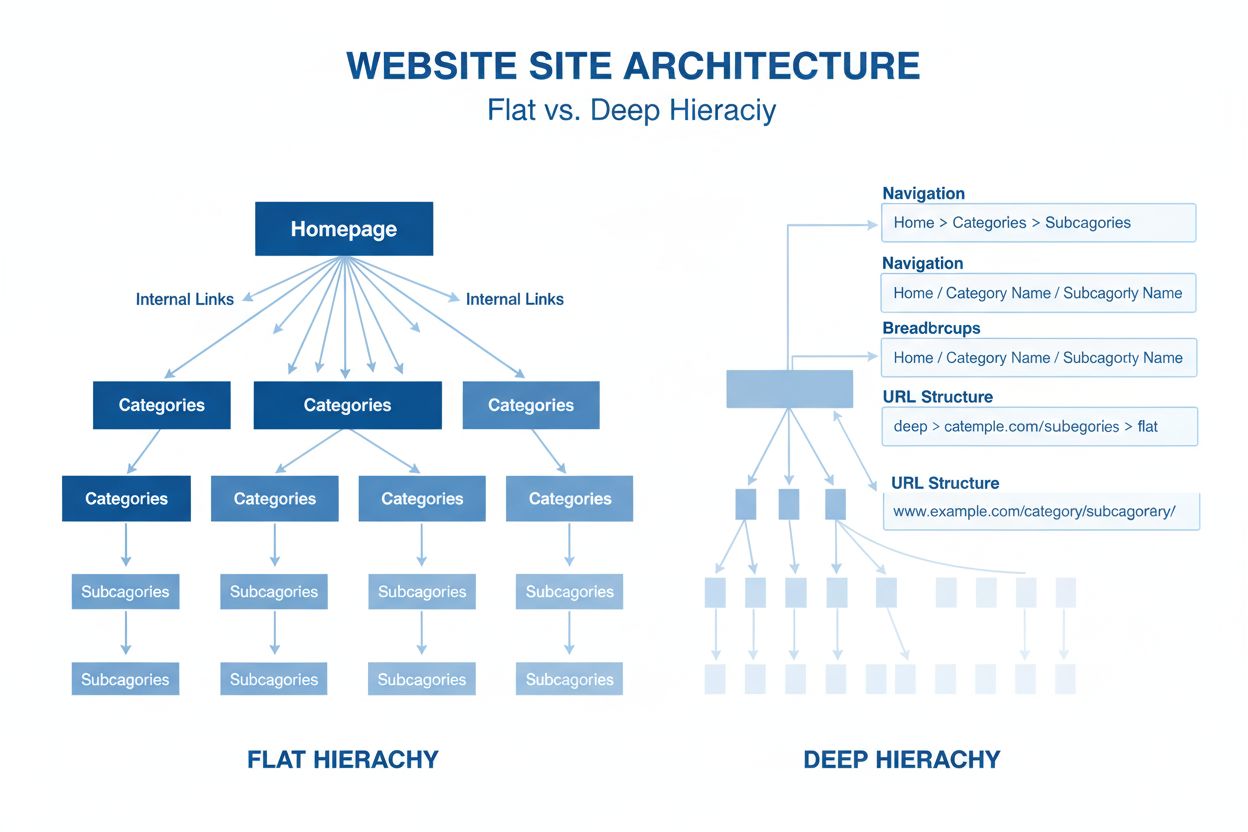
Sitearkitektur
Sitearkitektur er den hierarkiske organisering af websider og indhold. Lær hvordan korrekt webstedsstruktur forbedrer SEO, brugeroplevelse og AI-overvågningssyn...
8 min læsning

En neuralt netværksarkitektur baseret på multi-head self-attention-mekanismer, som behandler sekventielle data parallelt og muliggør udviklingen af moderne store sprogmodeller som ChatGPT, Claude og Perplexity. Transformer-arkitekturen blev introduceret i 2017-artiklen ‘Attention is All You Need’ og er blevet den grundlæggende teknologi bag stort set alle avancerede AI-systemer.
