
Træningsdata
Træningsdata er det datasæt, der bruges til at lære ML-modeller mønstre og relationer. Lær, hvordan kvaliteten af træningsdata påvirker AI-modellers ydeevne, nø...
11 min læsning

Træning med syntetiske data er processen med at træne AI-modeller ved hjælp af kunstigt genereret data i stedet for virkelighedstro menneskeskabte informationer. Denne tilgang løser problemer med datascarcity, accelererer modeludvikling og beskytter privatlivets fred, samtidig med at den introducerer udfordringer som modelkollaps og hallucinationer, der kræver omhyggelig håndtering og validering.
Træning med syntetiske data er processen med at træne AI-modeller ved hjælp af kunstigt genereret data i stedet for virkelighedstro menneskeskabte informationer. Denne tilgang løser problemer med datascarcity, accelererer modeludvikling og beskytter privatlivets fred, samtidig med at den introducerer udfordringer som modelkollaps og hallucinationer, der kræver omhyggelig håndtering og validering.
Træning med syntetiske data refererer til processen, hvor kunstige intelligensmodeller trænes ved hjælp af kunstigt genereret data i stedet for virkelighedstro menneskeskabte informationer. I modsætning til traditionel AI-træning, der bygger på autentiske datasæt indsamlet gennem undersøgelser, observationer eller webmining, skabes syntetiske data gennem algoritmer og beregningsmetoder, der lærer statistiske mønstre fra eksisterende data eller genererer helt nye data fra bunden. Dette grundlæggende skift i træningsmetode adresserer en central udfordring i moderne AI-udvikling: Den eksponentielle vækst i computerkrav har overhalet menneskehedens evne til at generere tilstrækkeligt med ægte data, hvor forskning indikerer, at menneskeskabte træningsdata kan være opbrugt inden for de næste par år. Træning med syntetiske data tilbyder et skalerbart, omkostningseffektivt alternativ, der kan genereres uendeligt uden de tidskrævende processer for dataindsamling, mærkning og rengøring, som optager op til 80% af traditionelle AI-udviklingstidslinjer.
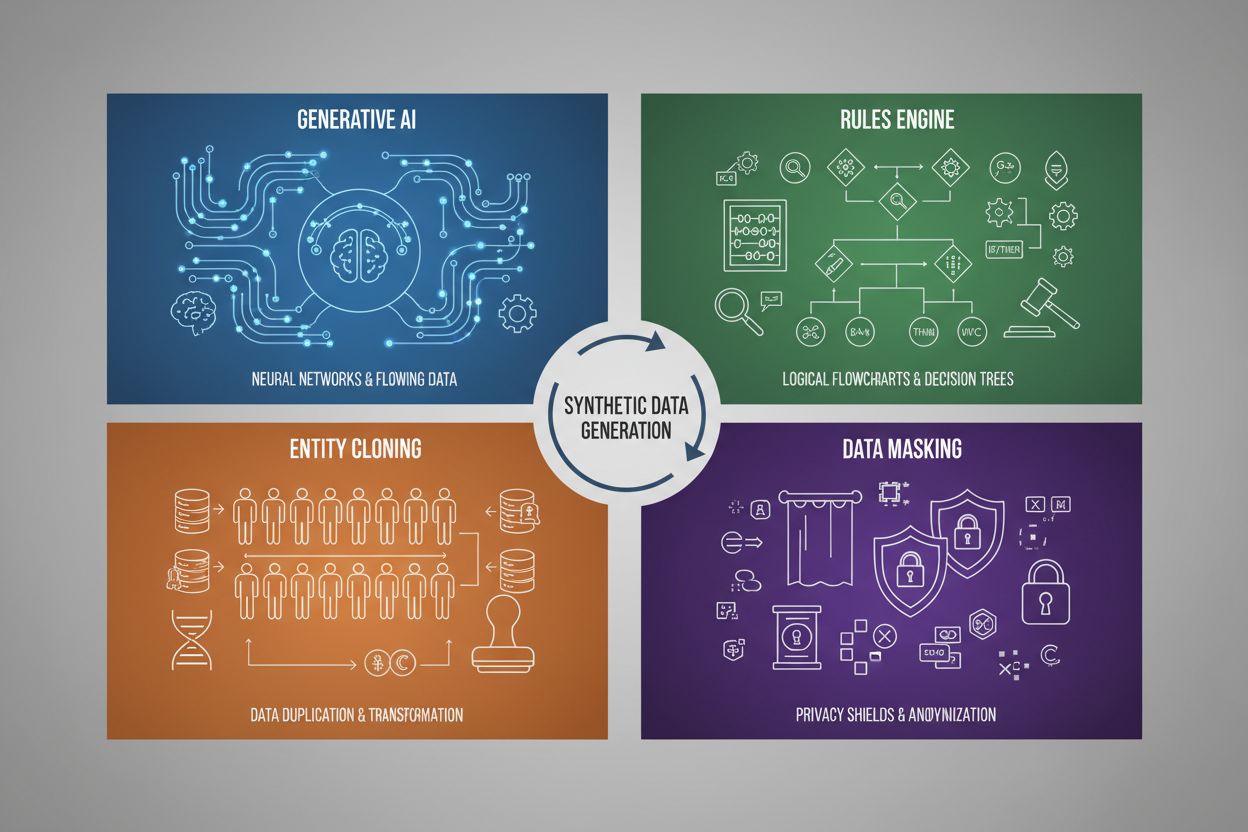
Generering af syntetiske data anvender fire primære teknikker, hver med forskellige mekanismer og anvendelser:
| Teknik | Sådan fungerer det | Anvendelsesområde |
|---|---|---|
| Generativ AI (GANs, VAEs, GPT) | Bruger dybe læringsmodeller til at lære statistiske mønstre og fordelinger fra ægte data og genererer derefter nye syntetiske prøver, der bevarer de samme statistiske egenskaber og relationer. GANs anvender modstridende netværk, hvor en generator skaber falsk data, mens en discriminator vurderer ægtheden, hvilket skaber stadigt mere realistiske resultater. | Træning af store sprogmodeller som ChatGPT, generering af syntetiske billeder med DALL-E, skabelse af mangfoldige tekstdatasæt til opgaver inden for naturlig sprogbehandling |
