Forespørgselsreformulering
Lær hvordan forespørgselsreformulering hjælper AI-systemer med at fortolke og forbedre brugerforespørgsler for bedre informationssøgning. Forstå teknikkerne, fo...
10 min læsning

Forespørgselsforfining er processen med at forbedre og optimere søgeforespørgsler gennem iterative justeringer, præciseringer og udvidelser for at generere mere nøjagtige, relevante og omfattende resultater fra AI-søgemaskiner og informationshentningssystemer. Det indebærer at opdele komplekse brugerforespørgsler i underforespørgsler, tilføje kontekstuelle detaljer og udnytte feedbacksløjfer for gradvist at forbedre søgeydelsen og resultatkvaliteten.
Forespørgselsforfining er processen med at forbedre og optimere søgeforespørgsler gennem iterative justeringer, præciseringer og udvidelser for at generere mere nøjagtige, relevante og omfattende resultater fra AI-søgemaskiner og informationshentningssystemer. Det indebærer at opdele komplekse brugerforespørgsler i underforespørgsler, tilføje kontekstuelle detaljer og udnytte feedbacksløjfer for gradvist at forbedre søgeydelsen og resultatkvaliteten.
Forespørgselsforfining er den iterative proces med at forbedre og optimere søgeforespørgsler gennem systematiske justeringer, præciseringer og udvidelser for at generere mere nøjagtige, relevante og omfattende resultater fra informationshentningssystemer og AI-søgemaskiner. I stedet for at betragte en brugers indledende søgning som endelig, anerkender forespørgselsforfining, at brugere ofte har behov for at ændre, udvide eller præcisere deres forespørgsler for at finde præcis det, de søger. Denne proces indebærer at analysere, hvordan brugere ændrer deres søgninger, foreslå forbedrede forespørgselsformuleringer og udnytte feedbacksløjfer for gradvist at forbedre søgeydelsen. I konteksten af moderne AI-søgeplatforme som ChatGPT, Perplexity, Google AI Overviews og Claude er forespørgselsforfining blevet en grundlæggende mekanisme til at levere omfattende, multisourcede svar, der adresserer komplekse brugerforespørgsler. Teknikken forvandler søgning fra en enkelt, statisk interaktion til en dynamisk, flertrins samtale, hvor hver forfining bringer brugeren tættere på den ønskede information.
Forespørgselsforfining er ikke et nyt begreb inden for informationshentning, men dens anvendelse har udviklet sig dramatisk med fremkomsten af kunstig intelligens og store sprogmodeller. Historisk set var søgemaskiner primært baseret på nøgleords-matchning, hvor en brugers forespørgsel blev matchet direkte mod indekserede dokumenter. Hvis du søgte efter “løbesko”, ville maskinen returnere dokumenter, der indeholdt de eksakte ord, uanset kontekst eller brugerintention. Denne tilgang var rigid og resulterede ofte i irrelevante resultater, fordi den ignorerede nuancerne i menneskets sprog og kompleksiteten i brugerbehov.
Udviklingen mod forespørgselsforfining begyndte med introduktionen af forespørgselsforslags-systemer i begyndelsen af 2000’erne, hvor søgemaskiner begyndte at analysere brugeradfærdsmønstre for at foreslå relaterede eller forfinede forespørgsler. Googles “Mente du?"-funktion og autofuldførelsesforslag var tidlige implementeringer af dette koncept. Disse systemer var dog relativt simple og baserede primært på historiske forespørgselslogs og frekvensanalyse. De manglede den semantiske forståelse, der er nødvendig for virkelig at begribe brugerintention eller relationerne mellem forskellige forespørgselsformuleringer.
Introduktionen af naturlig sprogbehandling (NLP) og maskinlæring transformerede forespørgselsforfining fundamentalt. Moderne systemer kan nu forstå, at “bedste vandtætte løbesko” og “topvurderet regntæt sportssko” i bund og grund er den samme forespørgsel, selvom de bruger helt forskellige udtryk. Denne semantiske forståelse gør det muligt for systemer at genkende forespørgselsvarianter, identificere implicitte brugerbehov og foreslå forfininger, der reelt forbedrer søgeresultaterne. Ifølge forskning fra Kopp Online Marketing SEO Research Suite er metoderne til forespørgselsforfining blevet stadig mere sofistikerede, og systemerne kan nu generere syntetiske forespørgsler (kunstigt skabte forespørgsler, der simulerer reelle brugersøgninger) for at forbedre træningsdata og øge hentningsnøjagtigheden.
