med GPTBots andel springende fra 5% til 30%, står websites nu over for konkurrence om crawl ressourcer fra flere systemer samtidigt. Traditionelle søgemaskiner, AI-crawlere og nye generative engine optimization (GEO) platforme konkurrerer alle om serverbåndbredde og crawlkapacitet. Denne tendens antyder, at crawl budget optimering kun bliver vigtigere fremover. Organisationer skal overvåge ikke blot Googles crawl mønstre, men også crawl mønstre fra OpenAI’s GPTBot, Anthropics Claude Bot, Perplexitys crawler og andre AI-systemer. Platforme som AmICited, der sporer brandnævnelser på tværs af AI-platforme, vil blive essentielle værktøjer til at forstå, om dit indhold opdages og citeres af AI-systemer. Definitionen af crawl budget kan udvikle sig til ikke kun at omfatte traditionel søgemaskinecrawling, men også crawling fra AI-systemer og LLM-træningssystemer. Nogle eksperter forudser, at websites skal implementere separate optimeringsstrategier for traditionel søgning versus AI-søgning, potentielt allokere forskelligt indhold og ressourcer til hvert system. Fremkomsten af robots.txt-udvidelser og llms.txt-filer (som tillader websites at specificere hvilket indhold AI-systemer kan tilgå) antyder, at crawl budget-styring bliver mere granulær og intentionel. Når søgemaskiner fortsætter med at prioritere E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness)-signaler, vil crawl budget-allokering i stigende grad favorisere autoritativt, kvalitetsindhold, hvilket kan udvide kløften mellem veloptimerede sites og dårligt optimerede konkurrenter. Integration af crawl budget-begreber i GEO-strategier betyder, at fremsynede organisationer ikke kun vil optimere for traditionel indeksering, men for synlighed på tværs af hele spektret af søge- og AI-platforme, som deres publikum bruger.
Crawl rate refererer til antallet af sider, en søgemaskine crawler pr. dag, mens crawl budget er det samlede antal sider, en søgemaskine vil crawle inden for et specifikt tidsrum. Crawl rate er en målemetrik, mens crawl budget er fordelingen af ressourcer. For eksempel, hvis Google crawler 100 sider om dagen på dit site, er det crawl rate, men dit månedlige crawl budget kan være 3.000 sider. Forståelse af begge metrikker hjælper dig med at overvåge, om søgemaskiner bruger deres tildelte ressourcer effektivt på dit site.
Da AI-crawlertrafik steg med 96% mellem maj 2024 og maj 2025, med GPTBots andel stigende fra 5% til 30%, er crawl budget blevet stadigt mere kritisk for AI-synlighed. Platforme som AmICited overvåger, hvor ofte dit domæne optræder i AI-genererede svar, hvilket delvist afhænger af, hvor ofte AI-crawlere kan få adgang til og indeksere dit indhold. Et veloptimeret crawl budget sikrer, at søgemaskiner og AI-systemer hurtigt kan opdage dit indhold, hvilket øger dine chancer for at blive citeret i AI-svar og opretholde synlighed på både traditionelle og generative søgeplatforme.
Du kan ikke direkte øge crawl budget via en indstilling eller anmodning til Google. Du kan dog indirekte øge det ved at forbedre dit websites autoritet gennem at opnå backlinks, øge sidens hastighed og reducere serverfejl. Googles tidligere leder af webspam, Matt Cutts, har bekræftet, at crawl budget er nogenlunde proportionalt med dit websites PageRank (autoritet). Derudover signalerer optimering af din sitestruktur, løsning af duplikeret indhold og fjernelse af crawl-ineffektivitet til søgemaskinerne, at dit site fortjener flere crawl-ressourcer.
Store websites med 10.000+ sider, e-handelssider med hundredtusindvis af produktsider, nyhedsudgivere der tilføjer dusinvis af artikler dagligt, og hurtigt voksende sites bør prioritere crawl budget optimering. Små websites under 10.000 sider behøver typisk ikke bekymre sig om crawl budget begrænsninger. Men hvis du oplever, at vigtige sider tager uger om at blive indekseret eller ser lav indeksdækning i forhold til det samlede antal sider, bliver crawl budget optimering kritisk uanset størrelse.
Crawl budget bestemmes af skæringspunktet mellem crawlkapacitetsgrænse (hvor meget crawl din server kan håndtere) og crawlefterspørgsel (hvor ofte søgemaskiner ønsker at crawle dit indhold). Hvis din server reagerer hurtigt og ikke har fejl, øges kapacitetsgrænsen, hvilket tillader flere samtidige forbindelser. Crawlefterspørgslen øges for populære sider med mange backlinks og ofte opdateret indhold. Søgemaskiner balancerer disse to faktorer for at bestemme dit effektive crawl budget og sikrer, at de ikke overbelaster dine servere, mens de stadig opdager vigtigt indhold.
