
Sådan implementerer du FAQ-skema for AI: Komplet guide 2025
Lær hvordan du implementerer FAQ-skema for AI-søgemaskiner. Trin-for-trin guide der dækker JSON-LD-format, bedste praksis, validering og optimering til AI-platf...
10 min læsning
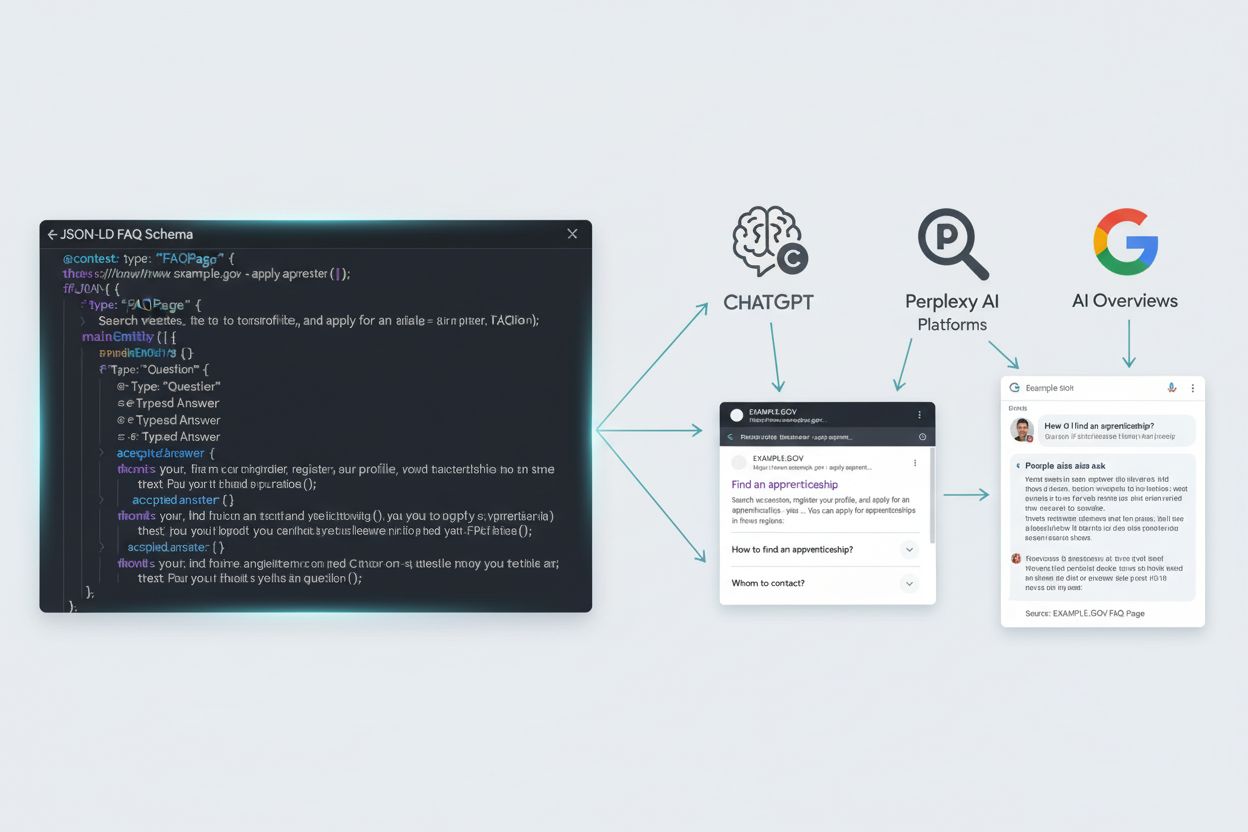
FAQ-skema (FAQPage) er struktureret data-markup, der bruger JSON-LD-format, som hjælper søgemaskiner og AI-platforme med at forstå relationen mellem spørgsmål og svar på websider. Det muliggør, at indhold kan vises i udvidede søgeresultater og citeres af AI-systemer som ChatGPT, Perplexity og Google AI Overviews.
FAQ-skema (FAQPage) er struktureret data-markup, der bruger JSON-LD-format, som hjælper søgemaskiner og AI-platforme med at forstå relationen mellem spørgsmål og svar på websider. Det muliggør, at indhold kan vises i udvidede søgeresultater og citeres af AI-systemer som ChatGPT, Perplexity og Google AI Overviews.