Fremkomsten af generativ AI og store sprogmodeller har yderligere accelereret denne udvikling. Moderne AI-søgemaskiner forfiner ikke blot forespørgsler; de opdeler dem i flere underforespørgsler, eksekverer dem parallelt på tværs af forskellige datakilder og syntetiserer resultaterne til omfattende svar. Dette repræsenterer et grundlæggende skift fra forespørgselsforfining som en brugerrettet forslagsteknik til forespørgselsforfining som en kernearkitektonisk komponent i AI-søgesystemer.
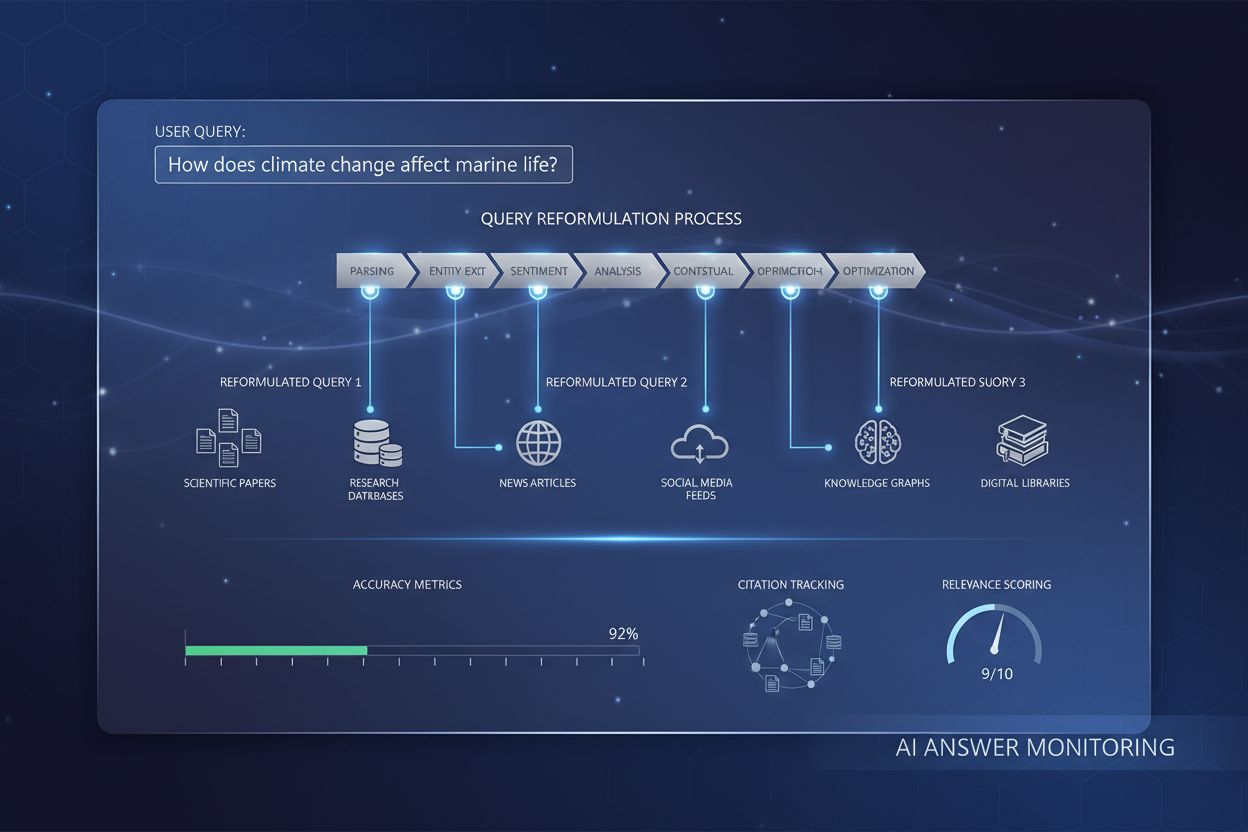
Forespørgselsforfining fungerer gennem flere indbyrdes forbundne tekniske mekanismer, der arbejder sammen for at forbedre søgekvaliteten. Den første mekanisme er forespørgselsanalyse og intentionsdetektion, hvor systemet behandler brugerens indledende forespørgsel for at identificere underliggende intention, kompleksitetsniveau og hvilken type svar, der er behov for. Avancerede NLP-modeller analyserer faktorer som forespørgslens længde, terminologisk specificitet og kontekstuelle signaler for at afgøre, om simpel nøgleords-matchning er tilstrækkelig, eller om mere sofistikeret forfining er nødvendig. For eksempel vil en simpel faktuel forespørgsel som “Tysklands hovedstad” måske ikke udløse omfattende forfining, mens en kompleks forespørgsel som “best practices for optimering af indhold til AI-søgemaskiner” vil aktivere omfattende forfiningsprocesser.
