
Original Research - Førstepartsdata og undersøgelser
Original forskning og førstepartsdata er proprietære undersøgelser og kundeoplysninger indsamlet direkte af brands. Lær hvordan de opbygger autoritet, driver AI...
11 min læsning

Sekundær forskning er analysen og fortolkningen af eksisterende data, der tidligere er indsamlet af andre forskere eller organisationer til andre formål. Det indebærer at syntetisere publicerede datasæt, rapporter, akademiske tidsskrifter og andre kilder for at besvare nye forskningsspørgsmål eller validere hypoteser uden at gennemføre original dataindsamling.
Sekundær forskning er analysen og fortolkningen af eksisterende data, der tidligere er indsamlet af andre forskere eller organisationer til andre formål. Det indebærer at syntetisere publicerede datasæt, rapporter, akademiske tidsskrifter og andre kilder for at besvare nye forskningsspørgsmål eller validere hypoteser uden at gennemføre original dataindsamling.
Sekundær forskning, også kendt som skrivebordsforskning, er en systematisk forskningsmetode, der involverer analyse, syntese og fortolkning af eksisterende data, som tidligere er indsamlet af andre forskere, organisationer eller institutioner til andre formål. I stedet for at indsamle originale data gennem spørgeskemaer, interviews eller eksperimenter benytter sekundær forskning publicerede datasæt, rapporter, akademiske tidsskrifter, statslige statistikker og andre sammenstillede informationskilder til at besvare nye forskningsspørgsmål eller validere hypoteser. Denne tilgang repræsenterer et fundamentalt skifte fra dataindsamling til dataanalyse og fortolkning, hvilket gør det muligt for organisationer at udlede handlingsorienterede indsigter fra information, der allerede findes i det offentlige domæne eller i organisationsarkiver. Betegnelsen “sekundær” refererer til, at forskere arbejder med data, der er sekundære i forhold til det oprindelige indsamlingsformål—data, der oprindeligt blev indsamlet til ét formål, genanalyseres for at adressere andre forskningsspørgsmål eller forretningsmæssige udfordringer.
Praksis med sekundær forskning har udviklet sig markant gennem det seneste århundrede og er gået fra litteraturgennemgange på fysiske biblioteker til sofistikeret digital dataanalyse. Historisk set var forskere afhængige af fysiske biblioteker, arkiver og trykte materialer til at udføre sekundær analyse, hvilket var en tidskrævende proces, der begrænsede forskningsomfang og tilgængelighed. Den digitale revolution ændrede fundamentalt sekundær forskning ved at gøre enorme datasæt øjeblikkeligt tilgængelige gennem online databaser, statslige portaler og akademiske arkiver. I dag genererer den globale markedsundersøgelsesindustri 140 milliarder dollars i årlig omsætning fra 2024, hvor sekundær forskning udgør en betydelig del af dette marked. Vækstkurven er bemærkelsesværdig—branchen voksede fra 102 milliarder dollars i 2021 til 140 milliarder dollars i 2024, hvilket svarer til en stigning på 37,25% på kun tre år. Denne ekspansion afspejler organisationers stigende afhængighed af databaseret beslutningstagning og erkendelsen af, at sekundær forskning giver omkostningseffektive veje til markedsindsigt. Fremkomsten af AI-drevne dataanalyseværktøjer har yderligere revolutioneret sekundær forskning og gør det muligt for forskere at behandle enorme datasæt, identificere mønstre og udlede indsigter med hidtil uset hastighed. Ifølge nyeste forskning har 69% af markedsanalysefolk integreret syntetiske data og AI-analyse i deres sekundære forskningsindsats, hvilket demonstrerer feltets hurtige teknologiske udvikling.