En neuralt netværksarkitektur baseret på multi-head self-attention-mekanismer, som behandler sekventielle data parallelt og muliggør udviklingen af moderne store sprogmodeller som ChatGPT, Claude og Perplexity. Transformer-arkitekturen blev introduceret i 2017-artiklen 'Attention is All You Need' og er blevet den grundlæggende teknologi bag stort set alle avancerede AI-systemer.
Transformer-arkitektur er et banebrydende neuralt netværksdesign, der blev introduceret i 2017-artiklen “Attention is All You Need” af forskere fra Google. Den er grundlæggende baseret på multi-head self-attention-mekanismer, der gør det muligt for modeller at behandle hele datastrømme parallelt i stedet for sekventielt. Arkitekturen består af stablede encoder- og decoderlag, som hver indeholder self-attention-underlag og feed-forward neurale netværk, forbundet gennem residualforbindelser og lag-normalisering. Transformer-arkitekturen er blevet den grundlæggende teknologi bag stort set alle moderne store sprogmodeller (LLM’er), herunder ChatGPT, Claude, Perplexity og Google AI Overviews, og anses dermed for at være den vigtigste neurale netværksinnovation i det seneste årti.
Betydningen af Transformer-arkitektur rækker langt ud over dens tekniske elegance. 2017-artiklen “Attention is All You Need” er blevet citeret over 208.000 gange og er en af de mest indflydelsesrige forskningsartikler i maskinlæringens historie. Denne arkitektur ændrede fundamentalt, hvordan AI-systemer behandler og forstår sprog, og muliggjorde udviklingen af modeller med milliarder af parametre, som kan engagere sig i sofistikeret ræsonnement, kreativ skrivning og kompleks problemløsning. Markedet for enterprise-LLM’er, der næsten udelukkende er bygget på transformer-teknologi, blev vurderet til 6,7 milliarder dollars i 2024 og forventes at vokse med en samlet årlig vækstrate på 26,1% frem til 2034, hvilket understreger arkitekturens afgørende betydning for moderne AI-infrastruktur.
Udviklingen af Transformer-arkitektur markerer et afgørende øjeblik i deep learning-historien, som udspringer af årtiers forskning i neurale netværk til sekventiel databehandling. Før transformers dominerede recurrent neural networks (RNNs) og deres varianter, især long short-term memory (LSTM) netværk, opgaver inden for naturlig sprogbehandling. Dog havde disse arkitekturer grundlæggende begrænsninger: De behandlede sekvenser sekventielt, ét element ad gangen, hvilket gjorde dem langsomme at træne og gav udfordringer med at indfange afhængigheder mellem fjerne elementer i lange sekvenser. Problemet med forsvindende gradienter begrænsede yderligere RNN’ers evne til at lære fra langtrækkende relationer, da gradienterne blev eksponentielt mindre, jo længere de blev ført bagud gennem mange lag.
Introduktionen af attention-mekanismer i 2014 af Bahdanau og kolleger blev et gennembrud, da det gjorde modeller i stand til at fokusere på relevante dele af inputsekvenser uanset afstand. Attention blev dog i første omgang brugt som et supplement til RNN’er og ikke som en erstatning. Transformer-artiklen fra 2017 tog dette koncept videre og foreslog, at attention er alt, du behøver—altså at en hel neural netværksarkitektur kunne bygges udelukkende ved hjælp af attention-mekanismer og feed-forward-lag og helt eliminere rekurrens. Denne indsigt blev skelsættende. Ved at eliminere sekventiel behandling gjorde transformers det muligt med massiv parallelisering, så forskere kunne træne på hidtil usete datamængder ved brug af GPU’er og TPU’er. Den største transformer-model i den oprindelige artikel, trænet på 8 GPU’er i 3,5 dage, demonstrerede, at skalering og parallelisering kunne føre til markant forbedret ydeevne.
