
Sådan implementerer du LLMs.txt: En trin-for-trin teknisk guide
Lær hvordan du implementerer LLMs.txt på dit website for at hjælpe AI-systemer med bedre at forstå dit indhold. Komplet trin-for-trin guide til alle platforme, ...
9 min læsning

En foreslået standardfil, der placeres i roddomænet på et website og kommunikerer med AI-crawlere og store sprogmodeller om indhold af høj kvalitet, der kan citeres. Minder om robots.txt, men er designet til vejledning under inferenstid frem for adgangskontrol. Hjælper AI-systemer med at opdage og prioritere autoritativt indhold, når de genererer svar. Bliver i stigende grad taget i brug af store AI-platforme som OpenAI, Anthropic, Perplexity og Google.
En foreslået standardfil, der placeres i roddomænet på et website og kommunikerer med AI-crawlere og store sprogmodeller om indhold af høj kvalitet, der kan citeres. Minder om robots.txt, men er designet til vejledning under inferenstid frem for adgangskontrol. Hjælper AI-systemer med at opdage og prioritere autoritativt indhold, når de genererer svar. Bliver i stigende grad taget i brug af store AI-platforme som OpenAI, Anthropic, Perplexity og Google.
LLMs.txt-filen er en ren tekst markdown-fil, der placeres i roddomænet på et website og fungerer som en kurateret guide for store sprogmodeller under inferenstid. I modsætning til traditionelle SEO-værktøjer er LLMs.txt designet til at hjælpe AI-crawlere og sprogmodeller med at opdage og prioritere indhold af høj kvalitet på dit website, når de genererer svar eller søger efter information. Denne foreslåede standard repræsenterer et skifte i, hvordan websites kommunikerer med kunstige intelligenssystemer, idet man bevæger sig ud over blokering som i robots.txt og i stedet leverer intelligent indholdskuratering. Filen fungerer som et indholds-roadmap, der fortæller AI-systemer, hvilke sider, artikler og ressourcer der er mest værdifulde, autoritative og relevante for deres formål. Det er vigtigt at forstå, at LLMs.txt ikke handler om at blokere eller tillade AI-træning — den handler specifikt om indtagelse under inferens, så AI-systemer kan finde det rette indhold, når de besvarer brugerspørgsmål. Filen skrives i markdown-format og gemmes som ren tekst, hvilket gør den enkel at oprette og vedligeholde. Ved at implementere LLMs.txt kan websites sikre, at når AI-systemer henviser til deres indhold, trækker de på de mest nøjagtige, velstrukturerede og autoritative kilder, der er tilgængelige.
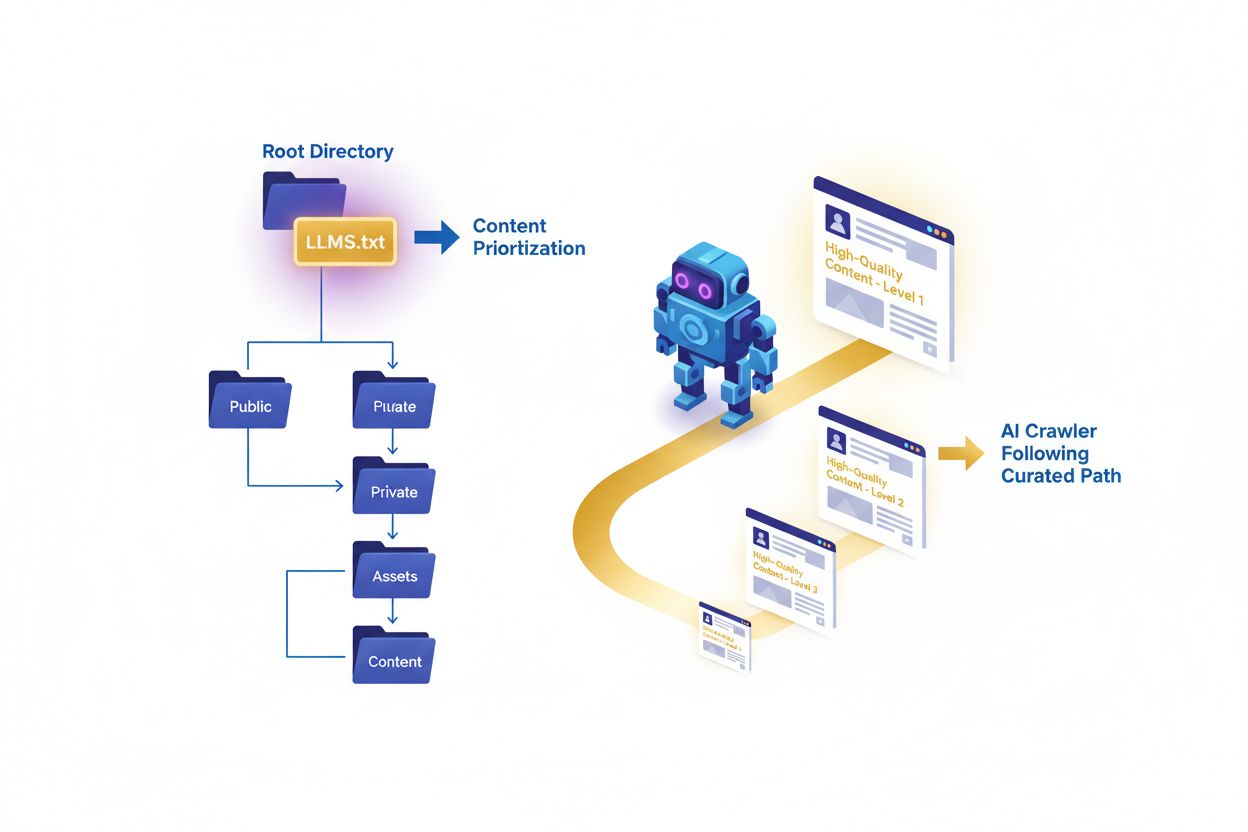