FAQ-skema (formelt kendt som FAQPage i Schema.org-vokabularet) er en type struktureret data-markup, der eksplicit mærker spørgsmål og svar på websider ved hjælp af JSON-LD-format. Det hjælper søgemaskiner og AI-platforme med at forstå forholdet mellem spørgsmål og deres tilhørende svar, hvilket gør det muligt for disse systemer at udtrække, verificere og citere dit indhold mere nøjagtigt. I modsætning til ustruktureret indhold, hvor AI-systemer skal fortolke relationer gennem naturlig sprogbehandling, leverer FAQ-skema maskinlæsbare metadata, der tydeligt signalerer: “Dette er et spørgsmål. Dette er det autoritative svar. Disse elementer hænger sammen.” Denne eksplicitte mærkning fjerner fortolkningsbyrden og øger sandsynligheden for korrekt udtræk og citat markant på tværs af søgemaskiner og AI-platforme.
FAQ-skema blev introduceret af Google i 2019 som et middel til at hjælpe søgemaskiner med bedre at forstå og vise ofte stillede spørgsmål i søgeresultater. Markupen opnåede hurtigt udbredelse på tværs af brancher—fra e-handel til SaaS, sundhedspleje til finans—efterhånden som websites indså de umiddelbare fordele i form af øget synlighed og højere klikrater. I 2021 var FAQ-skema implementeret på millioner af websider globalt og blev en af de mest populære strukturerede dataformater blandt SEO-professionelle. Skemaet repræsenterede et markant skifte i tilgangen til søgeoptimering, væk fra traditionel søgeordsfokusering og hen imod semantisk forståelse af indholdsrelationer.
Men landskabet ændrede sig dramatisk i august 2023, da Google annoncerede en afgørende begrænsning: FAQ-udvidede resultater ville kun blive vist for “velkendte, autoritative offentlige og sundhedssider.” Denne beslutning afspejlede Googles bekymringer over udbredt misbrug af markupen—spørgsmål fyldt med søgeord, irrelevant indhold og dubleret information, der reelt ikke hjalp søgende. I begyndelsen af 2024 havde Google effektivt fjernet FAQ-udvidede resultater for de fleste domæner, selvom de strukturerede data stadig var gyldige. Dette skifte markerede et kritisk vendepunkt i FAQ-skemaets rolle i SEO-strategien, hvor det gik fra at være en traditionel synlighedstaktik til at blive en essentiel faktor for AI-søgeoptimering.
Korrekt FAQ-skema-implementering kræver forståelse af den specifikke JSON-LD-struktur, som søgemaskiner og AI-platforme genkender. Markupen består af tre primære komponenter: typen FAQPage (der identificerer siden som indeholdende FAQs), Question-objekter (som indeholder egenskaben “name” med selve spørgsmålet) og Answer-objekter (som indeholder egenskaben “text” med svaret). Hvert spørgsmål skal have præcis ét acceptedAnswer, hvilket adskiller FAQ-skema fra QAPage (bruges til community Q&A med flere svar) eller HowTo-skema (bruges til trin-for-trin-instruktioner).
Den tekniske arkitektur for FAQ-skema afspejler, hvordan AI-systemer behandler information. Når du implementerer FAQPage-markup, leverer du eksplicitte semantiske relationer, som store sprogmodeller kan analysere direkte uden tvetydighed. Forskning viser, at 78% af AI-genererede svar inkluderer listeformater, og FAQ-skema strukturerer naturligt indhold som spørgsmål-svar-par—præcis det format, AI-platforme præsenterer for brugere. Denne strukturelle overensstemmelse gør FAQ-indhold særligt egnet til AI-citering. Skemaet understøtter HTML-formatering i svarteksten, hvilket gør det muligt at tilføje links, lister og fremhævning, der forbedrer læsbarheden uden at gå på kompromis med maskinlæsbarheden.