Efter den oprindelige transformer-artikel udviklede arkitekturen sig hurtigt. BERT (Bidirectional Encoder Representations from Transformers), lanceret af Google i 2019, viste, at transformer-encodere kunne fortrænes på enorme tekstkorpora og finjusteres til forskellige downstream-opgaver. BERT’s største model indeholdt 345 millioner parametre og blev trænet på 64 specialiserede TPU’er i fire dage til en anslået pris på 7.000 dollars, men opnåede alligevel resultater i verdensklasse på adskillige benchmarks for sprogforståelse. Samtidig forfulgte OpenAI’s GPT-serie en anden tilgang, hvor kun decoder-baserede transformer-arkitekturer blev trænet på sprogmodellering. GPT-2 med 1,5 milliarder parametre overraskede forskningsmiljøet ved at vise, at sprogmodellering alene kunne skabe bemærkelsesværdigt kapable systemer. GPT-3 med 175 milliarder parametre udviste emergente egenskaber—færdigheder, der først opstod ved denne skala, som få-skuds-læring og kompleks ræsonnement—og ændrede fundamentalt forventningerne til, hvad AI-systemer kunne opnå.
Transformer-arkitektur består af flere sammenkoblede tekniske komponenter, der arbejder sammen for at muliggøre effektiv parallel behandling og avanceret kontekstforståelse. Input-embedding-laget omdanner diskrete tokens (ord eller subwords) til kontinuerlige vektor-repræsentationer, typisk med dimensionen 512 eller højere. Disse embeddings suppleres med positionel kodning, der tilføjer information om hver tokens position i sekvensen ved hjælp af sinus- og cosinusfunktioner ved forskellige frekvenser. Denne positionsinformation er afgørende, fordi transformers—i modsætning til RNN’er, der implicit bevarer rækkefølgen via deres rekursive struktur—behandler alle tokens samtidigt og har brug for eksplicitte signaler for at forstå ordrækkefølge og relative afstande.
Self-attention-mekanismen er den arkitektoniske innovation, der adskiller transformers fra alle tidligere neurale netværksdesigns. For hver token i inputsekvensen beregner modellen tre vektorer: en Query-vektor (repræsenterer, hvilken information token ønsker), Key-vektorer (repræsenterer, hvilken information hver token indeholder) og Value-vektorer (repræsenterer selve informationen, der skal viderebringes). Attention-mekanismen beregner en lighedsscore mellem hver tokens Query og alle tokens Keys ved hjælp af prikprodukt, normaliserer disse score med softmax for at skabe attention-vægte mellem 0 og 1, og bruger derefter vægtene til at danne en vægtet sum af Value-vektorer. Denne proces gør det muligt for hver token selektivt at fokusere på andre relevante tokens og dermed forstå kontekst og relationer.
Multi-head attention udvider dette koncept ved at køre flere parallelle attention-mekanismer samtidigt, typisk 8, 12 eller 16 heads. Hver head arbejder med forskellige lineære projektioner af Query-, Key- og Value-vektorerne og gør det muligt for modellen at fokusere på forskellige typer relationer og mønstre i forskellige repræsentations-underområder. For eksempel kan én attention-head fokusere på syntaktiske relationer mellem ord, mens en anden fokuserer på semantiske relationer eller langtrækkende afhængigheder. Outputtene fra alle heads sammenføjes og transformereres lineært, hvilket giver modellen rig og mangesidet kontekstuel information. Denne tilgang har vist sig yderst effektiv, og forskning viser, at de enkelte heads specialiserer sig i forskellige sproglige fænomener.
Encoder-decoder-strukturen organiserer disse attention-mekanismer i en hierarkisk behandlingspipeline. Encoder’en består af flere stablede lag (typisk 6 eller flere), som hver indeholder et multi-head self-attention-underlag efterfulgt af et positionsvist feed-forward-netværk. Residualforbindelser omkring hvert underlag gør det muligt for gradienter at flyde direkte gennem netværket under træning, hvilket forbedrer stabiliteten og muliggør dybere arkitekturer. Lag-normalisering anvendes efter hvert underlag for at normalisere aktiveringer og opretholde en ensartet skala gennem hele netværket. Decoder’en har en lignende struktur, men inkluderer et ekstra encoder-decoder-attention-lag, der gør det muligt for decoder’en at fokusere på encoderens output, når der genereres outputtokens. I decoder-only-arkitekturer som GPT genererer decoder’en outputtokens autoregressivt, hvor hver nye token er betinget af alle tidligere genererede tokens.