Mens robots.txt og sitemap.xml har tjent websites godt i forhold til traditionelle søgemaskiner, adresserer LLMs.txt et fundamentalt anderledes behov i kunstig intelligens’ tidsalder. Den vigtigste forskel ligger i deres primære funktion og timing: robots.txt styrer crawl-adfærd og hvad søgemaskiner kan tilgå, sitemap.xml hjælper søgemaskiner med at opdage og indeksere sider, mens LLMs.txt vejleder AI-systemer under inferens, når de aktivt genererer svar. Det er afgørende at forstå, at LLMs.txt ikke blokerer eller tillader AI-træning — den kuraterer blot, hvilket indhold AI-systemer skal prioritere, når de besvarer spørgsmål eller henter information. De tre filer tjener komplementære formål og kan sagtens eksistere på samme domæne uden konflikt. Hvor robots.txt handler om adgangskontrol og sitemap.xml om opdagelse, handler LLMs.txt om indholdskvalitet og relevans. Tænk på det sådan: robots.txt siger “hvad du må crawle”, sitemap.xml siger “her er hvad der findes”, og LLMs.txt siger “her er det, der er vigtigst”. Denne forskel er især vigtig, fordi AI-systemer har brug for andre signaler end traditionelle søgemaskiner — de skal forstå, hvilket indhold der er autoritativt, velstruktureret og egnet til citation.
| Fil | Primær funktion | Hovedformål | Anvendelsesområde |
|---|---|---|---|
| robots.txt | Adgangskontrol | Forhindre/tillade crawler-adgang | Blokering af følsomme sider for søgemaskiner |
| sitemap.xml | Opdagelse | Hjælpe søgemaskiner med at finde sider | Forbedre indeksering af nyt eller dybt indhold |
| LLMs.txt | Indholdskuratering | Vejlede AI under inferens | Dirigere AI-systemer til autoritative kilder |
LLMs.txt-filen følger en markdown-baseret struktur, der både er menneskelæselig og maskinlæsbar, hvilket gør den tilgængelig for både indholdsskabere og AI-systemer. Filen starter typisk med en H1-titel (ved brug af #), der identificerer websitet og dets formål, efterfulgt af et indledende blockquote, der giver kontekst om websitets mission eller fokus. Kernen består af organiserede sektioner med H2-overskrifter (##), der kategoriserer forskellige typer indhold — såsom “Kerne Ressourcer”, “Vejledninger”, “Dokumentation” eller “Best Practices” — hver med en kurateret liste af URL’er med korte beskrivelser. En “Valgfri”-sektion til sidst giver mulighed for at inkludere yderligere ressourcer, der kan være værdifulde, men ikke er en del af den primære kuratering. Filen bruger ren tekst med UTF-8 kodning for at sikre kompatibilitet på tværs af alle systemer og AI-platforme. Hver URL-post omfatter typisk fuld sti og en kort beskrivelse af, hvorfor indholdet er værdifuldt eller hvad det omhandler. Anbefalet filstørrelse holdes generelt under 100KB for effektiv AI-behandling, selvom der ikke er et hårdt loft. Markdown-formatet giver fleksibel organisering med klarhed, og strukturen bør afspejle websitets faktiske indholdshierarki og vigtighed.