| Aspekt | FAQ-skema (FAQPage) | QA Page-skema | HowTo-skema | Artikel-skema |
|---|---|---|---|---|
| Bedst til | Ét svar pr. spørgsmål | Flere brugerindsendte svar | Trin-for-trin-vejledninger | Nyheder, blogindlæg, artikler |
| Svarstruktur | Ét accepteret svar | Flere svar mulige | Sekventielle trin med handlinger | Narrativt indholdsflow |
| Brugseksempel | Produktsupport-FAQs | Stack Overflow, Quora | Opskriftsvejledninger, tutorials | Nyhedsartikler, blogindlæg |
| AI-citatfrekvens | Højeste blandt skematyper | Medium (afhænger af community) | Høj (procedureindhold) | Høj (autoritetsindhold) |
| Google udvidede resultater | Begrænset (kun offentlige/sundhed) | Ikke berettiget til udvidede resultater | Berettiget til udvidede resultater | Berettiget til udvidede resultater |
| Ideel svarlængde | 40-60 ord | Variabel (afhængig af brugere) | 100-200 ord pr. trin | 150+ ord pr. sektion |
| Platformpræference | ChatGPT, Perplexity, Google AI | Begrænset AI-adoption | Google Assistant, stemmesøgning | Alle større AI-platforme |
| Synlighed i søgeresultater | Minimal (efter 2023) | Minimal | Featured snippets | Featured snippets, karruseller |
Skiftet fra traditionel søgning til AI-drevne svarmotorer har fundamentalt ændret indholdsstrategien og FAQ-skemaets rolle i den. AI-henviste sessioner steg med 527% mellem januar og maj 2025, ifølge Search Engine Land, hvilket fundamentalt ændrede måden, brugere opdager information på. I stedet for at klikke sig gennem søgeresultater, modtager brugerne nu direkte svar fra ChatGPT, Perplexity og Googles AI Overviews—hvilket gør FAQ-skema til det kritiske bindeled mellem dit indhold og AI-citater. Denne transformation repræsenterer et paradigmeskifte: Succes måles ikke længere primært på søgeplaceringer og klik, men på citatfrekvens i AI-genererede svar.
FAQ-skema har en af de højeste citatfrekvenser blandt alle skematyper i AI-genererede svar, fordi spørgsmål-svar-formatet afspejler, hvordan AI-platforme præsenterer information for brugere. Når AI-systemer støder på korrekt strukturerede FAQ-data, kan de udtrække svar direkte uden at skulle fortolke relationer gennem kompleks sprogbehandling. Denne pålidelighed gør FAQ-indhold iboende troværdigt for AI-algoritmer. Derudover skal FAQ-svar være selvstændige for at fungere effektivt i AI-søgning—i modsætning til traditionelt indhold, hvor konteksten bygges op over flere afsnit, udtrækker AI-platforme individuelle Q&A’er uden omgivende indhold. Dette krav forbedrer faktisk også indholdskvaliteten for menneskelige læsere, da det tvinger skribenter til at skabe omfattende, selvstændige svar, der giver mening uafhængigt.
Forskellige AI-søgeplatforme udviser forskellige citatmønstre og indholdspræferencer, som påvirker, hvordan FAQ-skema bør optimeres. ChatGPT udviser en stærk præference for opslagsværkslignende, velstruktureret indhold, hvor Wikipedia tegner sig for 47,9% af ChatGPTs samlede citater ifølge GEO-forskning. Dette afslører ChatGPTs præference for neutralt, autoritativt og omfattende struktureret information. FAQ-skema matcher perfekt disse præferencer, fordi det eksplicit mærker spørgsmål og svar på samme måde, som Wikipedia strukturerer sine indholdssektioner. For at optimere FAQ-indhold til ChatGPT-synlighed bør du opretholde en objektiv, informativ tone frem for salgspræget sprog, sikre at hvert svar er selvstændigt med fuld kontekst og inkludere specifikke statistikker, datoer og kvantificerede udsagn med korrekt kildeangivelse.
Perplexity AI vælger en markant anderledes tilgang, hvor Reddit tegner sig for 6,6% af Perplexitys citater—en meget højere procentdel end andre AI-platforme. Dette signalerer Perplexitys præference for autentisk, erfaringsbaseret, konversationelt indhold frem for rent opslagsværksstof. Til Perplexity-optimering bør du formulere spørgsmål, som rigtige mennesker ville stille dem i daglig tale, inkludere konkrete scenarier og kundeoplevelser i FAQ-svar, bevare en lidt mere personlig, hjælpsom stemme (som en ekspertven, der forklarer noget), og understrege praktisk handlemulighed med klare næste skridt. Google AI Overviews har en domæneuafhængig tilgang, hvor der trækkes fra featured snippet-indhold og sider med stærke E-E-A-T-signaler. Optimeringen bør fokusere på alignment med featured snippets (40-60 ords svar), E-E-A-T-signaler (forfatterkredentialer, publiceringsdatoer, eksterne citater), mobil-først-indholdsdesign og kombination af skematyper (FAQ + Artikel + Organisation) for øget autoritet.