Den anden mekanisme er forespørgselsopdeling og fan-out, en teknik hvor komplekse forespørgsler opdeles i flere konstituerende underforespørgsler. Denne proces, kendt som query fan-out, er særlig vigtig i AI-søgesystemer. Når en bruger spørger “Hvad er de bedste vandtætte løbesko til en med platfod, der løber på stier?”, opdeler systemet dette i flere underforespørgsler: én der undersøger produktlister, en anden der gennemgår ekspertanmeldelser, en tredje der analyserer brugeroplevelser, og en fjerde der ser på tekniske specifikationer. Disse underforespørgsler eksekveres derefter parallelt på tværs af forskellige datakilder, herunder det levende web, vidensgrafer og specialiserede databaser. Denne parallelle eksekvering udvider informationsmængden betydeligt og gør det muligt for AI at give mere omfattende og nuancerede svar.
Den tredje mekanisme er forespørgselsudvidelse, som indebærer at generere yderligere forespørgsler for at forbedre søgeydelsen. Ifølge forskning fra Kopp Online Marketing SEO Research Suite anvender forespørgselsudvidelse flere metoder: historisk dataanalyse (undersøgelse af tidligere forespørgselsforfininger i brugersøgehistorikker), n-gram-udskiftning (modificering af forespørgsler ved at udskifte sammenhængende sekvenser af termer), entitetsassociation (identifikation af entiteter fra søgeresultater og kombination med de oprindelige forespørgselsudtryk) og sibling query-identifikation (finde relaterede forespørgsler, der deler fælles overordnede forespørgsler). Disse udvidelsesteknikker sikrer, at systemet undersøger flere vinkler og perspektiver på brugerens informationsbehov.
Den fjerde mekanisme er feedbacksløjfer og kontinuerlig forbedring, hvor brugerinteraktioner med søgeresultater informerer forfiningsprocessen. Når brugere klikker på bestemte resultater, bruger tid på særlige sider eller omformulerer deres forespørgsler, indgår disse data i systemet for at forbedre fremtidige forfininger. Reinforcement learning kan anvendes til at optimere generative modeller, så kvaliteten af forespørgselsvarianter forbedres over tid på baggrund af tilfredsstillende svar. Dette skaber en positiv spiral, hvor hver brugerinteraktion gør systemet klogere og mere effektivt til at forfine forespørgsler.