# Eksempelwebsite - LLMs.txt
> Dette er Eksempelwebsite, en omfattende ressource til læring om [dit emne].
> Vi tilbyder autoritative guides, tutorials og dokumentation for [dit område].
## Kerne Ressourcer
- https://example.com/about - Oversigt over vores mission og ekspertise
- https://example.com/getting-started - Vigtig startside for nye brugere
## Omfattende Vejledninger
- https://example.com/guide/advanced-techniques - Dybtgående udforskning af avancerede metoder
- https://example.com/guide/best-practices - Branchestandarder og anbefalinger
## Dokumentation
- https://example.com/docs/api-reference - Fuldstændig API-dokumentation
- https://example.com/docs/installation - Opsætnings- og installationsvejledning
## Valgfri
- https://example.com/blog/latest-trends - Seneste brancheindsigter
- https://example.com/case-studies - Eksempler på implementering i praksis
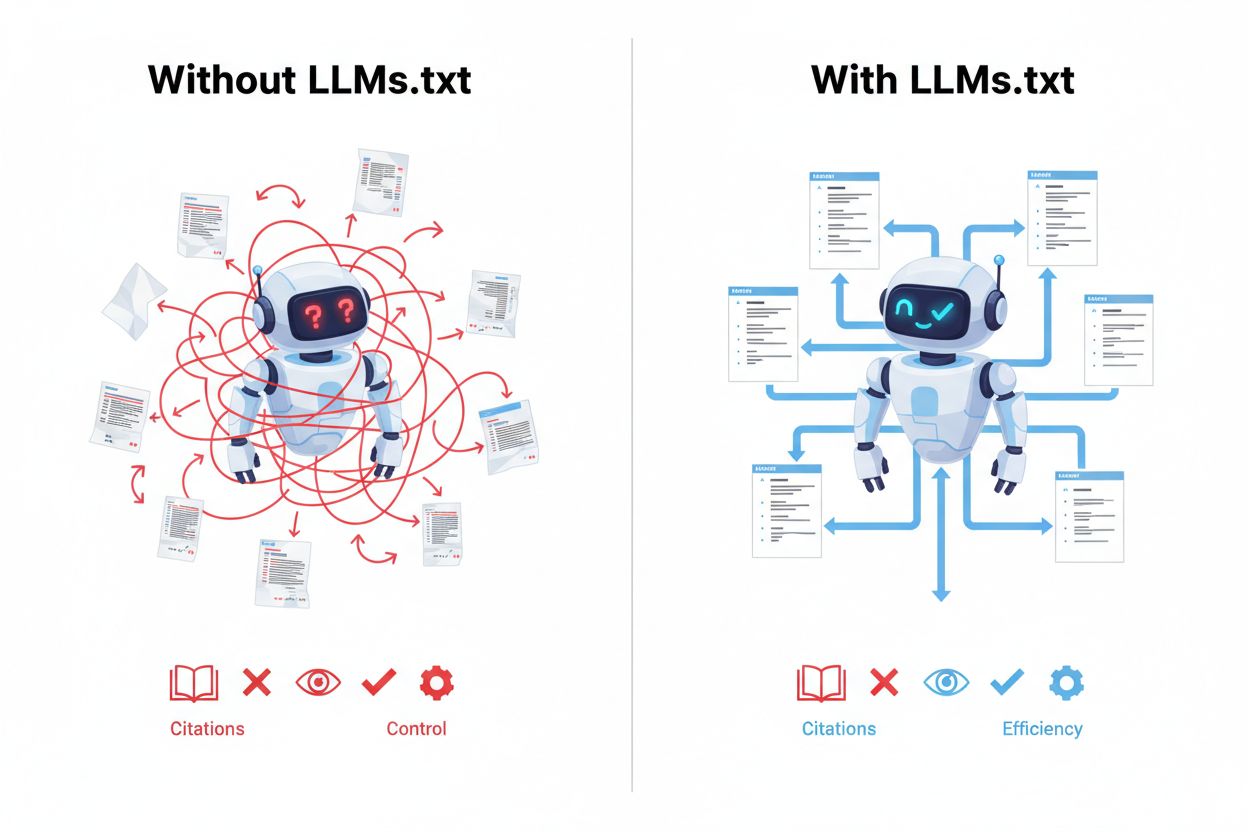
Implementering af LLMs.txt giver betydelige fordele i det nye landskab af AI-drevet søgning og indholdsopdagelse. Den største fordel er indtagelse under inferens, hvilket betyder, at dit kuraterede indhold prioriteres, når AI-systemer aktivt besvarer brugerspørgsmål, ikke under træning. Dette medfører bedre AI-forståelse af dit indholds kontekst, autoritet og relevans, hvilket resulterer i mere nøjagtige citationer og referencer, når AI-systemer omtaler dit arbejde. Ved at implementere LLMs.txt opnår du direkte kontrol over opdagelse, så AI-systemer finder dit bedste indhold først frem for potentielt mindre værdifulde sider. Filen øger din synlighed i AI-søgeresultater og AI-baserede applikationer, hvilket skaber en ny kanal for trafik og kreditering, der supplerer traditionel SEO. Organisationer, der tidligt tager LLMs.txt i brug, opnår en konkurrencefordel ved at etablere sig som autoritative kilder, før standarden bliver udbredt. Implementeringen fungerer også som en fremtidssikring og forbereder dit website til det uundgåelige skifte mod AI-drevet indholdsopdagelse.
Vigtige anvendelsestilfælde inkluderer:
LLM-venligt indhold har specifikke egenskaber, der gør det mere værdifuldt og brugbart for kunstige intelligenssystemer under inferens. Den vigtigste egenskab er klar struktur med korrekt overskriftshierarki, hvor H1, H2 og H3-tags bruges til at organisere information logisk, så AI-systemer kan forstå indholdets flow og relationer. Korte afsnit (typisk 2-4 sætninger) foretrækkes, fordi de gør det lettere for AI-systemer at udtrække diskrete begreber og idéer end tætte tekstblokke. Indholdet bør inkludere lister, tabeller og punktform, der opdeler komplekse informationer i overskuelige enheder, hvilket gør det lettere for AI at analysere og referere til specifikke punkter. Minimale forstyrrelser som autoafspillende videoer, pop-ups eller for mange reklamer bør undgås, da de ikke bidrager til indholdets kerneværdi. Semantisk klarhed er afgørende — brug klart sprog, definer tekniske udtryk og undgå tvetydighed, så AI-systemer kan forstå din mening korrekt. Indholdet skal være selvstændigt og kontekstuelt, så det giver mening, selv når det trækkes ud og bruges uden for den oprindelige sidekontekst. Denne tilgang understøtter direkte AI SEO og øger sandsynligheden for, at dit indhold citeres nøjagtigt og fuldt, når AI-systemer refererer til dit arbejde.
Korrekt implementering af LLMs.txt kræver strategisk overvejelse af, hvilket indhold der virkelig fortjener at blive inkluderet, og hvordan det organiseres for maksimal værdi. Filen skal placeres i roddomænet (f.eks. example.com/llms.txt) for let at kunne opdages af AI-systemer og crawlere. I stedet for at inkludere hele dit sitemap i LLMs.txt, skal du fokusere på kvalitet frem for kvantitet — inkludér kun dit mest autoritative, tidløse og værdifulde indhold, som du ønsker, AI-systemer skal referere til. Prioritér værdifulde ressourcer som omfattende vejledninger, dokumentation, tutorials og original forskning, der demonstrerer ekspertise og giver reel værdi. Overvej at inkludere din forside eller om-side for at hjælpe AI-systemer med at forstå din organisations mission og troværdighed. Det indhold, du vælger, bør være velvedligeholdt og opdateret, da forældet information kan skade din troværdighed hos AI-systemer. Organisér indholdet logisk med klare sektionstitler, der afspejler dit websites struktur og indholdskategorier. Undgå at inkludere indhold med krav om login, betalingsmure eller sider, der kræver brugeradgang, da AI-systemer ikke kan tilgå dem. Revider og opdatér din LLMs.txt-fil regelmæssigt for at afspejle ændringer i din indholdsstrategi, fjerne døde links og tilføje nye autoritative ressourcer efterhånden som de skabes.