Effektiv implementering af FAQ-skema kræver, at du følger specifikke retningslinjer, der sikrer både søgemaskinegenkendelse og AI-platform-kompatibilitet. Ét svar pr. spørgsmål er fundamentalt—FAQ-skema bør kun bruges, hvor der er ét endegyldigt svar på hvert spørgsmål. Hvis din side har ét spørgsmål, men flere brugere kan indsende alternative svar (som et forum), skal du i stedet bruge QAPage-skema. Brug ikke FAQ-skema til “How To”-indhold—selvom det kan virke relevant, er FAQ-skemaet ikke beregnet til trin-for-trin-instruktioner. Brug den dedikerede HowTo-skema-type til dette formål. Undgå at bruge markupen til reklameformål—skemaet er beregnet til at give søgemaskiner mere kontekst om dine siders indhold og give brugerne direkte adgang til værdifuld information. Brug af FAQ-skema til salgsformål overtræder Googles retningslinjer og lærer AI-platforme at mistro dit domæne.
Undgå gentaget FAQ-indhold på tværs af flere sider—hvis det samme spørgsmål og svar optræder på flere sider på dit site, bør du kun implementere det pågældende FAQ-skema én gang for hele sitet. En webcrawler kan hjælpe med at finde disse dublerede spørgsmål. Sørg for, at alt indhold er synligt for brugerne—Googles retningslinjer for strukturerede data forbyder eksplicit schema-markup for indhold, der ikke er synligt for brugerne. Hvis FAQ-indhold kun eksisterer i dit schema-markup, men ikke faktisk vises på siden, kan AI-platforme ignorere skemaet helt eller markere dit domæne for spam. FAQ-sektioner med spørgsmål, der er synlige og svar, der foldes ud ved klik, er acceptable; CSS display: none eller visibility: hidden anvendt på FAQ-indhold er ikke. Besvar spørgsmål fuldt ud—både spørgsmål og svar skal være udfyldt i dit schema-kode. Hele spørgsmålet og svaret kan blive vist som udvidet resultat eller citeret af AI, så der må ikke være fragmenter eller ufuldstændig information.
Selvom Google har begrænset FAQ-udvidede resultater, øger FAQ-skema stadig markant dine chancer for at optræde i featured snippets—de “position nul”-svarbokse over de organiske resultater. Forskning fra Search Engine Land viser, at sider med FAQ-skema har større sandsynlighed for at opnå featured snippets for spørgsmålssøgninger sammenlignet med tilsvarende sider uden struktureret Q&A-markup. Skemaet hjælper Google med at identificere det bedste svar at udtrække og vise og signalerer effektivt til algoritmen: “Dette er et komplet, autoritativt svar på dette specifikke spørgsmål.” Featured snippets er fortsat værdifulde, fordi de fanger stemmesvar (kritisk, da stemmesøgninger fortsætter med at vokse), vises fremtrædende på mobil, hvor skærmplads er begrænset, opbygger autoritet og tillid hos brugere, driver klik for dybere information, og leverer data til Google AI Overviews.
Stemmesøgeoptimering gennem FAQ-skema er blevet stadig vigtigere, efterhånden som smarte højttalere og stemmeassistenter breder sig. Når nogen spørger deres enhed om noget, søger assistenten efter korte, selvstændige svar—præcis det, et korrekt struktureret FAQ-skema leverer. Stemmeassistenter som Siri, Alexa og Google Assistant trækker svar fra strukturerede FAQ-data, hvilket gør FAQ-skema-implementering uundværlig for synlighed i stemmesøgninger. Spørgsmål-svar-formatet matcher naturligt den måde, folk stiller spørgsmål på til stemmeassistenter, hvilket gør FAQ-indhold særligt egnet til stemmesøgeoptimering. Efterhånden som stemmesøgning fortsætter med at stige—særligt for lokale forespørgsler, produktinformation og hurtige svar—bliver FAQ-skema en kritisk del af en omfattende stemmesøgestrategi.