| Aspekt | Transformer-arkitektur | RNN/LSTM | Konvolutionsneuronale netværk (CNN) |
|---|---|---|---|
| Behandlingsmetode | Parallel behandling af hele sekvenser med attention | Sekventiel behandling, ét element ad gangen | Lokale konvolutionsoperationer på vinduer af fast størrelse |
| Langtrækkende afhængigheder | Fremragende; attention kan forbinde fjerne tokens direkte | Dårlig; begrænset af forsvindende gradienter og sekventiel flaskehals | Begrænset; lokalt receptive field kræver mange lag |
| Træningshastighed | Meget hurtig; massiv parallelisering på GPU/TPU | Langsom; sekventiel behandling forhindrer parallelisering | Hurtig for faste inputstørrelser; mindre egnet til variable sekvenser |
| Hukommelseskrav | Høje; kvadratiske i sekvenslængde pga. attention | Lavere; lineære i sekvenslængde | Moderate; afhænger af kernelstørrelse og dybde |
| Skalerbarhed | Fremragende; skalerer til milliarder af parametre | Begrænset; svært at træne meget store modeller | God for billeder; mindre egnet til sekvenser |
| Typiske anvendelser | Sprogmodellering, maskinoversættelse, tekstgenerering | Tidsserier, sekventiel forudsigelse (sjældnere nu) | Billedklassifikation, objektdetektion, computer vision |
| Gradientflow | Stabilt; residualforbindelser muliggør dybe netværk | Problematisk; forsvindende/eksploderende gradienter | Generelt stabilt; lokale forbindelser hjælper gradientflow |
| Positionsinformation | Eksplicit positionel kodning påkrævet | Implicit via sekventiel behandling | Implicit via rumlig struktur |
| State-of-the-art LLM’er | GPT, Claude, Llama, Granite, Perplexity | Sjældent brugt i moderne LLM’er | Ikke brugt til sprogmodellering |
Forholdet mellem Transformer-arkitektur og moderne store sprogmodeller er fundamentalt og uadskilleligt. Alle væsentlige LLM’er, der er lanceret de seneste fem år—including OpenAI’s GPT-4, Anthropic’s Claude, Meta’s Llama, Googles Gemini, IBM’s Granite og Perplexity’s AI-modeller—er bygget på transformer-arkitekturen. Arkitekturens evne til effektivt at skalere både modelstørrelse og træningsdata har vist sig afgørende for at opnå de kapaciteter, der definerer moderne AI-systemer. Da forskere øgede modelstørrelsen fra millioner til milliarder og hundreder af milliarder af parametre, gjorde transformerens parallelisering og attention-mekanismer denne skalering mulig uden proportionalt forøgede træningstider.
Autoregressiv decoding, som bruges af de fleste moderne LLM’er, er en direkte anvendelse af transformer-decoder-arkitekturen. Når disse modeller genererer tekst, behandles inputprompten gennem encoder’en (eller i decoder-only-modeller gennem den fulde decoder), hvorefter outputtokens genereres én ad gangen. Hver ny token genereres ved at beregne sandsynlighedsfordelinger over hele ordforrådet via softmax, hvor modellen vælger den mest sandsynlige token (eller samplinger fra fordelingen afhængigt af temperaturindstillinger). Denne proces, der gentages hundredvis eller tusindvis af gange, producerer sammenhængende, kontekstuelt passende tekst. Self-attention-mekanismen gør det muligt for modellen at bevare kontekst på tværs af hele den genererede sekvens og giver mulighed for at skabe lange, sammenhængende afsnit med konsistente temaer, karakterer og logisk flow.
