
AI Crawler Management
Lær, hvordan du administrerer AI-crawleres adgang til dit webstedsindhold. Forstå forskellen mellem trænings- og søgecrawlere, implementer robots.txt-kontroller...
6 min læsning
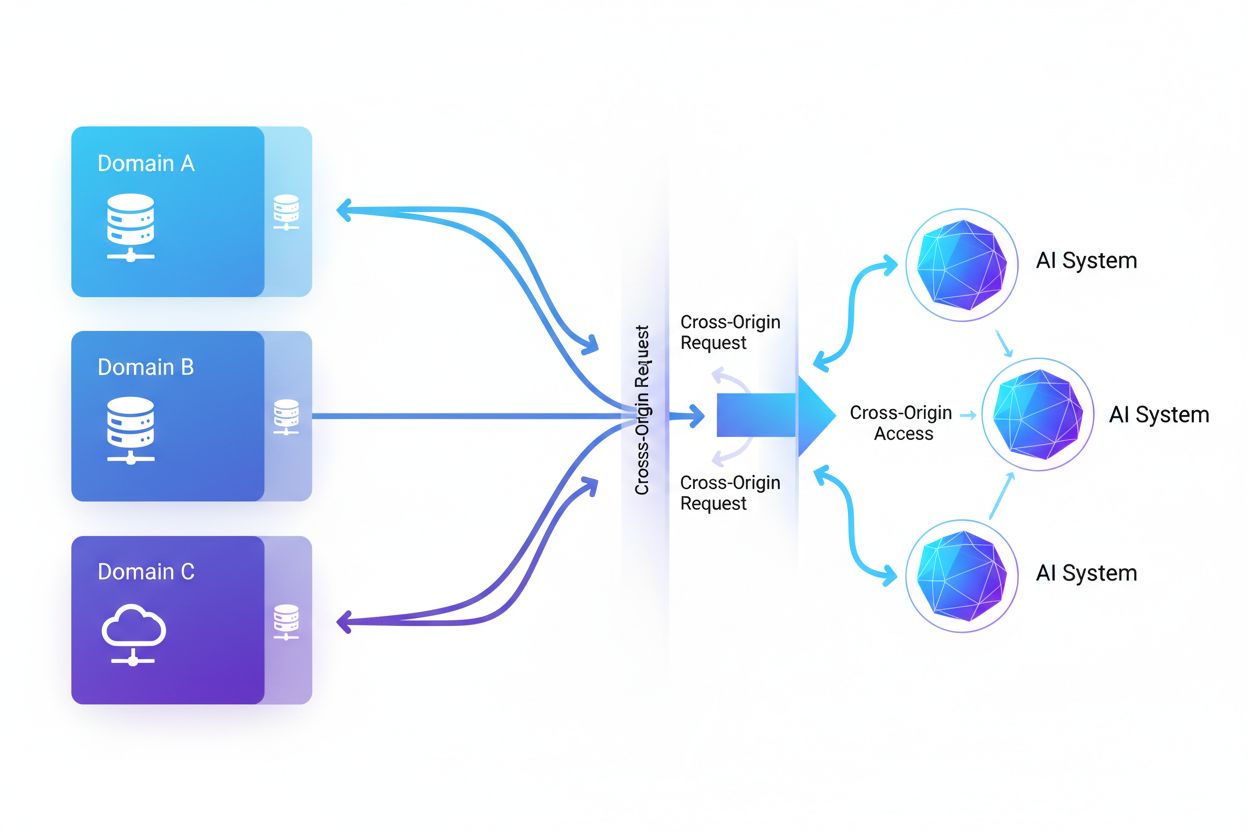
Cross-Origin AI-adgang henviser til kunstig intelligens-systemers og webcrawlers evne til at anmode om og hente indhold fra domæner, der adskiller sig fra deres oprindelse, styret af sikkerhedsmekanismer som CORS. Det omfatter, hvordan AI-virksomheder opskalerer dataindsamling til træning af store sprogmodeller, mens de navigerer i cross-origin-begrænsninger. Forståelse af dette begreb er afgørende for indholdsskabere og webstedsejere for at beskytte intellektuel ejendom og bevare kontrollen over, hvordan deres indhold bruges af AI-systemer. Indsigt i cross-origin AI-aktivitet hjælper med at skelne mellem legitim AI-adgang og uautoriseret scraping.