Sekundære forskningsdata stammer fra to hovedkategorier: interne kilder og eksterne kilder. Interne sekundære data omfatter information, der allerede er indsamlet og gemt i en organisation, såsom salgsdatabaser, kundetransaktionshistorik, tidligere forskningsprojekter, kampagnepræstationsmålinger og webanalyse. Disse interne data giver konkurrencemæssige fordele, da de forbliver eksklusive for organisationen og afspejler faktisk forretningspræstation. Eksterne sekundære data omfatter offentligt tilgængelig eller købt information fra statslige myndigheder, akademiske institutioner, markedsanalysefirmaer, brancheforeninger og medier. Statslige kilder leverer folketællingsdata, økonomisk statistik og reguleringsinformation; akademiske kilder tilbyder peer-reviewet forskning og longitudinelle studier; markedsanalysebureauer offentliggør branchespecifikke rapporter og konkurrenceanalyser; og brancheforeninger sammenstiller sektorspecifikke data og trends. Mangfoldigheden af sekundære kilder muliggør, at forskere kan triangulere resultater på tværs af flere perspektiver og validere konklusioner gennem krydskilde-verificering.
| Aspekt | Sekundær forskning | Primær forskning |
|---|---|---|
| Dataindsamling | Analyserer eksisterende data indsamlet af andre | Indsamler originale data direkte fra kilder |
| Tidslinje | Dage til uger | Uger til måneder |
| Omkostning | Lav til minimal (ofte gratis) | Høj (deltagerrekruttering, administration) |
| Datakontrol | Ingen kontrol over metode eller kvalitet | Fuld kontrol over forskningsdesign og udførelse |
| Specificitet | Adresserer måske ikke specifikke forskningsspørgsmål | Skræddersyet til præcise forskningsmål |
| Forskerbias | Ukendt bias fra oprindelige indsamler(e) | Potentiel bias fra nuværende forskere |
| Dataeksklusivitet | Ikke-eksklusiv (konkurrenter har adgang til samme data) | Eksklusivt ejerskab af resultater |
| Stikprøvestørrelse | Ofte store datasæt | Varierer efter budget og omfang |
| Relevans | Kan kræve tilpasning til nuværende behov | Direkte relevant for aktuelle forskningsmål |
| Hastighed til indsigt | Øjeblikkelig adgang til sammenstillede informationer | Kræver tid til dataindsamling og analyse |
Metodologien for sekundær forskning følger en struktureret femtrinsproces, der sikrer grundig analyse og valide konklusioner. Det første trin består i klart at definere forskningsemnet og identificere specifikke forskningsspørgsmål, som sekundære data kan besvare. Forskere skal tydeligt formulere målet—om det er eksplorativt (forstå, hvorfor noget skete) eller bekræftende (validere hypoteser). Andet trin kræver identificering og lokalisering af passende sekundære datakilder under hensyntagen til datarelevans, kilde-troværdighed, udgivelsesdato og geografisk rækkevidde. Tredje trin indebærer systematisk indsamling og organisering af data, ofte ved at få adgang til flere databaser, verificere kildens ægthed og samle information i analyserbare formater. I denne fase skal forskeren vurdere datakvalitet, vurdere metodetransparens og afgøre, om dataindsamlingsperioden matcher forskningsbehovene. Fjerde trin har fokus på at kombinere og sammenligne datasæt, identificere mønstre på tværs af forskellige kilder og genkende trends eller afvigelser, der fremkommer ved sammenlignende analyse. Forskere kan være nødt til at filtrere ubrugelige data, forene modstridende oplysninger og organisere resultater i sammenhængende fortællinger. Det sidste trin består af en omfattende analyse og fortolkning, hvor forskeren vurderer, om sekundære data tilstrækkeligt besvarer de oprindelige forskningsspørgsmål, identificerer videnshuller og vurderer, om supplerende primær forskning er nødvendig. Denne strukturerede tilgang sikrer, at sekundær forskning fører til troværdige, handlingsorienterede indsigter i stedet for overfladiske konklusioner.