| Regelmotor | Anvender foruddefinerede logiske regler og begrænsninger til at generere data, der følger specifik forretningslogik, domæneviden eller regulatoriske krav. Denne deterministiske tilgang sikrer, at genereret data overholder kendte mønstre og relationer uden at kræve maskinlæring. | Finansielle transaktionsdata, sundhedsdata med specifikke compliancekrav, produktionssensor-data med kendte driftsparametre |
| Entitetskloning | Duplikerer og ændrer eksisterende ægte dataposter ved at anvende transformationer, forstyrrelser eller variationer for at skabe nye eksemplarer, mens kerne-statistiske egenskaber og relationer bevares. Denne teknik bevarer dataautenticitet, mens datasættets størrelse udvides. | Udvidelse af begrænsede datasæt i regulerede industrier, oprettelse af træningsdata til sjældne sygdomsdiagnoser, forøgelse af datasæt med utilstrækkelige minoritetsklasser |
| Datamaskering & Anonymisering | Skjuler følsomme personhenførbare oplysninger (PII), mens datastruktur og statistiske relationer bibeholdes gennem teknikker som tokenisering, kryptering eller værdierstatning. Dette skaber privatlivsbeskyttende syntetiske versioner af ægte data. | Sundheds- og finansielle datasæt, kundeadfærdsdata, personfølsom information i forskningssammenhænge |
Træning med syntetiske data giver betydelige omkostningsreduktioner ved at eliminere dyre processer for dataindsamling, annotation og rengøring, som traditionelt kræver betydelige ressourcer og tid. Organisationer kan generere ubegrænsede træningsprøver efter behov, hvilket dramatisk accelererer udviklingen af modeller og muliggør hurtig iteration og eksperimentering uden at skulle vente på indsamling af virkelighedsdata. Teknikken giver stærke muligheder for dataforøgelse, så udviklere kan udvide begrænsede datasæt og skabe balancerede træningssæt, der adresserer problemer med skæv fordeling—et kritisk problem, hvor visse kategorier er underrepræsenteret i ægte data. Syntetiske data er særligt værdifulde til at løse datascarcity i specialiserede domæner som medicinsk billeddiagnostik, sjældne sygdomsdiagnoser eller test af autonome køretøjer, hvor det er uforholdsmæssigt dyrt eller etisk udfordrende at indsamle nok virkelighedseksempler. Privatlivsbeskyttelse er en væsentlig fordel, da syntetiske data kan genereres uden at eksponere følsomme personoplysninger, hvilket gør dem ideelle til træning af modeller på sundhedsdata, finansielle data eller andre regulerede informationer. Derudover muliggør syntetiske data systematisk bias-reduktion, fordi udviklere bevidst kan skabe balancerede, mangfoldige datasæt, der modvirker diskriminerende mønstre i virkelighedsdata—eksempelvis ved at generere mangfoldige demografiske repræsentationer i træningsbilleder for at forhindre, at AI-modeller viderefører køns- eller racebaserede stereotyper i ansættelse, långivning eller strafferetlige applikationer.