Cross-Origin AI-adgang henviser til kunstig intelligens-systemers og webcrawlers evne til at anmode om og hente indhold fra domæner, der adskiller sig fra deres oprindelse, styret af sikkerhedsmekanismer som CORS. Det omfatter, hvordan AI-virksomheder opskalerer dataindsamling til træning af store sprogmodeller, mens de navigerer i cross-origin-begrænsninger. Forståelse af dette begreb er afgørende for indholdsskabere og webstedsejere for at beskytte intellektuel ejendom og bevare kontrollen over, hvordan deres indhold bruges af AI-systemer. Indsigt i cross-origin AI-aktivitet hjælper med at skelne mellem legitim AI-adgang og uautoriseret scraping.
Cross-Origin AI-adgang henviser til kunstig intelligens-systemers og webcrawlers evne til at anmode om og hente indhold fra domæner, der adskiller sig fra deres oprindelse, styret af sikkerhedsmekanismer som Cross-Origin Resource Sharing (CORS). Efterhånden som AI-virksomheder opskalerer deres dataindsamling til at træne store sprogmodeller og andre AI-systemer, er forståelsen af, hvordan disse systemer navigerer cross-origin-begrænsninger, blevet afgørende for indholdsskabere og webstedsejere. Udfordringen består i at skelne mellem legitim AI-adgang til søgeindeksering og uautoriseret scraping til modeltræning, hvilket gør indsigt i cross-origin AI-aktivitet essentiel for at beskytte intellektuel ejendom og bevare kontrollen over, hvordan indhold bruges.
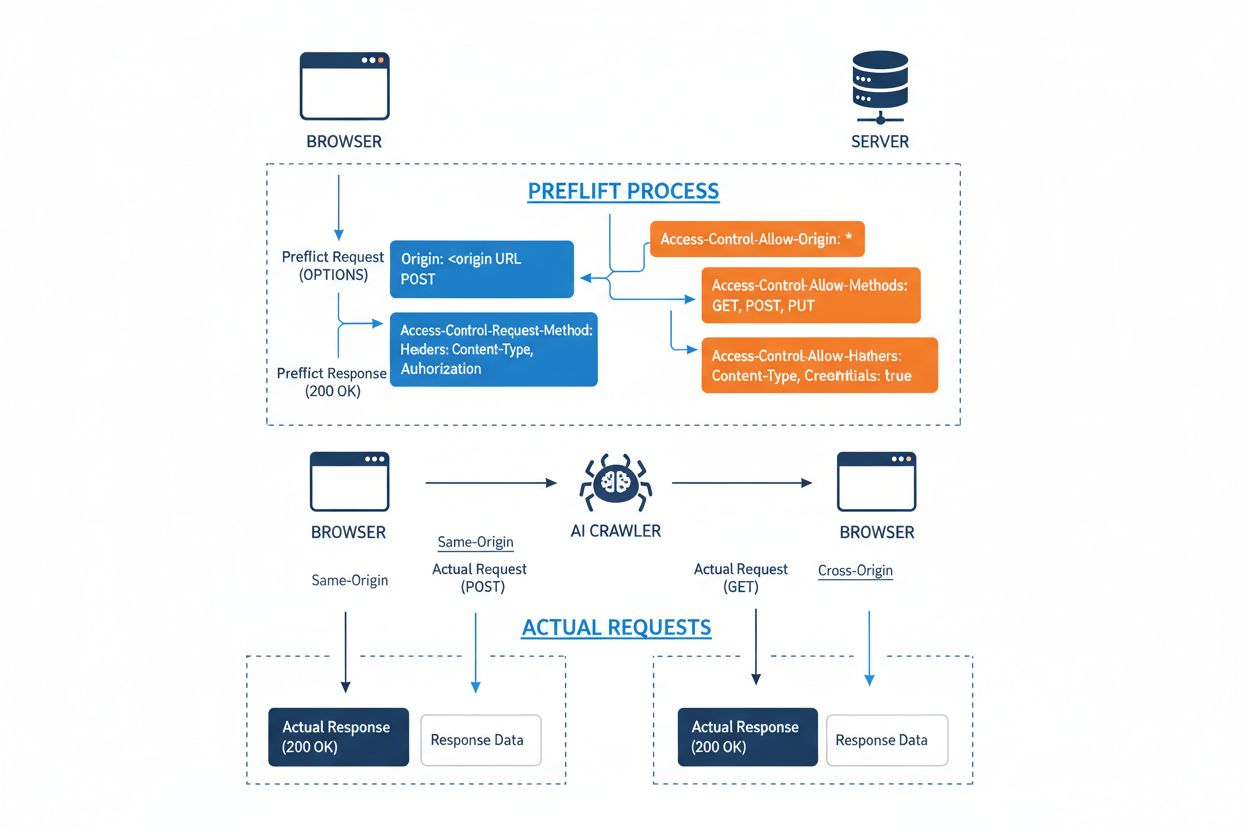
Cross-Origin Resource Sharing (CORS) er en HTTP-header-baseret sikkerhedsmekanisme, der gør det muligt for servere at specificere, hvilke oprindelser (domæner, skemaer eller porte) der kan tilgå deres ressourcer. Når en AI-crawler eller en klient forsøger at tilgå en ressource fra en anden oprindelse, indleder browseren eller klienten en preflight-anmodning med OPTIONS HTTP-metoden for at kontrollere, om serveren tillader den faktiske anmodning. Serveren svarer med specifikke CORS-headere, der dikterer adgangstilladelser, herunder hvilke oprindelser der er tilladt, hvilke HTTP-metoder der er tilladt, hvilke headere der kan inkluderes, og om legitimationsoplysninger som cookies eller autentificeringstokens kan sendes med anmodningen.