En af de mest overbevisende fordele ved sekundær forskning er dens markante omkostningseffektivitet sammenlignet med primære forskningsmetoder. Analyse af sekundære data er næsten altid billigere end at gennemføre primær forskning, og organisationer sparer typisk 50-70% på forskningsbudgetter ved at udnytte eksisterende datasæt. Da dataindsamling udgør den dyreste komponent i primær forskning—herunder deltagerrekruttering, incitamenter, spørgeskemaadministration og feltarbejde—eliminerer sekundær forskning disse betydelige udgifter fuldstændigt. De fleste sekundære datakilder er gratis tilgængelige via statslige institutioner, offentlige biblioteker og akademiske arkiver eller kan erhverves til minimal pris via abonnementstjenester. Tidsbesparelsen er lige så væsentlig: sekundær forskning kan gennemføres på dage eller uger, mens primær forskning typisk kræver uger til måneder. Forskere kan få adgang til sammenstillede datasæt med det samme via online platforme, hvilket muliggør hurtig beslutningstagning ved tidsfølsomme forretningsudfordringer. Derudover er sekundære data typisk forbehandlet og organiseret digitalt, hvilket eliminerer den arbejdsintensive datapreparation, der kræver betydelige ressourcer i primær forskning. For organisationer med begrænsede budgetter eller stramme tidsplaner giver sekundær forskning en tilgængelig vej til markedsindsigt, konkurrenceintelligens og trendanalyse. Den globale markedsundersøgelsesindustris vækst til 140 milliarder dollars afspejler øget investering i forskning, hvor sekundær forskning udgør en omkostningseffektiv komponent i omfattende forskningsstrategier.
I sammenhæng med AI-overvågning og generativ engine-optimering spiller sekundær forskning en afgørende rolle med at etablere udgangspunkter og forstå, hvordan AI-systemer citerer kilder. Platforme som AmICited udnytter principper fra sekundær forskning til at spore brandomtaler på tværs af AI-systemer, herunder ChatGPT, Perplexity, Google AI Overviews og Claude. Ved at analysere eksisterende data om konkurrentcitater, branchetrends og historisk brandperformance i AI-svar kan organisationer identificere mønstre i, hvordan AI-systemer vælger og citerer kilder. Sekundær forskning hjælper med at etablere benchmarks for AI-synlighed, så brands kan forstå deres nuværende position i forhold til konkurrenter og branchestandarder. Organisationer kan analysere sekundære data om indholdsperformance, citeringsmønstre og AI-systempræferencer for at optimere deres indholdsstrategi for bedre AI-citater. Denne integration af sekundær forskning med AI-overvågning giver en omfattende forståelse af, hvordan brands optræder i generative søgeresultater og AI-drevne svar. Analysen af eksisterende citeringsdata, konkurrentstrategier og branchetrends giver kontekst til fortolkning af realtids AI-overvågningsdata og muliggør mere sofistikerede optimeringsstrategier. Da 47% af forskere verden over regelmæssigt bruger AI i deres markedsanalyseaktiviteter, omformer sammenfletningen af sekundær forskningsmetode og AI-drevne analyseværktøjer, hvordan organisationer forstår deres markedsposition og AI-synlighed.
Sikring af datakvalitet i sekundær forskning kræver grundige valideringsprocesser og kritisk vurdering af kilders troværdighed. Forskere skal undersøge den oprindelige forskningsmetode, herunder stikprøvestørrelse, populationskarakteristika, dataindsamlingsprocedurer og potentielle bias, der kan have påvirket resultaterne. Peer-reviewede akademiske tidsskrifter opretholder højere troværdighedsstandarder end blogs eller meningsindlæg, da de gennemgår ekspertvurdering før offentliggørelse. Statslige myndigheder og etablerede forskningsinstitutioner har typisk strenge kvalitetskontroller, hvilket gør deres data mere pålidelige end selvudgivne kilder. Krydsreferering af resultater på tværs af flere uafhængige kilder hjælper med at validere konklusioner og identificere uoverensstemmelser, der kan indikere datakvalitetsproblemer. Forskere skal vurdere, om det oprindelige studies tidsramme passer til aktuelle forskningsbehov, da data indsamlet for fem år siden måske ikke afspejler nuværende markedsforhold eller forbrugeradfærd. Udgivelsesdatoen er kritisk—sekundære data bliver mindre relevante over tid, især i brancher med hurtige markedsændringer. Forskere bør også overveje, om den oprindelige dataindsamlingsmetode matcher deres forskningskrav, da forskellige metoder kan give ikke-sammenlignelige resultater. Kontakt til de oprindelige forskere eller organisationer kan give yderligere kontekst om dataindsamlingsprocesser, svarprocenter og eventuelle kendte begrænsninger. Denne omfattende valideringsmetode sikrer, at konklusioner fra sekundær forskning bygger på troværdige, højtkvalitetsdata frem for potentielt fejlbehæftet eller forældet information.