At skjule FAQ-indhold for brugere er en af de mest kritiske fejl, der blokerer for AI-citater. Googles retningslinjer for strukturerede data forbyder eksplicit schema-markup for indhold, der ikke er synligt for brugere, og denne regel gælder også for AI-platformes behandling af FAQ-skema. Hvis FAQ-indhold kun findes i dit schema-markup, men ikke faktisk vises på siden, kan AI-platforme ignorere skemaet helt eller markere dit domæne for spam. Hvad der tæller som “skjult” inkluderer CSS display: none eller visibility: hidden på FAQ-indhold, FAQ-tekst i schema, der ikke optræder nogen steder i synligt sideindhold, indhold, der kun indlæses via JavaScript, som bots ikke kan gengive, og FAQ-sektioner placeret langt uden for skærmen eller bag komplekse interaktioner. Hvad der er acceptabelt inkluderer FAQ-sektioner, hvor spørgsmål er synlige og svar foldes ud ved klik, tab-interface hvor FAQ-indhold findes i DOM, men forskellige faner viser forskellige FAQs, mobilvenlige implementeringer, der omorganiserer indhold til forskellige skærmstørrelser, og FAQ-indhold i sidekroppen, selv hvis det ikke optræder i navigationen.
At bruge FAQ-skema til markedsføringsindhold frem for reelt informative svar er en anden kritisk fejl. Google og AI-platforme skelner mellem reelt informative FAQ’er og salgsfremmende materiale, der er forklædt som spørgsmål. Forbudte FAQ-tilgange inkluderer “Hvorfor er [din virksomhed] det bedste valg?” med et svar, der blot er en salgstale, “Hvad gør [dit produkt] revolutionerende?” med markedsføringstekst som svar, og FAQ-sektioner, der kun eksisterer for at manipulere søgerangeringer frem for at hjælpe brugere. Skellet er tydeligt: Informations-FAQs besvarer spørgsmål, brugere reelt har om dit produkt eller din service. Marketing-FAQs er tyndt forklædte reklamer med spørgsmålstegn. Er du i tvivl, så spørg: “Ville dette FAQ-svar tilfredsstille én, der researcher objektivt, eller giver det kun mening som reklame?” Implementér kun schema for reelt hjælpsomme svar.
At skrive vage eller ufuldstændige svar reducerer citatmuligheden betydeligt. AI-platforme prioriterer faktuelle, specifikke, databaserede svar. Vage FAQ-svar som “Det er meget hjælpsomt,” “Mange eksperter anbefaler det,” eller “Du vil opleve markante forbedringer” giver ingen udtrækkelige fakta for AI-platforme at citere. Specifikke, citerbare svar indeholder kvantificerede udsagn med autoritative kilder og links. Derudover reducerer ufuldstændige svar, der straks afføder opfølgende spørgsmål, effektiviteten. Hvis dit FAQ-svar efterlader brugeren med behov for mere information, er det ufuldstændigt. Sørg for, at svar er selvstændige med komplet information, specifikke data og eksterne citater hvor relevant—not afhængige af omgivende indhold for forståelse.
Måling af FAQ-skemaets succes har fundamentalt ændret sig fra traditionelle SEO-metrics til AI-søgemetrics. Traditionel SEO målte FAQ-skemaets succes gennem FAQ-udvidede resultater i Google Search Console og klikrater fra søgeresultater. AI-søgemetrics fokuserer på citatfrekvens i ChatGPT, Perplexity og AI Overview-svar. Det repræsenterer et paradigmeskifte i, hvordan indholdsteams bør vurdere ROI på FAQ-skema. I stedet for at spørge “Hvor mange udvidede resultater fik vi?” bør teams spørge “Hvor mange gange blev vores FAQ-indhold citeret i AI-genererede svar?” og “Hvilken procentdel af AI-svar om vores emne inkluderer vores indhold?”
Sporing af AI-citater kræver andre værktøjer og tilgange end traditionel SEO-overvågning. Platforme som AmICited gør det muligt for brands at overvåge, hvor deres FAQ-indhold optræder i ChatGPT, Perplexity, Google AI Overviews og Claude—og giver indsigt i AI-søgepræstation. Ved at spore citatfrekvens over tid kan indholdsteams måle den direkte effekt af FAQ-skema-implementering på AI-synlighed. Derudover forbliver overvågning af featured snippet-placeringer værdifuldt, da featured snippets leverer data til Google AI Overviews og giver en dobbelt fordel: forbedret synlighed i traditionel søgning OG øget sandsynlighed for AI-citater. For teams med flere FAQ-implementeringer hjælper brugen af spørgeforskningsværktøjer med at identificere, hvilke spørgsmål der bør prioriteres for maksimal AI-citatpotentiale baseret på søgevolumen og emnerelevans.