| CORS Header | Formål |
|---|---|
Access-Control-Allow-Origin | Angiver, hvilke oprindelser der kan tilgå ressourcen (* for alle, eller specifikke domæner) |
Access-Control-Allow-Methods | Oplister tilladte HTTP-metoder (GET, POST, PUT, DELETE, mv.) |
Access-Control-Allow-Headers | Definerer, hvilke anmodningsheadere der er tilladt (Authorization, Content-Type, mv.) |
Access-Control-Allow-Credentials | Bestemmer, om legitimationsoplysninger (cookies, auth tokens) kan inkluderes i anmodninger |
Access-Control-Max-Age | Angiver, hvor længe preflight-svar kan caches (i sekunder) |
Access-Control-Expose-Headers | Oplister svarheadere, som klienter kan tilgå |
AI-crawlers interagerer med CORS ved at respektere disse headere, når de er korrekt konfigureret, men mange avancerede bots forsøger at omgå disse begrænsninger ved at forfalske user agents eller bruge proxynetværk. CORS’ effektivitet som forsvar mod uautoriseret AI-adgang afhænger fuldstændigt af korrekt serverkonfiguration og crawlerens vilje til at respektere begrænsningerne—en afgørende forskel, der er blevet stadig vigtigere, efterhånden som AI-virksomheder konkurrerer om træningsdata.
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Landskabet for AI-crawlers, der tilgår nettet, er udvidet dramatisk, med flere store aktører, der dominerer cross-origin-adgangsmønstre. Ifølge Cloudflares analyse af netværkstrafik er de mest udbredte AI-crawlers:
Disse crawlers genererer milliarder af anmodninger månedligt, med nogle som Bytespider og GPTBot, der tilgår størstedelen af internettets offentligt tilgængelige indhold. Det store omfang og den aggressive karakter af denne aktivitet har fået store platforme som Reddit, Twitter/X, Stack Overflow og adskillige nyhedsorganisationer til at implementere blokeringstiltag.