| Aspekt | Google AI Overviews | ChatGPT | Perplexity | Claude |
|---|---|---|---|---|
| Primær forfiningsmetode | Query fan-out med tematisk søgning | Samtale-baseret flertrinsforfining | Interaktive forespørgselsforslag med opfølgninger | Kontekstuel præcisering via dialog |
| Underforespørgselsgenerering | Automatisk opdeling baseret på intention | Bruger-guidet gennem samtale | Foreslåede forfininger vist som piller | Implicit via kontekstforståelse |
| Datakilder | Levende web, vidensgrafer, shoppinggrafer | Træningsdata + web-søgning (med plugins) | Realtidssøgning på tværs af flere kilder | Træningsdata med web-søgefunktion |
| Citeringsmekanisme | Direkte kildehenvisning i oversigt | Linkreferencer i svar | Kildekort med detaljeret attribution | Inline-citationer med kilde-links |
| Brugerkontrol | Begrænset (systemstyret forfining) | Høj (brugeren styrer samtalen) | Medium (foreslåede forfininger + brugerinput) | Høj (brugeren kan anmode om specifikke forfininger) |
| Forfiningssynlighed | Implicit (brugeren ser syntetiseret svar) | Eksplicit (brugeren ser samtalehistorik) | Eksplicit (forfiningsforslag synlige) | Implicit (forfining via dialog) |
| Hastighed af forfining | Øjeblikkelig (parallel behandling) | Sekventiel (tur-for-tur) | Øjeblikkelig (realtidssøgning) | Sekventiel (samtalebaseret) |
| Personalisering | Høj (baseret på søgehistorik & lokation) | Medium (baseret på samtalekontekst) | Medium (baseret på sessionsdata) | Medium (baseret på samtalekontekst) |
Processen for forespørgselsforfining i nutidens AI-søgemaskiner følger et sofistikeret, flertrins workflow, der adskiller sig markant fra traditionel søgning. Når en bruger indsender en forespørgsel til et system som Google AI Mode eller ChatGPT, søger systemet ikke straks efter resultater. I stedet analyserer det først forespørgslen ved hjælp af avanceret naturlig sprogbehandling for at forstå, hvad brugeren i virkeligheden spørger om. Analysen tager højde for faktorer som brugerens søgehistorik, lokation, enhedstype og forespørgslens kompleksitet. Systemet vurderer, om forespørgslen er ligetil (kræver simpel nøgleords-matchning) eller kompleks (kræver opdeling og multisource-syntese).
For komplekse forespørgsler aktiverer systemet query fan-out-processen. Dette indebærer at opdele den oprindelige forespørgsel i flere relaterede underforespørgsler, der udforsker forskellige aspekter af brugerens informationsbehov. For eksempel, hvis en bruger spørger “Hvordan skal jeg optimere min hjemmeside til AI-søgemaskiner?”, kan systemet generere underforespørgsler som: “Hvad er de vigtigste rangeringsfaktorer for AI-søgemaskiner?”, “Hvordan vurderer AI-systemer indholdskvalitet?”, “Hvad er E-E-A-T, og hvorfor betyder det noget for AI?”, “Hvordan strukturerer jeg indhold for AI-citering?” og “Hvad er best practices for AI-venlig indholdsformatering?”. Hver af disse underforespørgsler eksekveres parallelt på tværs af forskellige datakilder, hvilket indhenter forskelligartet information, der adresserer forskellige aspekter af det oprindelige spørgsmål.
Systemet evaluerer derefter den indhentede information ud fra kvalitetssignaler som domæneautoritet, indholdsaktualitet, tematisk relevans og citeringsmønstre. Information fra flere kilder kombineres og syntetiseres til et sammenhængende, omfattende svar, der direkte adresserer den oprindelige forespørgsel. Gennem hele processen identificerer systemet de mest autoritative og relevante kilder, som derefter præsenteres som citationer eller referencer i det endelige svar. Dette er grunden til, at forståelse af forespørgselsforfining er kritisk for AmICited-brugere—de kilder, der optræder i AI-genererede svar, bestemmes i høj grad af, hvor godt de matcher de forfinede underforespørgsler, AI-systemet genererer.
Forholdet mellem forespørgselsforfining og søgesynlighed i AI Overviews er direkte og målbart. Forskning viser, at over 88 % af søgninger, der udløser AI Overviews, har informationsmæssig intention, hvilket betyder, at brugere søger viden snarere end at foretage et køb eller navigere til en specifik side. Disse informationsforespørgsler er netop dem, der oftest gennemgår omfattende forfining, da de ofte kræver syntese fra flere kilder for at give et fuldstændigt svar. Når dit indhold matcher de forfinede underforespørgsler, et AI-system genererer, har dit website markant større chance for at blive citeret som kilde.
Tallene taler for sig selv: at blive fremhævet som AI Overview-kilde øger klikraten fra 0,6 % til 1,08 %, hvilket næsten fordobler trafikken sammenlignet med kun at optræde i traditionelle søgeresultater under oversigten. Dette gør forståelse af forespørgselsforfining afgørende for moderne SEO-strategi. I stedet for at optimere for et enkelt nøgleord skal indholdsskabere nu overveje, hvordan deres indhold adresserer de forskellige forfinede forespørgsler, et AI-system kan generere. Hvis du for eksempel skriver om “bæredygtig mode”, bør du forudse, at et AI-system kan forfine dette til underforespørgsler om “miljøpåvirkning af fast fashion”, “etiske produktionsmetoder”, “bæredygtige materialer”, “fairtrade-certificeringer” og “prisvenlige bæredygtige mærker”. Dit indhold bør dække disse forfinede vinkler for at maksimere citeringspotentialet.