Sidehastighed er en af de mest indflydelsesrige faktorer i crawl budget optimering. Hurtigere sider gør det muligt for Googlebot at besøge og behandle flere URL'er inden for samme tidsrum. Forskning viser, at når sites forbedrer sideindlæsning med 50%, kan crawl rates stige markant—nogle sites har set crawlvolumen stige fra 150.000 til 600.000 URL'er om dagen efter hastighedsoptimering. Langsomme sider forbruger mere af dit crawl budget og efterlader mindre tid for søgemaskiner til at opdage andet vigtigt indhold på dit site.
Duplikeret indhold tvinger søgemaskiner til at behandle flere versioner af den samme information uden at tilføje værdi til deres indeks. Dette spilder crawl budget, som kunne bruges på unikke, værdifulde sider. Almindelige kilder til duplikeret indhold inkluderer interne søgeresultatsider, billedvedhæftningssider, flere domænevarianter (HTTP/HTTPS, www/ikke-www) og facetteret navigation. Ved at konsolidere duplikeret indhold via redirects, canonical tags og robots.txt regler frigør du crawl budget, så søgemaskiner kan opdage og indeksere flere unikke, høj-kvalitets sider på dit site.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær, hvordan du optimerer crawl-budgettet for AI-bots som GPTBot og Perplexity. Opdag strategier til at styre serverressourcer, forbedre AI-synlighed og kontrol...

Lær hvad crawl budget for AI betyder, hvordan det adskiller sig fra traditionelle søgemaskiners crawl budgetter, og hvorfor det er vigtigt for din brands synlig...
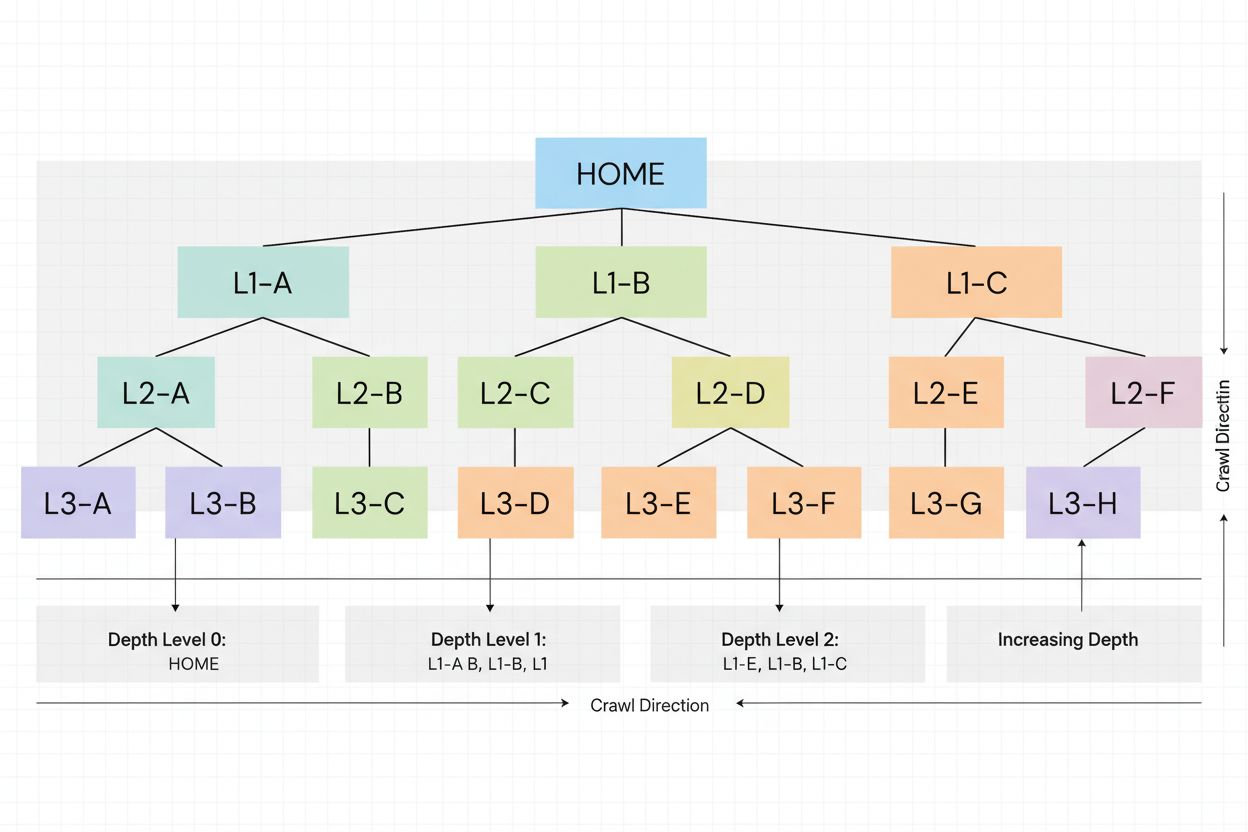
Crawl-dybde er, hvor dybt søgemaskinens bots navigerer i din hjemmesides struktur. Lær hvorfor det er vigtigt for SEO, hvordan det påvirker indeksering, og stra...