Fejlagtigt konfigurerede CORS-politikker skaber betydelige sikkerhedssårbarheder, som AI-crawlers kan udnytte til at tilgå følsomme data uden tilladelse. Når servere sætter Access-Control-Allow-Origin: * uden korrekt validering, tillader de utilsigtet enhver oprindelse—including ondsindede AI-scrapers—at tilgå ressourcer, der burde være begrænsede. En særligt farlig konfiguration opstår, når Access-Control-Allow-Credentials: true kombineres med wildcard-origin-indstillinger, hvilket gør det muligt for angribere at stjæle autentificerede brugerdata ved at foretage cross-origin-anmodninger, der inkluderer sessionscookies eller autentificeringstokens.
Almindelige CORS-fejlkonfigurationer omfatter dynamisk spejling af Origin-headeren direkte i Access-Control-Allow-Origin-svaret uden validering, hvilket reelt tillader enhver oprindelse at tilgå ressourcen. Overdrevent tilladende allow-lister, der ikke validerer domænegrænser korrekt, kan udnyttes via subdomæneangreb eller præfiksmanipulation. Mange organisationer undlader desuden at implementere korrekt validering af Origin-headeren, hvilket gør dem sårbare over for forfalskede anmodninger. Konsekvenserne af disse sårbarheder rækker ud over datatyveri til også at omfatte uautoriseret træning af AI-modeller på proprietært indhold, konkurrenceefterretning og overtrædelse af immaterielle rettigheder—risici, som værktøjer som AmICited.com hjælper organisationer med at overvåge og kvantificere.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Identifikation af AI-crawlers, der forsøger cross-origin-adgang, kræver analyse af flere signaler end blot user agent-strenge, da disse nemt kan forfalskes. User agent-analyse er stadig en første detektionsmetode, da mange AI-crawlers identificerer sig gennem specifikke user agent-strenge som “GPTBot/1.0” eller “ClaudeBot/1.0”, men avancerede crawlers maskerer bevidst deres identitet ved at udgive sig for legitime browsere. Adfærdsfingeraftryk analyserer, hvordan anmodninger foretages—gennemgår mønstre som anmodningsinterval, rækkefølgen af tilgåede sider, tilstedeværelsen eller fraværet af JavaScript-eksekvering og interaktionsmønstre, der grundlæggende adskiller sig fra menneskelig browsingadfærd.
Netværkssignalanalyse giver dybere detektionsmuligheder ved at undersøge TLS-handshake-signaturer, IP-ry, DNS-opløsningsmønstre og forbindelseskarakteristika, der afslører botaktivitet selv ved forfalskede user agents. Enheds-fingeraftryk samler dusinvis af signaler, herunder browserversion, skærmopløsning, installerede skrifttyper, operativsystemdetaljer og JA3 TLS-fingeraftryk for at skabe unikke identifikatorer for hver anmodningskilde. Avancerede detektionssystemer kan identificere, når flere sessioner stammer fra samme enhed eller script og fange distribuerede scrapingforsøg, der forsøger at undvige ratebegrænsning ved at sprede anmodninger over mange IP-adresser. Organisationer kan udnytte disse detektionsmetoder via sikkerhedsplatforme og overvågningstjenester for at få indsigt i, hvilke AI-systemer der tilgår deres indhold, og hvordan de forsøger at omgå begrænsninger.