Derudover indikerer forskning, at ca. 70 % af brugerne kun læser den første tredjedel af AI Overviews, hvilket betyder, at det er betydeligt mere værdifuldt at blive citeret tidligt i svaret end senere. Dette antyder, at indholdsskabere bør strukturere deres information med de mest centrale, opsummerende svar øverst i et klart og citerbart format. Målet er at blive den kilde, AI-systemet “skal” citere for at give et troværdigt, dækkende svar på de forfinede forespørgsler, det genererer.
Effektiv forespørgselsforfining kræver forståelse og implementering af flere centrale teknikker. Den første teknik er tilføjelse af kontekstuelle detaljer, hvor brugere eller systemer tilføjer specifik kontekst for at gøre forespørgsler mere præcise. I stedet for at søge efter “løbesko” kan en forfinet forespørgsel være “bedste vandtætte løbesko til kvinder med høj svang under 1.000 kr.” Denne ekstra kontekst hjælper AI-systemer med at forstå de specifikke begrænsninger og præferencer, der er vigtige for brugeren, hvilket muliggør mere målrettet informationshentning. For indholdsskabere betyder det at forudse disse kontekstuelle forfininger og skabe indhold, der adresserer specifikke brugsscenarier, demografier og begrænsninger.
Den anden teknik er specificering af begrænsninger, hvor brugere definerer grænser eller begrænsninger for deres søgning. Dette kan inkludere prisklasser, geografiske placeringer, tidsrammer eller kvalitetsstandarder. AI-systemer genkender disse begrænsninger og forfiner deres søgning tilsvarende. For eksempel indeholder en forespørgsel om “bedste projektstyringssoftware til fjernteams med færre end 50 ansatte” flere begrænsninger, som bør guide indholdsskabelsen. Dit indhold bør eksplicit adressere disse begrænsningsscenarier for at øge sandsynligheden for at blive citeret.
Den tredje teknik er opfølgende spørgsmål, hvor brugere stiller præciserende spørgsmål for at forfine deres forståelse. I samtale-AI-systemer som ChatGPT kan brugere spørge “Kan du forklare det mere simpelt?” eller “Hvordan gælder det for små virksomheder?” Disse opfølgende spørgsmål udløser forespørgselsforfining, hvor systemet justerer sin tilgang baseret på brugerens feedback. Derfor er samtaledybde og evnen til at adressere flere vinkler på et emne i stigende grad vigtige for indholdssynlighed.
Den fjerde teknik er forespørgselsopdeling, hvor komplekse spørgsmål opdeles i enklere delspørgsmål. Dette er især vigtigt for AI-systemer, der bruger denne teknik til at sikre dækkende behandling af et emne. Hvis en bruger spørger “Hvad er best practices for optimering af e-handelswebsites til AI-søgemaskiner?”, kan et AI-system opdele det i: “Hvad er AI-søgemaskiner?”, “Hvordan rangerer AI-systemer e-handelsindhold?”, “Hvilke tekniske optimeringer er vigtige?”, “Hvordan bør produktbeskrivelser struktureres?” og “Hvilken rolle spiller brugergenereret indhold?” Indhold, der dækkende adresserer disse delspørgsmål, vil have større sandsynlighed for at blive citeret på tværs af flere forfinede forespørgsler.
Generative Engine Optimization (GEO), også kendt som Large Language Model Optimization (LLMO), handler grundlæggende om at forstå og optimere for forespørgselsforfiningsprocesser. Traditionel SEO fokuserede på at rangere på specifikke nøgleord; GEO fokuserer på at blive citeret som kilde på tværs af de forfinede forespørgsler, AI-systemer genererer. Dette repræsenterer et paradigmeskift i, hvordan indholdsskabere bør tilgå søgeoptimering.