På trods af potentialet introducerer træning med syntetiske data væsentlige tekniske og praktiske udfordringer, der kan underminere modelpræstation, hvis de ikke håndteres omhyggeligt. Den vigtigste bekymring er modelkollaps, et fænomen hvor AI-modeller, der trænes intensivt på syntetiske data, oplever alvorlig forringelse af outputkvalitet, nøjagtighed og sammenhæng. Dette sker, fordi syntetiske data, selvom de statistisk ligner ægte data, mangler den nuancerede kompleksitet og de ekstreme tilfælde, der findes i autentisk menneskeskabt information—når modeller trænes på AI-genereret indhold, begynder de at forstærke fejl og artefakter, hvilket skaber et voksende problem, hvor hver generation af syntetiske data bliver gradvist lavere kvalitet.
Væsentlige udfordringer inkluderer:
Disse udfordringer understreger, hvorfor syntetiske data alene ikke kan erstatte ægte data—i stedet skal de omhyggeligt integreres som supplement til autentiske datasæt, med grundig kvalitetssikring og menneskelig overvågning gennem hele træningsprocessen.
I takt med at syntetiske data bliver stadig mere udbredte i AI-modellers træning, står brands over for en kritisk ny udfordring: At sikre nøjagtig og gunstig repræsentation i AI-genererede output og citeringer. Når store sprogmodeller og generative AI-systemer trænes på syntetiske data, påvirker kvaliteten og karakteristikaene af disse data direkte, hvordan brands beskrives, anbefales og citeres i AI-søgeresultater, chatbot-svar og automatiseret indholdsgenerering. Dette skaber en væsentlig brandsikkerhedsproblematik, da syntetiske data, der indeholder forældet information, konkurrentbias eller forkerte brandbeskrivelser, kan blive indlejret i AI-modeller og føre til vedvarende fejlrepræsentation på tværs af millioner af brugerinteraktioner. For organisationer, der bruger platforme som AmICited.com til at overvåge deres brandtilstedeværelse i AI-systemer, bliver forståelsen af syntetiske datas rolle i modeltræning afgørende—brands har brug for indsigt i, om AI-citater og omtaler stammer fra ægte træningsdata eller syntetiske kilder, da det påvirker troværdighed og nøjagtighed. Manglen på gennemsigtighed om brugen af syntetiske data i AI-træning skaber ansvarlighedsproblemer: Virksomheder kan ikke nemt afgøre, om deres brandoplysninger er blevet nøjagtigt repræsenteret i syntetiske datasæt, der bruges til at træne modeller, som påvirker forbrugeropfattelsen. Fremadskuende brands bør prioritere AI-overvågning og citationstracking for tidligt at opdage fejlrepræsentationer, arbejde for gennemsigtighedsstandarder, der kræver offentliggørelse af syntetisk dataanvendelse i AI-træning, og samarbejde med platforme, der giver indsigt i, hvordan deres brand fremstår i AI-systemer trænet på både ægte og syntetiske data. I takt med at syntetiske data bliver det dominerende træningsparadigme inden 2030, vil brandovervågning skifte fra traditionel medieovervågning til omfattende AI-citationsintelligens, hvilket gør platforme, der sporer brandrepræsentation på tværs af generative AI-systemer, uundværlige for at beskytte brandets integritet og sikre korrekt brandstemme i det AI-drevne informationsøkosystem.
Traditionel AI-træning er afhængig af virkelige data indsamlet fra mennesker gennem undersøgelser, observationer eller webmining, hvilket er tidskrævende og i stigende grad en mangelvare. Træning med syntetiske data anvender kunstigt genereret data skabt af algoritmer, der lærer statistiske mønstre fra eksisterende data eller genererer helt nye data fra bunden. Syntetiske data kan produceres uendeligt efter behov, hvilket drastisk reducerer udviklingstid og omkostninger samtidig med, at det adresserer privatlivsproblemer.