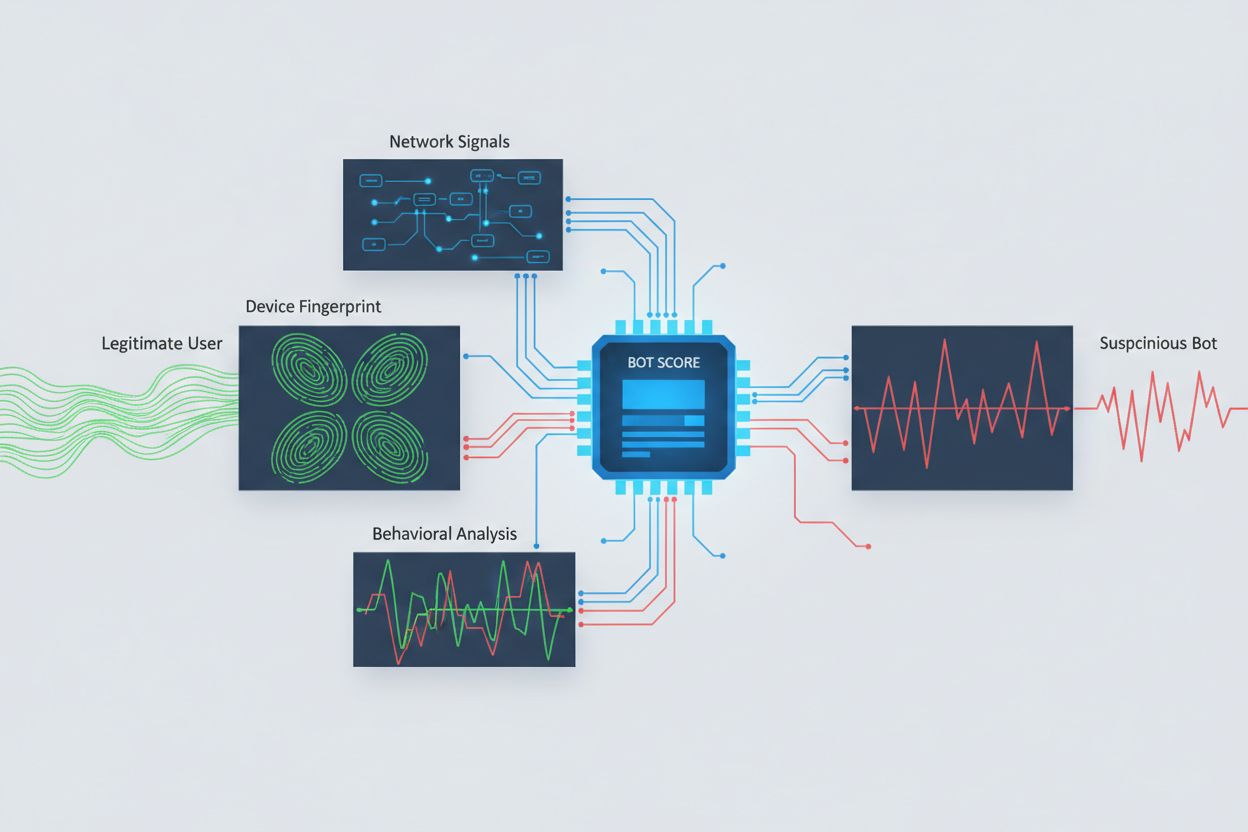
Organisationer anvender flere komplementære strategier til at blokere eller kontrollere cross-origin AI-adgang, idet de erkender, at ingen enkelt metode giver fuldstændig beskyttelse:
User-agent: GPTBot efterfulgt af Disallow: /) giver en høflig, men frivillig mekanisme; effektiv for velopdragne crawlers, men let ignoreret af beslutsomme scrapersDen mest effektive beskyttelse kombinerer flere lag, da beslutsomme angribere vil udnytte svagheder ved enhver enkeltmetode. Organisationer bør løbende overvåge, hvilke blokeringsteknikker der fungerer, og tilpasse sig, når crawlers udvikler deres undvigelsesteknikker.