LLMs.txt-udbredelsen accelererer hurtigt blandt større AI-platforme og virksomheder, der anerkender værdien af kuraterede indholdskilder. OpenAI, Anthropic, Perplexity og Google har alle udtrykt støtte til eller interesse for LLMs.txt-standarden, og nogle platforme bruger den aktivt for at forbedre deres retrieval- og citation-systemer. Standarden er stadig under udvikling og endnu ikke obligatorisk, men den bliver i stigende grad anerkendt som best practice for websites, der vil optimere deres synlighed i AI-drevne applikationer. Flere kataloger og registre er opstået for at liste websites, der implementerer LLMs.txt, hvilket gør det lettere for AI-systemer at opdage og prioritere kuraterede indholdskilder. Tidlige adoptører opnår en betydelig fordel ved at etablere sig som autoritative kilder, før standarden bliver allestedsnærværende på AI-platforme. Virkelige eksempler viser, at websites, der implementerer LLMs.txt, oplever flere citationer og bedre repræsentation i AI-genereret indhold. Udviklingen tyder på, at LLMs.txt vil blive lige så standardiseret som robots.txt og sitemap.xml inden for de næste par år, hvilket gør implementering til en fornuftig investering for fremadskuende organisationer.
Forskellen mellem llms.txt og llms-full.txt repræsenterer to komplementære tilgange til at vejlede AI-systemer gennem dit indhold. LLMs.txt er den kuraterede, menneskevalgte version, der kun indeholder dit vigtigste, mest autoritative og værdifulde indhold — typisk 20-100 URL’er organiseret efter kategori med beskrivelser. LLMs-full.txt derimod er en fuldstændig maskinlæsbar version, der inkluderer alle sider på dit website i et struktureret format, ofte automatisk genereret fra dit sitemap eller CMS. Hovedforskellen er intentionalitet: llms.txt kræver menneskelig vurdering og kuratering, mens llms-full.txt er omfattende og udtømmende. LLMs.txt bør bruges, når du ønsker at guide AI-systemer mod dit bedste indhold og etablere klare autoritetssignaler, mens llms-full.txt fungerer som fallback for AI-systemer, der ønsker fuld dækning af dit site. Begge filer bruger markdown-format, men med forskellige organisationsfilosofier — llms.txt er selektiv og strategisk, mens llms-full.txt er inkluderende og komplet. Mange organisationer implementerer begge filer sammen, så AI-systemer kan vælge mellem kurateret vejledning (llms.txt) eller fuld dækning (llms-full.txt). For eksempel tilbyder AIOSEO værktøjer til automatisk at generere begge versioner, hvor llms.txt fremhæver premium-indhold og llms-full.txt giver komplet site-dækning.
Flere almindelige fejl kan underminere effektiviteten af din LLMs.txt-implementering og bør undgås. Den mest kritiske fejl er at placere filen det forkerte sted — den skal ligge i roddomænet (example.com/llms.txt), ikke i undermapper eller med andre navngivninger. Manglende obligatoriske elementer som H1-titel og indledende blockquote kan forvirre AI-systemer omkring dit websteds formål og autoritet. Inkludering af døde eller forældede URL’er skader din troværdighed og spilder AI-systemers ressourcer på ikke-eksisterende indhold. Overinkludering er en anden fejl — hvis du tilføjer for mange URL’er (hundreder eller tusinder), går kurateringsformålet tabt, og det bliver sværere for AI-systemer at identificere det virkelig vigtige indhold. Dårlige eller manglende beskrivelser for hver URL betyder, at AI-systemer ikke kan forstå, hvorfor indholdet er værdifuldt eller hvad det dækker. Hvis du undlader regelmæssig opdatering bliver din LLMs.txt-fil forældet med døde links og irrelevant indhold, der ikke længere afspejler dit websites fokus. Inkludering af indhold med krav om login eller betalingsmur, som AI-systemer ikke kan tilgå, skaber frustration og reducerer tillid. Sørg endelig for at bruge korrekt MIME-type (text/plain eller text/markdown) ved servering af filen, da forkert konfiguration kan forhindre korrekt parsing af AI-systemer.