De emergente evner, der observeres i store transformer-modeller—evner, der kun opstår ved tilstrækkelig skala, såsom få-skuds-læring, kæde-af-tanke-reasoning og in-context learning—er direkte konsekvenser af transformer-arkitekturens design. Multi-head attention-mekanismens evne til at opfange forskellige relationer, kombineret med modellens enorme parameterantal og træning på varieret data, gør disse systemer i stand til at udføre opgaver, de aldrig eksplicit er blevet trænet på. For eksempel kunne GPT-3 udføre aritmetik, skrive kode og besvare trivia-spørgsmål, selvom den kun var trænet på sprogmodellering. Disse emergente egenskaber har gjort transformer-baserede LLM’er til fundamentet i den moderne AI-revolution, med anvendelser fra samtale-AI og indholdsgenerering til kodegenerering og videnskabelig forskningsassistance.
Self-attention-mekanismen er den arkitektoniske innovation, der fundamentalt adskiller transformers og forklarer deres overlegne præstation sammenlignet med tidligere tilgange. For at forstå self-attention kan man tage udgangspunkt i udfordringen med at fortolke tvetydige pronominer i sprog. I sætningen “Trofæet kan ikke være i kufferten, fordi det er for stort,” kan pronomenet “det” henvise til enten trofæet eller kufferten, men konteksten gør det klart, at det henviser til trofæet. I sætningen “Trofæet kan ikke være i kufferten, fordi det er for lille,” henviser det samme pronomen nu til kufferten. En transformer-model skal lære at løse sådanne tvetydigheder ved at forstå relationerne mellem ordene.
Self-attention løser dette med en matematisk elegant proces. For hver token i inputsekvensen beregner modellen en Query-vektor ved at multiplicere token-embedding’en med en lært vægtmatrix WQ. På samme måde beregnes Key-vektorer (med WK) og Value-vektorer (med WV) for alle tokens. Attention-scoren mellem en tokens Query og en anden tokens Key beregnes som prikproduktet mellem disse vektorer, normaliseret med kvadratroden af nøgle-dimensionen (typisk √64 ≈ 8). Disse rå score sendes gennem en softmax-funktion, der omdanner dem til normaliserede attention-vægte, der summerer til 1. Til sidst udregnes outputtet for hver token som en vægtet sum af alle Value-vektorer, hvor vægtene er attentionscorerne. Denne proces gør det muligt for hver token selektivt at aggregere information fra alle andre tokens, hvor vægtene læres under træning til at fange meningsfulde relationer.
Den matematiske elegance ved self-attention muliggør effektiv beregning. Hele processen kan udtrykkes som matrixoperationer: Attention(Q, K, V) = softmax(QK^T / √d_k)V, hvor Q, K og V er matricer med alle query-, key- og value-vektorer. Denne matrixformulering muliggør GPU-acceleration, så transformers kan behandle hele sekvenser parallelt i stedet for sekventielt. En sekvens på 512 tokens kan behandles omtrent lige så hurtigt som én token i en RNN, hvilket gør transformers mange størrelsesordener hurtigere at træne. Denne beregningseffektivitet, kombineret med attention-mekanismens evne til at opfange langtrækkende afhængigheder, forklarer, hvorfor transformers er blevet den dominerende arkitektur til sprogmodellering.
Multi-head attention udvider self-attention-mekanismen ved at køre flere parallelle attention-operationer, som hver lærer forskellige aspekter af token-relationer. I en typisk transformer med 8 attention-heads projiceres input-embeddings lineært ind i 8 forskellige underområder, hver med egne Query-, Key- og Value-vægtmatricer. Hver head beregner uafhængigt attention-vægte og producerer outputvektorer. Disse outputs sammenføjes og transformeres lineært via en samlet vægtmatrix, hvilket giver det endelige multi-head-attention-output. Denne arkitektur gør det muligt for modellen samtidigt at fokusere på information fra forskellige underområder på forskellige positioner.