Sekundær forskning byder på adskillige strategiske fordele, der gør den til en uundværlig del af omfattende forskningsprogrammer. Let tilgængelige data kan hurtigt findes gennem online databaser, biblioteker og statslige portaler og kræver minimal teknisk ekspertise at lokalisere. Den hurtigere forskningsproces gør det muligt for organisationer at besvare forskningsspørgsmål på dage frem for måneder og understøtter hurtige beslutninger og konkurrenceevne. Lave omkostninger gør sekundær forskning tilgængelig for organisationer med begrænsede forskningsbudgetter og demokratiserer adgang til markedsindsigt. Sekundær forskning kan inspirere yderligere forskningsaktiviteter ved at identificere videnshuller, der kræver primær forskning, og fungere som fundament for mere målrettede studier. Muligheden for at skalere resultater hurtigt ved hjælp af store datasæt som folketællingsdata gør det muligt for forskere at drage konklusioner om brede populationer uden dyre, store spørgeskemaundersøgelser. Sekundær forskning giver forindsigt, der hjælper organisationer med at afgøre, om yderligere forskning overhovedet er nødvendig, og kan spare ressourcer ved at identificere, at svar allerede findes i eksisterende litteratur. Databredde og -dybde gør det muligt for forskere at undersøge trends over flere år, identificere mønstre og forstå historisk kontekst, der informerer nuværende beslutninger. Organisationer kan udnytte konkurrencefordele ved at have adgang til interne sekundære data, som konkurrenter ikke kan opnå, hvilket giver unikke indsigter i organisationspræstation og markedsposition.
På trods af fordelene har sekundær forskning betydelige begrænsninger, som forskere nøje må overveje. Forældede data er en primær bekymring, da sekundære kilder måske ikke afspejler aktuelle markedsforhold, forbrugerpræferencer eller teknologiske ændringer. I hurtige brancher kan sekundære data blive forældet inden for måneder, og forskere skal sikre sig, at informationen stadig er relevant. Manglende kontrol over metode betyder, at forskeren ikke kan verificere, hvordan oprindelige data blev indsamlet, om kvalitetsstandarder blev overholdt, eller om ukendte bias påvirkede resultaterne. Manglende mulighed for at tilpasse data til specifikke forskningsspørgsmål kræver ofte, at forskeren tilpasser sine mål til tilgængelig information, frem for at finde data, der perfekt adresserer behovet. Ikke-eksklusiv adgang til data betyder, at konkurrenter kan få adgang til de samme sekundære kilder, hvilket eliminerer konkurrencemæssige fordele, som primær forskning kan give. Ukendt forskerbias fra de oprindelige dataindsamlere kan have påvirket resultaterne på måder, som nuværende forskere ikke kan detektere eller korrigere. Relevansgab i data kan nødvendiggøre, at forskeren supplerer sekundære fund med primær forskning for at adressere specifikke spørgsmål. Kompleksitet i dataintegration, når flere sekundære kilder med forskellige metoder, tidsrammer og populationer kombineres, kan give analytiske udfordringer. Forskere skal investere betydelig indsats i datavalidering og verifikation for at sikre, at sekundære kilder lever op til kvalitetsstandarder og giver pålidelige indsigter.