I GEO-konteksten er forespørgselsforfining ikke noget, der sker med dit indhold—det er noget, du aktivt skal forudse og forberede dig på. Når du skaber indhold, bør du overveje alle de måder, et AI-system kan forfine eller opdele dit emne i underforespørgsler. Hvis du for eksempel skriver om “bæredygtig mode”, bør du skabe indhold, der adresserer: miljøpåvirkningen fra konventionel mode, bæredygtige materialer og deres egenskaber, etisk produktion og arbejdsforhold, certificeringer og standarder, omkostningsaspekter, mærkeanbefalinger og hvordan man skifter til bæredygtig mode. Ved at adressere disse forfinede vinkler omfattende øger du sandsynligheden for, at dit indhold citeres på tværs af flere AI-genererede svar.
Forskning fra Elementors 2026 AI SEO Statistics viser, at AI-søgetrafik er steget med 527 % år-over-år, og nogle sider rapporterer nu, at over 1 % af alle sessioner kommer fra platforme som ChatGPT, Perplexity og Copilot. Denne eksplosive vækst understreger vigtigheden af at forstå forespørgselsforfining. Trafikken fra AI-platforme er også betydeligt mere værdifuld—AI-henvist trafik er 4,4 gange mere værd end traditionel organisk søgetrafik, med 27 % lavere bounce rate og 38 % længere sessionvarighed for retail-sider. Det betyder, at optimering for forespørgselsforfining ikke kun handler om synlighed; det handler om at drive trafik af høj kvalitet med høj konverteringsrate.
Fremtiden for forespørgselsforfining bevæger sig mod stadig mere sofistikerede, personaliserede og autonome systemer. Syntetisk forespørgselsgenerering bliver mere avanceret, hvor AI-systemer kan generere varierede, kontekstuelt passende forespørgsler, der simulerer reelle brugersøgemønstre. Disse syntetiske forespørgsler er afgørende for at træne AI-systemer til at håndtere nye eller sjældent anvendte forespørgsler ved at udnytte lærte mønstre og kontekstuel information. I takt med at AI-systemer bliver mere avancerede, vil de generere stadig mere nuancerede og specifikke underforespørgsler, hvilket kræver, at indholdsskabere tænker endnu dybere over de mange vinkler og perspektiver på deres emner.
En anden fremvoksende tendens er stateful forespørgselsforfining, hvor AI-systemer bevarer kontekst på tværs af flere samtaleomgange, hvilket muliggør mere sofistikeret forfining baseret på brugerens skiftende behov og præferencer. I stedet for at behandle hver forespørgsel som uafhængig, forstår disse systemer, hvordan forespørgsler relaterer sig til tidligere interaktioner, hvilket muliggør mere personaliserede og kontekstuelt passende forfininger. Dette har betydning for indholdsstrategien—dit indhold bør struktureres til at understøtte flertrins samtaler, hvor brugere gradvist forfiner deres forståelse.
Integrationen af reinforcement learning i forespørgselsforfiningssystemer er også væsentlig. Disse
Forespørgselsforfining fokuserer på at forbedre relevansen og nøjagtigheden af søgeresultater ved at justere eller foreslå forespørgsler baseret på brugerens kontekst og historiske data med det formål at give mere præcis information. Forespørgselsudvidelse handler derimod om at generere yderligere forespørgsler for at forbedre søgemaskinens ydeevne ved at tage fat på problemer som dårligt formulerede indledende forespørgsler eller irrelevante resultater. Mens forfining forbedrer en eksisterende forespørgsel, skaber udvidelse flere relaterede forespørgsler for at udvide søgeomfanget. Begge teknikker arbejder sammen i moderne AI-søgesystemer for at forbedre informationshentningskvaliteten.
AI-søgemaskiner bruger forespørgselsforfining gennem en proces kaldet query fan-out, hvor en enkelt brugerforespørgsel opdeles i flere underforespørgsler, som udføres samtidigt på tværs af forskellige datakilder. For eksempel kan et komplekst spørgsmål som 'bedste vandtætte løbesko til platfodede' opdeles i underforespørgsler, der udforsker produktlister, ekspertanmeldelser, brugeroplevelser og tekniske specifikationer. Denne parallelle indhentning af information fra forskellige kilder udvider informationsmængden betydeligt til svarsyntese, hvilket gør det muligt for AI at give mere omfattende og nøjagtige svar.