De fire primære teknikker er: 1) Generativ AI (ved brug af GANs, VAEs eller GPT-modeller til at lære og replikere datamønstre), 2) Regelmotor (anvendelse af foruddefineret forretningslogik og begrænsninger), 3) Entitetskloning (duplikering og ændring af eksisterende poster samtidig med at statistiske egenskaber bevares), og 4) Datamaskering (anonymisering af følsomme oplysninger, mens datastrukturen opretholdes). Hver teknik tjener forskellige anvendelser og har unikke fordele.
Modelkollaps opstår, når AI-modeller, der er trænet intensivt på syntetiske data, oplever kraftig forringelse af outputkvalitet og nøjagtighed. Dette sker, fordi syntetiske data, selvom de er statistisk lignende ægte data, mangler den nuancerede kompleksitet og de ekstreme tilfælde fra autentisk information. Når modeller trænes på AI-genereret indhold, forstærker de fejl og artefakter, hvilket skaber et voksende problem, hvor hver generation bliver gradvist lavere kvalitet og til sidst producerer ubrugelige resultater.
Når AI-modeller trænes på syntetiske data, påvirker kvaliteten og karakteristikaene af disse syntetiske data direkte, hvordan brands bliver beskrevet, anbefalet og citeret i AI-output. Syntetiske data af dårlig kvalitet, der indeholder forældet information eller konkurrentbias, kan blive indlejret i AI-modeller, hvilket fører til vedvarende fejlagtig brandrepræsentation på tværs af millioner af brugerinteraktioner. Dette skaber en brandsikkerhedsudfordring, der kræver overvågning og gennemsigtighed om brugen af syntetiske data i AI-træning.
Nej, syntetiske data bør supplere snarere end erstatte ægte data. Selvom syntetiske data giver væsentlige fordele i forhold til omkostninger, hastighed og privatliv, kan de ikke fuldt ud gengive kompleksiteten, mangfoldigheden og ekstreme tilfælde, der findes i autentiske menneskeskabte data. Den mest effektive tilgang kombinerer syntetiske og ægte data med grundig kvalitetssikring og menneskelig overvågning for at sikre modelnøjagtighed og pålidelighed.
Syntetiske data giver overlegen beskyttelse af privatlivet, fordi de ikke indeholder faktiske værdier fra de oprindelige datasæt og ikke har en-til-en relationer til rigtige personer. I modsætning til traditionelle metoder til datamaskering eller anonymisering, der stadig kan medføre risiko for genidentifikation, skabes syntetiske data helt fra bunden baseret på lærte mønstre. Dette gør dem ideelle til træning af modeller på følsomme oplysninger som sundhedsdata, økonomiske data eller personlige adfærdsoplysninger uden at eksponere rigtige personers data.
Syntetiske data muliggør systematisk reduktion af bias ved at udviklere bevidst kan skabe balancerede, mangfoldige datasæt, der modvirker diskriminerende mønstre i virkelige data. For eksempel kan udviklere generere mangfoldige demografiske repræsentationer i træningsbilleder for at forhindre, at AI-modeller viderefører køns- eller racemæssige stereotyper. Denne mulighed er især værdifuld i applikationer som ansættelse, långivning og strafferetspleje, hvor bias kan have alvorlige konsekvenser.
Efterhånden som syntetiske data bliver det dominerende træningsparadigme inden 2030, skal brands forstå, hvordan deres information repræsenteres i AI-systemer. Kvaliteten af syntetiske data påvirker direkte brandciteringer og omtale i AI-output. Brands bør overvåge deres tilstedeværelse på tværs af AI-systemer, arbejde for gennemsigtighedsstandarder, der kræver offentliggørelse af syntetisk dataanvendelse, og bruge platforme som AmICited.com til at spore brandrepræsentation og opdage fejlrepræsentationer tidligt.
Opdag hvordan dit brand bliver repræsenteret på tværs af AI-systemer trænet på syntetiske data. Spor citeringer, overvåg nøjagtighed, og sikr brandsikkerhed i det AI-drevne informationsøkosystem.
Træningsdata er det datasæt, der bruges til at lære ML-modeller mønstre og relationer. Lær, hvordan kvaliteten af træningsdata påvirker AI-modellers ydeevne, nø...

Komplet guide til at fravælge indsamling af AI-træningsdata på tværs af ChatGPT, Perplexity, LinkedIn og andre platforme. Lær trin-for-trin instruktioner til at...

Sammenlign optimering af træningsdata og realtids-hentningsstrategier for AI. Lær hvornår du skal bruge finjustering vs. RAG, omkostningsimplikationer og hybrid...