Forskning i trænede transformer-modeller har vist, at forskellige attention-heads specialiserer sig i forskellige sproglige fænomener. Nogle heads fokuserer på syntaktiske relationer og lærer at rette opmærksomheden mod grammatisk relaterede ord (f.eks. verber, der retter opmærksomheden mod deres subjekter og objekter). Andre heads fokuserer på semantiske relationer og lærer at rette opmærksomheden mod ord med beslægtet betydning. Yderligere heads opfanger langtrækkende afhængigheder og retter opmærksomheden mod ord, der er langt fra hinanden i sekvensen, men alligevel semantisk relaterede. Nogle heads lærer endda primært at fokusere på det nuværende token, hvilket i praksis fungerer som en identitetsoperation. Denne specialisering opstår naturligt under træningen uden eksplicit supervision og demonstrerer multi-head-arkitekturens evne til at lære mangfoldige og komplementære repræsentationer.
Antallet af attention-heads er en vigtig arkitektonisk hyperparameter. Større modeller bruger typisk flere heads (16, 32 eller endda flere), hvilket gør dem i stand til at opfange flere forskellige relationer. Dog holdes den samlede dimensionalitet af attention-beregningen typisk konstant, så flere heads betyder lavere dimensionalitet pr. head. Dette designvalg balancerer fordelene ved flere underområder med beregningseffektivitet. Multi-head-tilgangen er blevet standard i stort set alle moderne transformer-implementeringer, fra BERT og GPT til specialiserede arkitekturer for vision, lyd og multimodale opgaver.
Den oprindelige transformer-arkitektur, som beskrevet i “Attention is All You Need”-artiklen, bruger en encoder-decoder-struktur optimeret til sekvens-til-sekvens-opgaver som maskinoversættelse. Encoder’en behandler inputsekvensen og producerer en sekvens af kontekstrige repræsentationer. Hvert encoder-lag består af to hovedkomponenter: et multi-head self-attention-underlag, der gør det muligt for tokens at rette opmærksomheden mod andre tokens i inputtet, og et positionsvist feed-forward-netværk, der anvender den samme ikke-lineære transformation på hver position uafhængigt. Disse underlag forbindes via residualforbindelser (også kaldet skip connections), som lægger inputtet til outputtet af hvert underlag. Dette designvalg, inspireret af residualnetværk i computer vision, muliggør træning af meget dybe netværk, fordi gradienter kan flyde direkte gennem netværket.
Decoder’en genererer outputsekvensen én token ad gangen ved brug af information fra både encoder’en og tidligere genererede tokens. Hvert decoder-lag indeholder tre hovedkomponenter: et maskeret self-attention-underlag, der gør det muligt for hver token kun at rette opmærksomheden mod tidligere tokens (så modellen ikke kan “snyde” ved at se fremtidige tokens under træningen), et encoder-decoder-attention-underlag, der gør det muligt for decoder-tokens at rette opmærksomheden mod encoder-outputs, samt et positionsvist feed-forward-netværk. Maskeringen i self-attention-underlaget er afgørende: den forhindrer information i at flyde fra fremtidige positioner til tidligere positioner, så forudsigelser for position i kun afhænger af kendte outputs på positioner mindre end i. Denne autoregressive struktur er essentiel for at generere sekvenser én token ad gangen.
Encoder-decoder-arkitekturen har vist sig særligt effektiv til opgaver, hvor input og output har forskellige strukturer eller længder, såsom maskinoversættelse (oversættelse fra ét sprog til et andet), opsummering (kondensering af lange dokumenter) og spørgsmål-svar (generering af svar på baggrund af kontekst). Dog bruger moderne LLM’er som GPT kun decoder-arkitekturer, hvor en enkelt stak af decoder-lag både behandler inputprompten og genererer output. Denne forenkling mindsker modelkompleksiteten og har vist sig lige så eller mere effektiv til sprogmodellering, sandsynligvis fordi modellen kan lære at bruge self-attention til at behandle input og generere output i én samlet proces.
En kritisk udfordring i transformer-arkitekturen er at repræsentere rækkefølgen af tokens i en sekvens. I modsætning til RNN’er, der implicit bevarer sekvensrækkefølgen gennem deres rekursive struktur, behandler transformers alle tokens parallelt og har ingen indbygget opfattelse af position. Uden eksplicit positionsinformation ville en transformer behandle sekvensen “Katten sad på måtten” identisk med “måtten på sad katten,” hvilket ville være katastrofalt for sprogforståelsen. Løsningen er positionel kodning, hvor positionsafhængige vektorer tilføjes til token-embeddings inden behandling.