Naturlig sprogbehandling er grundlæggende for forespørgselsforfining, da det gør det muligt for AI-systemer at fortolke mening ud over simpel nøgleords-matchning. NLP bruger mønstre og kontekstuelle relationer mellem ord til at afkode, hvordan mennesker taler, hvilket gør søgninger mere intuitive og præcise. For eksempel gør NLP det muligt for systemet at forstå, at 'åbne kaffebarer' betyder virksomheder, der aktuelt har åbent og ligger i nærheden, ikke blot dokumenter med de eksakte ord. Denne kontekstuelle forståelse gør, at moderne AI-systemer kan forfine forespørgsler intelligent og levere resultater, der matcher brugerens intention frem for blot bogstavelige nøgleordstræf.
Forespørgselsforfining forbedrer søgesynligheden i AI Overviews ved at hjælpe indholdsskabere med at forstå, hvordan brugere ændrer deres søgninger for at finde bedre resultater. Ved at målrette både indledende og forfinede forespørgsler med omfattende indhold, der forudser brugerbehov og opfølgende spørgsmål, kan hjemmesider øge deres chancer for at blive citeret som kilder. Forskning viser, at det at blive fremhævet som en AI Overview-kilde øger klikraten fra 0,6 % til 1,08 %, hvilket gør forståelsen af forespørgselsforfining afgørende for moderne SEO-strategi og AI-citeringssynlighed.
Syntetiske forespørgsler er kunstigt genererede forespørgsler skabt af store sprogmodeller, der simulerer reelle brugersøgeforespørgsler. De er afgørende for forespørgselsforfining, fordi de udvider mærkede træningsdata, forbedrer recall og gør det muligt for generativ hentning at skalere til store datasæt ved at udfylde datamangler. Syntetiske forespørgsler genereres gennem minedrift af strukturerede data, analyse af dokumenttitler og ankertekster samt brug af strukturerede regelsæt. De hjælper AI-systemer med at forstå og forfine forespørgsler ved at give forskellige eksempler på, hvordan brugere kan formulere lignende informationsbehov, hvilket i sidste ende forbedrer systemets evne til effektivt at forfine og udvide brugerforespørgsler.
Virksomheder kan optimere for forespørgselsforfining ved at analysere Google Search Console-data for at identificere relaterede nøgleord og forespørgselsvarianter, som brugere søger efter i rækkefølge. De bør skabe omfattende indhold, der adresserer både indledende brede forespørgsler og forfinede, specifikke varianter. Ved at bruge værktøjer som seoClarity eller lignende platforme kan virksomheder udtrække forespørgselsforfininger og autosuggest-data for at finde relevante forespørgselsvarianter til nøgleordsforskning. Derudover hjælper overvågning af placeringer efter forespørgselsforfining og sporing af, hvordan forskellige facetterede sider klarer sig, med at drive beslutninger om indholdsstrategi og teknisk implementering.
Forespørgselsforfining er tæt forbundet med brugerintention, fordi det afslører, hvordan brugeres informationsbehov udvikler sig gennem deres søgeforløb. Ved at analysere mønstre i forespørgselsforfining kan virksomheder forstå, hvad brugere egentlig leder efter på hvert trin af deres beslutningsproces. For eksempel kan en bruger starte med bred intention ('løbesko') og gradvist forfine til mere specifik intention ('bedste vandtætte løbesko til platfodede'). Forståelse af disse forfiningsmønstre gør det muligt for indholdsskabere at udvikle målrettet indhold til hvert trin i brugerrejsen, hvilket i sidste ende forbedrer både søgesynlighed og konverteringsrater.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær hvordan forespørgselsreformulering hjælper AI-systemer med at fortolke og forbedre brugerforespørgsler for bedre informationssøgning. Forstå teknikkerne, fo...
Lær hvad søgeforslag og autofuldførelsesanbefalinger er, hvordan de fungerer ved brug af AI og maskinlæring, og deres indvirkning på brandets synlighed, brugero...
Lær, hvordan optimering af forespørgselsudvidelse forbedrer AI-søgeresultater ved at bygge bro over ordforrådsgab. Opdag teknikker, udfordringer og hvorfor det ...