Fremtiden for sekundær forskning bliver fundamentalt omformet af kunstig intelligens, maskinlæring og avancerede analyseteknologier. AI-drevne værktøjer gør det nu muligt for forskere at behandle enorme datasæt, identificere komplekse mønstre og udlede indsigter, som ville være umulige at opdage manuelt. 83% af markedsanalysefolk planlægger at investere i AI til deres forskningsaktiviteter i 2025, hvilket indikerer bred anerkendelse af AI’s transformerende potentiale. Integrationen af syntetiske data i sekundær forskning accelererer, hvor over 70% af markedsforskere forventer, at syntetiske data vil udgøre mere end 50% af dataindsamlingen inden for tre år. Dette skift afspejler den voksende betydning af AI-genererede indsigter og behovet for at supplere traditionelle sekundære kilder med algoritmisk genererede data. Automatiseret indholdsanalyse ved brug af natural language processing gør det muligt at analysere kvalitative sekundære kilder i stor skala og identificere temaer, stemning og semantiske relationer på tværs af tusindvis af dokumenter. Sammenfletningen af sekundær forskning med generative engine optimization (GEO)-strategier skaber nye muligheder for organisationer i forhold til at forstå, hvordan AI-systemer citerer og refererer kilder. Efterhånden som AI-systemer som ChatGPT, Perplexity og Claude bliver primære informationskilder for forbrugere, udvikler sekundære forskningsmetoder sig til at analysere, hvordan disse systemer udvælger, citerer og præsenterer information. Organisationer bruger i stigende grad sekundær forskning til at etablere udgangspunkter for AI-synlighed og forstå, hvordan deres brands fremtræder i AI-genererede svar sammenlignet med konkurrenter. Fremtiden vil sandsynligvis byde på, at sekundær forskning bliver mere sofistikeret, realtidsorienteret og integreret med AI-overvågningsplatforme, der sporer brandomtaler på tværs af flere AI-systemer samtidigt. Denne udvikling repræsenterer et fundamentalt skifte fra historisk sekundær forskning til dynamisk, AI-forstærket analyse, der løbende giver indsigter i markedsposition, konkurrentlandskab og AI-synlighed.
Organisationer, der ønsker at maksimere effektiviteten af sekundær forskning, bør anvende strukturerede bedste praksisser, der sikrer grundig analyse og handlingsorienterede indsigter. Definer klare forskningsmål før start af sekundær forskning ved at formulere specifikke spørgsmål, som sekundære data kan besvare, og fastlægge succeskriterier for projektet. Prioriter kildetroværdighed ved at foretrække peer-reviewede akademiske kilder, statslige institutioner og veletablerede forskningsorganisationer frem for selvpublicerede eller biased kilder. Etabler verifikationsprotokoller, der kræver krydsreferering af fund på tværs af flere uafhængige kilder, før der drages konklusioner. Dokumenter metode ved at registrere, hvilke kilder der blev konsulteret, hvordan data blev analyseret, og hvilke begrænsninger eller bias der kan have påvirket resultaterne. Vurder datatidssvarighed ved at sikre, at sekundære data afspejler aktuelle markedsforhold og ikke er blevet forældet på grund af hurtige brancheændringer. Kombinér med primær forskning, når sekundære data ikke besvarer specifikke forskningsspørgsmål, eller når validering af sekundære fund er nødvendig. Udnyt interne data ved at gennemføre grundige audits af organisatoriske databaser og tidligere forskningsprojekter, før der søges efter eksterne sekundære kilder. Brug AI-drevne analyseværktøjer til effektivt at behandle store sekundære datasæt og identificere mønstre, som manuel analyse måske overser. Overvåg AI-synlighed ved at integrere indsigter fra sekundær forskning med AI-overvågningsplatforme som AmICited for at forstå, hvordan brands fremstår i AI-genererede svar. Etabler opdateringsplaner for sekundære forskningsprojekter, da markedsforhold ændres, og periodisk re-analyse kan være nødvendig for at opretholde indsigtens nøjagtighed.
Sekundær forskning forbliver en afgørende metode for organisationer, der søger omkostningseffektive, hurtige indsigter i markedsforhold, konkurrentlandskab og forbrugertrends. Efterhånden som den globale markedsanalyseindustri fortsætter sin vækst—fra 102 milliarder dollars i 2021 til 140 milliarder dollars i 2024—udgør sekundær forskning en stadig vigtigere del af omfattende forskningsstrategier. Integrationen af AI og maskinlæringsteknologier transformerer sekundær forskning fra en manuel, tidskrævende proces til en automatiseret, sofistikeret analytisk disciplin, der kan behandle enorme datasæt og identificere komplekse mønstre. Organisationer, der mestrer sekundær forskningsmetode, opnår væsentlige konkurrencefordele, hvilket muliggør hurtig beslutningstagning, omkostningseffektiv markedsanalyse og informeret strategisk planlægning. Fremkomsten af AI-overvågningsplatforme som AmICited demonstrerer, hvordan principperne bag sekundær forskning udvikler sig for at adressere nye udfordringer i den generative AI-æra, hvor forståelse af, hvordan AI-systemer citerer og refererer kilder, er blevet kritisk for brandsynlighed og markedspositionering. Da 47% af forskere globalt nu regelmæssigt bruger AI i deres markedsanalyseaktiviteter, ligger fremtiden for sekundær forskning i en sofistikeret integration af traditionelle forskningsmetoder med banebrydende AI-funktioner. Organisationer, der kombinerer grundige sekundære forskningspraksisser med AI-drevne analyseværktøjer, realtids-overvågningsplatforme og strategiske valideringsprotokoller, vil være bedst positioneret til at udnytte eksisterende data optimalt og samtidig bevare den troværdighed og nøjagtighed, der er nødvendig for sikker beslutningstagning i et stadig mere komplekst, AI-drevet erhvervsmiljø.