Flere værktøjer og ressourcer er opstået for at forenkle oprettelse og vedligeholdelse af LLMs.txt-filer. AIOSEO tilbyder et dedikeret plugin, der automatisk genererer både llms.txt og llms-full.txt-filer, hvilket gør implementering tilgængelig selv for ikke-tekniske brugere. For dem, der foretrækker manuel oprettelse, er processen enkel — opret blot en tekstfil i markdown-format og upload den til dit roddomæne. Valideringsværktøjer er tilgængelige online for at tjekke din LLMs.txt-fil for korrekt format, døde links og overholdelse af standarden. GitHub-fællesskabet har oprettet adskillige repositories med skabeloner, eksempler og best practices til LLMs.txt-implementering. Officiel dokumentation på llmstxt.org giver omfattende vejledning om filstruktur, formatkrav og implementeringsstrategier. Mange AI-platformes dokumentationssider inkluderer nu sektioner om LLMs.txt-support, så du kan forstå, hvordan forskellige systemer bruger dit kuraterede indhold. Disse ressourcer gør det samlet set nemmere end nogensinde at implementere LLMs.txt og sikre, at dit indhold bliver korrekt optimeret til AI-drevet opdagelse og citation.
LLMs.txt vejleder AI-systemer til dit bedste indhold til brug under inferenstid, mens robots.txt styrer, hvad søgemaskinecrawlere kan få adgang til. De tjener forskellige formål og kan eksistere side om side på samme domæne. LLMs.txt handler om kuratering og vejledning, mens robots.txt handler om adgangskontrol.
Nej, det er ikke obligatorisk, men det er ved at blive god praksis. Implementering af LLMs.txt giver dig en konkurrencefordel i AI-drevne søgeresultater og sikrer, at dit indhold får korrekt kreditering, når det citeres af AI-systemer.
Filen skal placeres i roden af dit domæne (f.eks. ditwebsite.com/llms.txt) for at kunne opdages af AI-systemer og crawlere. Den skal være offentligt tilgængelig uden autentificering.
Nej, llms.txt er ikke designet til at blokere eller styre træning. Den er specifikt til at vejlede AI-systemer under inferens (når der genereres svar). Brug robots.txt eller andre mekanismer, hvis du vil styre adgang til træning.
Gennemgå og opdatér kvartalsvis eller når du foretager væsentlige ændringer i din webstruktur, tilføjer nyt vigtigt indhold eller ændrer URL'er. Regelmæssig vedligeholdelse sikrer, at din fil forbliver nøjagtig og værdifuld.
OpenAI, Anthropic, Perplexity og Google er begyndt at implementere støtte til llms.txt. Anvendelsen vokser, efterhånden som standarden bliver mere etableret og anerkendt som god praksis.
LLMs.txt er en kurateret liste over dit bedste indhold (typisk 20-100 URL'er), mens llms-full.txt indeholder en komplet maskinlæsbar version af alt dit indhold i Markdown-format. Begge kan bruges sammen for maksimal fleksibilitet.
Fokusér på kvalitet frem for kvantitet. Inkludér 10-20 af dine vigtigste, mest autoritative sider, der bedst repræsenterer din ekspertise og indholdsværdi. Undgå at dumpe hele dit sitemap i filen.
AmICited sporer, hvordan AI-systemer henviser til dit brand på ChatGPT, Perplexity, Google AI Overviews og flere. Sørg for, at dit indhold får korrekt kreditering og synlighed i AI-genererede svar.
Lær hvordan du implementerer LLMs.txt på dit website for at hjælpe AI-systemer med bedre at forstå dit indhold. Komplet trin-for-trin guide til alle platforme, ...

Kritisk analyse af LLMs.txt's effektivitet. Find ud af, om denne AI-indholdsstandard er essentiel for dit site eller blot hype. Rigtige data om udbredelse, plat...

Lær hvordan du identificerer og målretter LLM-kildesider for strategiske backlinks. Oplev hvilke AI-platforme der citerer kilder mest, og optimer din linkbuildi...