Effektiv håndtering af cross-origin AI-adgang kræver en omfattende, lagdelt tilgang, der balancerer sikkerhed og operationelle behov. Organisationer bør implementere en trinvis strategi, der starter med grundlæggende kontrol som robots.txt og user agent-filtrering og derefter gradvist tilføjer mere avancerede detektions- og blokeringsteknikker baseret på observerede trusler. Kontinuerlig overvågning er essentiel—opfølgning på, hvilke AI-systemer der tilgår dit indhold, hvor ofte de anmoder, og om de respekterer dine begrænsninger, giver den nødvendige indsigt til at træffe informerede beslutninger om adgangspolitikker.
Dokumentation af adgangspolitikker bør være klar og håndhævelig med eksplicitte servicevilkår, der forbyder uautoriseret scraping og fastlægger konsekvenser ved overtrædelse. Regelmæssige audits af CORS-konfigurationer hjælper med at identificere fejl, inden de udnyttes, mens et opdateret inventar over kendte AI-crawler-user agents og IP-ranges muliggør hurtig respons på nye trusler. Organisationer bør også overveje de forretningsmæssige konsekvenser af at blokere AI-adgang—nogle AI-crawlers tilfører værdi gennem søgeindeksering eller legitime partnerskaber, så politikker bør skelne mellem gavnlig og skadelig adgang. Implementering af disse praksisser kræver koordinering mellem sikkerheds-, juridiske og forretningsmæssige teams for at sikre, at politikkerne stemmer overens med organisationens mål og lovgivningsmæssige krav.
Specialiserede værktøjer og platforme er opstået for at hjælpe organisationer med at overvåge og kontrollere cross-origin AI-adgang med større præcision og indsigt. AmICited.com leverer omfattende overvågning af, hvordan AI-systemer refererer til og tilgår dit brand på tværs af GPT’er, Perplexity, Google AI Overviews og andre AI-platforme, og giver indsigt i, hvilke AI-modeller der bruger dit indhold, og hvor ofte dit brand optræder i AI-genererede svar. Denne overvågningskapacitet udvides til at spore cross-origin-adgangsmønstre og forstå det bredere økosystem af AI-systemer, der interagerer med dine digitale aktiver.
Ud over overvågning tilbyder Cloudflare bot management-funktioner med et-klik-blokering af kendte AI-crawlers og bruger maskinlæringsmodeller, der er trænet på netværksdækkende trafikmønstre, til at identificere bots selv ved forfalskede user agents. AWS WAF (Web Application Firewall) tilbyder tilpassede regler til blokering af specifikke user agents og IP-ranges, mens Imperva tilbyder avanceret botdetektion, der kombinerer adfærdsanalyse med trusselsintelligens. Bright Data specialiserer sig i at forstå bottrafikmønstre og kan hjælpe organisationer med at skelne mellem forskellige typer crawlers. Valget af værktøjer afhænger af organisationens størrelse, tekniske niveau og specifikke krav—fra simpel robots.txt-håndtering for små sider til virksomheds-grade bot management-platforme for store organisationer med følsomme data. Uanset værktøjsvalg er det grundlæggende princip: Indsigt i cross-origin AI-adgang er fundamentet for effektiv kontrol og beskyttelse af digitale aktiver.
Få fuld indsigt i, hvilke AI-systemer der tilgår dit brand på tværs af GPT'er, Perplexity, Google AI Overviews og andre platforme. Spor cross-origin AI-adgangsmønstre og forstå, hvordan dit indhold anvendes i AI-træning og inferens.
Lær, hvordan du administrerer AI-crawleres adgang til dit webstedsindhold. Forstå forskellen mellem trænings- og søgecrawlere, implementer robots.txt-kontroller...

Lær hvordan webapplikationsfirewalls giver avanceret kontrol over AI-crawlere ud over robots.txt. Implementer WAF-regler for at beskytte dit indhold mod uautori...

Lær hvordan Cloudflares edge-baserede AI Crawl Control hjælper dig med at overvåge, kontrollere og tjene penge på AI-crawlers adgang til dit indhold med granulæ...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.