Primær forskning indebærer indsamling af originale data direkte fra kilder gennem spørgeskemaer, interviews eller observationer, mens sekundær forskning analyserer eksisterende data, der tidligere er indsamlet af andre. Primær forskning er mere tidskrævende og dyrere, men giver skræddersyede indsigter, mens sekundær forskning er hurtigere og mere omkostningseffektiv, men måske ikke præcist adresserer specifikke forskningsspørgsmål. Begge metoder kombineres ofte for omfattende forskningsstrategier.
Sekundære forskningskilder omfatter statslig statistik og folketællingsdata, akademiske tidsskrifter og peer-reviewede publikationer, markedsundersøgelsesrapporter fra professionelle bureauer, virksomhedsrapporter og white papers, brancheforeningsdata, nyhedsarkiver og mediepublikationer samt interne organisatoriske databaser. Disse kilder kan være interne (fra din egen organisation) eller eksterne (offentligt tilgængelige eller købt fra tredjeparter). Valget af kilde afhænger af forskningsmål, datarelevans og troværdighedskrav.
Sekundær forskning eliminerer udgifter til dataindsamling, da information allerede er blevet indsamlet og sammenstillet af andre. Forskere undgår omkostninger forbundet med rekruttering af deltagere, gennemførelse af spørgeskemaer eller interviews og håndtering af feltarbejde. Derudover er sekundære data ofte tilgængelige gratis eller til minimal pris via offentlige databaser, biblioteker og statslige institutioner. Organisationer kan spare 50-70% på forskningsbudgetter ved at udnytte eksisterende datasæt, hvilket gør det ideelt for teams med begrænsede ressourcer.
Sekundære forskningsdata kan være forældede og muligvis mangle nylige markedsændringer eller trends. Den oprindelige dataindsamlingsmetode er ukendt, hvilket rejser spørgsmål om datakvalitet og validitet. Forskere har ingen kontrol over, hvordan data blev indsamlet, hvilket potentielt kan introducere ukendte bias. Sekundære datasæt adresserer måske ikke præcist specifikke forskningsspørgsmål, hvilket kræver, at forskerne tilpasser deres mål. Derudover mangler sekundære data eksklusivitet, hvilket betyder, at konkurrenter kan få adgang til de samme oplysninger.
Organisationer bør undersøge den oprindelige forskningsmetode, udgivelsesdato og kildens omdømme, før de bruger sekundære data. Peer-reviewede akademiske tidsskrifter og statslige institutioner har typisk højere troværdighedsstandarder end blogs eller meningsindlæg. Krydsreferering af data på tværs af flere uafhængige kilder hjælper med at validere fund og identificere uoverensstemmelser. Forskere bør vurdere, om det oprindelige studies stikprøvestørrelse, population og forskningsdesign matcher deres behov. Kontakt til oprindelige forskere eller organisationer kan give yderligere kontekst om dataindsamlingsprocesser.
Sekundær forskning giver historisk kontekst og baseline-data til AI-overvågningsplatforme som AmICited, der sporer brandomtaler på tværs af AI-systemer som ChatGPT, Perplexity og Claude. Ved at analysere eksisterende data om konkurrenters omtaler, branchens trends og historisk brandperformance kan organisationer etablere benchmarks for AI-synlighed. Sekundær forskning hjælper med at identificere mønstre i, hvordan AI-systemer citerer kilder, hvilket gør det muligt for brands at optimere deres indholdsstrategi for bedre AI-citater og synlighed i generative søgeresultater.