FAQ-skemaets fremtid er uløseligt forbundet med udviklingen af AI-søgning og den fortsatte udvikling af generative søgemaskiner. Efterhånden som flere brugere vender sig mod ChatGPT, Perplexity og Google AI Overviews for svar i stedet for traditionelle søgeresultater, bliver FAQ-skema en uundværlig forudsætning for indholdssynlighed. Skiftet fra “klik” til “citater” som primært succeskriterium for indhold er allerede i gang, og denne tendens vil accelerere. De første beviser tyder på, at dobbeltoptimering—at skabe indhold, der klarer sig godt både i traditionelle søgeresultater OG i AI-genererede citater—giver sammensatte gevinster. Indhold, der rangerer i Googles top 10 og har korrekt FAQ-skema, opnår synlighed i blå links, featured snippets og AI Overviews og dominerer effektivt søgelandskabet for målrettede forespørgsler.
AI-platforme vil sandsynligvis fortsætte med at forfine, hvordan de udtrækker og citerer FAQ-indhold, og udvikle mere sofistikerede metoder til at identificere kilder af høj kvalitet og autoritet. Efterhånden som AI-systemer bliver bedre til at opdage og straffe lavkvalitets eller manipulerende FAQ-implementeringer, vil vigtigheden af ægte, brugerfokuseret FAQ-indhold kun stige. Desuden vil spørgsmål-svar-formatet blive endnu mere centralt for brugerinteraktion med søgesystemer i takt med, at stemmesøgning og konversationelle AI-forespørgsler bliver mere udbredte. Organisationer, der investerer i FAQ-skema af høj kvalitet i dag, vil være godt positioneret til at opnå synlighed på alle større AI-platforme, efterhånden som disse teknologier fortsætter med at udvikle sig og modnes.
FAQ-skema er struktureret data-markup med JSON-LD-format, der eksplicit mærker spørgsmål og svar på websider og hjælper søgemaskiner og AI-platforme med at forstå indholdsrelationer.
AI-citatfrekvensen er højest for FAQ-skema blandt strukturerede datatyper, og sider med FAQPage-markup optræder markant hyppigere i ChatGPT, Perplexity og Google AI Overviews end ustruktureret indhold.
Google begrænsede FAQ-udvidede resultater i august 2023 til offentlige og sundhedssider, men FAQ-skema forbliver kritisk for featured snippets, stemmesøgning og især AI-søgeoptimering.
Platform-specifik optimering er vigtig—ChatGPT foretrækker neutralt, autoritativt indhold med citater; Perplexity vægter konversationelle, erfaringsbaserede svar; Google AI Overviews lægger vægt på E-E-A-T-signaler og mobiloptimering.
Ideelle FAQ-svar er 40-60 ord, selvstændige med fuld kontekst, specifikke data og eksterne citater—not afhængige af omgivende indhold for forståelse.
Almindelige fejl inkluderer at skjule FAQ-indhold for brugere, bruge FAQ-skema til markedsføringsformål, skrive vage svar og undlade at validere schema-markup før udgivelse.
Succesmåling er skiftet fra traditionelle SEO-metrics (udvidede resultater) til AI-søgemetrics (citatfrekvens i AI-genererede svar).
FAQ-skemaets fremtid er forbundet med AI-søgnings udvikling—efterhånden som AI-henviste sessioner fortsætter med at vokse eksplosivt, bliver FAQ-skema-implementering stadig mere afgørende for indholdssynlighed.
FAQ-skema (FAQPage) er struktureret data-markup, der bruger JSON-LD-format til eksplicit at mærke spørgsmål og deres tilhørende svar på websider. Det hjælper søgemaskiner og AI-platforme med at forstå spørgsmål-svar-relationen, hvilket gør det nemmere for disse systemer at udtrække, verificere og citere dit indhold i genererede svar. Skemaet fungerer som metadata, som maskiner kan læse for at identificere Q&A-struktur uanset sidens design eller formateringsvariationer.