Den oprindelige transformer-artikel bruger sinusoide positionelle kodninger, hvor positionsvektoren for position pos og dimension i beregnes som:
Disse sinusoide funktioner skaber et unikt mønster for hver position med forskellige frekvenser for forskellige dimensioner. Lavere frekvenser (mindre i) varierer langsomt med positionen og indfanger langtrækkende positionsinformation, mens højere frekvenser varierer hurtigt og indfanger detaljerede positionsdata. Dette design har flere fordele: det generaliserer naturligt til sekvenser, der er længere end dem, modellen er trænet på, det giver glatte positionsovergange, og det gør det muligt for modellen at lære relative positionsrelationer. De positionelle kodningsvektorer lægges blot til token-embeddings inden det første attention-lag, og modellen lærer at bruge denne positionsinformation under træningen.
Alternative positionelle kodningsmetoder er blevet foreslået og undersøgt, herunder relative positionsrepræsentationer (der koder afstande mellem tokens i stedet for absolutte positioner) og roterende positionsembeddings (RoPE) (der roterer embedding-vektorer baseret på position). Disse alternativer har vist forbedringer i visse scenarier, især for meget lange sekvenser eller ved finjustering på sekvenser, der er længere end træningssekvenserne. Valget af positionel kodning kan have stor betydning for modelpræstationen, og dette er fortsat et aktivt forskningsområde i optimering af transformer-arkitektur.
Forståelse af Transformer-arkitektur er afgørende for at begribe, hvordan moderne AI-systemer genererer svar, der optræder på platforme som ChatGPT, Claude, Perplexity og Google AI Overviews. Disse systemer, alle bygget på transformer-teknologi, behandler brugerforespørgsler gennem flere lag af self-attention, hvilket gør dem i stand til at forstå kontekst og generere sammenhængende, relevante svar. Når en bruger stiller et spørgsmål om et brand, produkt eller domæne, afgør transformer-modellens attention-mekanismer, hvilke dele af træningsdataene der er mest relevante, og decoder’en genererer et svar, der kan nævne eller referere til det brand.
For organisationer, der bruger AI-overvågningsplatforme som AmICited, giver forståelse af transformer-arkitektur vigtig kontekst for at fortolke, hvordan og hvorfor brands optræder i AI-genereret indhold. Self-attention-mekanismens evne til at indfange relationer mellem begreber betyder, at brands nævnt i træningsdataene kan forbindes med bestemte emner, brancher eller use cases. Når en bruger spørger et AI-system om disse emner, kan attention-mekanismen aktivere forbindelser til dit brand, hvilket resulterer i omtaler i outputtet. Multi-head attention-strukturen betyder, at forskellige aspekter af dit brands tilstedeværelse i træningsdataene kan indfanges af forskellige attention-heads, hvilket påvirker, hvor omfattende modellen forstår og repræsenterer dit brand.
Transformer-arkitekturens afhængighed af træningsdata forklarer også, hvorfor brand-synlighed i AI-output i høj grad afhænger af kvaliteten og mængden af din online tilstedeværelse. Modeller, der er trænet på internettekster, vil have rigere repræsentationer af brands med
Transformer-arkitektur behandler hele sekvenser parallelt ved hjælp af self-attention, mens RNN'er og LSTM'er behandler sekvenser sekventielt, ét element ad gangen. Denne parallelisering gør transformerne betydeligt hurtigere at træne og bedre til at fange langtrækkende afhængigheder mellem fjerne ord eller tokens. Transformere undgår også det forsvindende gradientproblem, der plagede RNN'er, hvilket gør dem i stand til effektivt at lære fra meget længere sekvenser.