AI-værktøjer automatiserer nu analyse af sekundære data, hvilket gør det muligt for forskere at behandle store datasæt hurtigere og identificere mønstre, der ville være svære at opdage manuelt. Omkring 47% af forskere globalt bruger regelmæssigt AI i deres markedsundersøgelser, og adoptionsraten når 58% i Asien-Stillehavsområdet. AI-drevne indholdsanalyseværktøjer kan genkende temaer, semantiske forbindelser og relationer i sekundære kilder. 73% af forskere udtrykker dog tillid til brugen af AI i sekundær forskning, mens der stadig er bekymringer om kompetencegab hos nogle teams.
Sekundær forskning kan gennemføres på dage eller uger, da data allerede er indsamlet og organiseret, hvorimod primær forskning typisk kræver uger til måneder til planlægning, dataindsamling og analyse. Organisationer kan få øjeblikkelig adgang til sekundære data gennem online databaser og biblioteker, hvilket muliggør hurtig beslutningstagning. Tidsfordelen gør sekundær forskning ideel til tidssensitive forretningsbeslutninger, konkurrenceanalyse og indledende forskningsfaser. Ulempen er dog, at sekundære data måske ikke giver de specifikke, aktuelle indsigter, som primær forskning leverer.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Original forskning og førstepartsdata er proprietære undersøgelser og kundeoplysninger indsamlet direkte af brands. Lær hvordan de opbygger autoritet, driver AI...
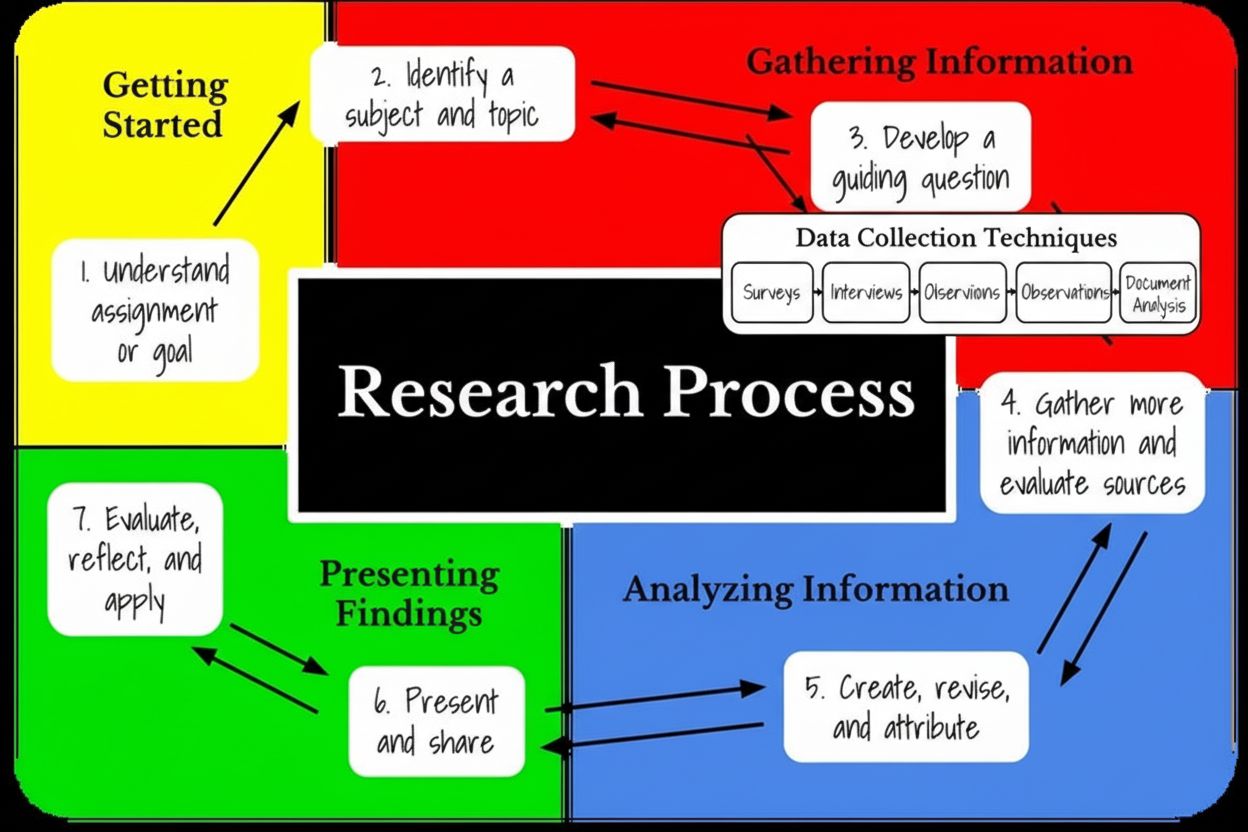
Lær hvad forskningsfasens informationsindsamlingsstadie er, dets betydning i forskningsmetodologi, teknikker til dataindsamling, og hvordan det påvirker AI-over...