Ja, men dets værdi er flyttet fra traditionel SEO til AI-søgeoptimering. Google begrænsede FAQ-udvidede resultater til offentlige og sundhedssider i august 2023, hvilket reducerede synlige FAQ-uddrag for de fleste virksomheder. FAQ-skema forbliver dog kritisk for featured snippets, stemmesøgning og især AI-søgeplatforme som ChatGPT og Perplexity, som i høj grad er afhængige af strukturerede FAQ-data til citater. Skemaet blev endnu vigtigere for generativ engine-optimering, selvom det blev mindre synligt i traditionelle søgeresultater.
FAQ-skema har en af de højeste citatfrekvenser blandt skematyper i AI-genererede svar, fordi spørgsmål-svar-formatet afspejler, hvordan AI-platforme præsenterer information. Strukturerede FAQ-data fjerner fortolkningsbyrden fra naturlig sprogbehandling, så AI kan udtrække svar direkte og citere kilder præcist. Sider med FAQ-skema har 3,2 gange større sandsynlighed for at optræde i Google AI Overviews sammenlignet med sider uden FAQ-strukturerede data, ifølge Search Engine Lands analyse fra 2024.
For traditionel SEO gik FAQ-skema efter udvidede resultater og featured snippets i Googles søgeresultater. For GEO (Generative Engine Optimization) og AEO (Answer Engine Optimization) muliggør FAQ-skema, at AI-platforme kan udtrække, forstå og citere dit indhold i genererede svar på tværs af ChatGPT, Perplexity og Google AI Overviews. Fokus er flyttet fra at opnå klik gennem synlige udvidede resultater til at opnå citater i AI-genererede svar, som brugere læser uden at klikke videre til kildesider.
Inkludér 5-10 FAQ-spørgsmål pr. side for søjleindhold. Færre end 5 giver begrænset værdi for brugere og AI-udtræk, mens mere end 10 kan udvande fokus og overvælde læsere. Kvalitet er vigtigere end kvantitet—besvar reelle brugerspørgsmål grundigt med svar på 40-60 ord, der indeholder specifikke data, eksterne citater og fuld kontekst. Brug spørgeforskningsværktøjer til at identificere, hvilke spørgsmål der har reel søgeefterspørgsel, inden du implementerer skemaet.
Ja, så længe FAQs er reelt informative og ikke salgsfremmende. Googles retningslinjer for strukturerede data forbyder FAQ-skema til reklame- eller markedsføringsindhold. Fokuser på at besvare reelle kundespørgsmål om funktioner, pris, levering, brug, kompatibilitet eller support. Acceptable spørgsmål inkluderer 'Hvilke funktioner er inkluderet?' eller 'Hvordan fungerer levering?' Uacceptable spørgsmål inkluderer 'Hvorfor skal du købe nu?' eller 'Hvorfor er vi de bedste?'
40-60 ord er ideelt for AI-udtræk, featured snippets og brugeroplevelse. Kortere svar (under 30 ord) mangler ofte tilstrækkelig kontekst til at stå alene. Længere svar (over 80 ord) bliver sværere for AI-platforme at udtrække rent som enkelte enheder og sværere for brugere at overskue hurtigt. Sørg for, at svar er selvstændige med komplet information, specifikke data og eksterne citater hvor det er relevant—not afhængige af omgivende indhold for forståelse.
Brug Google Rich Results Test til at validere JSON-LD-syntaks, finde manglende egenskaber og forhåndsvise, hvordan Google fortolker dit markup. Verificer desuden mobilvisning (hvor stemmeassistenter kører), sørg for at spørgsmål matcher synlige sideoverskrifter nøjagtigt, test at svar er selvstændige og omfattende, og overvåg om dit FAQ-indhold optræder i AI-genererede svar i 2-4 uger efter implementering. Periodisk revalidering efter siteopdateringer forhindrer tilbagefald og sikrer løbende kompatibilitet.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær hvordan du implementerer FAQ-skema for AI-søgemaskiner. Trin-for-trin guide der dækker JSON-LD-format, bedste praksis, validering og optimering til AI-platf...
Lær hvorfor FAQ-skema har de højeste citationsrater for AI-søgning. Komplet guide til FAQPage-strukturerede data for ChatGPT, Perplexity og Google AI Overviews....
Fællesskabsdiskussion om implementering af FAQ-skema for AI-synlighed. Tekniske SEO-professionelle deler erfaringer, bedste praksis for implementering og effekt...