Self-attention beregner tre vektorer (Query, Key og Value) for hver token i inputsekvensen. Query-vektoren fra én token sammenlignes med Key-vektorerne for alle tokens for at bestemme relevansscore, som normaliseres ved hjælp af softmax. Disse attention-vægte anvendes derefter på Value-vektorer for at skabe kontekstafhængige repræsentationer. Denne mekanisme gør det muligt for hver token at 'rette opmærksomheden mod' andre relevante tokens i sekvensen, hvilket gør modellen i stand til at forstå kontekst og relationer.
De vigtigste komponenter omfatter: (1) Input Embeddings og Positionel Kodning for at repræsentere tokens og deres positioner, (2) Multi-head self-attention-lag, der beregner attention på tværs af flere repræsentations-underområder, (3) Feed-forward neurale netværk anvendt uafhængigt på hver position, (4) Encoder-stak, der behandler inputsekvenser, (5) Decoder-stak, der genererer outputsekvenser, og (6) Residualforbindelser og lag-normalisering for træningsstabilitet. Disse komponenter arbejder sammen og muliggør effektiv parallel behandling og kontekstforståelse.
Transformer-arkitektur er fremragende for LLM'er, fordi den muliggør parallel behandling af hele sekvenser, hvilket dramatisk reducerer træningstiden sammenlignet med sekventielle RNN'er. Den opfanger langtrækkende afhængigheder mere effektivt via self-attention, så modeller kan forstå kontekst på tværs af hele dokumenter. Arkitekturen skalerer også effektivt med større datasæt og flere parametre, hvilket har vist sig essentielt for at træne modeller med milliarder af parametre, der udviser emergente evner.
Multi-head attention kører flere parallelle attention-mekanismer (typisk 8 eller 16 heads) samtidigt, som hver arbejder på forskellige repræsentations-underområder. Hver head lærer at fokusere på forskellige typer relationer og mønstre i dataene. Outputtene fra alle heads sammenføjes og transformeres lineært, så modellen kan indfange mangfoldig kontekstuel information. Denne tilgang forbedrer markant modellens evne til at forstå komplekse relationer og øger den samlede præstation.
Positionel kodning tilføjer information om token-positioner til inputembeddings ved hjælp af sinus- og cosinusfunktioner ved forskellige frekvenser. Da transformers behandler alle tokens parallelt (i modsætning til sekventielle RNN'er), har de brug for eksplicit positionsinformation for at forstå ordrækkefølge. Positionelle kodningsvektorer lægges til token-embeddings inden behandling, så modellen kan lære, hvordan position påvirker betydning og generalisere til sekvenser, der er længere end dem, den er trænet på.
Encoder'en behandler inputsekvensen og skaber rige kontekstuelle repræsentationer gennem flere lag af self-attention og feed-forward-netværk. Decoder'en genererer outputsekvensen én token ad gangen og bruger encoder-decoder-attention til at fokusere på relevante dele af inputtet. Denne struktur er særlig nyttig til sekvens-til-sekvens-opgaver som maskinoversættelse, men moderne LLM'er bruger ofte kun decoder-arkitekturer til tekstgenereringsopgaver.
Transformer-arkitektur driver de AI-systemer, der genererer svar på platforme som ChatGPT, Claude, Perplexity og Google AI Overviews. Forståelse af, hvordan transformers behandler og genererer tekst, er afgørende for AI-overvågningsplatforme som AmICited, der sporer, hvor brands og domæner optræder i AI-genererede svar. Arkitekturens evne til at forstå kontekst og generere sammenhængende tekst påvirker direkte, hvordan brands nævnes og repræsenteres i AI-output.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Sitearkitektur er den hierarkiske organisering af websider og indhold. Lær hvordan korrekt webstedsstruktur forbedrer SEO, brugeroplevelse og AI-overvågningssyn...
Informationsarkitektur er praksissen med at organisere og strukturere indhold for optimal brugervenlighed. Lær, hvordan IA forbedrer findbarhed, brugeroplevelse...

GPT-4 er OpenAI's avancerede multimodale LLM, der kombinerer tekst- og billedbehandling. Lær om dens kapaciteter, arkitektur og indflydelse på AI-overvågning og...