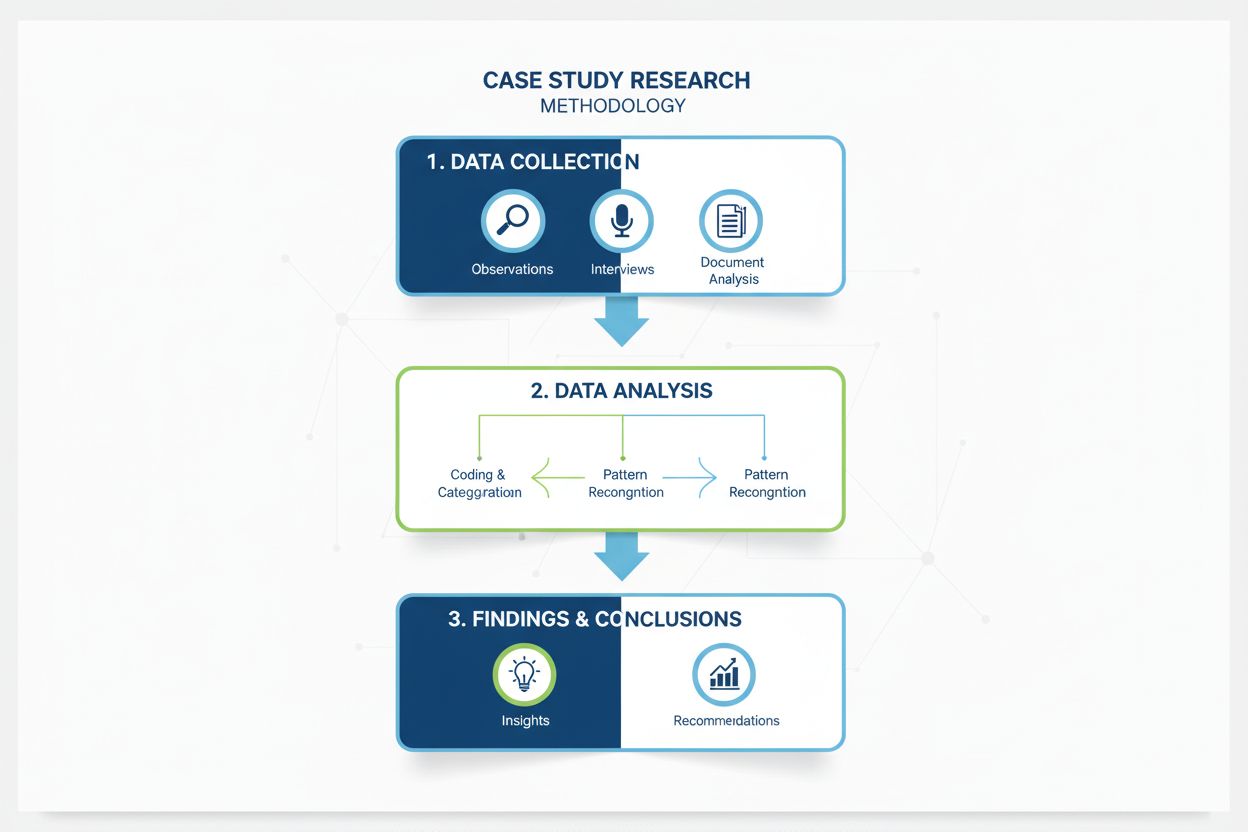
Omfattende definition af casestudieforskningsmetodologi. Lær hvordan casestudier giver dybdegående analyse af specifikke eksempler, dataindsamlingsmetoder og an...